文章目录
- 元组
- 列表
- 字典
- 集合
- 推导式
- 函数
- 错误和异常处理
- 文件和操作系统
元组
元组是一个固定长度,不可改变的Python序列对象。创建元组的最简单方式,是用逗号分隔一列值。
- 创建
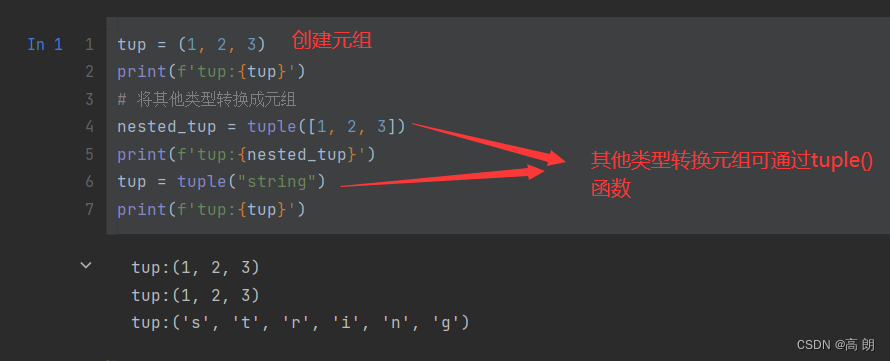
2. 元组不可修改的解释
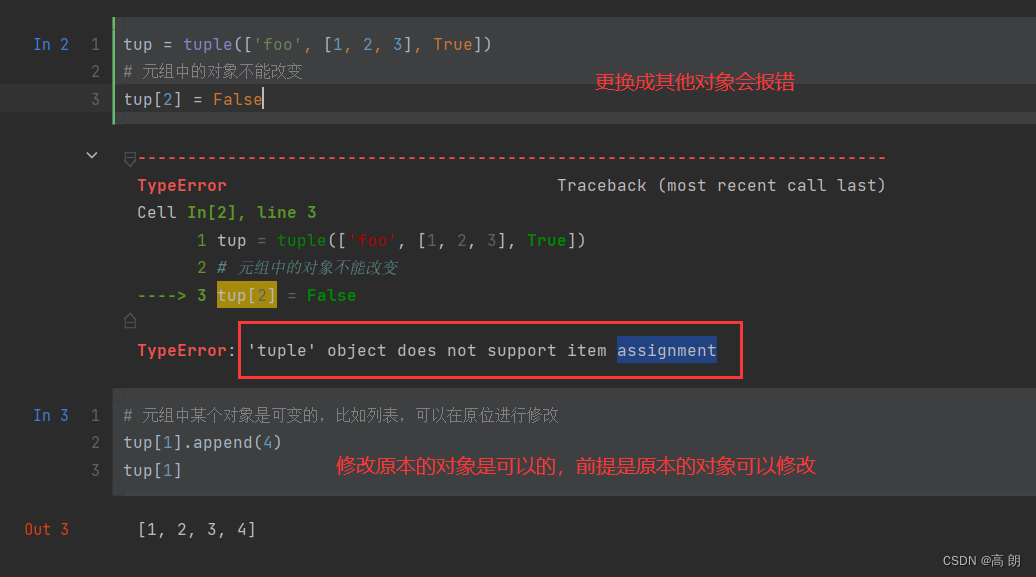
对于元组对象不可变的说明,通俗一点就是,不能更换里面的对象,但是里面对象本来就是可以修改,那我们可以修改原本对象的内容:
 3. 其他一些小知识
3. 其他一些小知识
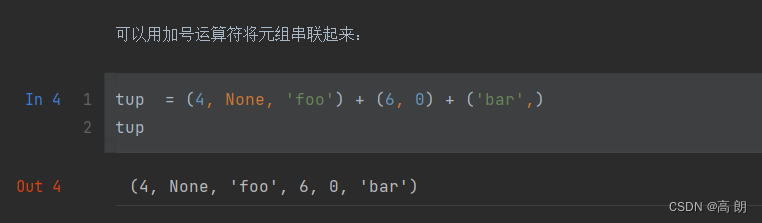
(1)可以通过加号将多个元组串联起来
 (2)元组乘以一个整数,像列表一样,会将几个元组的复制串联起来:(对象本身并没有被复制,只是引用了它)
(2)元组乘以一个整数,像列表一样,会将几个元组的复制串联起来:(对象本身并没有被复制,只是引用了它)

(3)元组可以拆分
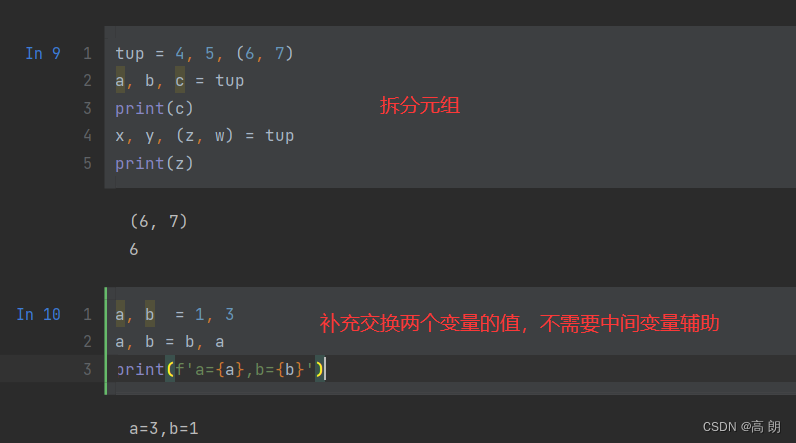 如何只需要元组的前两个值,后面的不需要,舍弃,该怎么操作:
如何只需要元组的前两个值,后面的不需要,舍弃,该怎么操作:

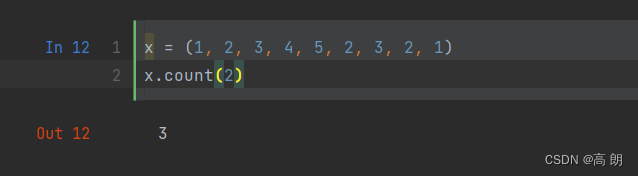
(4)count方法,也适用于列表,可以统计某个值得出现频率:
列表
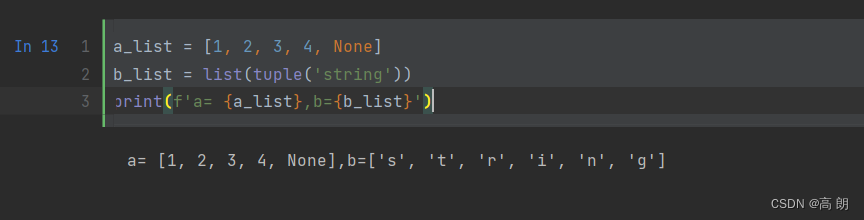
与元组对比,列表的长度可变、内容可以被修改。你可以用方括号定义,或用list函数:
- 创建
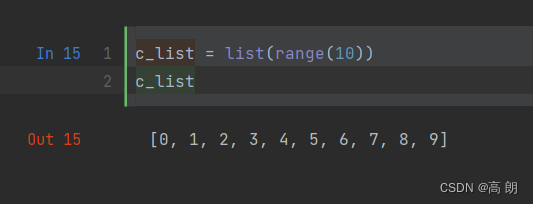
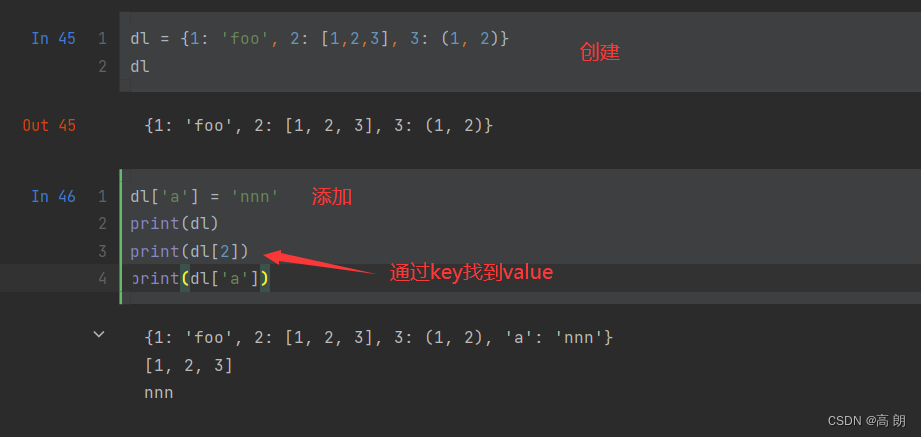
2. 添加元素
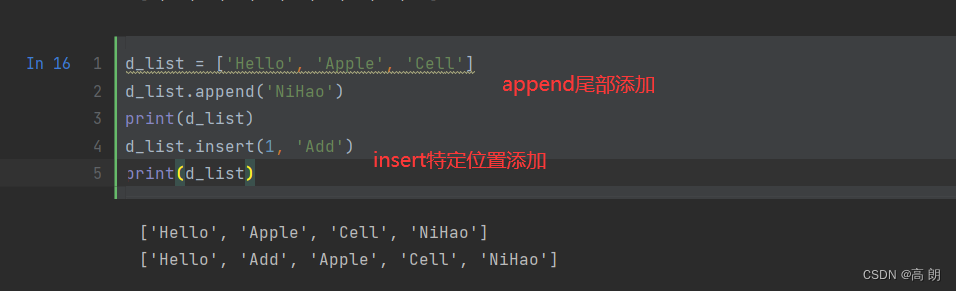
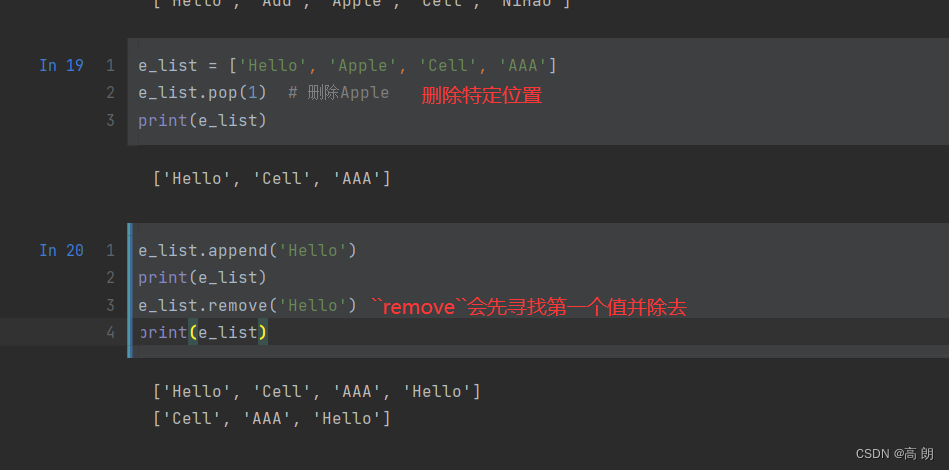
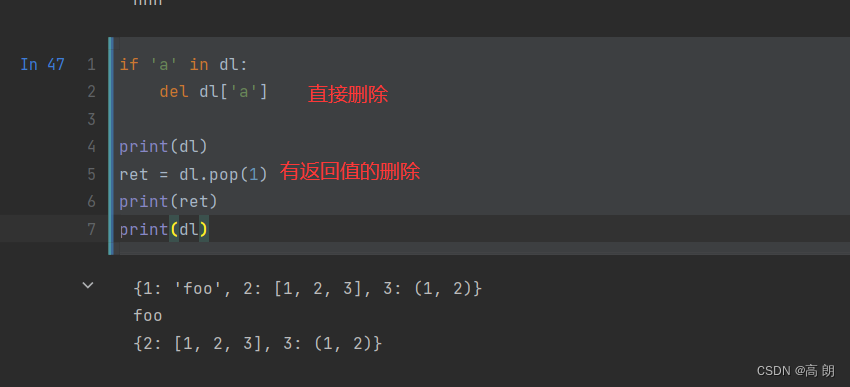
3. 删除元素
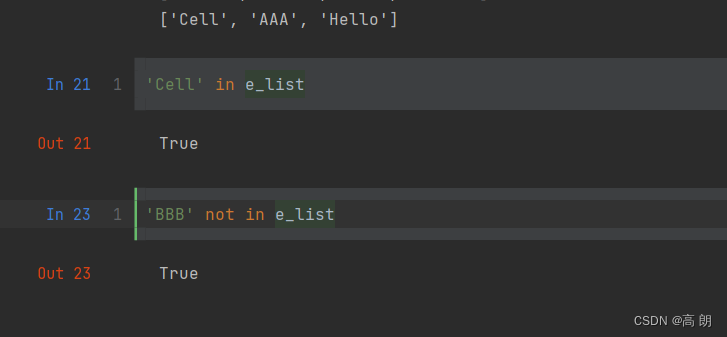
4. 用in可以检查列表是否包含某个值:
5. 与元组类似,可以用加号将两个列表串联起来:
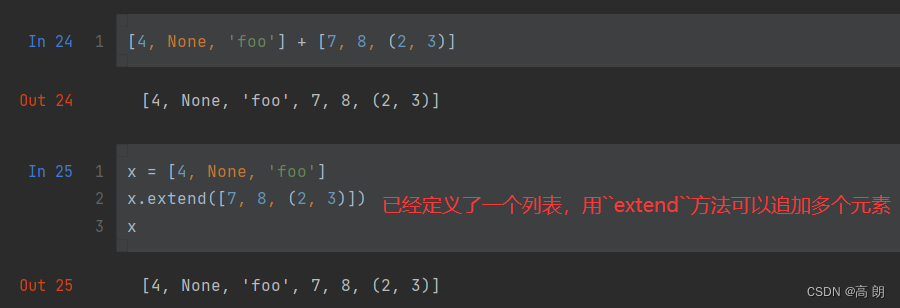

6. 排序
(1)sort 将一个列表原地排序(不创建新的对象)
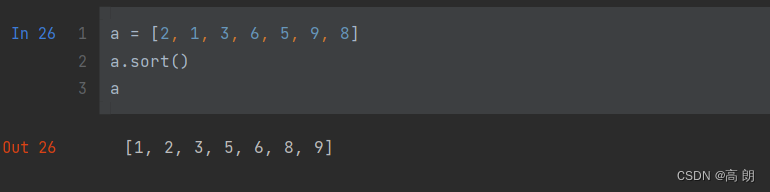
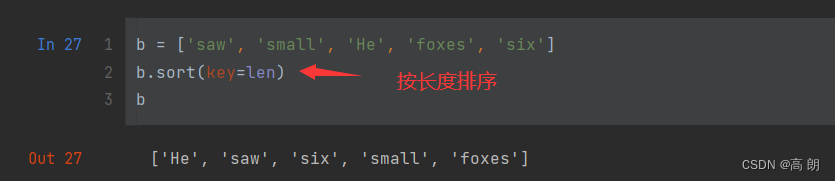
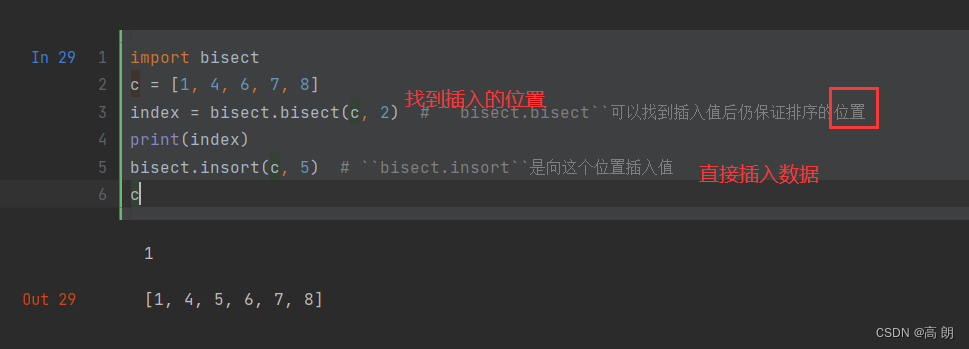
(2)二分法插入数据(bisect模块不会检查列表是否已排好序,进行检查的话会耗费大量计算。因此,对未排序的列表使用bisect不会产生错误,但结果不一定正确)
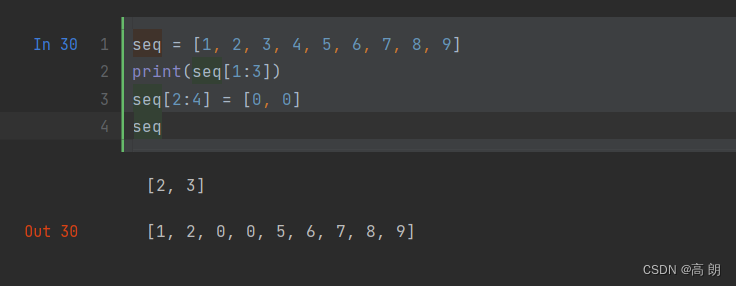
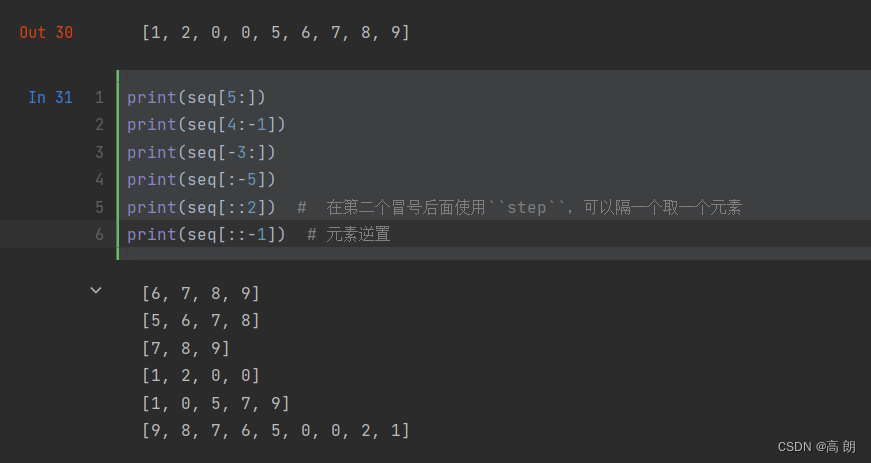
- 切片操作
切片输出,赋值。切片的起始元素是包括的,不包含结束元素
- 序列函数
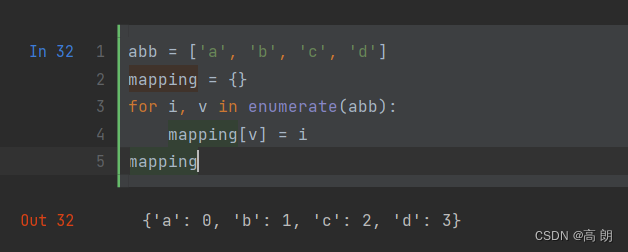
enumerate
sorted函数
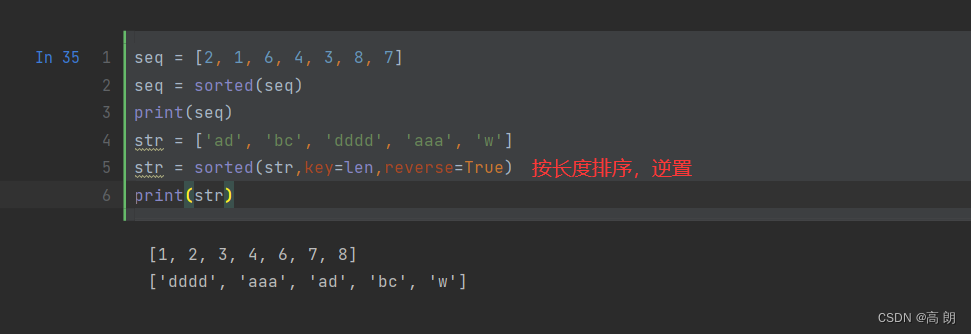
sorted函数可以从任意序列的元素返回一个新的排好序的列表:
- zip函数
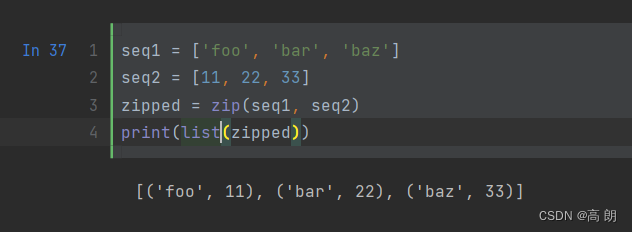
zip可以将多个列表、元组或其它序列成对组合成一个元组列表:
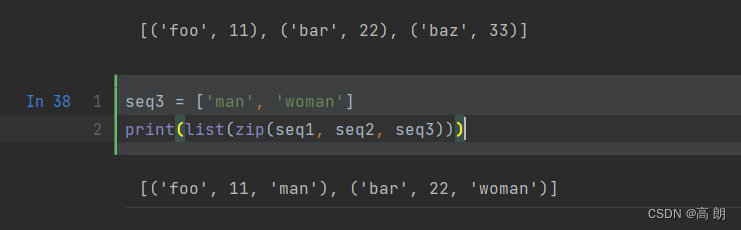
zip可以处理任意多的序列,元素的个数取决于最短的序列:
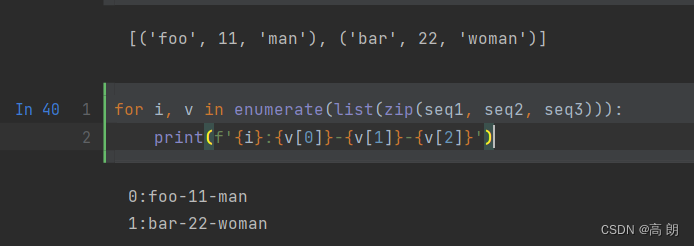
zip的常见用法之一是同时迭代多个序列,可能结合enumerate使用:
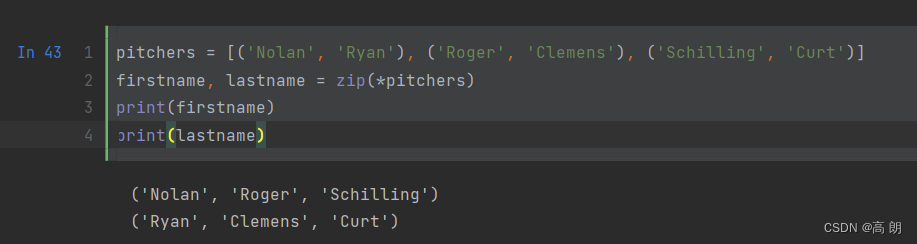
给出一个“被压缩的”序列,zip可以被用来解压序列。也可以当作把行的列表转换为列的列表。
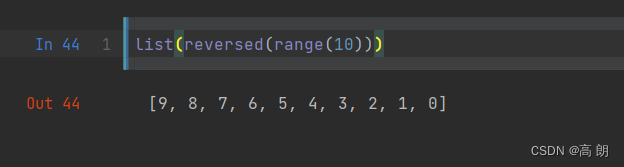
11. reversed函数
reversed可以从后向前迭代一个序列:
字典
哈希映射或关联数组。它是键值对的大小可变集合,键和值都是Python对象。创建字典的方法之一是使用尖括号,用冒号分隔键和值:
 将两个序列配对组合成字典:
将两个序列配对组合成字典:
mapping = {}
for key, value in zip(key_list, value_list):
mapping[key] = value
或:
mapping = dict(zip(key_list, value_list))
找某个key的value,没有返回default_value:
value = some_dict.get(key, default_value)
通过首字母分类:
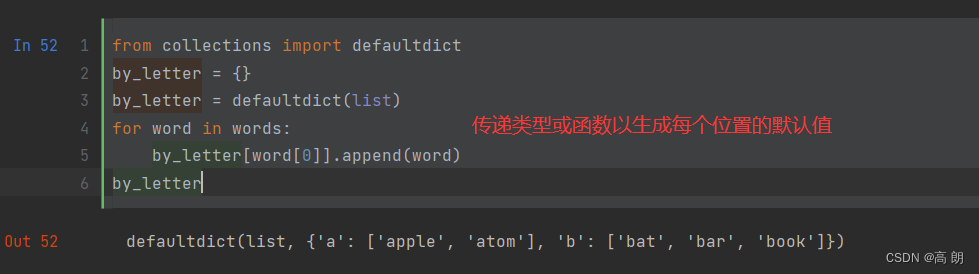
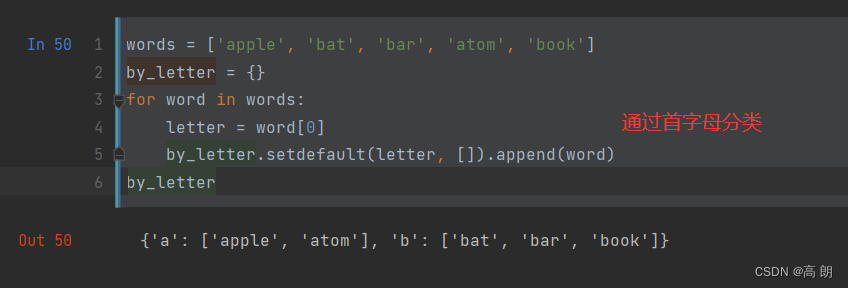 或:
或:
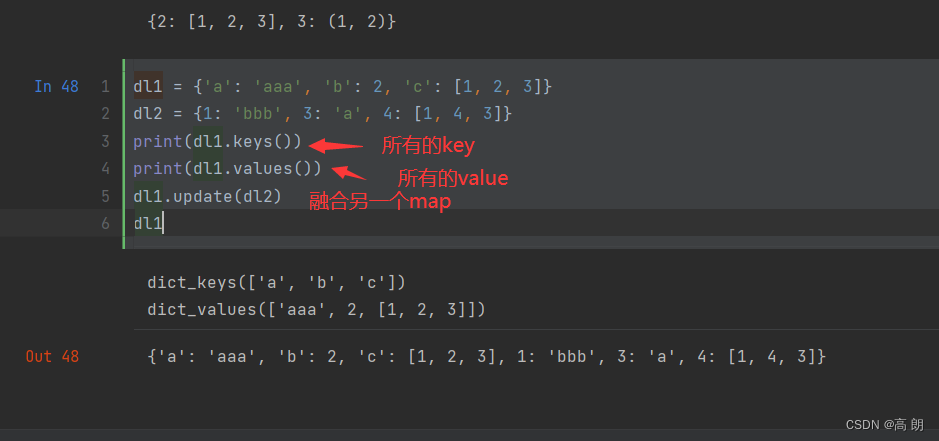
 字典的值可以是任意Python对象,而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的)。
字典的值可以是任意Python对象,而键通常是不可变的标量类型(整数、浮点型、字符串)或元组(元组中的对象必须是不可变的)。
集合
集合是无序的不可重复的元素的集合。你可以把它当做字典,但是只有键没有值。可以用两种方式创建集合:通过set函数或使用尖括号set语句:
set([2, 2, 2, 1, 3, 3]) #{2, 2, 2, 1, 3, 3}
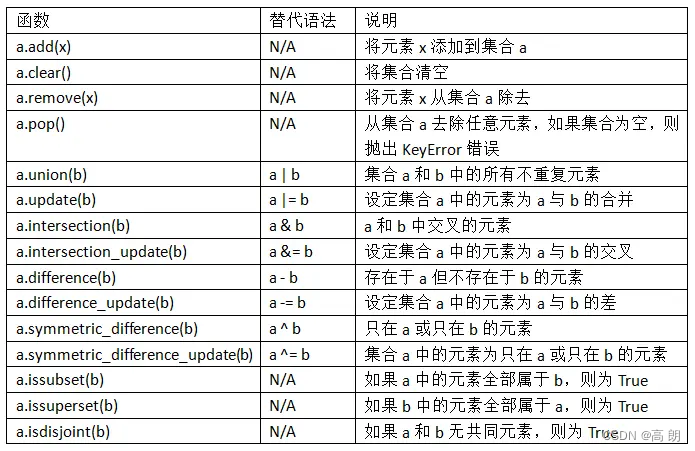
相关用法:
推导式
- 列表、集合和字典推导式
result = [expr for val in collection if condition]
等价于:
result = []
for val in collection:
if condition:
result.append(expr)
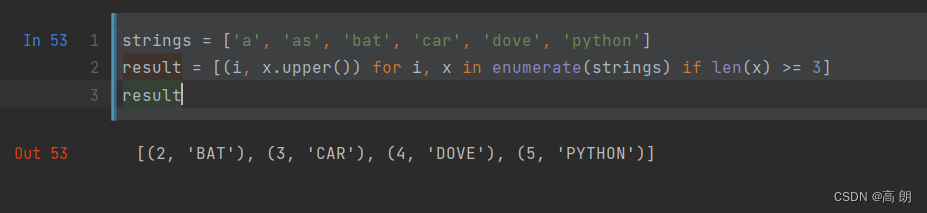
示例:
 字典:
字典:
dict_comp = {key-expr : value-expr for value in collection if condition}
集合:
set_comp = {expr for value in collection if condition}
- 嵌套列表推导式
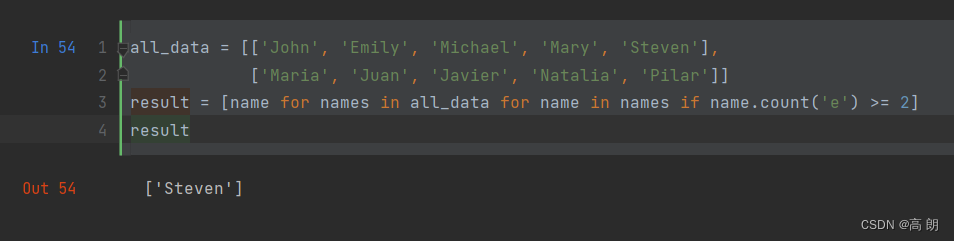 元组展平:
元组展平:
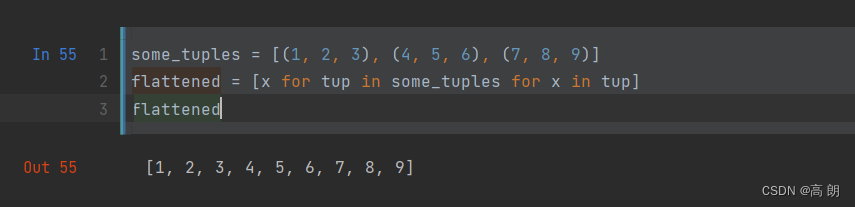 for表达式的顺序是与嵌套for循环的顺序一样(而不是列表推导式的顺序)
for表达式的顺序是与嵌套for循环的顺序一样(而不是列表推导式的顺序)
上述还原代码:
flattened = []
for tup in some_tuples:
for x in tup:
flattened.append(x)

函数
函数使用def关键字声明,用return关键字返回值:
def my_function(x, y, z=1.5):
if z > 1:
return z * (x + y)
else:
return z / (x + y)
其他一些特色:
(1)可返回多个值:【该函数其实只返回了一个对象,也就是一个元组,最后该元组会被拆包到各个结果变量中】
def f():
a = 5
b = 6
c = 7
return a, b, c
a, b, c = f()
(2)用内建的字符串方法和正则表达式re模块去除空白符、删除各种标点符号、正确的大写格式等
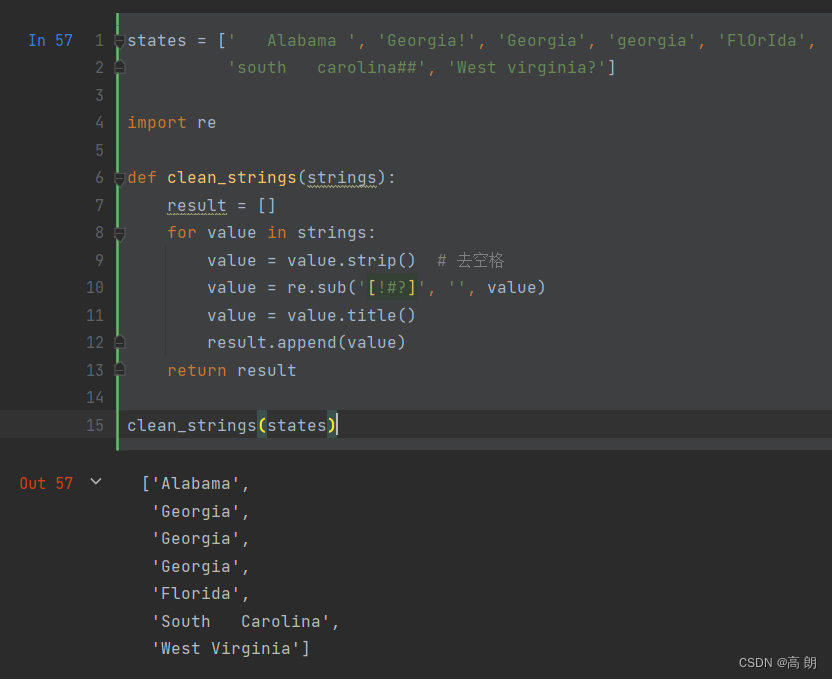 等价于:
等价于:
def remove_punctuation(value):
return re.sub('[!#?]', '', value)
clean_ops = [str.strip, remove_punctuation, str.title]
def clean_strings(strings, ops):
result = []
for value in strings:
for function in ops:
value = function(value)
result.append(value)
return result
还可以将函数用作其他函数的参数,比如内置的map函数,它用于在一组数据上应用一个函数:
for x in map(remove_punctuation, states):
print(x)
(3)匿名(lambda)函数
它仅由单条语句组成,该语句的结果就是返回值。它是通过lambda关键字定义的,这个关键字没有别的含义,仅仅是说“我们正在声明的是一个匿名函数”。
def short_function(x):
return x * 2
# 等价
equiv_anon = lambda x: x * 2
常见用法:
def apply_to_list(some_list, f):
return [f(x) for x in some_list]
ints = [4, 0, 1, 5, 6]
apply_to_list(ints, lambda x: x * 2)
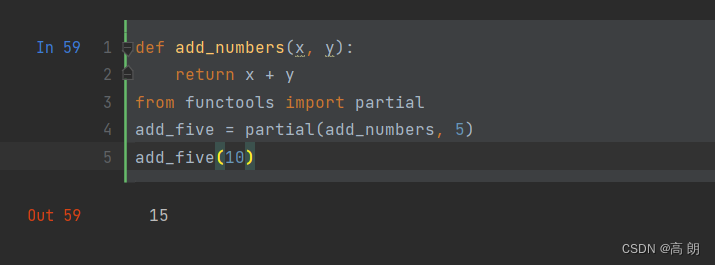
 (4)柯里化:部分参数应用,对于某些函数,我们可以直接给定某些参数,方便后面调用
(4)柯里化:部分参数应用,对于某些函数,我们可以直接给定某些参数,方便后面调用
 (5)生成器
(5)生成器
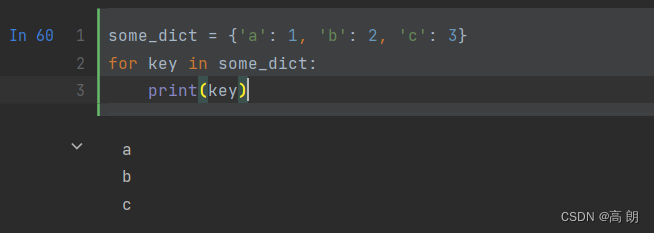
可以用下面迭代器代码来代替上面:
ict_iterator = iter(some_dict) # 迭代器是一种特殊对象
list(dict_iterator)
生成器(generator)是构造新的可迭代对象的一种简单方式。一般的函数执行之后只会返回单个值,而生成器则是以延迟的方式返回一个值序列,即每返回一个值之后暂停,直到下一个值被请求时再继续。要创建一个生成器,只需将函数中的return替换为yeild即可:
def squares(n=10):
print('Generating squares from 1 to {0}'.format(n ** 2))
for i in range(1, n + 1):
yield i ** 2
调用该生成器时,没有任何代码会被立即执行,直到你从该生成器中请求元素时,它才会开始执行其代码:
gen = squares() # 并不会立即执行
for x in gen: # 该生成器中请求元素,开始执行
print(x, end=' ')
(6)生成器表达式
另一种更简洁的构造生成器的方法是使用生成器表达式(generator expression)。这是一种类似于列表、字典、集合推导式的生成器。其创建方式为,把列表推导式两端的方括号改成圆括号:
gen = (x ** 2 for x in range(100))
# 等价于
def _make_gen():
for x in range(100):
yield x ** 2
gen = _make_gen()
(7)itertools模块
标准库itertools模块中有一组用于许多常见数据算法的生成器。例如,groupby可以接受任何序列和一个函数。它根据函数的返回值对序列中的连续元素进行分组。下面是一个例子:
import itertools
first_letter = lambda x: x[0]
names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven']
for letter, names in itertools.groupby(names, first_letter):
print(letter, list(names)) # names is a generator
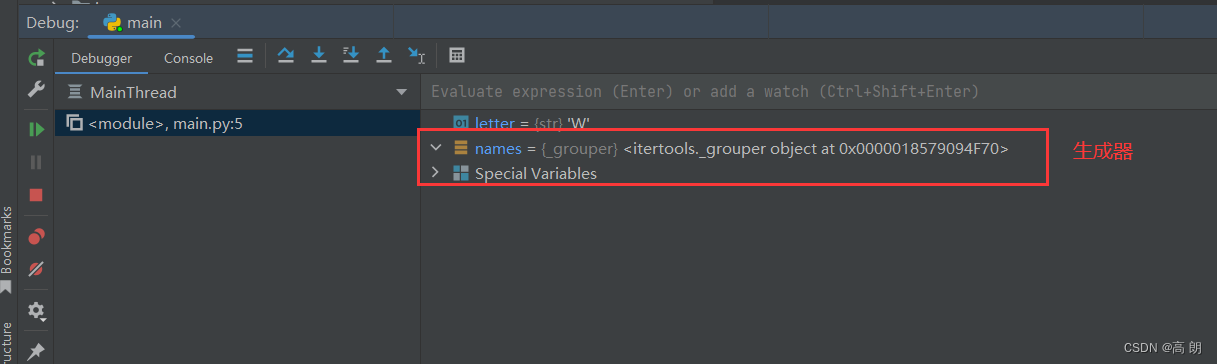 常用到的itertools函数:
常用到的itertools函数:

错误和异常处理
(1)把有异常放到try/except代码块中处理
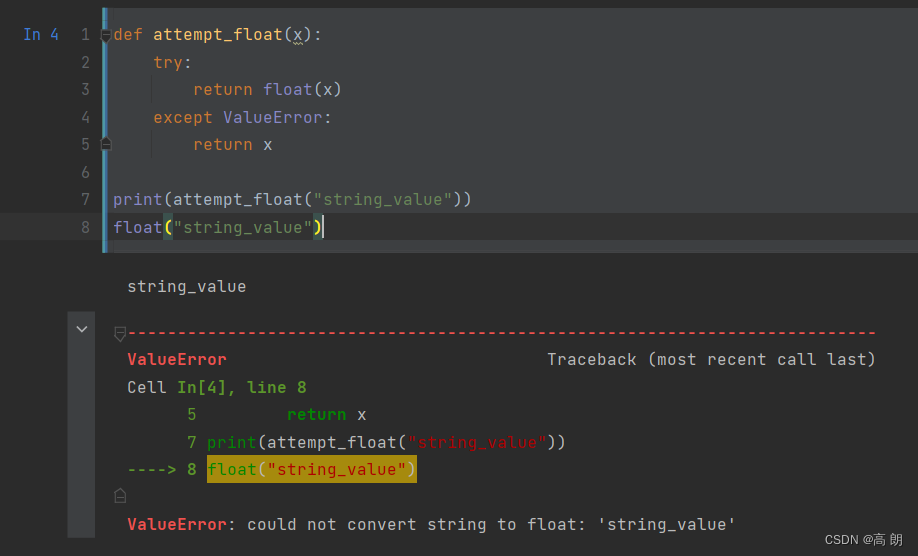
except去捕获异常时,可以元组指定异常的类型(多个异常类型),如果需要捕获所以异常就不需要指定。
常见的文件处理:
f = open(path, 'w')
try:
write_to_file(f)
except:
print('Failed')
else:
print('Succeeded')
finally:
f.close()
文件和操作系统
(1)简单的文件操作
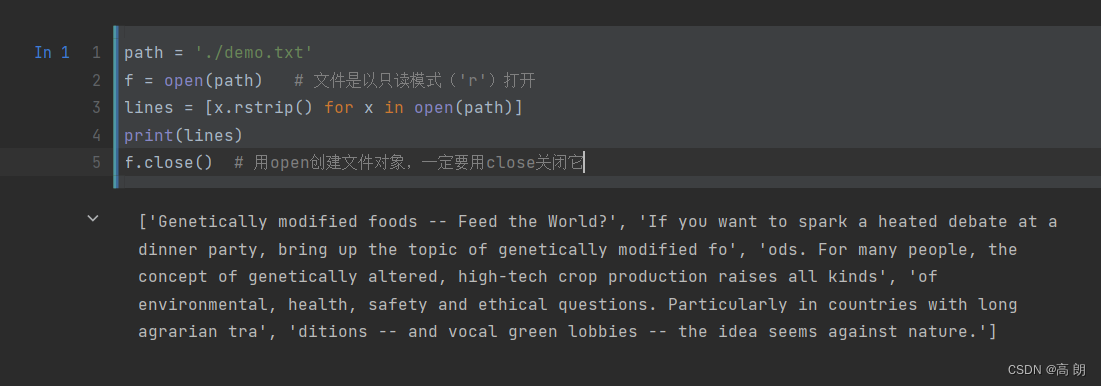 常常用
常常用with语句来代替上面的:这样可以在退出代码块时,自动关闭文件。
with open(path) as f:
lines = [x.rstrip() for x in f]
关于open()第二参数说明,默认是f = open(path, 'r')
 对于可读文件,一些常用的方法是read、seek和tell。read会从文件返回字符。字符的内容是由文件的编码决定的(如UTF-8):
对于可读文件,一些常用的方法是read、seek和tell。read会从文件返回字符。字符的内容是由文件的编码决定的(如UTF-8):
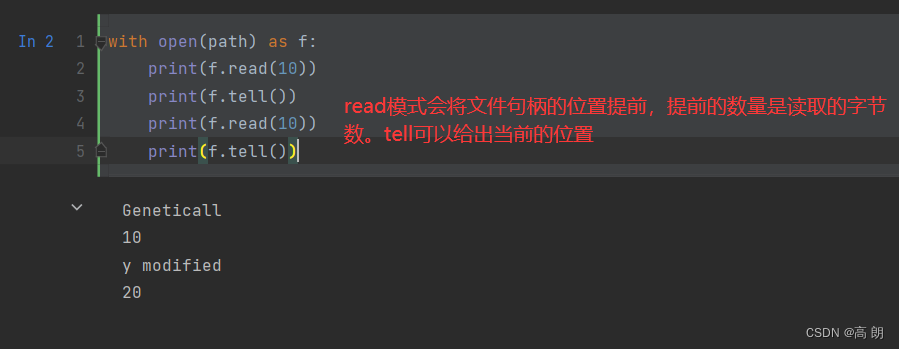
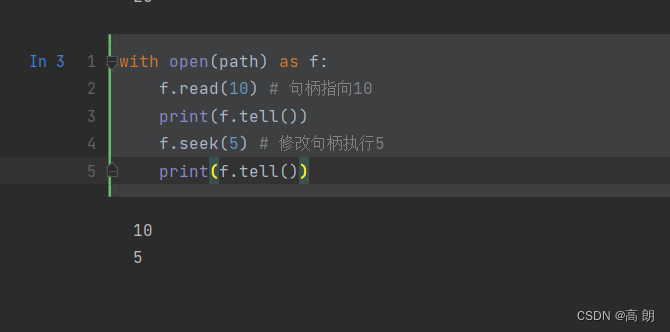
改变句柄的位置使用seek函数
写文件:
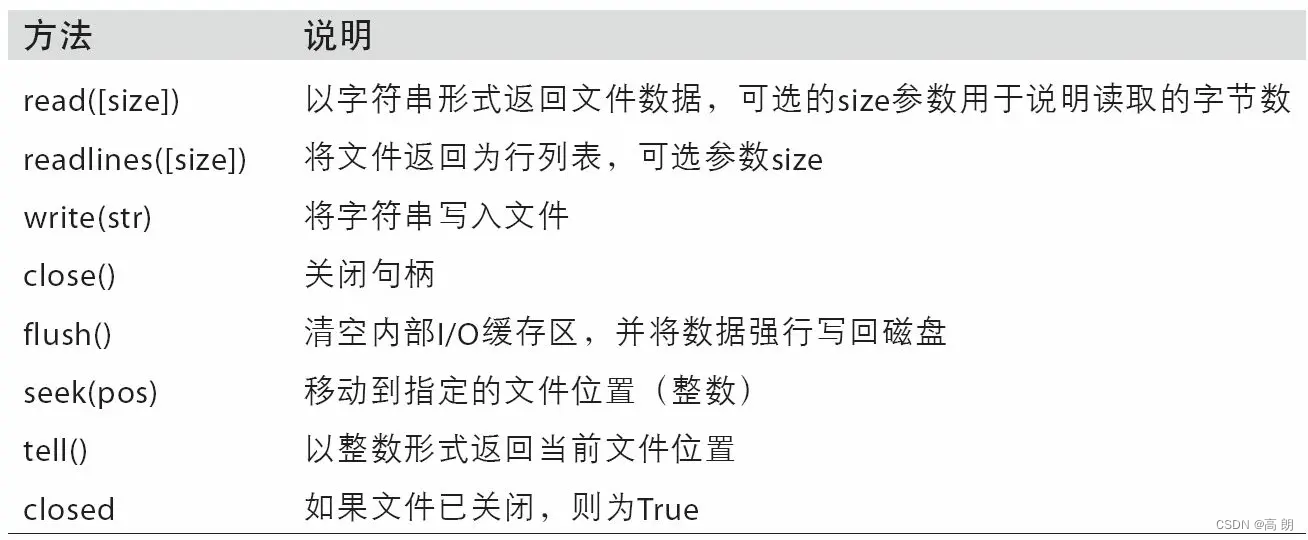
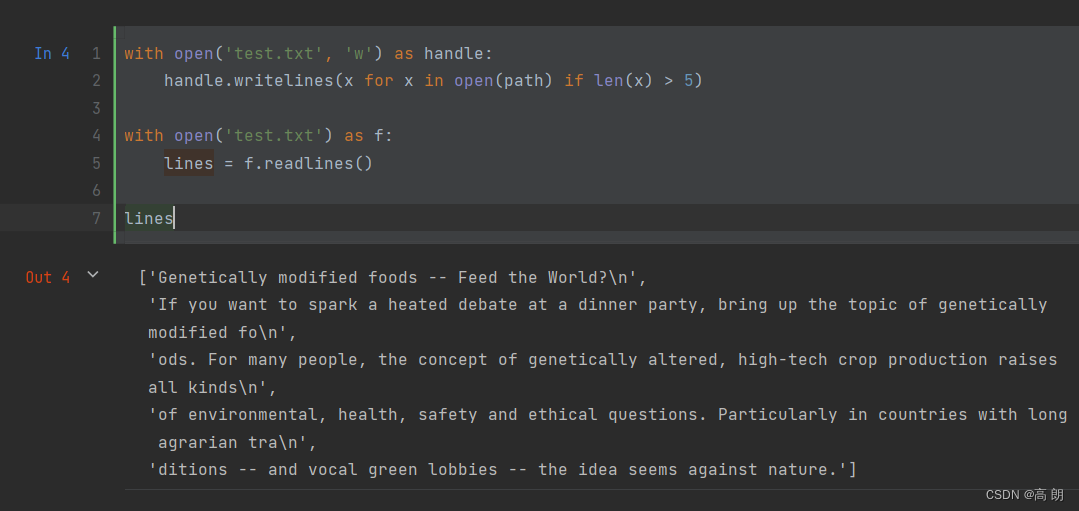 其他方法:
其他方法: