使用model, serializer, view执行查询操作最后得到数据, 通过序列化serializer.data获取查询结果集, 最后得到的数据如下所示:
[
OrderedDict([('id', 4), ('time', '2023/09/18 11:11:20'), ('level', '4'), ('count', 4), ('s_assets', '设备4'), ('d_assets', '设备4'), ('sip', '10.60.6.4'), ('dip', '10.60.6.4'), ('sport', '44'), ('dport', '44'), ('description', 'dffd44'), ('type', '4'), ('protocol_content', 'fdfd4')]),
OrderedDict([('id', 2), ('time', '2023/09/18 11:11:19'), ('level', '2'), ('count', 3), ('s_assets', '设备2'), ('d_assets', '设备2'), ('sip', '10.60.6.6'), ('dip', '1060.6.7'), ('sport', '22'), ('dport', '22'), ('description', '22df'), ('type', '2'), ('protocol_content', 'fdfd2')]),
OrderedDict([('id', 1), ('time', '2023/09/18 11:11:18'), ('level', '1'), ('count', 1), ('s_assets', '设备1'), ('d_assets', '设备2'), ('sip', '10.60.6.3'), ('dip', '10.60.6.7'), ('sport', '11'), ('dport', '12'), ('description', 'dfdf'), ('type', '1'), ('protocol_content', 'fdfd')])
]
很多新手会比较懵, 一看这是啥数据类型??别慌, 且听我一一为你道来
上面得到的数据是Python中的OrderedDict数据类型。OrderedDict是Python标准库collections中的类,它是一个字典(dict)的子类,特点是它会保持元素被插入的顺序。这在处理需要记录插入顺序的数据时非常有用。
在上面的例子中,每个OrderedDict对象都包含一组键值对,每个键值对都代表一条网络流量的信息,比如'id'、'time'、'level'等是键,其后的值是具体的信息,如'10.60.6.4'、'设备4'等。每个单独的OrderedDict对象代表一条网络流量记录。
如果我们想访问或者处理这些数据,可以使用Python字典和OrderedDict的常见操作,例如:获取一个键的值(dict[key]),遍历所有的键值对(dict.items()),或者获取所有的键(dict.keys()), 所有的值(dict.values())
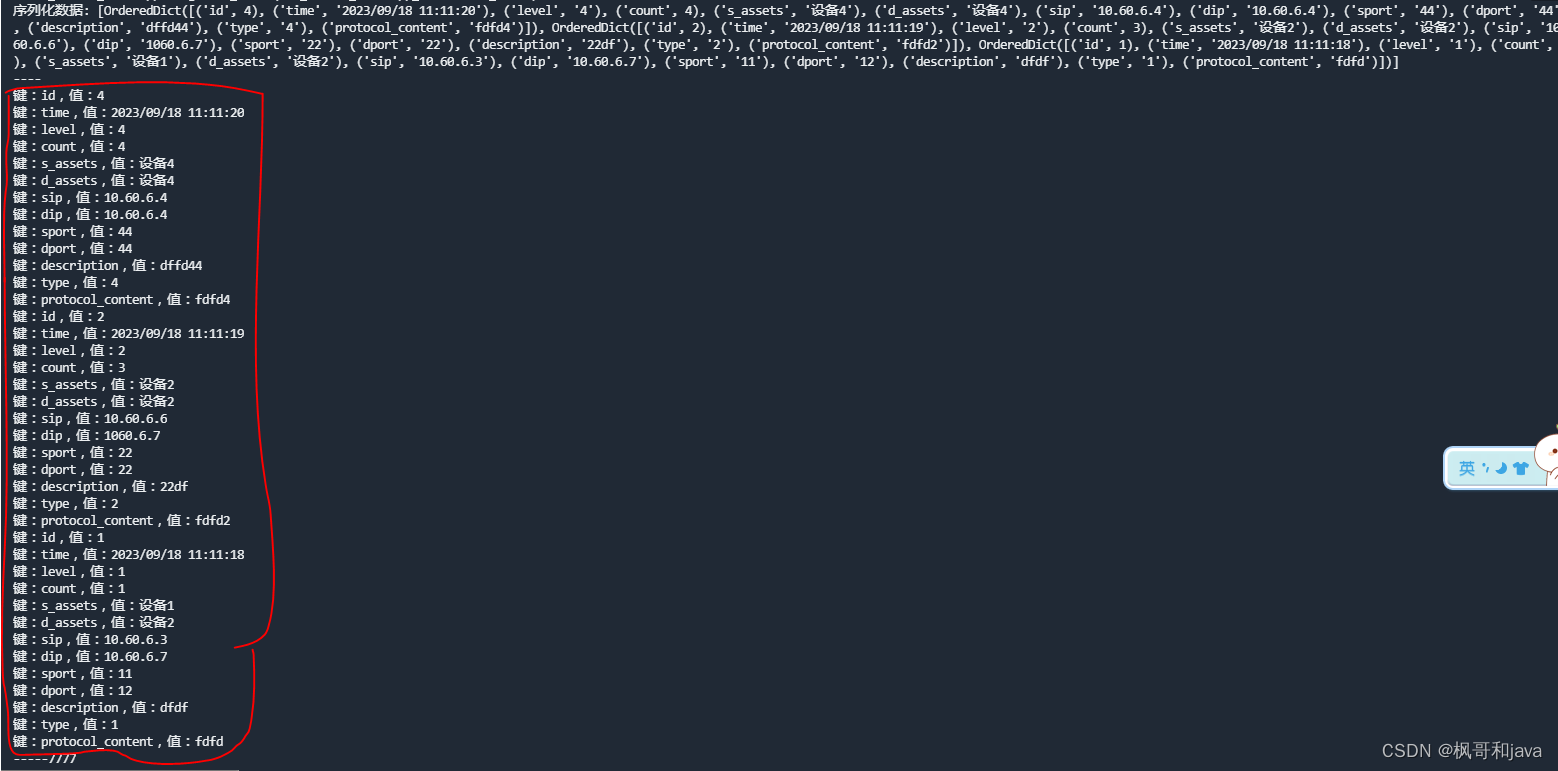
一, 遍历以上数据, 需要得到每个键和值实例代码如下:
from collections import OrderedDict
data_dict = OrderedDict([('id', 4), ('time', '2023/09/18 11:11:20'), ('level', '4'), ('count', 4), ('s_assets', '设备4'), ('d_assets', '设备4'), ('sip', '10.60.6.4'), ('dip', '10.60.6.4'), ('sport', '44'), ('dport', '44'), ('description', 'dffd44'), ('type', '4'), ('protocol_content', 'fdfd4')]), OrderedDict([('id', 2), ('time', '2023/09/18 11:11:19'), ('level', '2'), ('count', 3), ('s_assets', '设备2'), ('d_assets', '设备2'), ('sip', '10.60.6.6'), ('dip', '1060.6.7'), ('sport', '22'), ('dport', '22'), ('description', '22df'), ('type', '2'), ('protocol_content', 'fdfd2')]), OrderedDict([('id', 1), ('time', '2023/09/18 11:11:18'), ('level', '1'), ('count', 1), ('s_assets', '设备1'), ('d_assets', '设备2'), ('sip', '10.60.6.3'), ('dip', '10.60.6.7'), ('sport', '11'), ('dport', '12'), ('description', 'dfdf'), ('type', '1'), ('protocol_content', 'fdfd')])
for key, value in data_dict.items():
print(f"键:{key},值:{value}")
运行后得到的结果如下:
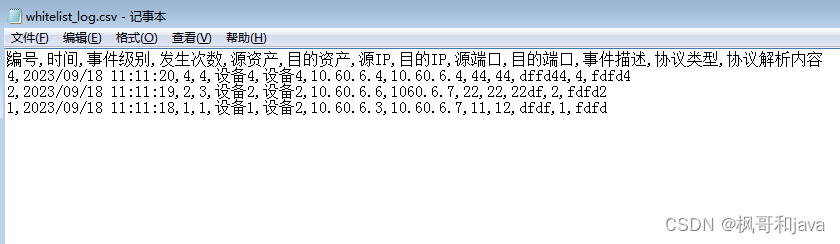
二, 遍历以上数据, 需求, 将每个value写进csv文件:
部分关键示例代码:
2.1, 写csv先定义一组表头:
import csv
from collections import OrderedDict
header = ['编号', '时间', '事件级别', '发生次数', '源资产', '目的资产', '源IP', '目的IP', '源端口', '目的端口',
'事件描述', '协议类型', '协议解析内容']
data_dict = serializer.data # 序列化得到的便是上面那组字典数据
filepath = "/hardisk/download/whitelist_log.csv" # 要写入的csv文件
with open(filepath, 'w', newline='') as f:
write = csv.writer(f)
write.writerow(header)
for i in range(len(data_dict)):
write.writerow(data_dict[i].values()) # 获取上面数据每一个value的内容写入csv文件
写入效果如下:
好了, 今天就先写到这.下期再会