作者:杨博东(凡澈)
本文详述了阿里云数据库 Tair/Redis 将使用长连接客户端在非预期故障宕机切换场景下的恢复时间从最初的 900s 降到 120s 再到 30s的优化过程,涉及产品优化,开源产品问题修复等诸多方面。
一、背景
Lettuce1 是一款优秀的 Redis2 Java 客户端,支持同步、异步、流式等编程接口,深受用户喜欢。2020 年开始,随着其用户量增大,很多用户反馈其使用 Lettuce 客户端时,在某些 Redis 故障宕机情况下,Lettuce 会持续超时长达 15 分钟,导致业务不可用。
阿里云数据库工程师也收到了客户反馈,于是我们开始深入调查并持续跟踪解决这个问题。终于,在最近 9 月份,这个问题得到了有效解决。下面我们以 Redis 的标准版架构来描述此问题(注意,即使在非云环境,此问题仍旧存在)。

(图 1. Redis 标准版双副本切换流程)
-
Redis 标准版架构中,开源 SDK 通过域名解析获取到 VIP 地址,建连到 Ali-LB,再到 Redis Master(图中 1’ 和 1 连接对应)。
-
当 Master 由于非预期故障直接宕机,有概率不会产生 RST 注。
-
HA 组件探测 Master 宕机,调用 Ali-LB switch_rs 接口,将后端的连接从 Master 切换到 Replica。
-
切换完成后 Ali-LB 并不会主动释放前端旧的客户端连接,对于客户端发到 Ali-LB 的包,由于后端不可用,默认丢弃,因此客户端将持续超时。此时如果有新的连接建立(例如 4’,会建连到新的 Master)是不存在问题的,但 Lettuce 客户端在超时情况下不会重新建立连接,因此旧连接存在问题。
-
直到到达 Ali-LB 的 est_timeout(默认 900s)之后,Ali-LB 会回复 RST 断开连接,之后客户端恢复。
注:对于部分网卡宕机、网络分区故障等情况,概率性不会产生 RST。大多数的宕机,操作系统会在退出前给客户端发送 RST,因此这个问题不是切换或者宕机就必现;在正常切换情况下由于 Master 可服务,在第 3 步,HA 组件会主动发送 client kill 命令给旧的 Master,从而让客户端发起一次重连恢复。
二、问题分析
-
首先这是一个 Lettuce 客户端设计缺陷,原因见后文和其余客户端对比分析。
-
其次这是一个 Ali-LB 的不成熟的机制(切换之后保持静默状态,不关闭自己与 Client 的连接),因此所有使用 Ali-LB 的数据库产品都会遇到,包括 RDS MySQL 等。
-
由于 900s 不可用对 Tair 来说影响太大,比如用户 1 万 QPS,那么 900s 就涉及约千万 QPS,因此我们率先来推动这个问题的解决。
2.1 为什么 Jedis 和 Redisson 客户端没有问题?
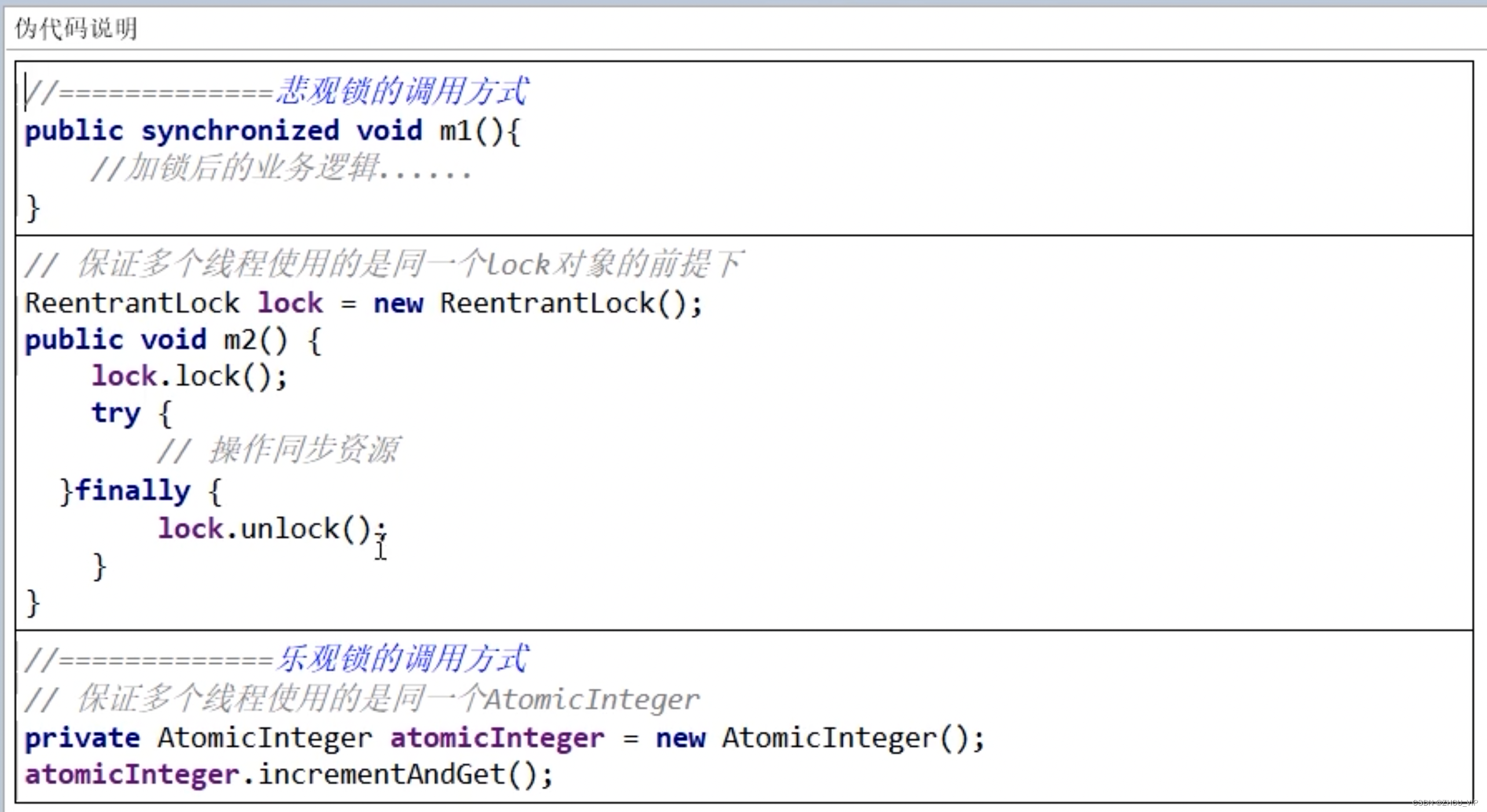
Jedis 是连接池模式,底层超时之后,会销毁当前连接,下一次重新建连,就会连接到新的切换节点上去并恢复。
Jedis连接池模式
try {
jedis = jedisPool.getResource(); // 查询前获取一个连接
// jedis.xxx // 执行操作查询
} catch (Exception e) {
e.printStackTrace(); // 超时,命令错误等情况
} finally {
if (jedis != null) {
// 这里的 close,如果连接正常,就返回连接池
// 如果连接异常,则会销毁这条连接
jedis.close();
}
}Redisson 本身支持了间隔发 ping 给服务端判活,如果不通则发起重连。
Redisson 的 PingConnectionInterval 参数
// PingConnectionInterval: 间隔多少 ms 给服务端发 PING 包,在本连接上,如果不通则重连,默认 30000
config.useSingleServer().setAddress(uri).setPingConnectionInterval(1000);
RedissonClient connect = Redisson.create(config);2.2 能否通过配置 TCP 的 KeepAlive 来保活?
结论是不行,因为 TCP Retransmission Package 的优先级高于 KeepAlive,即如果是一个活跃连接,当此问题出现时候,会先开始 TCP Retran,具体取决于 tcp_retries23 参数(默认 15 次,需要 924.6 s)。

(图2. 活跃连接黑洞问题流程图)
-
T1:Client 发送 set key value 给 Ali-LB
-
T2:Ali-LB 回复 ok
-
T3:Client 发送 get key 给 Ali-LB,但是此时后端发生切换,之后 Ali-LB 没有任何 Response,客户端表现超时
-
T4:开始第一次 tcp retran
-
T5:开始第二次 tcp retran
-
T6:此时还在 tcp retran,但是因为到达 Ali-LB est_timeout 时间,因此 Ali-LB 回复了 RST 回来,客户端就会恢复了。那如果 Ali-LB 一直不回复 RST,重传结束之后,TCP 也是会主动断开重连的,也可以恢复。
所以说,如果客户端侧想解决这个问题,依靠 TCP KeepAlive 是无法完成的,也可以参考知乎此问题《TCP中已有SO_KEEPALIVE选项,为什么还要在应用层加入心跳包机制》4 ,而 Lettuce 在 6.1.05 版本开始支持了设置 KeepAlive 的选项,但如此前分析,这并不能解决活跃连接的问题。因此我们给 Lettuce 提了一个详细的 issue6 ,来描述问题、复现方法、原因,可能的修复方法,作者也认同了问题。
三、问题解决
3.1 紧急止血
-
由于没有别的有效方法,只能先将 est_timeout 调整到 120s (不能再小,否则会断开正常静默连接),这意味着用户最多受损 135s(120s + 15s 探测,注意:不可用之后还要探测完才能发起切换)。
-
官网文档不推荐用户使用 Lettuce。

3.2 客户端侧修复
尝试一:为 Lettuce 添加 PingConnectionInterval
上述分析我们提到,如果客户端侧想解决这个问题,需要实现应用层的判活机制,简而言之就是客户端会在和服务端的连接上间接的插入判活数据包,注意,这里使用的连接必须是客户端和服务端已有连接,而不能是一个单独的新连接,否则会误判,因为问题是针对连接维度的黑洞,如果使用新连接判断,那么服务端会返回正常的结果。
提交了 commit7 之后,作者对这个方案并不是非常认同,他认为:
-
这个修复方法比较复杂。
-
由于 Lettuce 支持 Command Listener,他认为用户可以在 Command 超时之后自己关闭连接。
-
Redis 本身存在一些 Block 的命令,例如 xread,brpop,此时连接是被 hang 住的,探活无法进行。
交流下来,我们拒绝因为修改复杂就让用户通过 Command Listener 的方法来自己关闭连接,这意味着每个用户为了安全使用 Lettuce 都要改代码,成本将会非常高,但是 block 的命令通过此方案无法解决的问题也确实存在,因此暂时被搁置。
尝试二:使用 TCP_USER_TIMEOUT
TCP USER TIMEOUT 是RFC 54288 规定的 TCP option,用来扩展 TCP RFC 7939 协议中本身的 "User Timeout" 参数(原协议不允许配置参数大小)。其用来控制已经发送,但是尚未被 ACK的数据包的存活时间,超过这个时间则会强制关闭连接。用它可以解决上述 KeepAlive 无法解决的 Retran 优先级高的问题,下面是 KeepAlive 和 Retran 以及 TCP USER TIMEOUT 一起工作的情况。

确认 TCP_USER_TIMEOUT 可以解决此问题后,和作者再次沟通,作者也同意了此修复访问,我们提交了 PR10,并最终被合并,之后也验证了修复的效果,符合预期。使用下述版本可以解决黑洞问题,但需要依赖netty-transport-native-epoll:4.1.65.Final:linux-x86_64,在 EPOLL 可用时,用下面代码开启,tcpUserTimeout 可结合业务具体情况配置,建议 30s。
开启 TCP_USER_TIMEOUT
bootstrap.option(EpollChannelOption.TCP_USER_TIMEOUT, tcpUserTimeout);Lettuce 修复版本的SNAPSHOT版本
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.3.0.BUILD-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-transport-native-epoll</artifactId>
<version>4.1.65.Final</version>
<classifier>linux-x86_64</classifier>
</dependency>3.3 Ali-LB 的修复方案
Ali-LB 侧针对此问题,推出了 Connection Draining 功能,Connection Draing 意为连接排空,为了做优雅关闭使用。
优雅关闭意味着通常后端服务器可用,如下图一个 Ali-LB 后面挂有 4 个 Server,执行缩容操作移除 Server4,对于即将要发给这个 Server 的 Request 4 和 6(同连接上),在 draining 配置的时间内(0-900s),Server4 还是会对 Request 做出响应,等到 draining 时间到达之后才断开连接,注意:draining 之后,新的链接就不会再调度给 Server4 了,因此后续的7,8,9等请求都不会再发给 Server4 了,这也是能排空的前提。
因此一旦开启 draining,则在最迟到达 draining 时间之后,客户端就会收到 Ali-LB 的 RST 了。
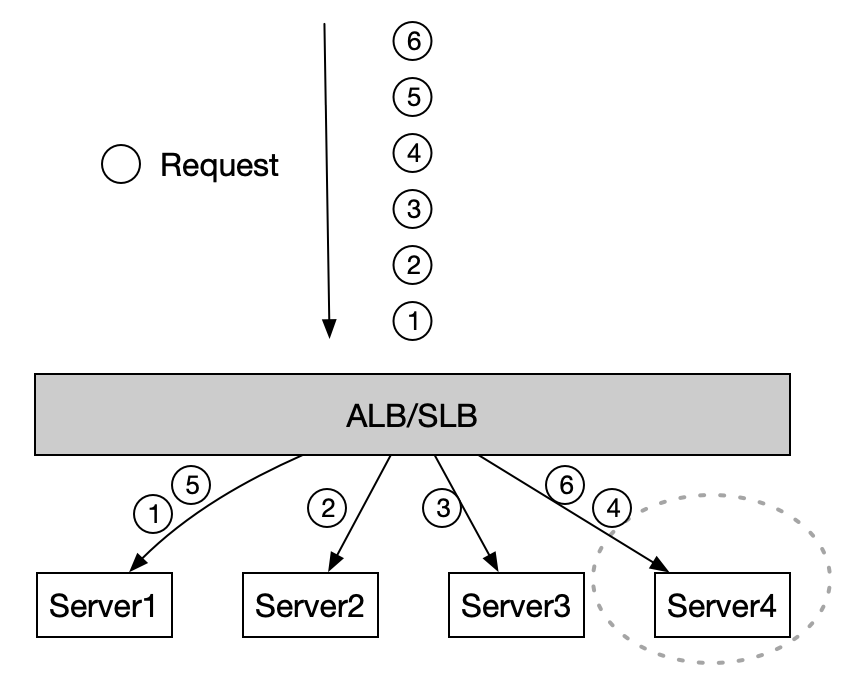
(图 3. Connection Draining 示意图)
对比 est_timeout 机制,Connection Draining 的优势是减少了误判,尽最大能力交付。
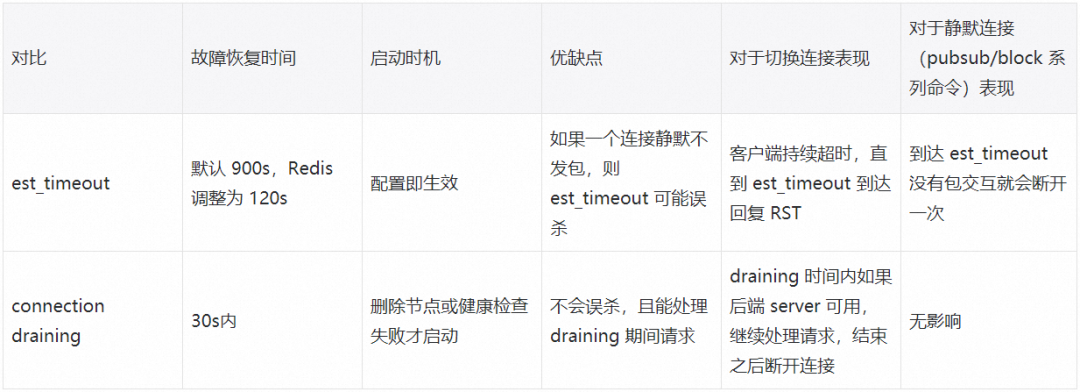
(表1. est_timeout 对比 connection draining)
Ali-LB 团队上线 Connection Draining 之后,我们配合验证,可以将故障时间从 120s 缩短至 30s 内,符合 Redis 产品的 SLA,目前已经全网发布完成,这也解决其余 Redis 收敛连接 SDK,和整个数据库产品的连接黑洞问题。
四、总结
本文详述了 Lettuce 客户端黑洞问题的原理和解决方案:
-
从客户端侧:可以升级 Lettuce 最新的 6.3.0 版本,并打开 TCP_USER_TIMEOUT 参数。在阿里云上,无需修改代码,Ali-LB 的 Connection Draining 将会主动避免此问题,(无需用户升级,阿里云会主动逐步变更)。
-
一个应用广泛的软件包的恶性 Bug 伤害巨大。比如这次 Lettuce,本来属于 Spring Boot 中最常用的 Redis SDK,由于作者的矫情也好,较真也好(见6)导致数年中诸多云上使用者出现大量恶性故障,我们在推动中既看到如 Azure、AWS 和华为在咨询和推动,也看到无数期待 Fix 的开发者。Redis 和 Tair 也要加大在社区 SDK 的投入,尤其是自研,自主自控的 SDK 尤为重要。
此问题从发现,到修复历时约 2 年,终于被解决,道阻且长,行则将至!
参考阅读
[01] https://github.com/lettuce-io/lettuce-core
[02] https://github.com/redis/redis
[03] tcp_retries2
https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
[04] 《TCP中已有SO_KEEPALIVE选项,为什么还要在应用层加入心跳包机制?》
https://www.zhihu.com/question/40602902/answer/209148428
[05] https://github.com/lettuce-io/lettuce-core/issues/1437
[06] https://github.com/lettuce-io/lettuce-core/issues/2082
[07] https://github.com/yangbodong22011/lettuce-core/commit/23bafbb9255c87ed96a6476c260b299f852ee88a
[08] TCP_USER_TIMEOUT
https://www.rfc-editor.org/rfc/rfc5482.html
[09] https://www.rfc-editor.org/rfc/rfc793
[10] https://github.com/lettuce-io/lettuce-core/pull/2499