安装mysql主从复制
主从搭建步骤
1.1 新建主服务器容器实例3307
docker run -p 3307:3306 --name mysql-master #3307映射到3306,容器名为mysql-master
-v /app/mysql/mydata/mysql-master/log:/var/log/mysql #容器数据卷
-v /app/mysql/mydata/mysql-master/data:/var/lib/mysql
-v /app/mysql/mydata/mysql-master/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root # -e配置环境,配置了root的密码为root
-d mysql:5.7
完整命令
docker run -p 3307:3306 --name mysql-master -v /app/mysql/mydata/mysql-master/log:/var/log/mysql -v /app/mysql/mydata/mysql-master/data:/var/lib/mysql -v /app/mysql/mydata/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
2、进入/mydata/mysql-master/conf目录下新建my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
3、修改完配置后重启master实例
docker restart mysql-master
4、进入mysql-master容器
[root@centos100 conf]# docker exec -it mysql-master /bin/bash
root@b58afbb1ac1a:/# mysql -uroot -p
Enter password:
...
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql | <--上面配置不需要同步的数据库名称mysql,指的就是这个库
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
5、master容器实例内创建数据同步用户
#创建一个用户
mysql> create user 'slave'@'%' identified by '123456';
Query OK, 0 rows affected (0.03 sec)
#授权
mysql> grant replication slave,replication client on *.* to 'slave'@'%';
Query OK, 0 rows affected (0.00 sec)
6、新建从服务器容器3308
docker run -p 3308:3306 --name mysql-slave #端口映射,3308映射到3306,修改容器名为mysql-slave
-v /app/mysql/mydata/mysql-slave/log:/var/log/mysql #添加容器卷
-v /app/mysql/mydata/mysql-slave/data:/var/lib/mysql
-v /app/mysql/mydata/mysql-slave/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root #创建root密码为root
-d mysql:5.7 #镜像名
完整命令
docker run -p 3308:3306 --name mysql-slave -v /app/mysql/mydata/mysql-slave/log:/var/log/mysql -v /app/mysql/mydata/mysql-slave/data:/var/lib/mysql -v /app/mysql/mydata/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.7
7、进入/app/mysql/mydata/mysql-slave/conf目录下新建my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
8、修改完配置后重启slave实例
docker restart mysql-slave
9、在主数据库中查看主从同步状态
[root@centos100 conf]# docker exec -it mysql-master /bin/bash
root@b58afbb1ac1a:/# mysql -uroot -p
Enter password:
...
mysql> show master status;
+-----------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------------+----------+--------------+------------------+-------------------+
| mall-mysql-bin.000001 | 617 | | mysql | |
+-----------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
10、进入mysql-slave容器
[root@centos100 conf]# docker exec -it mysql-slave /bin/bash
root@ee7d461daf7f:/# mysql -uroot -p
Enter password:
11、在从数据库中配置主从复制
change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30;
主从复制命令参数说明
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。
12、在从数据库中查看主从同步状态
show slave status\G;
13、在从数据库开启主从同步
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
执行这个命令之前,在12步时可以看到
Slave_IO_Running: No
Slave_SQL_Running: No
当执行成功后
Slave_IO_Running: Yes
14、查看从数据库状态发现已经同步
15、主从复制测试
主机创建库、表
mysql> create database db01;
Query OK, 1 row affected (0.00 sec)
mysql> use db01;
Database changed
mysql> create table t1(id int,name varchar(12));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t1 values (1,'zhangsan');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t1;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
+------+----------+
1 row in set (0.00 sec)
从机
mysql> use db01;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from t1;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
+------+----------+
1 row in set (0.00 sec)
1.2 安装Redis集群
cluster(集群)模式-docker版
哈希槽分区进行亿级数据存储
1.2.1 面试题:1~2亿条数据需要缓存,请问应该怎样设计
单机单台100%不可能,肯定是分布式存储,用redis如何落地?
1. 哈希取余分区
1.1 2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
1.2 优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
1.3 缺点:
原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
2. 一致性哈希算法分区
2.1 是什么
一致性Hash算法背景:一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
2.2 能干啥
提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
2.3 三大步骤
2.3.1 一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
2.3.2 节点映射
将集群中各个IP节点映射到环上的某一个位置。将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip))
2.3.3 key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
2.4 优点
2.4.1 解决了一致性哈希算法的容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
2.4.2 解决了一致性哈希算法的扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
2.5 缺点
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题
2.6 总结
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点:
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点 :
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
3. 哈希槽分区
3.1 为什么会出现
解决一致性哈希算法的数据倾斜问题
哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
3.2 能干什么
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
3.3 有多少个hash槽
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
3.4 哈希槽计算
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上
1.2.2 三主三从集群配置步骤
1、新建6个docker容器实例
docker run -d #创建并运行docker容器实例
--name redis-node-1 #容器名字
--net host #使用宿主机的ip端口,默认
--privileged=true #获取宿主机的用户权限
-v /app/redis/share/redis-node-1:/data #容器卷 宿主机地址:docker内部地址
redis #redis镜像
--cluster-enabled yes #开启redis集群
--appendonly yes #开启持久化
--port 6381 #redis端口
docker run -d --name redis-node-1 --net host --privileged=true -v /app/redis/share/redis-node-1:/data redis --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /app/redis/share/redis-node-2:/data redis --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /app/redis/share/redis-node-3:/data redis --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /app/redis/share/redis-node-4:/data redis --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /app/redis/share/redis-node-5:/data redis --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /app/redis/share/redis-node-6:/data redis --cluster-enabled yes --appendonly yes --port 6386
2、进入容器redis-node-1并为6台机器构建集群关系
//注意,进入docker容器后才能执行一下命令,且注意自己的真实IP地址
redis-cli --cluster create 192.168.75.100:6381 192.168.75.100:6382 192.168.75.100:6383 192.168.75.100:6384 192.168.75.100:6385 192.168.75.100:6386 --cluster-replicas 1
--cluster-replicas 1 表示为每个master创建一个slave节点
[root@centos100 ~]# docker exec -it redis-node-1 /bin/bash
root@centos100:/data# redis-cli --cluster create 192.168.75.100:6381 192.168.75.100:6382 192.168.75.100:6383 192.168.75.100:6384 192.168.75.100:6385 192.168.75.100:6386 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.75.100:6385 to 192.168.75.100:6381
Adding replica 192.168.75.100:6386 to 192.168.75.100:6382
Adding replica 192.168.75.100:6384 to 192.168.75.100:6383
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381
slots:[0-5460] (5461 slots) master
M: c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382
slots:[5461-10922] (5462 slots) master
M: 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383
slots:[10923-16383] (5461 slots) master
S: 16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384
replicates c71627fc6d20b9ca61fca76d1fd7e0adab02ec48
S: 7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385
replicates 1f37845789f52b4713200bbc4bc89dbad1fdfdf5
S: 1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386
replicates 08df796c1908646c721bf261d01604cfcde0bdec
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 192.168.75.100:6381)
M: 08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384
slots: (0 slots) slave
replicates c71627fc6d20b9ca61fca76d1fd7e0adab02ec48
M: c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386
slots: (0 slots) slave
replicates 08df796c1908646c721bf261d01604cfcde0bdec
S: 7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385
slots: (0 slots) slave
replicates 1f37845789f52b4713200bbc4bc89dbad1fdfdf5
M: 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
root@centos100:/data#
3、链接进入6381作为切入点,查看集群状态
root@centos100:/data# redis-cli -p 6381
127.0.0.1:6381> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #6个节点
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:188
cluster_stats_messages_pong_sent:198
cluster_stats_messages_sent:386
cluster_stats_messages_ping_received:193
cluster_stats_messages_pong_received:188
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:386
127.0.0.1:6381> cluster nodes
16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384@16384 slave c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 0 1653649433792 2 connected
c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382@16382 master - 0 1653649433000 2 connected 5461-10922
1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386@16386 slave 08df796c1908646c721bf261d01604cfcde0bdec 0 1653649430699 1 connected
7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385@16385 slave 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 0 1653649432000 3 connected
1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383@16383 master - 0 1653649432777 3 connected 10923-16383
08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381@16381 myself,master - 0 1653649431000 1 connected 0-5460
#根据输出结果来看 1 -> 6 2 -> 4 3 -> 5
127.0.0.1:6381>

1.2.3 主从容错切换迁移案例
数据读写存储
1、通过exec进入一台redis
[root@centos100 ~]# docker exec -it redis-node-1 /bin/bash
root@centos100:/data# redis-cli -p 6381
127.0.0.1:6381> keys *
(empty array)
2、对6381新增几个key
127.0.0.1:6381> set k1 v1
(error) MOVED 12706 192.168.75.100:6383
127.0.0.1:6381> set k2 v2
OK
127.0.0.1:6381> set k3 v3
OK
127.0.0.1:6381> set k4 v4
(error) MOVED 8455 192.168.75.100:6382
127.0.0.1:6381>
3、防止路由器失效,添加参数-c
root@centos100:/data# redis-cli -p 6381 -c
127.0.0.1:6381> flushall
OK
127.0.0.1:6381> set vi k1
-> Redirected to slot [8048] located at 192.168.75.100:6382
OK
192.168.75.100:6382> set k2 v2
-> Redirected to slot [449] located at 192.168.75.100:6381
OK
192.168.75.100:6381> set k3 v3
OK
192.168.75.100:6381> set k4 v4
-> Redirected to slot [8455] located at 192.168.75.100:6382
OK
4、查看集群信息
redis-cli --cluster check 192.168.75.100:6381
1.2.4 主从容错的切换迁移
1、主6381和从机切换,先停止6381
[root@centos100 ~]# docker stop redis-node-1
redis-node-1
2、再次查看集群信息
[root@centos100 ~]# docker exec -it redis-node-2 /bin/bash
root@centos100:/data# redis-cli -p 6382 -c
127.0.0.1:6382> cluster nodes
1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386@16386 master - 0 1653652908000 7 connected 0-5460
c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382@16382 myself,master - 0 1653652904000 2 connected 5461-10922
08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381@16381 master,fail - 1653652828089 1653652822986 1 disconnected
1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383@16383 master - 0 1653652906922 3 connected 10923-16383
7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385@16385 slave 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 0 1653652908000 3 connected
16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384@16384 slave c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 0 1653652908967 2 connected

3、还原之前的3主3从
[root@centos100 ~]# docker start redis-node-1
redis-node-1
[root@centos100 ~]# docker exec -it redis-node-1 /bin/bash
root@centos100:/data# redis-cli -p 6381 -c
127.0.0.1:6381> cluster nodes
16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384@16384 slave c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 0 1653653200093 2 connected
7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385@16385 slave 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 0 1653653202126 3 connected
1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383@16383 master - 0 1653653203142 3 connected 10923-16383
c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382@16382 master - 0 1653653201111 2 connected 5461-10922
1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386@16386 master - 0 1653653200000 7 connected 0-5460
08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381@16381 myself,slave 1240de80a446da678036b886d11beddee60c6ba3 0 1653653201000 7 connected
停止6386
[root@centos100 ~]# docker stop redis-node-6
redis-node-6
再启动6386
[root@centos100 ~]# docker start redis-node-6
redis-node-6
查看集群状态
redis-cli --cluster check 192.168.75.100:6381
1.2.5 主从扩容案例
1、新建6387、6388两个节点,新建后启动,检查是否8个节
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis --cluster-enabled yes --appendonly yes --port 6388
2、进入到6387容器内部
3、将新增的6387节点(空槽位)作为master节点加入原集群
将新增的6387作为master节点加入集群
redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387 就是将要作为master新增节点
6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
redis-cli --cluster add-node 192.168.75.100:6387 192.168.75.100:6381
4、检查集群的情况第一次
root@centos100:/data# redis-cli --cluster check 192.168.75.100:6381
192.168.75.100:6381 (08df796c...) -> 2 keys | 5461 slots | 1 slaves.
192.168.75.100:6387 (987146b1...) -> 0 keys | 0 slots | 0 slaves.
192.168.75.100:6382 (c71627fc...) -> 2 keys | 5462 slots | 1 slaves.
192.168.75.100:6383 (1f378457...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 4 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.75.100:6381)
M: 08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 987146b1eb2e78155b1885312cc5fd92e4155b79 192.168.75.100:6387
slots: (0 slots) master
S: 7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385
slots: (0 slots) slave
replicates 1f37845789f52b4713200bbc4bc89dbad1fdfdf5
S: 1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386
slots: (0 slots) slave
replicates 08df796c1908646c721bf261d01604cfcde0bdec
M: c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384
slots: (0 slots) slave
replicates c71627fc6d20b9ca61fca76d1fd7e0adab02ec48
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
5、重新分配槽位
重新分派槽号命令:redis-cli --cluster reshard IP地址:端口号
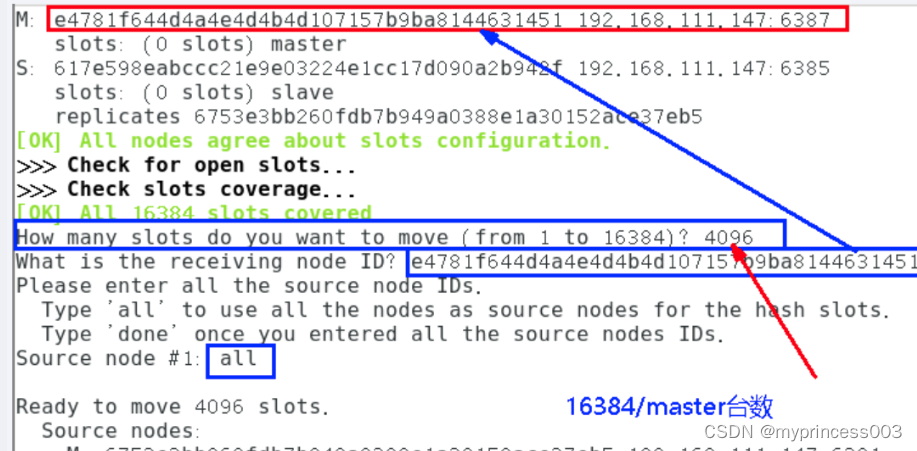
6、第二次查看集群情况
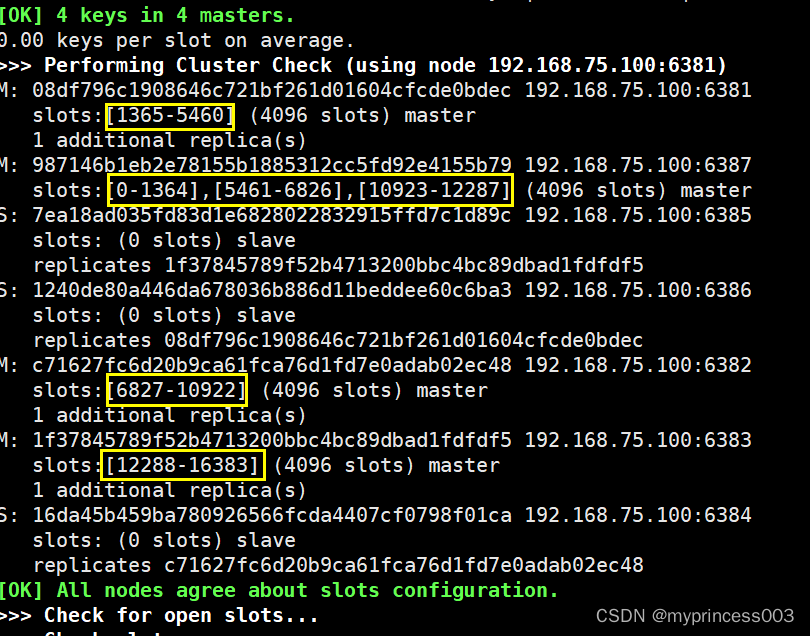
7、为主节点6387分配从节点6388
命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli --cluster add-node 192.168.111.147:6388 192.168.111.147:6387 --cluster-slave --cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451-------这个是6387的编号,按照自己实际情况
redis-cli --cluster add-node 192.168.75.100:6388 192.168.75.100:6387 --cluster-slave --cluster-master-id 987146b1eb2e78155b1885312cc5fd92e4155b79
8、第三次查看集群情况
redis-cli --cluster check 192.168.75.100:6381
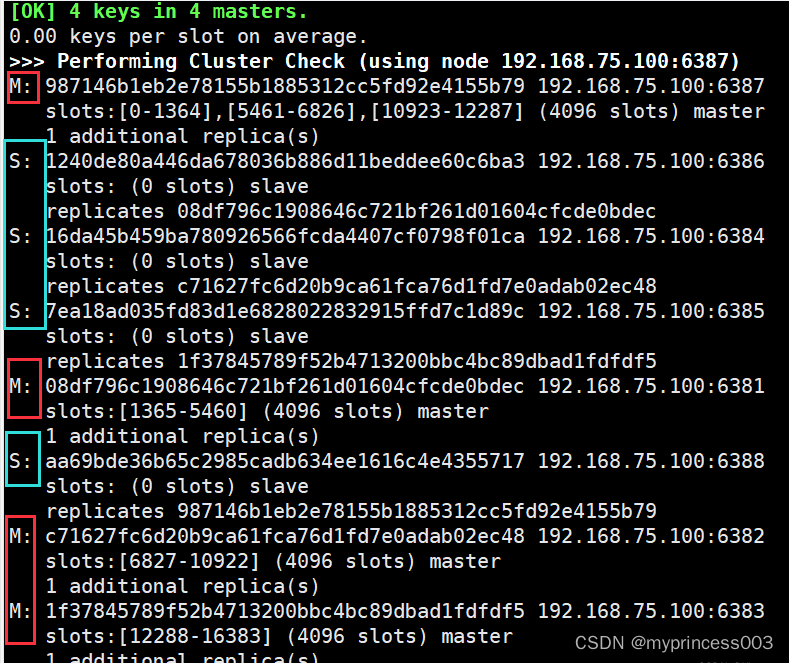
1.2.6 主从缩容案例
目的:6387、6388下线
1、检查集群情况,获得6387节点ID
aa69bde36b65c2985cadb634ee1616c4e4355717
2、从集群中将4号从节点6388删除
命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID
redis-cli --cluster del-node 192.168.75.100:6388 aa69bde36b65c2985cadb634ee1616c4e4355717
检查一下,可以发现6388已经被删除
redis-cli --cluster check 192.168.75.100:6387
3、将6387槽位重新分配,本例将所有清出来的槽位都给6381
redis-cli --cluster reshard 192.168.75.100:6381
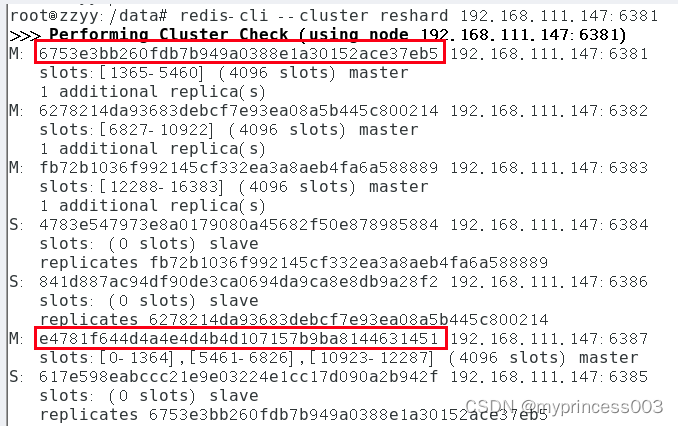
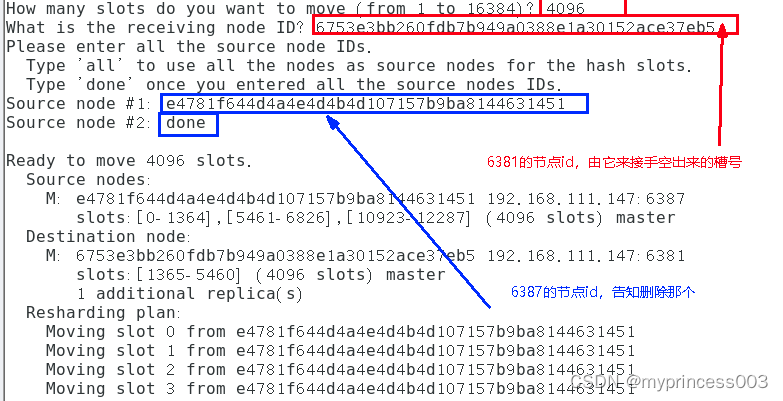
4、第二次检查集群情况
redis-cli --cluster check 192.168.75.100:6381
4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次
5、将6387删除
命令:redis-cli --cluster del-node ip:端口 6387节点ID
redis-cli --cluster del-node 192.168.75.100:6387 987146b1eb2e78155b1885312cc5fd92e4155b79
6、第三次检查集群情况
1.3 补充:将容器设置为开机自启
运行启动容器时指定
docker run -p 3306:3306 --restart=always -d mysql:5.7
restart具体参数值详细信息:
no 容器退出时,不重启容器;
on-failure 只有在非0状态退出时才从新启动容器;
always 无论退出状态是如何,都重启容器;
创建时未指定
docker update --restart=always xxx