PgSQL-向量数据库插件-lantern
即pgvector、pg_embedding 后又一向量数据库扩展Lantern问世了。当然也为向量列提供了hnsw索引以加速ORDER BY... LIMIT查询。Lantern使用usearch实现hnsw。
使用方法
保留了标准PgSQL接口,兼容其生态工具。首先需要安装该插件:
CREATE EXTENSION lantern;创建一个包含向量列的表,并添加数据:
CREATE TABLE small_world (id integer, vector real[3]);
INSERT INTO small_world (id, vector) VALUES (0, '{0,0,0}'), (1, '{0,0,1}');在表上创建hnsw索引:
CREATE INDEX ON small_world USING hnsw (vector);根据向量数据自定义hnsw索引参数,例如距离函数(dist_l2sq_ops)、索引构建参数和索引搜索参数:
CREATE INDEX ON small_world USING hnsw (vector dist_l2sq_ops)
WITH (M=2, ef_construction=10, ef=4, dim=3);开始查询:
SET enable_seqscan = false;
SELECT id, l2sq_dist(vector, ARRAY[0,0,0]) AS dist
FROM small_world ORDER BY vector <-> ARRAY[0,0,0] LIMIT 1;关于运算符
Lantern在索引上支持的多种距离函数。只需要创建索引时指定用于列的距离函数,Lantern会自动推断用于搜索的距离函数进行查询,因此查询中使用<->操作符。
请注意,该运算符<->专门用于索引查找。如果您希望在查询中不使用索引,则直接使用距离函数(例如l2sq_dist(v1, v2))
在创建索引期间可以使用四个已定义的运算符类:
1)dist_l2sq_ops:类型的默认值real[]
2)dist_vec_l2sq_ops:类型的默认值vector
3)dist_cos_ops:适用类型real[]
4)dist_hamming_ops: 适用类型integer[]
索引构建参数
M, ef, 和ef_construction参数控制hnsw算法的性能:
1)通常以召回代价降低M和ef_construction值来加快索引创建速度
2)较低的M和ef值可以提高查询性能,以召回为代价减少共享缓冲区命中率。
特点
1)流行用例(CLIP 模型、Hugging Face 模型、自定义模型)的嵌入生成
2)与 pgvector 数据类型的互操作性,因此任何使用 pgvector 的人都可以切换到 Lantern
3)通过外部索引器创建并行索引
4)够在数据库服务器外部生成索引图
5)支持在数据库外部和另一个实例内部创建索引,使您可以在不中断数据库工作流程的情况下创建索引
6)查看所有helper函数以了解使用方法
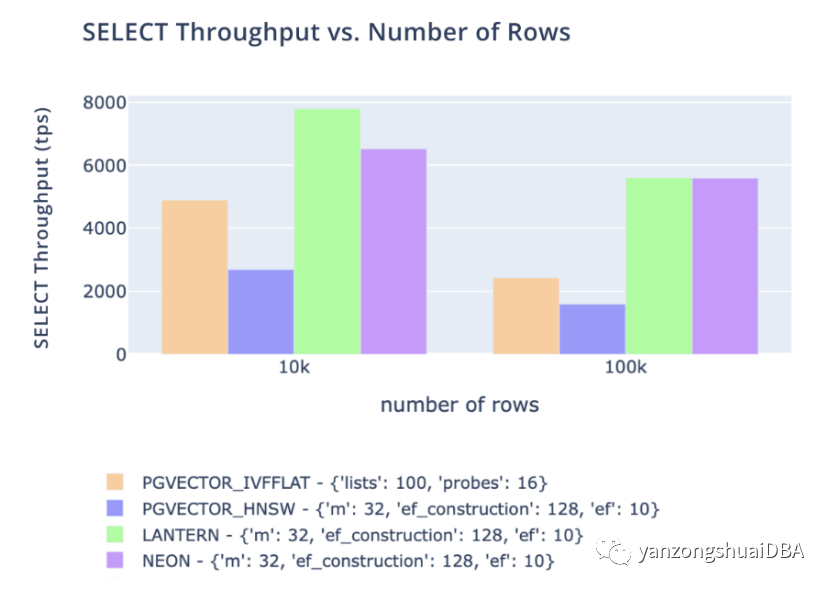
性能
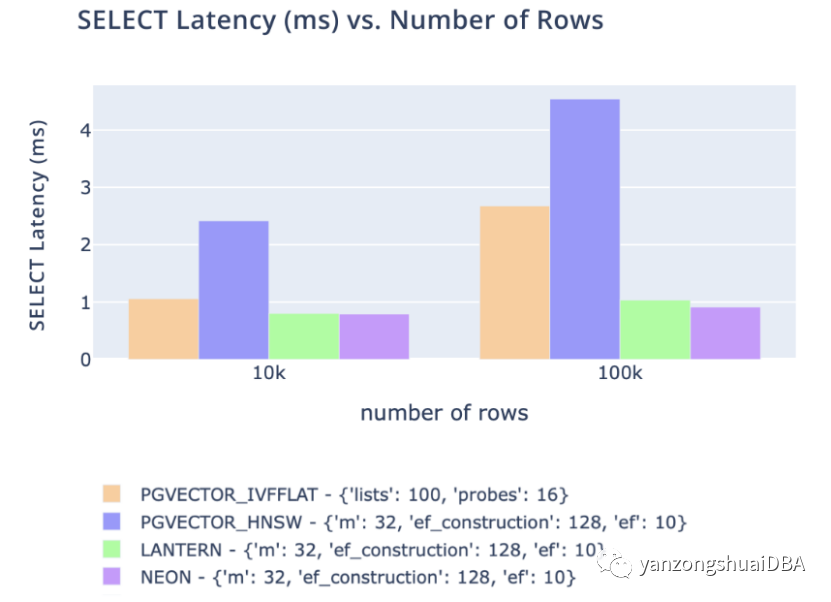
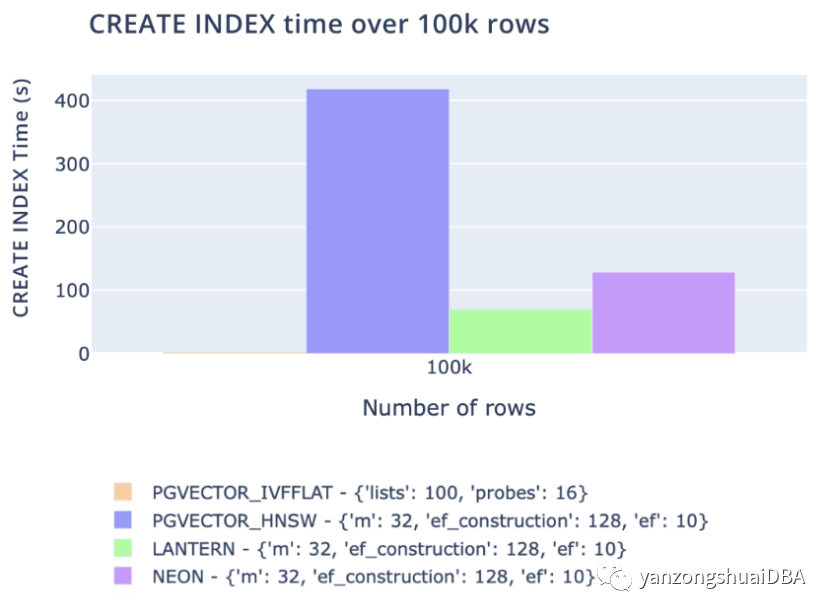
1)我们跟踪三个关键指标。CREATE INDEX时间、SELECT吞吐量和SELECT延迟。
2)我们在所有这些指标上都匹配或优于 pgvector 和 pg_embedding (Neon)。
3)我们计划继续进行性能改进,以确保我们是性能最佳的数据库。
路线图
1)Lantern 的云托管版本 -注册更新
2)为您的 CPU 量身定制的硬件加速距离指标,可实现更快的查询
3)用于构建不同行业应用程序的模板和指南
4)更多用于生成嵌入的工具(支持第三方模型 API、更多本地模型)
5)支持版本控制和 A/B 测试嵌入
6)自动调整的索引类型将选择适当的创建参数
7)支持 1 字节和 2 字节向量元素,以及最多 8000 个维度向量 ( PR #19 )
8)请通过support@lantern.dev请求功能
原文及代码
https://github.com/lanterndata/lantern