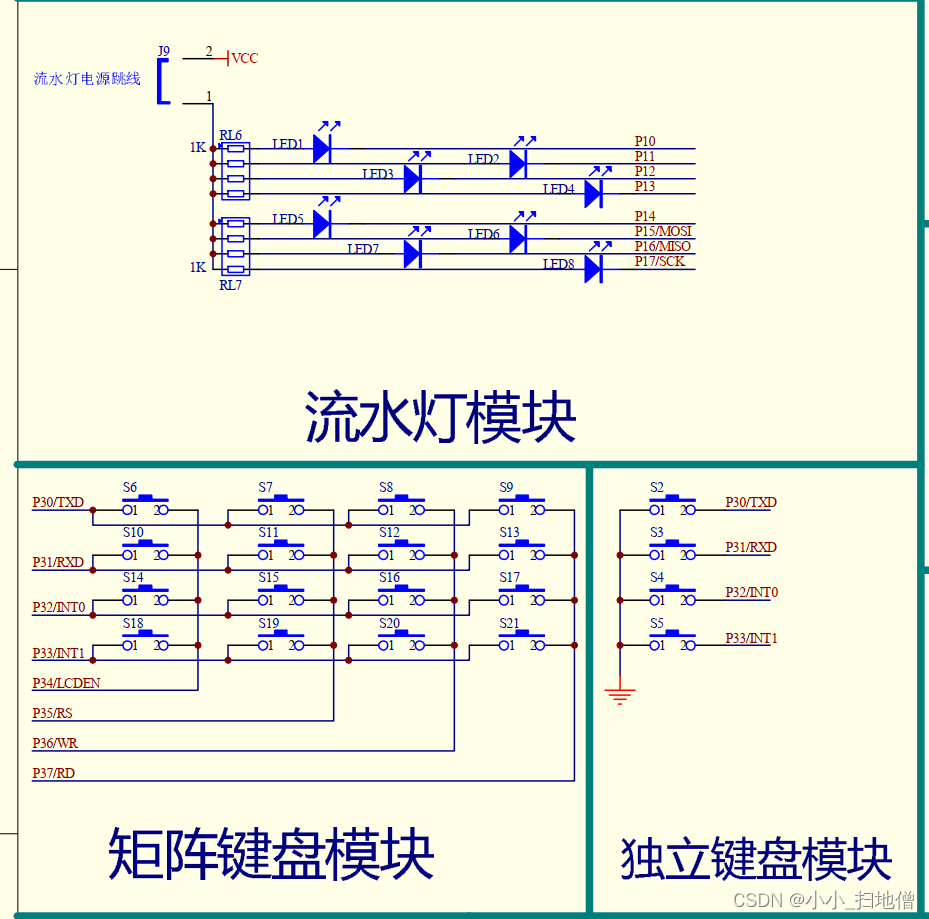
👀樊梓慕:个人主页
🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》
🌝每一个不曾起舞的日子,都是对生命的辜负
目录
前言
1.直接插入排序
2.希尔排序
3.直接选择排序
4.堆排序
前言
本篇文章博主将介绍排序算法中的插入排序:直接插入排序、希尔排序和选择排序:选择排序、堆排序,并进行代码实现,感兴趣的同学给博主点点关注哦🌝
欢迎大家📂收藏📂以便未来做题时可以快速找到思路,巧妙的方法可以事半功倍。
=========================================================================
GITEE相关代码:🌟fanfei_c的仓库🌟
=========================================================================
1.直接插入排序
直接插入排序的思想就是从左到右进行遍历,在遍历过程中将当前的元素插入到前面(已经有序)合适的位置,直到遍历完成。
直接插入排序的特性:
- 元素集合越接近有序,直接插入排序算法时间效率越高;
- 时间复杂度:O(N^2);
- 空间复杂度:O(1);
- 稳定性:稳定。
排序的稳定性:指的是保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。
代码实现:
// 插入排序
void InsertSort(int* a, int n)
{
for (int i = 0; i < n-1; i++)
{
int end = i;
int tmp = a[end + 1];//保存待插入的值
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];//向后覆盖
}
else//因为此时前面已经是有序序列,如果tmp>当前值,证明比前面都大,所以break跳出即可
{
break;
}
end--;
}
a[end+1]= tmp;
}
}2.希尔排序
希尔排序与直接插入排序同属插入排序方法,也就是说希尔排序也是靠向前插入的思路进行的。
不同的是,希尔排序先进行预排序,将待排序序列调整的接近有序后,再进行一次直接插入排序。
希尔排序利用了插入排序的特性:待排序序列越接近有序,插入排序时间效率越高。
那么如何进行预排序呢?
希尔排序将待排序序列分组,假设定义一个变量 gap ,那么间隔gap的数据我们分为一组,如图:

预排序阶段:我们以分组情况为基础,每组内部进行直接插入排序,每完成一轮,gap=gap/3-1。
注意:预排序阶段的边界设计很多可以参照直接插入排序,就是将1改为了gap而已,不理解时可以代入直接插入排序进行理解。
直接插入排序阶段:直到gap的值为1的时候,我们发现此时就是直接插入排序了,经过这轮排序就能得到最终的有序序列。


图片取自wikipedia-Shell_sort
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定。大致为O(N^1.25)到O(1.6*N^1.25)。
- 稳定性:不稳定
代码实现:
// 希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//gap递减普遍取这种,也有取gap=gap/2的
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}3.直接选择排序
选择排序的思想是每遍历一遍选出最小的值,放到最开始的位置。
我们对该思想优化,每次遍历选出最大值和最小值,分别放到两边。
直接选择排序的特性:
- 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
代码实现:
// 选择排序
void SelectSort(int* a, int n)
{
int left = 0;
int right = n - 1;
while (right > left)
{
int maxi = left;
int mini = left;
for (int i = left+1; i <=right ; i++)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
swap(&a[left], &a[mini]);
if (maxi == left)//假设max被换走了,恢复一下
{
maxi = mini;
}
swap(&a[right], &a[maxi]);
right--;
left++;
}
}4.堆排序
堆排序首先要介绍的是向下调整算法。
向下调整算法的前提是左右子树是堆。
以小堆为例:
1.给定向下调整的起点(双亲节点下标)和节点总数,根据起点下标计算孩子节点下标。
注意:向下调整时,若有两个孩子节点,则需要确保调整的是较大的孩子节点。
2.比较孩子节点与双亲节点数值大小,若孩子节点小于双亲节点,则交换两者,并将双亲节点的下标更新为之前的孩子节点下标,根据最新的双亲节点下标重新计算孩子节点下标,重复这一过程直到孩子节点超出节点总数。

对于堆排序来说:
以升序为例:
首先构建大堆(推荐使用向下调整),此时堆顶元素一定为最大值,然后将堆顶元素与最后一个节点交换,此时最大值就放到了整个数组的最后面,然后除了最后一个值以外,其他的数据再向下调整,调整完成后堆顶元素为次大值,再与数组倒数第二个位置的值交换,这样依此往复就得到了升序数组。
注意:升序建大堆,降序建小堆。
🌐更多关于堆的内容可以参考博客:堆排序与TopK问题---樊梓慕🌐
堆排序的特性总结:
- 堆排序擅于处理庞大数据。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
- 稳定性:不稳定
代码实现:
// 堆排序
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
// 找出小的那个孩子
if (child + 1 < n && a[child + 1] > a[child])
{
++child;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
// 继续往下调整
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
// 向下调整建堆
// O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
// O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}=========================================================================
如果你对该系列文章有兴趣的话,欢迎持续关注博主动态,博主会持续输出优质内容
🍎博主很需要大家的支持,你的支持是我创作的不竭动力🍎
🌟~ 点赞收藏+关注 ~🌟
=========================================================================