读高性能MySQL(第4版)笔记17_复制(下)
news2026/3/17 5:31:45
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1049682.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

JDBC【DBUtils】
一、 DBUtils工具类🍓
(一)、DBUtils简介🥝
使用JDBC我们发现冗余的代码太多了,为了简化开发 我们选择使用 DbUtils Commons DbUtils是Apache组织提供的一个对JDBC进行简单封装的开源工具类库,使用它能够简化JDBC应用程序的开发,…

Ubuntu 20.04二进制部署Nightingale v6.1.0和Prometheus
sudo lsb_release -r可以看到操作系统版本是20.04,sudo uname -r可以看到内核版本是5.5.19。
sudo apt-get update进行更新镜像源。
完成之后,如下图:
sudo apt-get upgrade -y更新软件。
选择NO,按下Enter。
完成如下&…
C# Onnx Yolov8 Detect 手势识别
效果 Lable
five
four
one
three
two
项目 代码
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
using OpenCvSharp;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;…
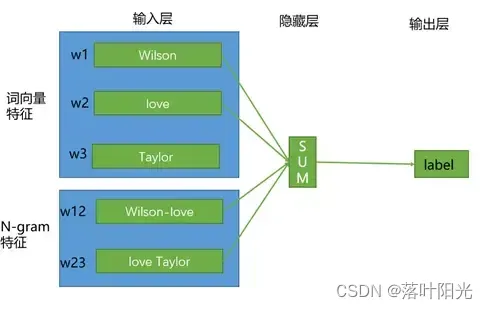
【小笔记】fasttext文本分类问题分析
【学而不思则罔,思维不学则怠】 2023.9.28 关于fasttext的原理及实战文章很多,我也尝试在自己的任务中进行使用,是一个典型的短文本分类任务,对知识图谱抽取的实体进行校验,判断实体类别是否正确,我构建了…
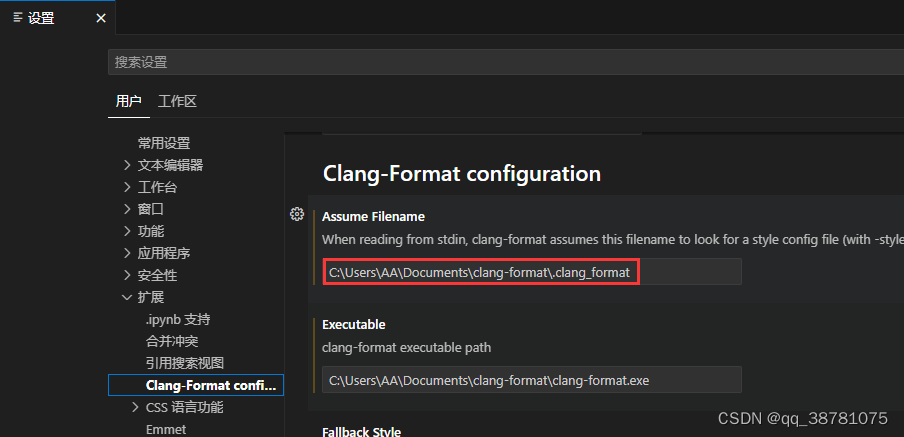
windows 下 vs code 格式化代码(clang-format)
vscode 的格式化代码能力来源于插件(有不止一种插件提供格式化功能),而非 vscode 本身
1、安装插件 2、windows 下载 LLVM-17.0.1-win64.exe (exe 结尾的安装包)
Releases llvm/llvm-project GitHub
可以直接把这…

python - random模块随机数常用方法
文章目录 前言python - random模块随机数常用方法1. 返回1-10之间的随机数,不包括102. 返回1-10的随机数,包括103. 随机选取0到100之间的偶数4. 返回一个随机浮点数5. 返回一个给定数据集合中的随机字符6. 从多个字符中选取特定数量的字符7. 生成随机字符…
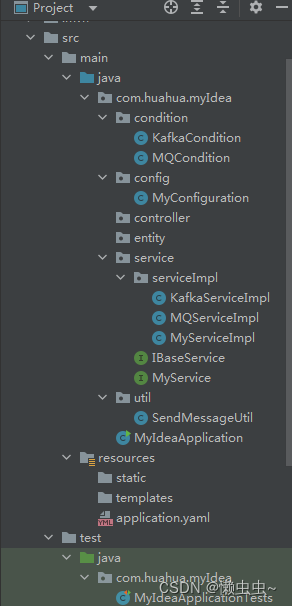
巧用@Conditional注解根据配置文件注入不同的bean对象
项目中使用了mq,kafka两种消息队列进行发送数据,为了避免硬编码,在项目中通过不同的配置文件自动识别具体消息队列策略。这里整理两种实施方案,仅供参考!
方案一:创建一个工具类,然后根据配置文…
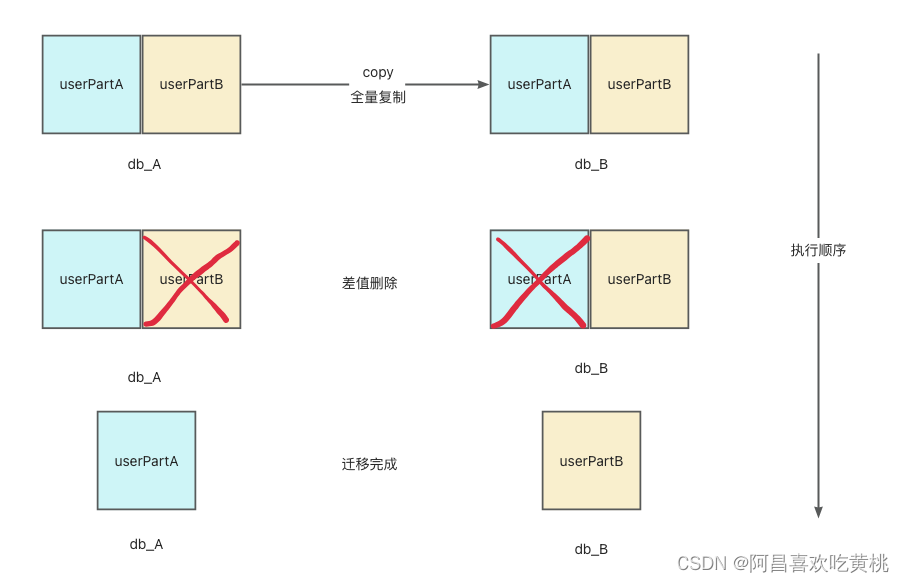
23.09.26用户切库流程记录
23.09.26用户切库流程记录
hello,我是阿昌,今天记录一下最近切库的流程,内容如下:
一、切库的原因
因为db_A用户数据量超过预期,磁盘空间逐渐不足,需要换成db_A库的压力,所以将部分db_A用户切…
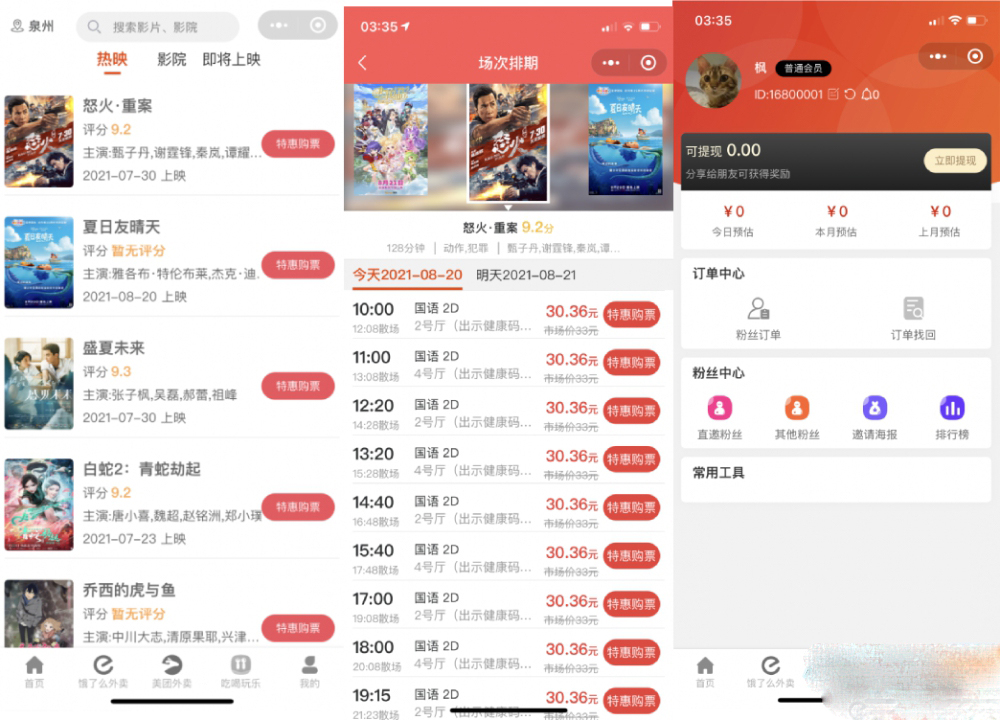
外卖侠CPS小程序_带有分销功能的完整全套源码【前后端】
外卖侠CPS全套源码是一款为外卖平台提供分销功能的微信小程序。用户可以通过你的链接去领取外卖红包,然后去下单点外卖,既能省钱,又能获得佣金。该小程序带有商城、影票、吃喝玩乐等多个模块,适合不同用户的需求。
外卖CPS的势头…
第一届龙信杯取证比赛部分题目复现
感谢大佬是toto的wp
第一届“龙信杯”电子数据取证竞赛Writeup-CSDN博客
手机取证
1.请分析涉案手机的设备标识是_______。(标准格式:12345678)
打开龙信取证软件分析镜像即可得到结果 2.请确认嫌疑人首次安装目标APP的安装时间是______。…
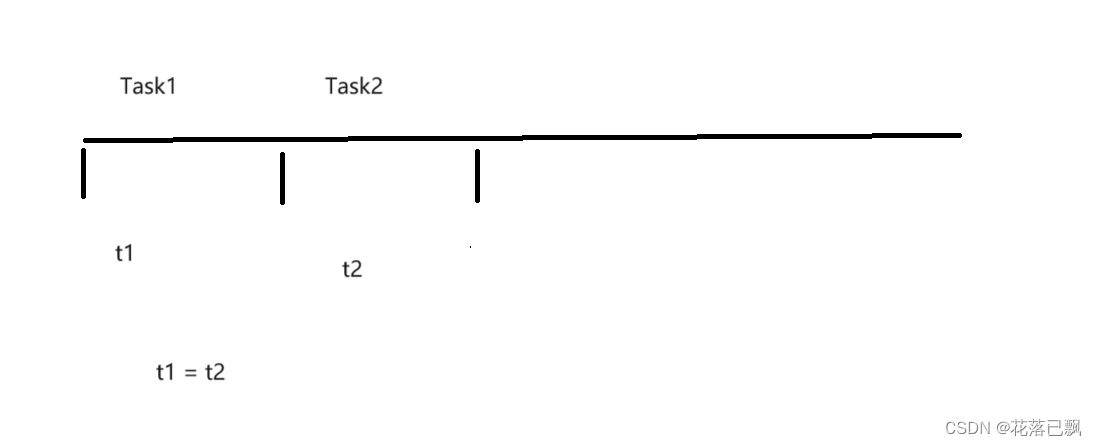
FreeRTOS入门教程(任务优先级,Tick)
文章目录 前言一、什么是任务优先级二、FreeRTOS如何分辨出优先级最高可运行的任务三、FreeRTOS中的时钟节拍Tick四、什么是时间片五、相同优先级任务怎么进行切换六、任务优先级实验七、修改任务优先级总结 前言
本篇文章将带大家学习FreeRTOS中的任务优先级,并且…

FreeRTOS入门教程(任务状态)
文章目录 前言一、简单实验二、任务状态概念讲解三、vTaskDelay和vTaskDelayUntil1.vTaskDelay2.vTaskDelayUntil3.vTaskDelay和vTaskDelayUntil的区别 总结 前言
本篇文章将为大家讲解FreeRTOS中的任务状态,在FreeRTOS任务是有非常多种状态的,了解了任…
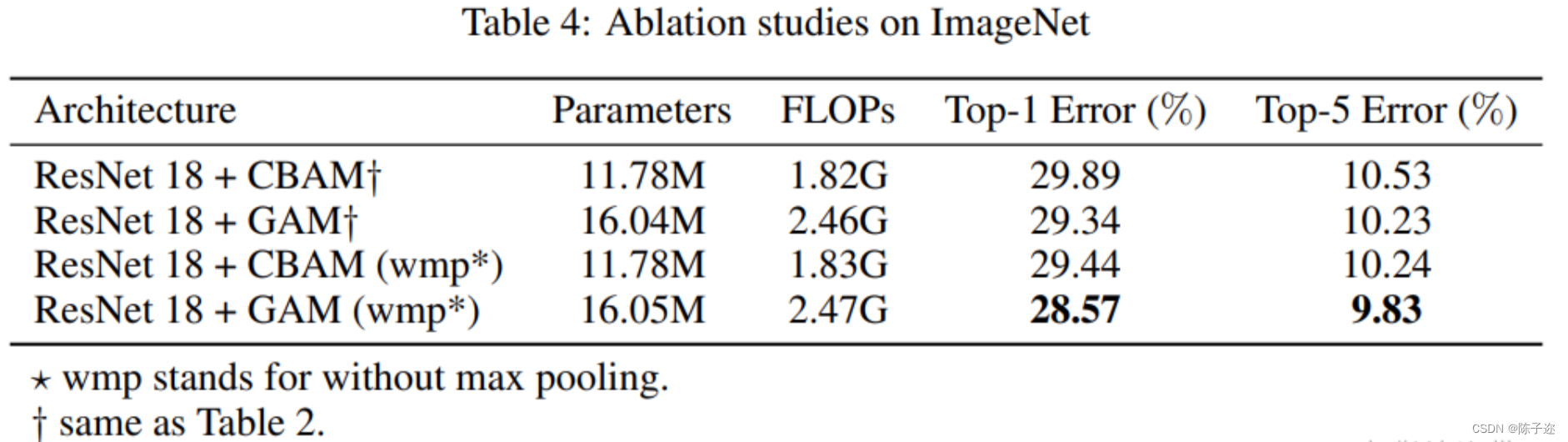
YOLOv7改进:GAMAttention注意力机制
1.背景介绍 为了提高各种计算机视觉任务的性能,人们研究了各种注意机制。然而,以往的方法忽略了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局调度机制,通过减少信息缩减和放大全局交互表示来提高深…
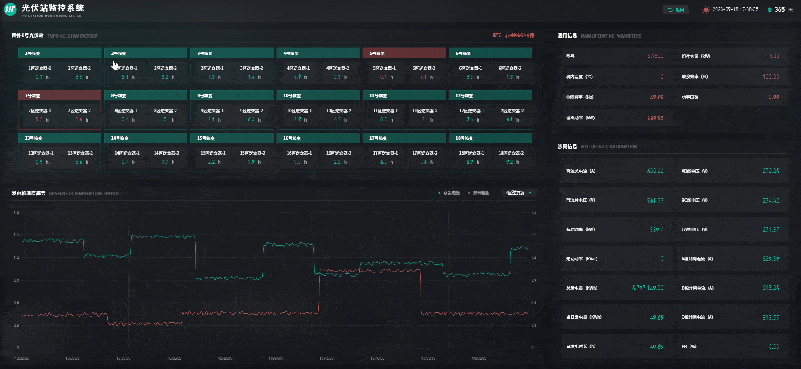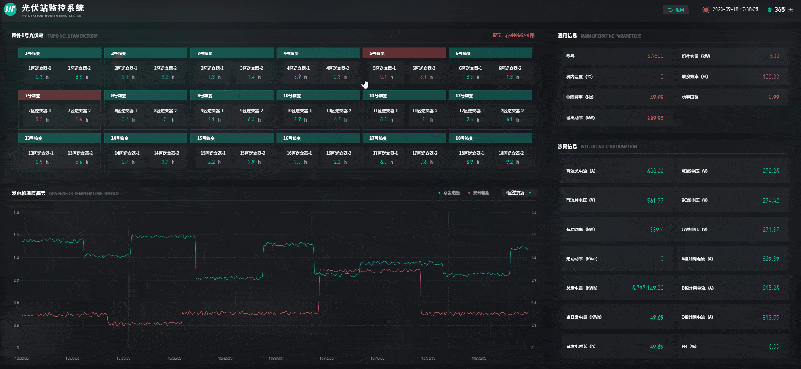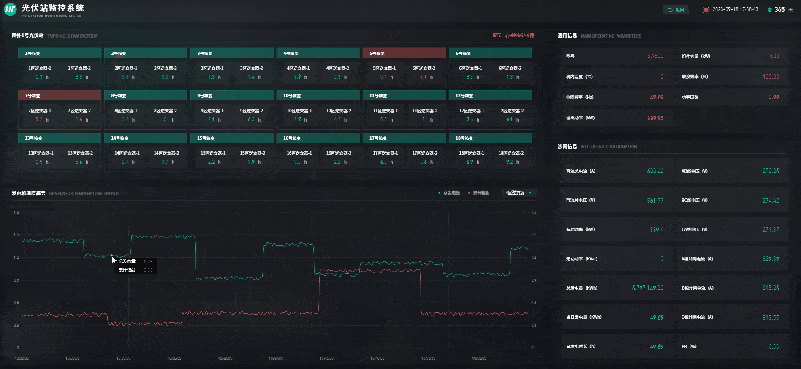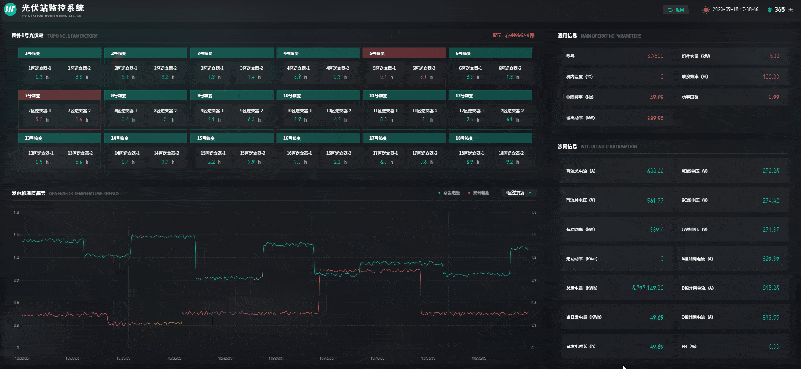
风光储一体化能源中心 | 数字孪生智慧能源
自“双碳”目标提出以来,我国能源产业不断朝着清洁低碳化、绿色化的方向发展。其中,风能、太阳能等可再生能源在促进全球能源可持续发展、共建清洁美丽世界中被寄予厚望。风能、太阳能具有波动性、间歇性、随机性等特点,主要通过转化为电能再…
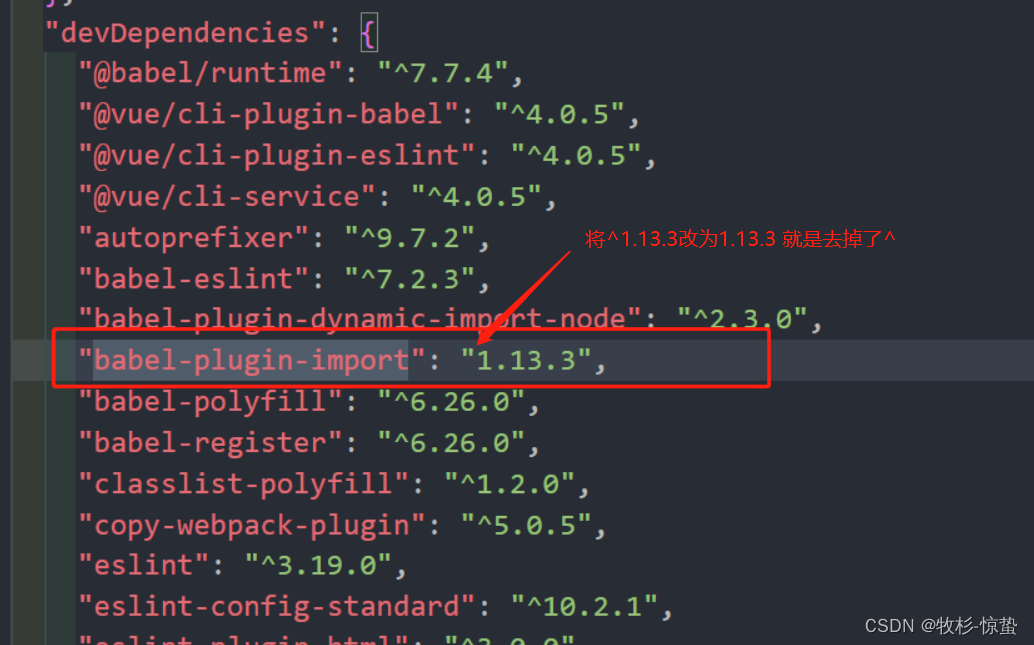
This dependency was not found: vxe-table/lib/vxe-table in ./src/main.js
描述
使用时
安装 npm install xe-utils vxe-table 引入 import Vue from vue import xe-utils import VXETable from vxe-table import vxe-table/lib/style.css vxe-table是一个基于 vue 的 PC 端表格组件, 支持增删改查、虚拟滚动、懒加载、快捷菜单、数据校验…
微信公众平台怎么添加秒杀活动
微信公众平台是一个非常有用的工具,它可以帮助企业或个人建立自己的品牌形象,增加用户粘性,提高销售业绩等等。在微信公众平台上添加秒杀活动为主题可以吸引更多的用户关注,促进销售,提高品牌知名度等。下面我们将介绍…

uni-app 实现凸起的 tabbar 底部导航栏
效果图 在 pages.json 中设置隐藏自带的 tabbar 导航栏
"custom": true, // 开启自定义tabBar(不填每次原来的tabbar在重新加载时都回闪现) 新建一个 custom-tabbar.vue 自定义组件页面
custom-tabbar.vue
<!-- 自定义底部导航栏 -->
<template><v…
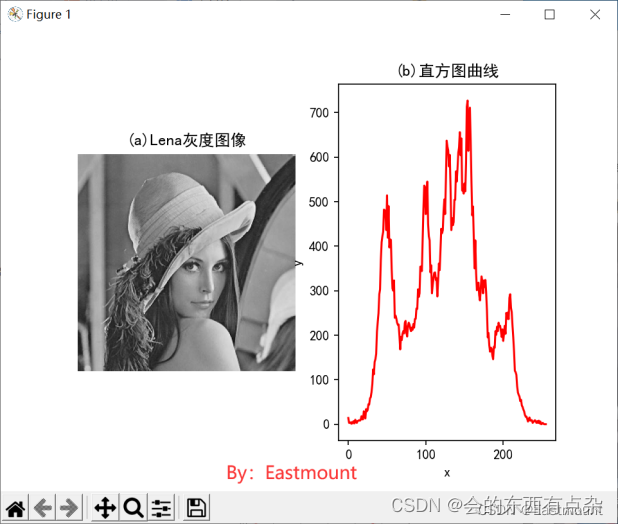
图像直方图的基础知识
直方图的概念
图像直方图反映了图像中的灰度分布规律。它描述每个灰度级具有的像元个数,但不包含这些像元在图像中的位置信息。任何一幅特定的图像都有唯一的直方图与之对应,但不同的图像可以有相同的直方图。如果一幅图像有两个不相连的区域组成&#…

ARM Linux DIY(十四)摄像头捕获画面显示到屏幕
前言
前期已经调试好了摄像头和屏幕,今天我们将摄像头捕获的画面显示到屏幕上。
原理
摄像头对应 /dev/video0,屏幕对应 /dev/fb0,所以我们只要写一个应用程序,读取 video0 写入到 fb0 就可以了。
应用程序代码实例
camera_d…