文章目录
- 0. 前言
- 1. Cifar10数据集
- 1.1 Cifar10数据集下载
- 1.2 Cifar10数据集解析
- 2. LeNet5网络
- 2.1 LeNet5的网络结构
- 2.2 基于PyTorch的LeNet5网络编码
- 3. LeNet5网络训练及输出验证
- 3.1 LeNet5网络训练
- 3.2 LeNet5网络验证
- 4. 完整代码
- 4.1 训练代码
- 4.1 验证代码
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文是基于PyTorch框架使用LeNet5网络实现图像分类的实战演练,训练的数据集采用Cifar10,旨在通过实操强化对深度学习尤其是卷积神经元网络的理解。
本文是一个完整的保姆级学习指引,只要具备最基础的深度学习知识就可以通过本文的指引:使用PyTorch库从零搭建LeNet5网络,然后对其进行训练,最后能够识别实拍图像中的实物。
1. Cifar10数据集
Cifar10数据集由计算机科学家Geoffrey Hinton的学生Alex Krizhevsky、Ilya Sutskever 在1990年代创建。Cifar10是一个包含10个类别的图像分类数据集,每个类别包含6000张32x32像素的彩色图像,总计60000张图像,其中50000个图像用于训练网络模型(训练组),10000个图像用于验证网络模型(验证组)。
其名字Cifar10代表Canadian Institute for Advanced Research(加拿大高级研究所)做的10种分类的图像集,后面的Cifar100则是100种分类的图像集。
1.1 Cifar10数据集下载
使用torchvision直接下载Cifar10:
from torchvision import datasets
from torchvision import transforms
data_path = 'CIFAR10/IMG_file'
cifar10 = datasets.CIFAR10(root=data_path, train=True, download=True,transform=transforms.ToTensor()) #首次下载时download设为true
datasets.CIFAR10中的参数:
- root:下载文件的路径
- train:如果为True,则是下载训练组数据,总计50000张图像;如果为False,则是下载验证组数据,总计10000张图像
- download:新下载时需要设定为True,如果已经下载好数据可以设定为False
- transform:对图像数据进行变形,这里指定为
transforms.ToTensor()图像数据会被转换为Tensor,数据范围调整到0~1,省得我们再写一行归一化代码了
1.2 Cifar10数据集解析
下载之后可以看一下Cifar10数据集的具体内容:
print(type(cifar10))
print(cifar10[0])
------------------------输出------------------------------------
<class 'torchvision.datasets.cifar.CIFAR10'>
(tensor([[[0.2314, 0.1686, 0.1961, ..., 0.6196, 0.5961, 0.5804],
[0.0627, 0.0000, 0.0706, ..., 0.4824, 0.4667, 0.4784],
[0.0980, 0.0627, 0.1922, ..., 0.4627, 0.4706, 0.4275],
...,
[0.8157, 0.7882, 0.7765, ..., 0.6275, 0.2196, 0.2078],
[0.7059, 0.6784, 0.7294, ..., 0.7216, 0.3804, 0.3255],
[0.6941, 0.6588, 0.7020, ..., 0.8471, 0.5922, 0.4824]],
[[0.2431, 0.1804, 0.1882, ..., 0.5176, 0.4902, 0.4863],
[0.0784, 0.0000, 0.0314, ..., 0.3451, 0.3255, 0.3412],
[0.0941, 0.0275, 0.1059, ..., 0.3294, 0.3294, 0.2863],
...,
[0.6667, 0.6000, 0.6314, ..., 0.5216, 0.1216, 0.1333],
[0.5451, 0.4824, 0.5647, ..., 0.5804, 0.2431, 0.2078],
[0.5647, 0.5059, 0.5569, ..., 0.7216, 0.4627, 0.3608]],
[[0.2471, 0.1765, 0.1686, ..., 0.4235, 0.4000, 0.4039],
[0.0784, 0.0000, 0.0000, ..., 0.2157, 0.1961, 0.2235],
[0.0824, 0.0000, 0.0314, ..., 0.1961, 0.1961, 0.1647],
...,
[0.3765, 0.1333, 0.1020, ..., 0.2745, 0.0275, 0.0784],
[0.3765, 0.1647, 0.1176, ..., 0.3686, 0.1333, 0.1333],
[0.4549, 0.3686, 0.3412, ..., 0.5490, 0.3294, 0.2824]]]), 6)
Process finished with exit code 0
可以见到Cifar10有其单独的数据类型torchvision.datasets.cifar.CIFAR10,其结构类似list。
如果输出其中某一元素,例如第一个cifar10[0],其中包含:
- 一个维度为[3,32,32]的tensor(因为上面Transform已经指定了ToTensor),这个就是RGB三通道的图像数据
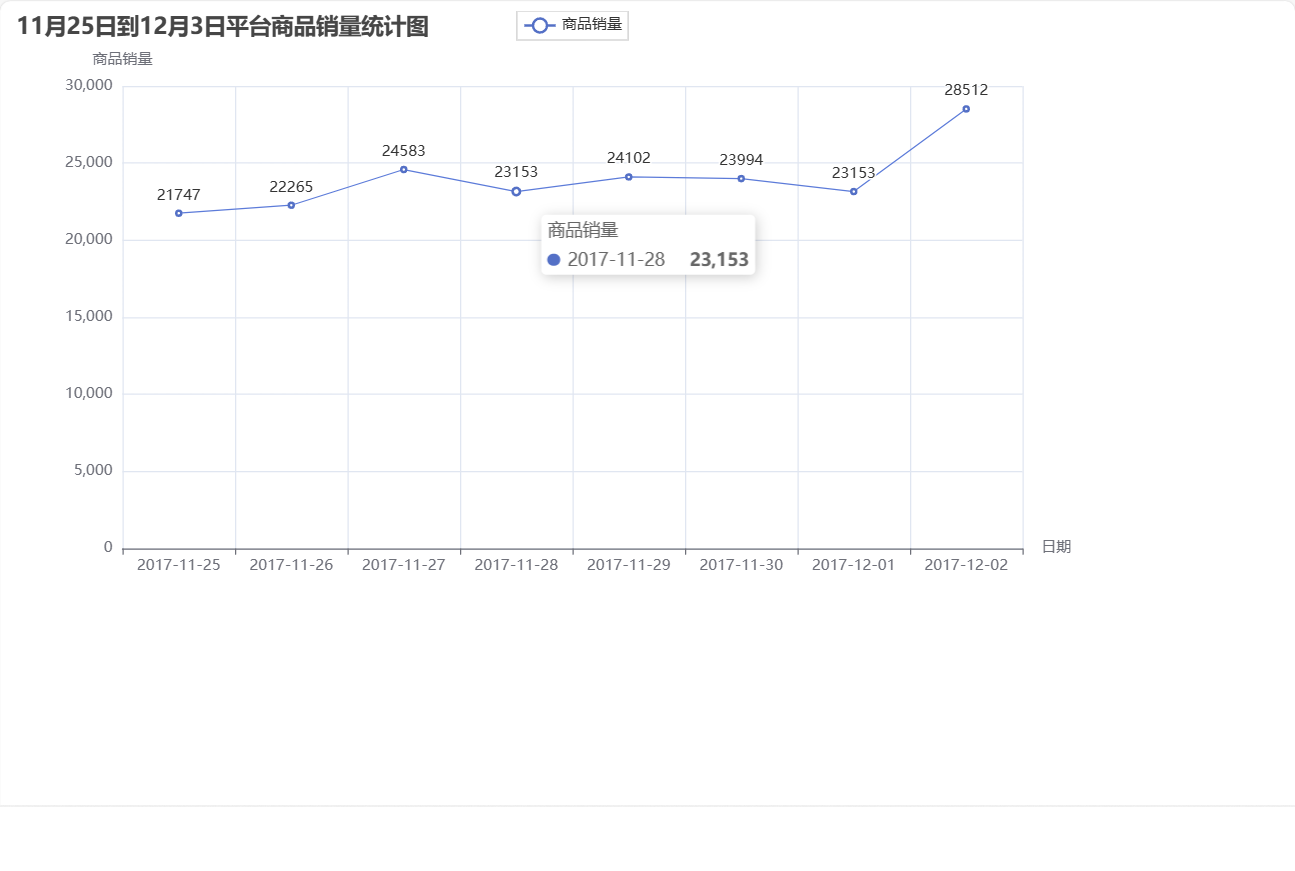
- 一个标量数据label,这里是
6,这个数据代表图像的真实分类,其对应关系如下表:
这里我们也可以用matplotlib把图像的tensor数据转回图像,看看这个label为6的图像究竟是什么样的:
from torchvision import datasets
import matplotlib.pyplot as plt
from torchvision import transforms
data_path = 'CIFAR10/IMG_file'
cifar10 = datasets.CIFAR10(root=data_path, train=True, download=False,transform=transforms.ToTensor()) #首次下载时download设为true
# print(type(cifar10))
# print(cifar10[0])
img,label = cifar10[0]
plt.imshow(img.permute(1,2,0))
plt.show()
输出为:
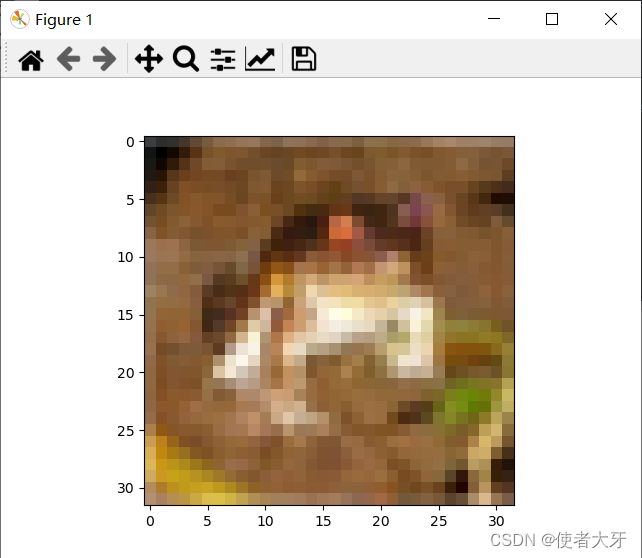
没错,这是一个label为6的Frog,32×32像素的图像就只能做到这个程度了。
这里使用了
.permute()是因为原始数据的维度是[channel3, H32, W32],而.imshow()要求的输入维度应该是[H, W, channel],需要调整下原始数据的维度顺序。
2. LeNet5网络
LeNet5是由Yann LeCun在20世纪90年代初提出,是一个经典的卷积神经网络。LeNet5由7层神经网络组成,包括2个卷积层、2个池化层和3个全连接层。其(在当时的时代背景下)创造性地使用了卷积层和池化层对输入进行特征提取,减少了参数数量,同时增强了网络对输入图像的平移和旋转不变性。
LeNet5被广泛应用于手写数字识别,也可用于其他图像分类任务。虽然现在的深度卷积神经网络比LeNet5有更好的性能,但LeNet5对于学习卷积神经网络的基本原理和方法具有重要的教育意义。
2.1 LeNet5的网络结构
LeNet5的网络结构如下图:
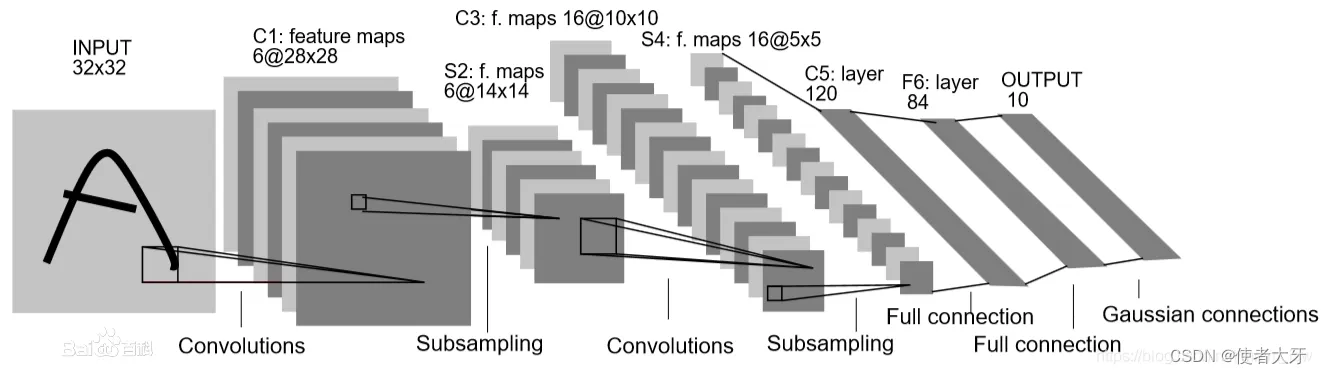
LeNet5的输入为32x32的图像:
- 第一层为一个卷积层,包含6个5x5的卷积核,输出的特征图为28x28
- 第二层为一个2x2的最大池化层,将特征图大小缩小一半14×14
- 第三层为另一个卷积层,包含16个5x5的卷积核,输出的特征图为10x10
- 第四层同第二层,将特征图大小缩小一半5×5
- 第五层为一个全连接层,含有120个神经元
- 第六层为另一个全连接层,含有84个神经元
- 最后一层为输出层,包含10个神经元,每个神经元对应一个label
2.2 基于PyTorch的LeNet5网络编码
根据上文LeNet5的网络结构,编写代码如下:
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5), # 由于图片为RGB彩图,channel_in = 3
#输出张量为 Batch(1)*Channel(6)*H(28)*W(28)
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 输出张量为 Batch(1)*Channel(6)*H(14)*W(14)
nn.Conv2d(in_channels=6,out_channels= 16,kernel_size= 5),
# 输出张量为 Batch(1)*Channel(16)*H(10)*W(10)
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 输出张量为 Batch(1)*Channel(16)*H(5)*W(5)
nn.Conv2d(in_channels=16, out_channels=120,kernel_size=5),
# 输出张量为 Batch(1)*Channel(120)*H(1)*W(1)
nn.Flatten(),
# 将输出一维化,用于后面的全连接网络输入
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, x):
return self.net(x)
3. LeNet5网络训练及输出验证
3.1 LeNet5网络训练
碍于我的电脑没有GPU,使用CPU版PyTorch数据训练非常慢,我只取了Cifar10的前2000个数据进行训练 (T_T)
small_cifar10 = []
for i in range(2000):
small_cifar10.append(cifar10[i])
训练相关设置如下:
- 损失函数:交叉熵损失函数
nn.CrossEntropyLoss() - 优化方式:随机梯度下降
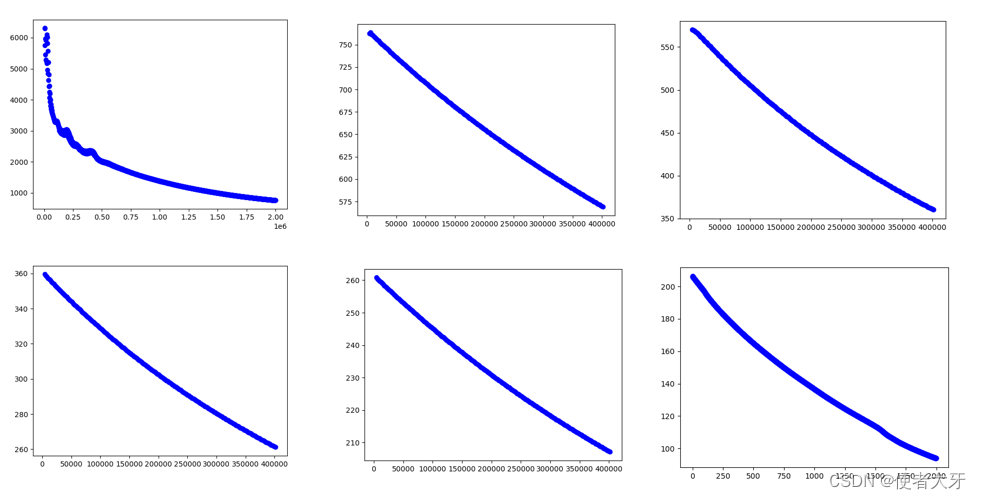
torch.optim.SGD() - epoch与learning rate:这是比较头疼的地方,目前我没有探索出太好的方式能在初期就把epoch和lr设定的比较好,只能进行逐步尝试。为了不浪费每次训练,我们可以把每次训练的权重保存下来,下次训练基于上次的结果进行。保存和加载权重的方式可以参考往期博客:通过实例学习Pytorch加载权重.load_state_dict()与保存权重.save()。下图展示了我的探索过程:lr的取值大约从1e-5逐步降低到2e-7,epoch总计大概有3000左右,loss值由初始的10000左右下降到100内。
这一块的训练过程忘记完整记录每一步的详细参数(epoch和lr)了,如果你有需要可以留下邮箱,我把训练好的权重发给你。读者也可以探索更好的训练参数。
3.2 LeNet5网络验证
激动人心的时刻来了!现在来验证我们训练好的网络能否准确识别目标图像!
我选用的图像是小鹏汽车在2023年上市的G6车型进行验证,图像如下:

加载我们训练好的权重文件,把图像输入到模型中:
def img_totensor(img_file):
img = Image.open(img_file)
transform = transforms.Compose([transforms.ToTensor(), transforms.Resize((32, 32))])
img_tensor = transform(img).unsqueeze(0) #这里要升维,对应增加batch维度
return img_tensor
test_model = LeNet()
test_model.load_state_dict(torch.load('CIFAR10/small2000_8.pth'))
img1 = img_totensor('1.jpg')
img2 = img_totensor('2.jpg')
img3 = img_totensor('3.jpg')
img4 = img_totensor('4.jpg')
print(test_model(img1))
print(test_model(img2))
print(test_model(img3))
print(test_model(img4))
最终输出如下:
tensor([[ 8.4051, 12.0952, -7.9274, 0.3868, -3.0866, -4.7883, -1.6089, -3.6484,
-1.1387, 4.7348]], grad_fn=<AddmmBackward0>)
tensor([[-1.1992, 17.4531, -2.7929, -6.0410, -1.7589, -2.6942, -3.6753, -2.6800,
3.6378, 2.4267]], grad_fn=<AddmmBackward0>)
tensor([[ 1.7580, 10.6321, -5.3922, -0.4557, -2.0147, -0.5974, -0.5785, -4.7977,
-1.2916, 5.4786]], grad_fn=<AddmmBackward0>)
tensor([[10.5689, 6.2413, -0.9554, -4.4162, 1.0807, -7.9541, -5.3185, -6.0609,
5.1129, 4.2243]], grad_fn=<AddmmBackward0>)
我们来解读一下这个输出:
- 第1、2、3个图像对应输出tensor最大值在第
[1]个元素(从0开始计数),即对应label值为1,真实分类为Car,预测正确。 - 第4个图像的输出预测错误,最大值在第
[0]个元素,LeNet5认为这个图像是Airplane。
这个准确率虽然不算高,但是别忘了我仅仅使用了Cifar10的前2000个数据进行训练;而且LeNet5网络输入为32×32大小的图像,例如上面的青蛙,即使让人来分辨也是挺困难的任务。
4. 完整代码
4.1 训练代码
#文件命名为 CIFAR10_main.py 后面验证时需要调用
from torchvision import datasets
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import transforms
from tqdm import tqdm
data_path = 'CIFAR10/IMG_file'
cifar10 = datasets.CIFAR10(data_path, train=True, download=False,transform=transforms.ToTensor()) #首次下载时download设为true
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5), # 由于图片为RGB彩图,channel_in = 3
#输出张量为 Batch(1)*Channel(6)*H(28)*W(28)
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 输出张量为 Batch(1)*Channel(6)*H(14)*W(14)
nn.Conv2d(in_channels=6,out_channels= 16,kernel_size= 5),
# 输出张量为 Batch(1)*Channel(16)*H(10)*W(10)
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 输出张量为 Batch(1)*Channel(16)*H(5)*W(5)
nn.Conv2d(in_channels=16, out_channels=120,kernel_size=5),
# 输出张量为 Batch(1)*Channel(120)*H(1)*W(1)
nn.Flatten(),
# 将输出一维化,用于后面的全连接网络输入
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, x):
return self.net(x)
if __name__ == '__main__':
model = LeNet()
model.load_state_dict(torch.load('CIFAR10/small2000_7.pth'))
loss = nn.CrossEntropyLoss()
opt = torch.optim.SGD(model.parameters(),lr=2e-7)
small_cifar10 = []
for i in range(2000):
small_cifar10.append(cifar10[i])
for epoch in range(1000):
opt.zero_grad()
total_loss = torch.tensor([0])
for img,label in tqdm(small_cifar10):
output = model(img.unsqueeze(0))
label = torch.tensor([label])
LeNet_loss = loss(output, label)
total_loss = total_loss + LeNet_loss
LeNet_loss.backward()
opt.step()
total_loss_numpy = total_loss.detach().numpy()
plt.scatter(epoch,total_loss_numpy,c='b')
print(total_loss)
print("epoch=",epoch)
torch.save(model.state_dict(),'CIFAR10/small2000_8.pth')
plt.show()
4.1 验证代码
import torch
from torchvision import transforms
from PIL import Image
from CIFAR10_main import LeNet
def img_totensor(img_file):
img = Image.open(img_file)
transform = transforms.Compose([transforms.ToTensor(), transforms.Resize((32, 32))])
img_tensor = transform(img).unsqueeze(0) #这里要升维,对应增加batch维度
return img_tensor
test_model = LeNet()
test_model.load_state_dict(torch.load('CIFAR10/small2000_8.pth'))
img1 = img_totensor('1.jpg')
img2 = img_totensor('2.jpg')
img3 = img_totensor('3.jpg')
img4 = img_totensor('4.jpg')
print(test_model(img1))
print(test_model(img2))
print(test_model(img3))
print(test_model(img4))