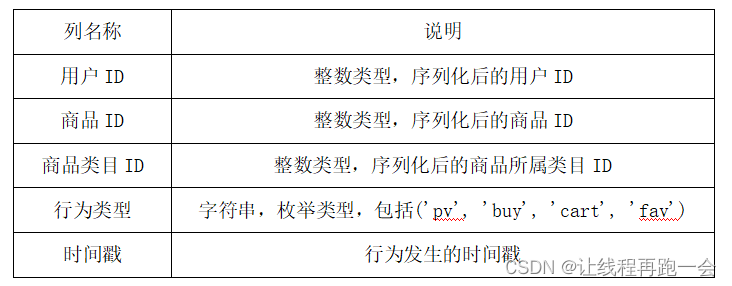
数据说明
Spark 数据分析 (Scala)
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
import java.io.{File, PrintWriter}
object Taobao {
case class Info(userId: Long,itemId: Long,action: String,time: String)
def main(args: Array[String]): Unit = {
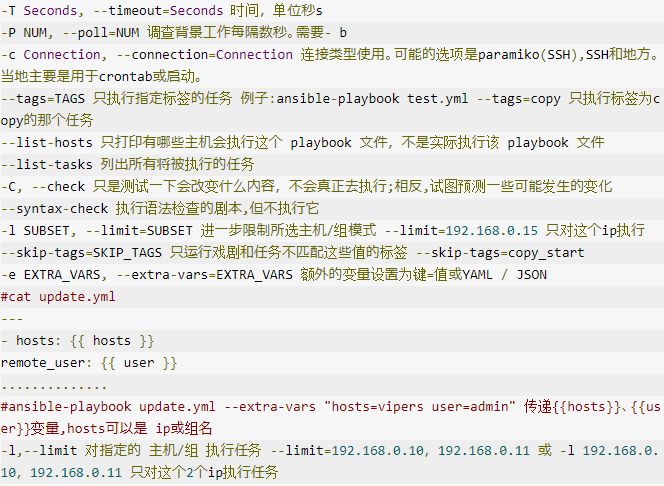
// 使用2个CPU核心
val conf = new SparkConf().setMaster("local[2]").setAppName("tao bao product")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val sc = spark.sparkContext
// 从本地文件系统加载文件生成RDD对象
val rdd: RDD[Array[String]] = sc.textFile("data/practice2/Processed_UserBehavior.csv").map(_.split(","))
// RDD 转为 DataFrame对象
val df: DataFrame = rdd.map(attr => Info(attr(0).trim.toInt, attr(1).trim.toInt, attr(2), attr(3))).toDF()
// Spark 数据分析
//1.用户行为信息统计
val behavior_count: DataFrame = df.groupBy("action").count()
val result1 = behavior_count.toJSON.collectAsList().toString
// val writer1 = new PrintWriter(new File("data/practice2/result1.json"))
// writer1.write(result1)
// writer1.close()
//2.销量前十的商品信息统计
val top_10_item:Array[(String,Int)] = df.filter(df("action") === "buy").select(df("itemId"))
.rdd.map(v => (v(0).toString,1))
.reduceByKey(_+_)
.sortBy(_._2,false)
.take(10)
val result2 = sc.parallelize(top_10_item).toDF().toJSON.collectAsList().toString
// val writer2 = new PrintWriter(new File("data/practice2/result2.json"))
// writer2.write(result2)
// writer2.close()
//3.购物数量前十的用户信息统计
val top_10_user: Array[(String,Int)] = df.filter(df("action") === "buy").select(df("userId"))
.rdd.map(v => (v(0).toString, 1))
.reduceByKey(_ + _)
.sortBy(_._2, false)
.take(10)
val result3 = sc.parallelize(top_10_user).toDF().toJSON.collectAsList().toString
// val writer3 = new PrintWriter(new File("data/practice2/result3.json"))
// writer3.write(result3)
// writer3.close()
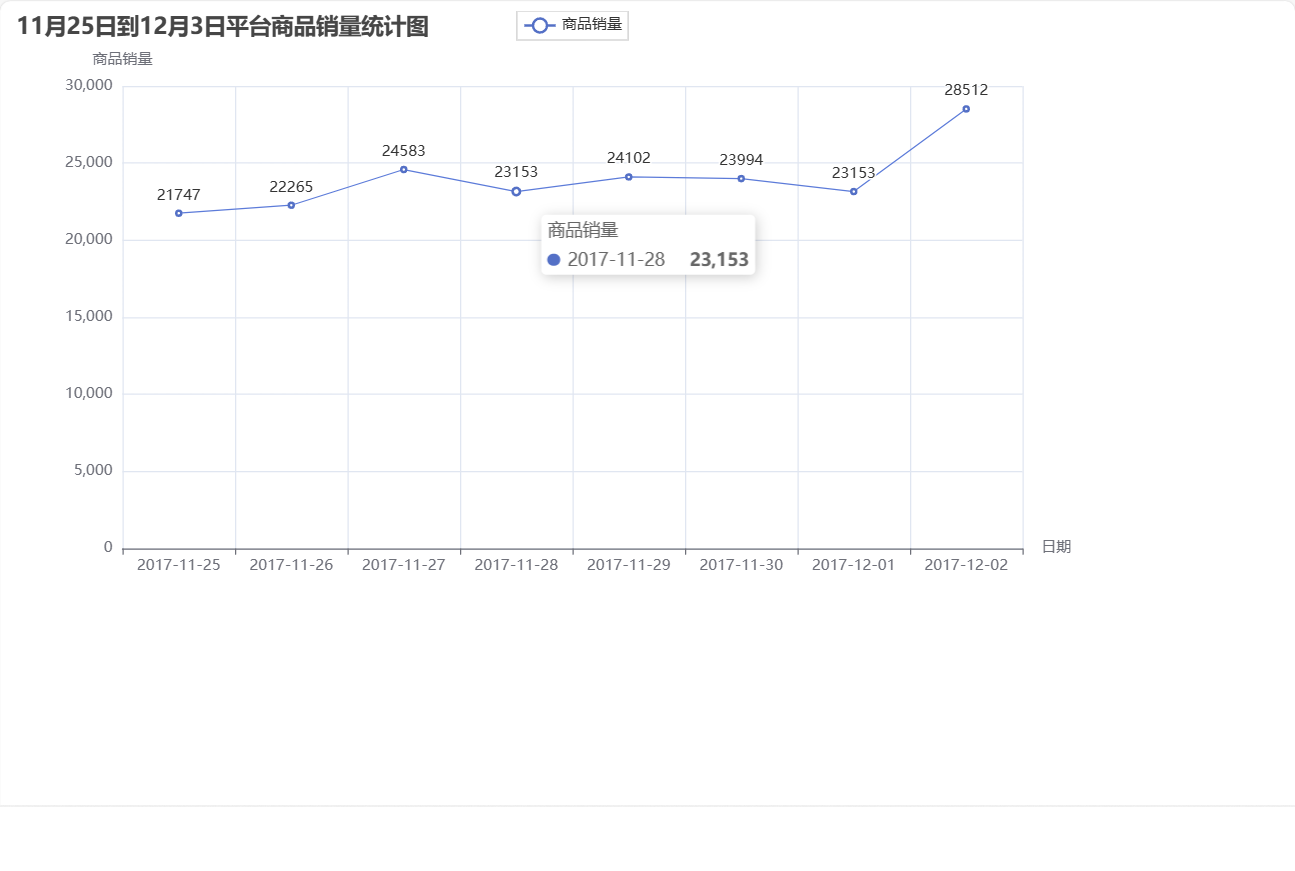
// 4.时间段内平台商品销量统计
val buy_order_by_date: Array[(String,Int)] = df.filter(df("action") === "buy").select(df("time"))
.rdd.map(v => (v.toString().replace("[","").replace("]","").split(" ")(0),1)
).reduceByKey(_+_).sortBy(_._1).collect()
//转为dataframe
// buy_order_by_date.foreach(println)
/*
(2017-11-25,21747)
(2017-11-26,22265)
(2017-11-27,24583)
(2017-11-28,23153)
(2017-11-29,24102)
(2017-11-30,23994)
(2017-12-01,23153)
(2017-12-02,28512)
*/
val result4 = sc.parallelize(buy_order_by_date).toDF().toJSON.collectAsList().toString
val writer4 = new PrintWriter(new File("data/practice2/result4.json"))
writer4.write(result4)
writer4.close()
sc.stop()
spark.stop()
}
}
数据可视化(pyecharts)
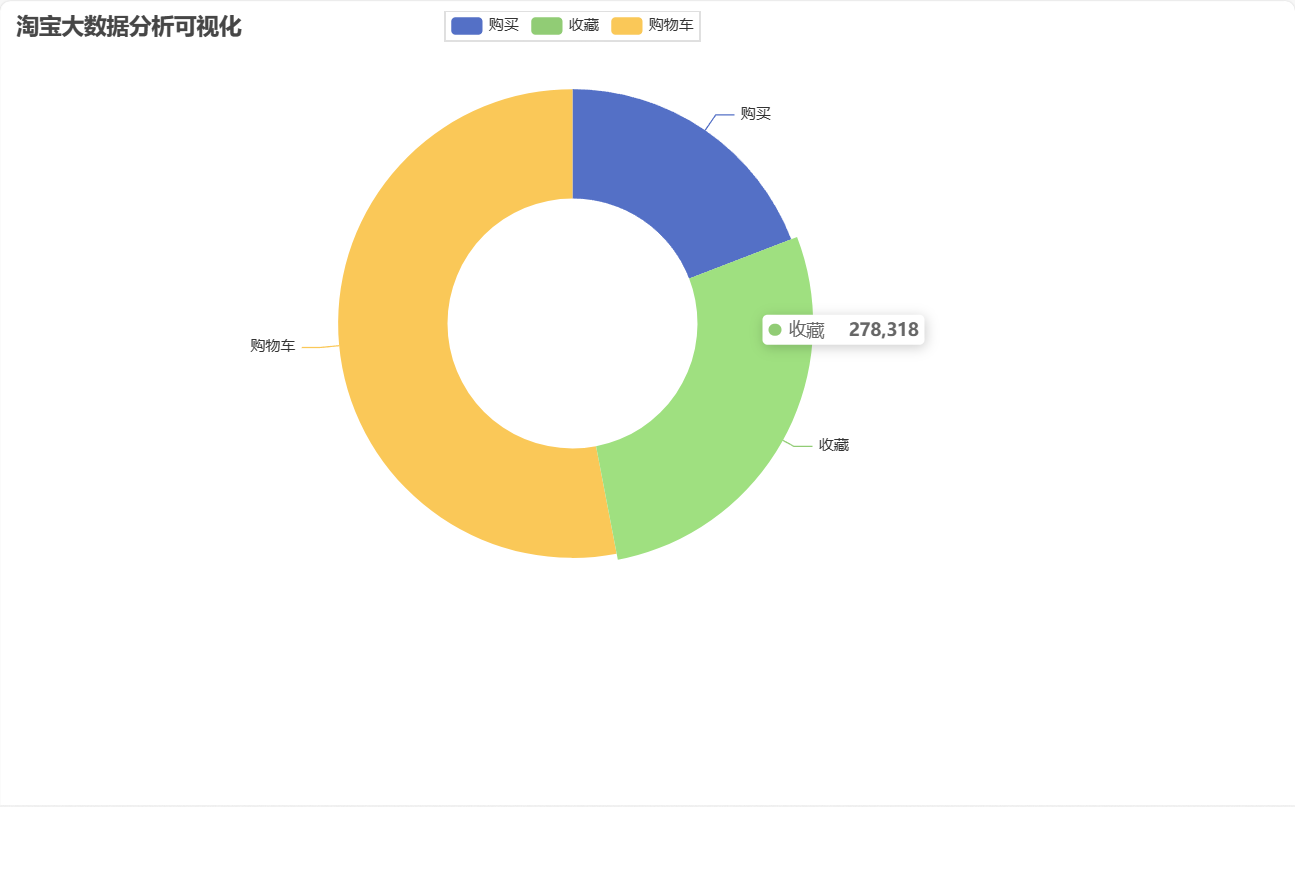
1、 用户行为数据分析
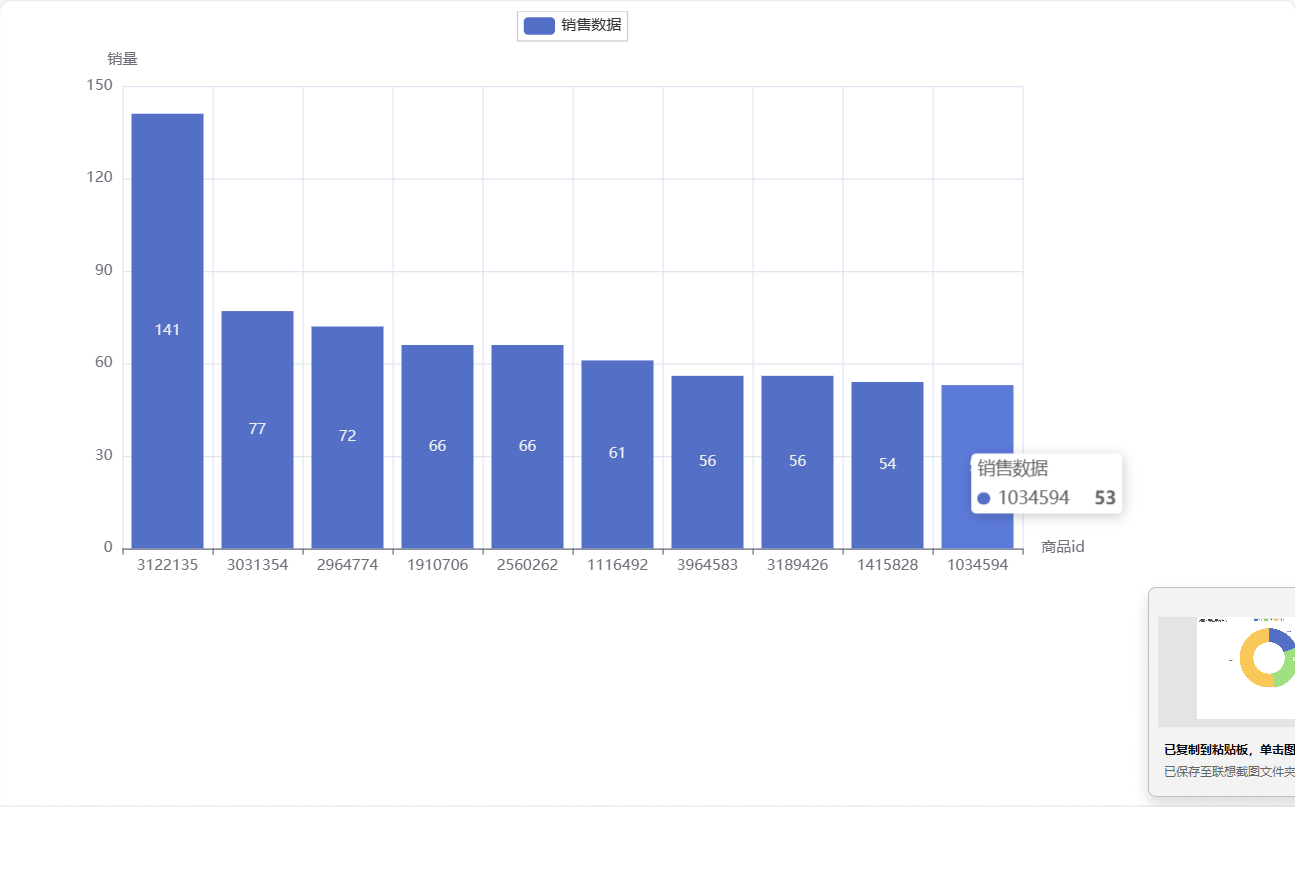
2、销量前 10 的商品数据
3、用户购买量前 10

4、时间段商品销量波动