目录
7.1 定义和推论
7.1.1 非阻塞型数据结构
7.1.2 无锁数据结构
7.1.3 无需等待的数据结构
7.1.4 无锁数据结构的优点和缺点
7.2 无锁数据结构范例
7.2.1 实现线程安全的无锁栈
7.2.2 制止麻烦的内存泄漏:在无锁数据结构中管理内存
7.2.3 运用风险指针检测无法回收的节点
7.2.4 借引用计数检测正在使用中的节点
7.2.5 为无锁容器施加内存模型
7.2.6 实现线程安全的无锁队列
7.3 实现无锁数据结构的原则
7.3.1 原则1:在原型设计中使用std::memory_order_seq_cst次序
7.3.2 原则2:使用无锁的内存回收方案
7.3.3 原则3: 防范ABA问题
7.3.4 原则4:找出忙等循环,协助其他线程
参考:https://github.com/xiaoweiChen/CPP-Concurrency-In-Action-2ed-2019/blob/master/content/chapter7/7.2-chinese.md
7.1 定义和推论
使用互斥量、条件变量,以及future可以用来同步算法和数据结构。调用库函数将会挂起执行线程,直到其他线程完成某个特定动作。库函数将调用阻塞操作来对线程进行阻塞,在阻塞解除前线程无法继续自己的任务。通常,操作系统会完全挂起一个阻塞线程(并将其时间片交给其他线程),直到解阻塞。“解阻塞”的方式很多,比如互斥锁解锁、通知条件变量达成,或让“future状态”就绪。
7.1.1 非阻塞型数据结构
无锁结构的具体定义,这将有助于你判断哪些类型的数据结构是无锁的。这些类型有:
- 无阻碍——如果其他线程都暂停了,任何给定的线程都将在一定时间内完成操作。
- 无锁——如果多个线程对一个数据结构进行操作,经过一定时间后,其中一个线程将完成其操作。
- 无等待——即使有其他线程也在对该数据结构进行操作,每个线程都将在一定的时间内完成操作。
大多数情况下无阻塞算法用的很少——其他线程都暂停的情况太少见了,因此这种方式用于描述一个失败的无锁实现更为合适。
7.1.2 无锁数据结构
无锁结构意味着线程可以并发的访问数据结构,线程不能做相同的操作。一个无锁队列可能允许一个线程压入数据,另一个线程弹出数据,当有两个线程同时添加元素时,将破坏这个数据结构。不仅如此,当调度器中途挂起其中一个访问线程时,其他线程必须能够继续完成自己的工作,而无需等待挂起线程。
具有“比较/交换”操作的数据结构,通常有一个循环。使用“比较/交换”操作的原因:当有其他线程同时对指定的数据进行修改时,代码将尝试恢复数据。当其他线程挂起时,“比较/交换”操作执行成功,这样的代码就是无锁的。当执行失败时,就需要一个自旋锁,且这个结构就是“无阻塞-有锁”的结构。
7.1.3 无需等待的数据结构
无等待数据结构:首先是无锁数据结构,并且每个线程都能在有限的时间内完成操作,暂且不管其他线程是如何工作的。由于可能会和其他线程的行为冲突,从而算法会进行了若干次尝试,因此无法做到无等待。本章的大多数例子都有一种特性——对compare_exchange_weak或compare_exchange_strong操作进行循环,并且循环次数没有上限。操作系统对线程进行进行管理,有些线程的循环次数非常多,有些线程的循环次数就非常少。因此,这些操作不是无等待的。
7.1.4 无锁数据结构的优点和缺点
7.2 无锁数据结构范例
无锁结构依赖于原子操作和内存序,以确保多线程以正确的顺序访问数据结构,原子操作默认使用memory_order_seq_cst内存序。不过,后面的例子中会降低内存序的要求。虽然例子中没有直接使用锁,但需要注意std::atomic_flag。一些平台上无锁结构的实现(实际上在C++标准库中实现)使用了内部锁。另一些平台上,基于锁的简单数据结构可能会更加合适,还有很多平台的实现细节不明确。选择一种实现前,需要明确需求,并且配置各种选项以满足需求。
7.2.1 实现线程安全的无锁栈
代码7.2 不用锁实现push()
template<typename T>
class lock_free_stack
{
private:
struct node
{
T data;
node* next;
node(T const& data_): // 1
data(data_)
{}
};
std::atomic<node*> head;
public:
void push(T const& data)
{
node* const new_node=new node(data); // 2
new_node->next=head.load(); // 3
while(!head.compare_exchange_weak(new_node->next,new_node)); // 4
}
};上面代码能匹配之前的三个步骤:创建一个新节点②,设置新节点的next指针指向当前head③,并设置head指针指向新节点④。node结构用其自身的构造函数来进行数据填充①,必须保证节点在构造完成后能随时弹出。之后需要使用compare_exchange_weak()来保证在被存储到new_node->next的head指针和之前的一样③。代码的亮点是使用“比较/交换”操作:返回false时,因为比较失败(例如,head被其他线程锁修改),会使用head中的内容更新new_node->next(第一个参数)的内容。因为编译器会重新加载head指针,所以循环中不需要每次都重新加载head指针。同样,因为循环可能直接就失败了,所以使用compare_exchange_weak要好于使用compare_exchange_strong(详见第5章)。
7.2.2 制止麻烦的内存泄漏:在无锁数据结构中管理内存
代码7.5 使用引用计数的回收机制
template<typename T>
class lock_free_stack
{
private:
std::atomic<node*> to_be_deleted;
static void delete_nodes(node* nodes)
{
while(nodes)
{
node* next=nodes->next;
delete nodes;
nodes=next;
}
}
void try_reclaim(node* old_head)
{
if(threads_in_pop==1) // 1
{
node* nodes_to_delete=to_be_deleted.exchange(nullptr); // 2 声明“可删除”列表
if(!--threads_in_pop) // 3 是否只有一个线程调用pop()?
{
delete_nodes(nodes_to_delete); // 4
}
else if(nodes_to_delete) // 5
{
chain_pending_nodes(nodes_to_delete); // 6
}
delete old_head; // 7
}
else
{
chain_pending_node(old_head); // 8
--threads_in_pop;
}
}
void chain_pending_nodes(node* nodes)
{
node* last=nodes;
while(node* const next=last->next) // 9 让next指针指向链表的末尾
{
last=next;
}
chain_pending_nodes(nodes,last);
}
void chain_pending_nodes(node* first,node* last)
{
last->next=to_be_deleted; // 10
while(!to_be_deleted.compare_exchange_weak( // 11 用循环来保证last->next的正确性
last->next,first));
}
void chain_pending_node(node* n)
{
chain_pending_nodes(n,n); // 12
}
};回收节点时①,threads_in_pop是1,当前线程对pop()进行访问时,就可以安全的将节点删除⑦(将等待节点删除也是安全的)。当数值不是1时,删除任何节点都不安全,所以需要向等待列表中继续添加节点⑧。
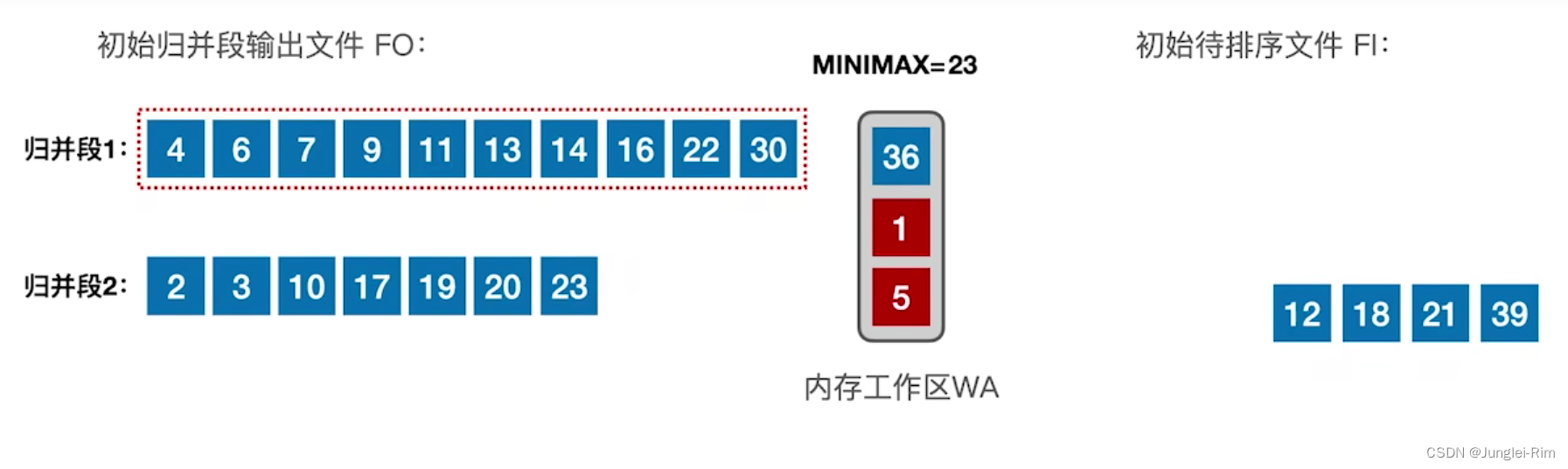
假设某一时刻,threads_in_pop值为1。就可以尝试回收等待列表,如果不回收,节点就会继续等待,直到整个栈被销毁。要做到回收,首先要通过原子exchange操作声明②删除列表,并将计数器减1③。如果之后计数的值为0,意味着没有其他线程访问等待节点链表。不必为出现新的等待节点而烦恼,因为它们会安全的回收。而后,可以使用delete_nodes对链表进行迭代,并将其删除④。
计数值在减后不为0时,回收节点就不安全。如果存在⑤,就需要将其挂在等待删除链表后⑥,这种情况会发生在多个线程同时访问数据结构的时候。一些线程在第一次测试threads_in_pop①和对“回收”链表的声明②操作间调用pop(),这可能会将已经访问的节点新填入到链表中。图7.1中,线程C添加节点Y到to_be_deleted链表中,即使线程B仍将其引用作为old_head,之后会尝试访问其next指针。线程A删除节点时,会造成线程B发生未定义行为。

7.2.3 运用风险指针检测无法回收的节点
“风险指针”这个术语引用于Maged Michael的研究[1],之所以这样叫是因为删除一个节点可能会让其他引用线程处于危险状态。其他线程持有已删除节点的指针对其进行解引用操作时,会出现未定义行为。基本观点就是,当有线程去访问(其他线程)删除的对象时,会先对这个对象设置风险指针,而后通知其他线程——使用这个指针是危险的行为。当这个对象不再需要,就可以清除风险指针。
std::shared_ptr<T> pop()
{
std::atomic<void*>& hp=get_hazard_pointer_for_current_thread();
node* old_head=head.load(); // 1
node* temp;
do
{
temp=old_head;
hp.store(old_head); // 2
old_head=head.load();
} while(old_head!=temp); // 3
// ...
}while循环能保证node不会在读取旧head指针①时,以及设置风险指针②时被删除。这种模式下,其他线程不知道有线程对这个节点进行了访问。幸运的是,旧head节点要删除时,head本身会发生变化,所以需要对head进行检查并持续循环,直到head指针中的值与风险指针中的值相同③。使用默认的new和delete操作对风险指针进行操作时,会出现未定义行为,所以需要确定实现是否支持这样的操作,或使用自定义内存分配器来保证用法的正确性
7.2.4 借引用计数检测正在使用中的节点
代码7.12 使用分离引用计数从无锁栈中弹出一个节点
template<typename T>
class lock_free_stack
{
private:
void increase_head_count(counted_node_ptr& old_counter)
{
counted_node_ptr new_counter;
do
{
new_counter=old_counter;
++new_counter.external_count;
}
while(!head.compare_exchange_strong(old_counter,new_counter)); // 1
old_counter.external_count=new_counter.external_count;
}
public:
std::shared_ptr<T> pop()
{
counted_node_ptr old_head=head.load();
for(;;)
{
increase_head_count(old_head);
node* const ptr=old_head.ptr; // 2
if(!ptr)
{
return std::shared_ptr<T>();
}
if(head.compare_exchange_strong(old_head,ptr->next)) // 3
{
std::shared_ptr<T> res;
res.swap(ptr->data); // 4
int const count_increase=old_head.external_count-2; // 5
if(ptr->internal_count.fetch_add(count_increase)== // 6
-count_increase)
{
delete ptr;
}
return res; // 7
}
else if(ptr->internal_count.fetch_sub(1)==1)
{
delete ptr; // 8
}
}
}
};7.2.5 为无锁容器施加内存模型
7.2.6 实现线程安全的无锁队列
代码7.16 使用带有引用计数tail,实现的无锁队列中的push()
template<typename T>
class lock_free_queue
{
private:
struct node;
struct counted_node_ptr
{
int external_count;
node* ptr;
};
std::atomic<counted_node_ptr> head;
std::atomic<counted_node_ptr> tail; // 1
struct node_counter
{
unsigned internal_count:30;
unsigned external_counters:2; // 2
};
struct node
{
std::atomic<T*> data;
std::atomic<node_counter> count; // 3
counted_node_ptr next;
node()
{
node_counter new_count;
new_count.internal_count=0;
new_count.external_counters=2; // 4
count.store(new_count);
next.ptr=nullptr;
next.external_count=0;
}
};
public:
void push(T new_value)
{
std::unique_ptr<T> new_data(new T(new_value));
counted_node_ptr new_next;
new_next.ptr=new node;
new_next.external_count=1;
counted_node_ptr old_tail=tail.load();
for(;;)
{
increase_external_count(tail,old_tail); // 5
T* old_data=nullptr;
if(old_tail.ptr->data.compare_exchange_strong( // 6
old_data,new_data.get()))
{
old_tail.ptr->next=new_next;
old_tail=tail.exchange(new_next);
free_external_counter(old_tail); // 7
new_data.release();
break;
}
old_tail.ptr->release_ref();
}
}
};代码7.17 使用尾部引用计数,将节点从无锁队列中弹出
template<typename T>
class lock_free_queue
{
private:
struct node
{
void release_ref();
};
public:
std::unique_ptr<T> pop()
{
counted_node_ptr old_head=head.load(std::memory_order_relaxed); // 1
for(;;)
{
increase_external_count(head,old_head); // 2
node* const ptr=old_head.ptr;
if(ptr==tail.load().ptr)
{
ptr->release_ref(); // 3
return std::unique_ptr<T>();
}
if(head.compare_exchange_strong(old_head,ptr->next)) // 4
{
T* const res=ptr->data.exchange(nullptr);
free_external_counter(old_head); // 5
return std::unique_ptr<T>(res);
}
ptr->release_ref(); // 6
}
}
};代码7.21 修改pop()帮助push()完成工作
template<typename T>
class lock_free_queue
{
private:
struct node
{
std::atomic<T*> data;
std::atomic<node_counter> count;
std::atomic<counted_node_ptr> next; // 1
};
public:
std::unique_ptr<T> pop()
{
counted_node_ptr old_head=head.load(std::memory_order_relaxed);
for(;;)
{
increase_external_count(head,old_head);
node* const ptr=old_head.ptr;
if(ptr==tail.load().ptr)
{
return std::unique_ptr<T>();
}
counted_node_ptr next=ptr->next.load(); // 2
if(head.compare_exchange_strong(old_head,next))
{
T* const res=ptr->data.exchange(nullptr);
free_external_counter(old_head);
return std::unique_ptr<T>(res);
}
ptr->release_ref();
}
}
};代码7.22 无锁队列中简单的帮助性push()的实现
template<typename T>
class lock_free_queue
{
private:
void set_new_tail(counted_node_ptr &old_tail, // 1
counted_node_ptr const &new_tail)
{
node* const current_tail_ptr=old_tail.ptr;
while(!tail.compare_exchange_weak(old_tail,new_tail) && // 2
old_tail.ptr==current_tail_ptr);
if(old_tail.ptr==current_tail_ptr) // 3
free_external_counter(old_tail); // 4
else
current_tail_ptr->release_ref(); // 5
}
public:
void push(T new_value)
{
std::unique_ptr<T> new_data(new T(new_value));
counted_node_ptr new_next;
new_next.ptr=new node;
new_next.external_count=1;
counted_node_ptr old_tail=tail.load();
for(;;)
{
increase_external_count(tail,old_tail);
T* old_data=nullptr;
if(old_tail.ptr->data.compare_exchange_strong( // 6
old_data,new_data.get()))
{
counted_node_ptr old_next={0};
if(!old_tail.ptr->next.compare_exchange_strong( // 7
old_next,new_next))
{
delete new_next.ptr; // 8
new_next=old_next; // 9
}
set_new_tail(old_tail, new_next);
new_data.release();
break;
}
else // 10
{
counted_node_ptr old_next={0};
if(old_tail.ptr->next.compare_exchange_strong( // 11
old_next,new_next))
{
old_next=new_next; // 12
new_next.ptr=new node; // 13
}
set_new_tail(old_tail, old_next); // 14
}
}
}
};个人理解:通过else解决多线程调用push()阻塞的问题。
7.3 实现无锁数据结构的原则
7.3.1 原则1:在原型设计中使用std::memory_order_seq_cst次序
std::memory_order_seq_cst比起其他内存序要简单的多,因为所有操作都将其作为总序。本章的所有例子,都是从std::memory_order_seq_cst开始,只有当基本操作正常工作的时候,才放宽内存序的选择。这种情况下,使用其他内存序就是优化(早期可以不用这样做)。通常,了解整套代码对数据结构的操作后,才能决定是否要放宽内存序的选择。所以,尝试放宽选择,可能会轻松一些。测试通过后,工作代码可能会很复杂(不过,不能完全保证内存序正确)。除非你有一个算法检查器,可以系统的测试,线程能看到的所有可能性组合,这样就能保证指定内存序的正确性(这样的测试的确存在)。
7.3.2 原则2:使用无锁的内存回收方案
与无锁代码最大的区别就是内存管理。当线程对节点进行访问的时候,线程无法删除节点。为避免内存的过多使用,还是希望这个节点能在删除的时候尽快删除。本章中介绍了三种技术来保证内存可以安全回收:
-
等待无线程对数据结构进行访问时,删除所有等待删除的对象。
-
使用风险指针来标识正在访问的对象。
-
对对象进行引用计数,当没有线程对对象进行引用时将其删除。
所有例子的想法都是使用一种方式去跟踪指定对象上的线程访问数量。无锁数据结构中,还有很多方式可以用来回收内存,例如:理想情况下使用一个垃圾收集器,比起算法来说更容易实现一些。只需要让回收器知道,当节点没引用的时就回收节点。
其他替代方案就是循环使用节点,只在数据结构销毁时才将节点完全删除。因为节点能复用,这样就不会有非法的内存,所以就能避免未定义行为的发生。这种方式的缺点,就是会产生“ABA问题”。
7.3.3 原则3: 防范ABA问题
基于“比较/交换”的算法中要格外小心“ABA问题”。其流程是:
- 线程1读取原子变量x,并且发现其值是A。
- 线程1对这个值进行一些操作,比如,解引用(当其是一个指针的时候),或做查询,或其他操作。
- 操作系统将线程1挂起。
- 其他线程对x执行一些操作,并且将其值改为B。
- 另一个线程对A相关的数据进行修改(线程1持有),让其不再合法。可能会在释放指针指向的内存时,代码产生剧烈的反应(大问题),或者只是修改了相关值而已(小问题)。
- 再来一个线程将x的值改回为A。如果A是一个指针,那么其可能指向一个新的对象,只是与旧对象共享同一个地址而已。
- 线程1继续运行,并且对x执行“比较/交换”操作,将A进行对比。这里,“比较/交换”成功(因为其值还是A),不过这是一个错误的A(the wrong A value)。从第2步中读取的数据不再合法,但是线程1无法言明这个问题,并且之后的操作将会损坏数据结构。
7.3.4 原则4:找出忙等循环,协助其他线程
最终队列的例子中,已经见识到线程在执行push操作时,必须等待另一个push操作流程的完成。这样等待线程就会陷入到忙等待循环中,当线程尝试失败时会继续循环,这会浪费CPU的计算周期。忙等待循环结束时,就像解阻塞操作和使用互斥锁的行为一样。通过对算法的修改,当之前的线程还没有完成操作前,让等待线程执行未完成的步骤,就能让忙等待的线程不再阻塞。队列示例中需要将一个数据成员转换为原子变量,而不是使用非原子变量和使用“比较/交换”操作来做这件事。要在更加复杂的数据结构中进行使用,需要更多的变化来满足需求。