文章中所有内容仅供学习交流使用,不用于其他任何目的!严禁将文中内容用于任何商业与非法用途,由此产生的一切后果与作者无关。若有侵权,请联系删除。
目标:去哪儿网指定城市人气值最高的15个景点评论数据采集
地址:aHR0cHM6Ly9waWFvLnF1bmFyLmNvbS90aWNrZXQvbGlzdC5odG0/a2V5d29yZD0lRTUlOEMlOTclRTQlQkElQUMmcGFnZT0xJnNvcnQ9cHA=

进入主页之后可以看到每一个景点是根据推荐来进行排序的,所以我们如果要获取人气值最高的景点的话需要获取人气排序时的url,点击根据人气排序即可。

其在url中的体现主要是查询参数sort的值的改变。

通过抓包预览不难发现在当前页面中各景点的详情页url是位于静态html中的,所以我们考虑使用xpath来解析详情页的url。

这部分代码如下
def index_request(url):
"""请求主页获取每一个景点的详情页面url"""
response = requests.get(url, params=params, headers=headers)
text_html = response.content.decode()
tree = etree.HTML(text_html)
div_list = tree.xpath('//*[@id="search-list"]/div') # 各个景点所在的所有div标签,需要提取出各个景点的详情页面的url
for div in div_list:
detail_url = 'https://piao.qunar.com' + div.xpath('./div[1]/div[2]/h3/a/@href')[0]
detail_request(detail_url)
注意:该站点对Cookie有最基础的检测,所以代码中需要携带上Cookie进行请求。
在获取到详情页的url之后,就需要对详情页进行分析,寻找一下用户评论是如何获取的。首先来观察静态页面,在其中我们是无法看到用户评论的,所以初步断定用户评论是异步加载的数据。

切到xhr中分析,包并不多,可以直接搜索关键字快速定位也可以一个个查看。

定位到之后分析一下这个包的请求接口在请求的时候可能传递的参数。

可以看到的是一共传递了5个参数,其中page表示的是页数,这个毫无疑问;pageSize表示每页多少条数据,这个参数是不用修改的。其他参数就需要我们去访问不同页面进行分析了,接下来我们翻到第二页看一下两次访问有什么不同。

可以看到两页不同的请求变化的参数为index和page,再多访问几页也是一样的结果,所以断定index随page变化而同步变化。最后剩下sightId这个参数,这个参数如果有经验的话其实可以断定其是某个景点在这个站点中的唯一ID。就算不知道的话我们也可以来直接搜索一下这个值,因为该值在多次访问的时候是没有发生变化的,所以直接全局搜索即可。
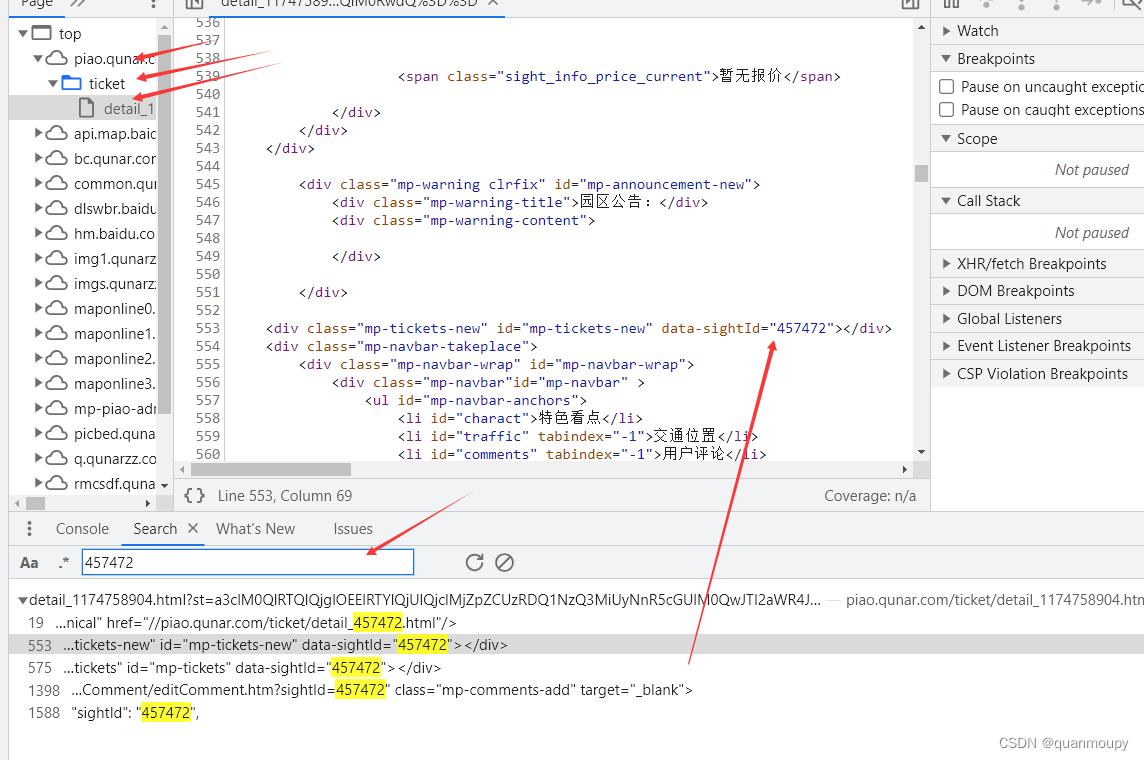
这样来看就非常明显了,这个值就是从静态页面中可以直接提取的,那么我们就需要先访问详情页面将sightId值解析出来作为评论接口的参数。最后请求评论接口以获取评论信息并保存即可。
完整代码请移步:https://gitee.com/shuailiuquan/spider-code/tree/master/