前言
这里主要是 探究一下 explain $sql 中各个 type
诸如 const, ref, range, index, all 的查询的影响, 以及一个初步的效率的判断
这里会调试源码来看一下 各个类型的查询 需要 lookUp 的记录
以及 相关的差异
此系列文章建议从 mysql const 查询 开始看
测试表结构信息如下
CREATE TABLE `tz_test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3333343 DEFAULT CHARSET=utf8
测试数据为序列 1 – 99
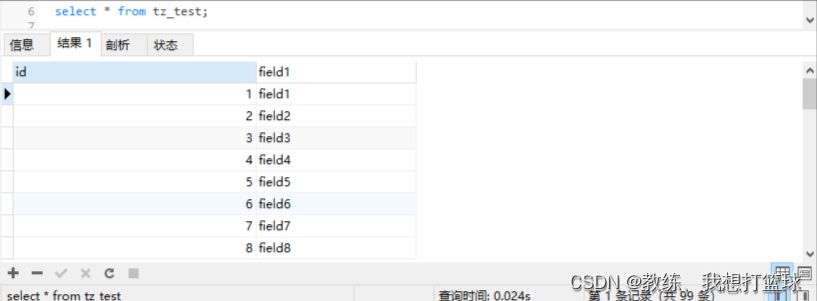
range 查询存在的记录
执行查询如下 “select * from tz_test where field1 > 'field33' and field1 < 'field37';”
optimize 的时候, 根据索引定位了 ”field33” 和 “field37” 的位置

第一次查询是从索引 ‘field34’ -> 34 开始, 然后 row_search_idx_cond_check 来判断当前记录是否满足条件
比较的方式是当前记录的给定的字段 是否属于给定的区间, 因为是顺序往下遍历, 只需要判断是否超出了 右边界 即可
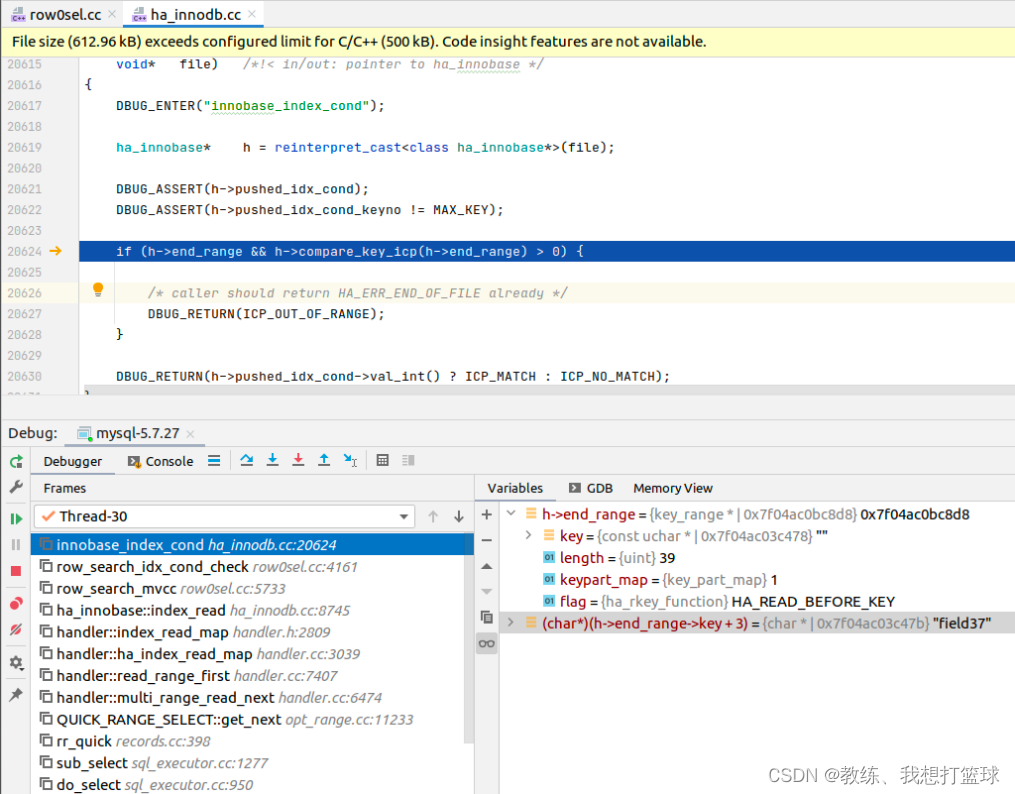
这里是将 rec 转换为 mysql_rec 的地方
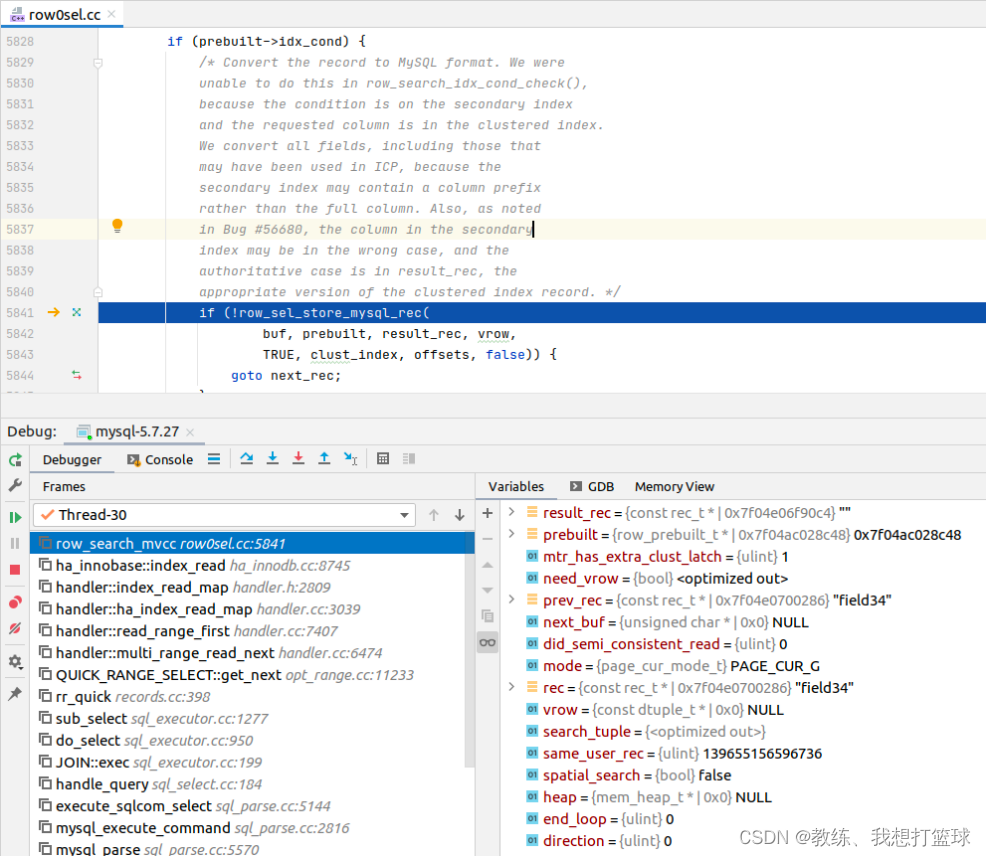
这里根据索引的区间判断是没有使用到 prebuilt->fetch_cache 的
然后在迭代的过程中会依次比较 “field36”-> 36, “field37”->37 的记录信息, id 为 35 的记录 field1 为 “field33”, 索引是按照顺序排列的, 因此是不会遍历到索引 “field33” -> 35 -
迭代到 “field36” -> 36 的时候满足条件, 因此获取给定的记录返回回去
迭代到 “field37” -> 37 的时候, 一边是索引记录的值 “field37”, 另外一边是查询条件中的 “field37”
然后这里比较 两者相等, 外面根据查询条件是否包含 “等于”, 来更新这里的比较结果
来符合我们的一个 “<”/”<=” 的一个计算需求
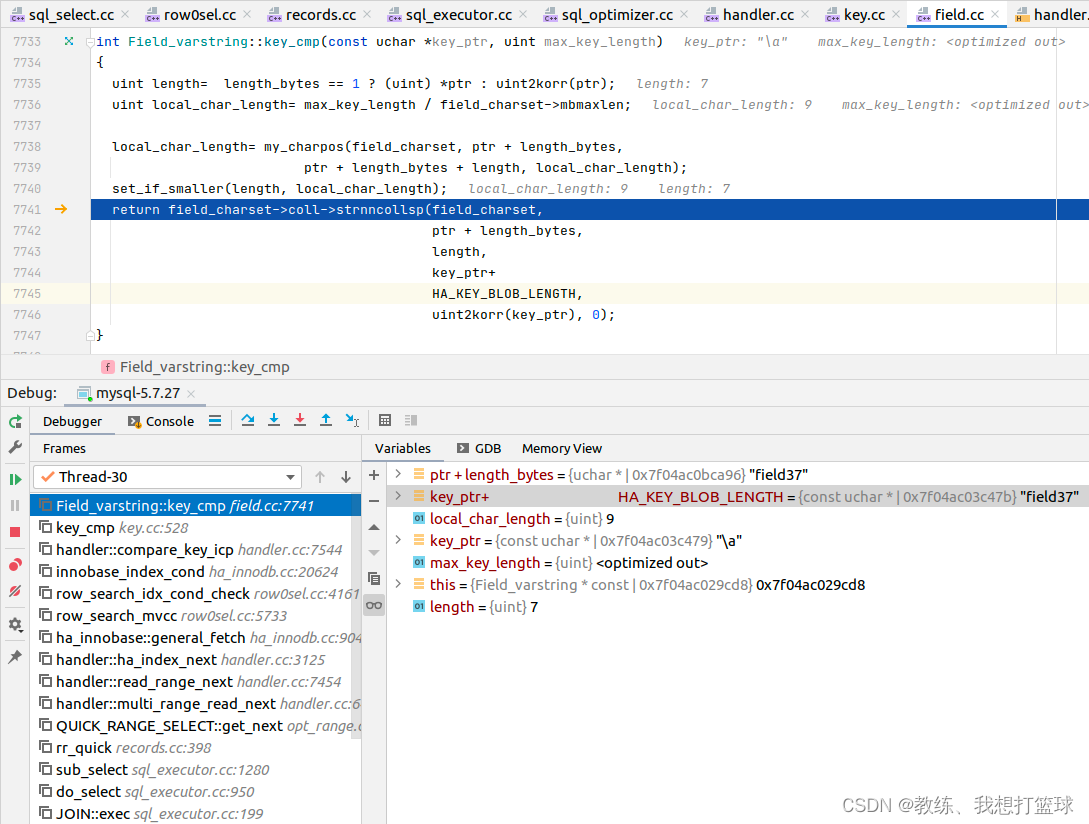
我们这里查询条件为 “field1 < 'field37';”, 因此在 “field37” = “field37” 的场景下面是不满足需求的, 因此这里设置了一个 如果两者相等的时候的一个默认值, 这里为 1 表示 OUT_OF_RANGE
key_compare_result_on_equal 是在之前设置的, 根据查询条件动态调整
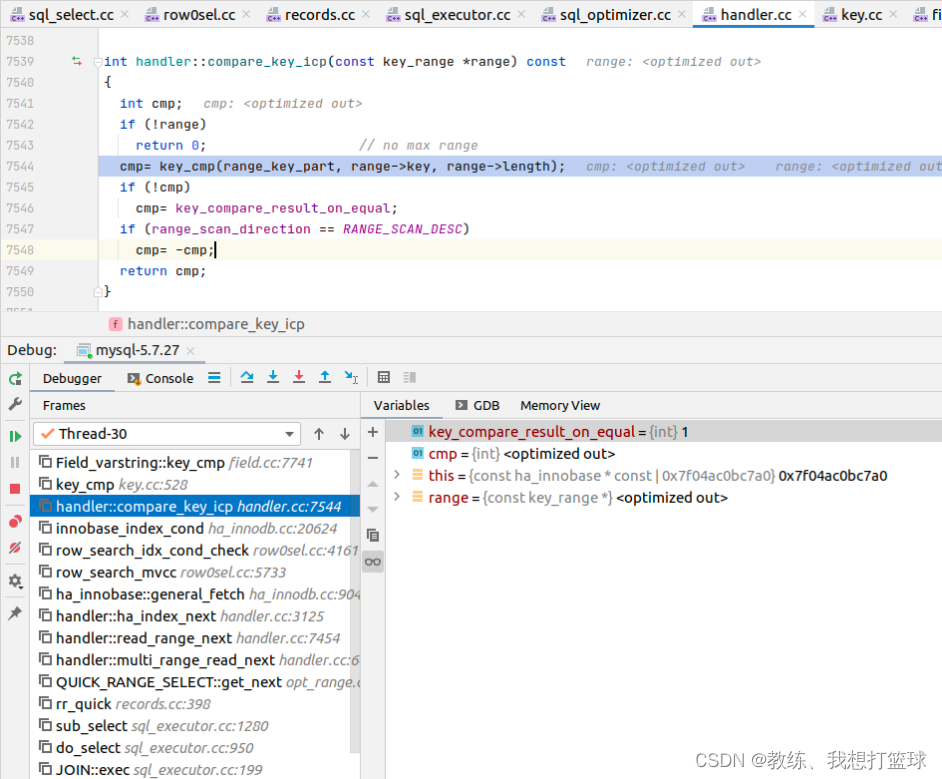
然后外层 row_search_mvcc 控制着外层跳出循环

然后外层 sub_select 跳出循环

range 使用索引 or 不使用索引 ?
假设执行查询如下 “select * from tz_test where field1 > 'field33';”
这里比较的两个 estimate, 一个应该是 全表扫描 的开销, 另外一个是使用 field1 索引的开销
cost 的 io_cost 为扫描的记录数量, cpu_cost 为计算的 cpu 开销
allTableEstimate 的计算方式不太清楚, 这里合计为 23[每次计算可能有所差异, 我们这里仅仅以这次调试为例], 所以 可以推导出的是如果 range 查询记录数量超过了 23 是肯定使用 全表扫描

假设执行查询如下 “select * from tz_test where field1 > 'field97';”
这里很显然就会使用 field1 字段的 range 查询
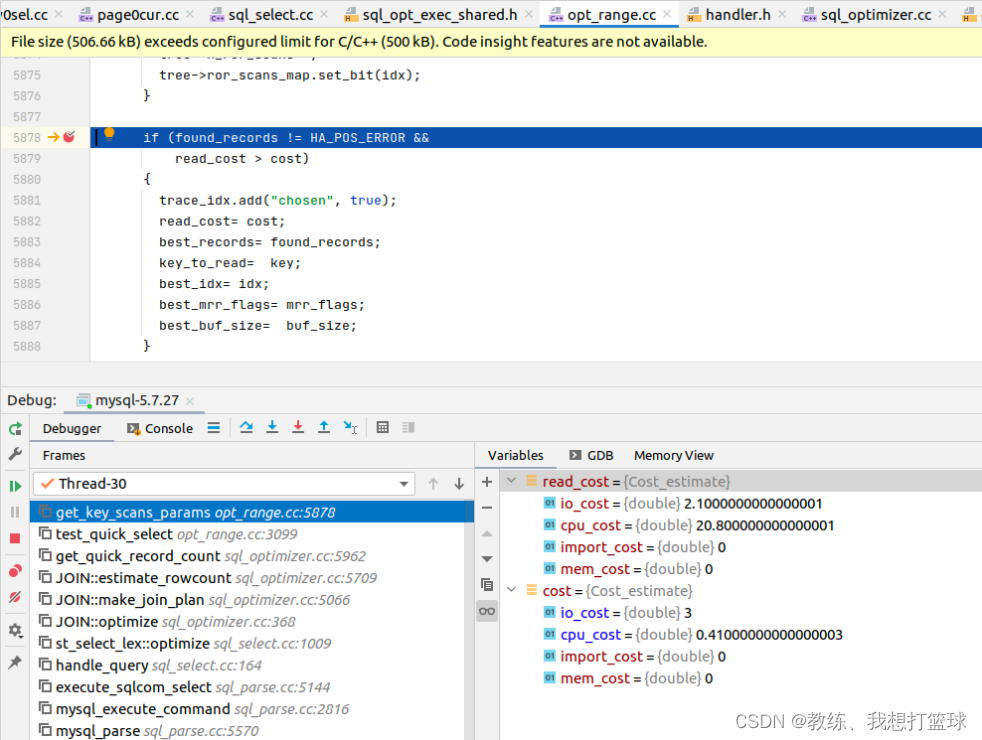
假设执行查询如下 “select * from tz_test where field1 > 'field81';”
选择全表扫描

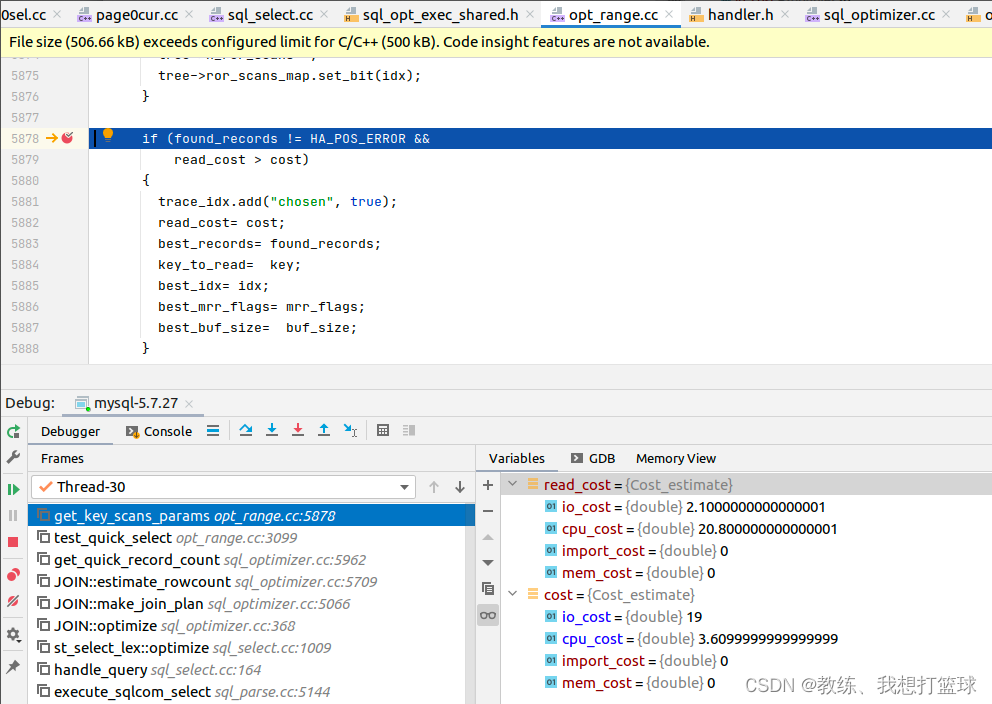
假设执行查询如下 “select * from tz_test where field1 > 'field82';”
选择索引查询
完