一,Requests库
1,主要使用方法:

1)get()方法:

这个Response对象中包含爬虫返回的内容。

除了request方法是基础方法外,其他都是通过调用request方法来实现的。
所以,我们甚至可以这么理解,Requests库只有一种方法request方法,为了使编程更加方便,所以就有了另外的六种方法。
以get方法为例:

2)Response 对象的属性:

流程图:

3)Response的编码:

网络上的资源都有着对应各自的编码,如果我们不知道资源的编码方式,那资源对于我们而言就是不可读的。
r.encoding;如果header中不存 在charset,则认为编码为ISO-8859-1。
原则上来说,后者比前者更加准确,因为前者并没有分析内容,而只是从header中的相关字段提取编码,进行猜测。而后者则是在实实在在的分析内容,并且找到其中可能的编码。
2,爬取网页的通用代码框架:
就是一组代码,可以准确的爬取网页内容。
我们要知道,get方法是不一定成功的,因为网络连接是有分线的,所以对于程序来说,异常处理就显得很重要。
Requests库支持六种常用的连接异常:


import requests
def ge tHTMLText (ur1) :
try:
r = requests . get (url, timeout =30)
r.raise_ for_ status () #如果状态不是200,引发HTTPError异常
r . encoding = r. apparent encoding
return r. text
except :
return "产生异常”
if __name__==”__main__ " :
url = "http: //www . baidu . com"
print (ge tHTMLText (ur1) )

也就是说,通用代码框架最大的作用是能够使得用户访问或爬取网页变得更有效更稳定。
3,HTTP协议对资源的操作:
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。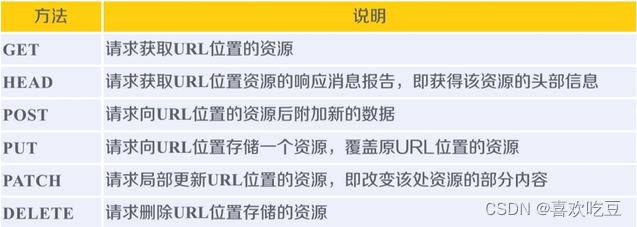
六个方法就是Requests库提供的六个主要函数所对应的功能。

HTTP协议通过URL对资源做定位,通过这六个方法对资源进行管理,每一次操作都是独立无状态的,也就是说这个操作和下一个操作是不相关的。
在HTTP协议的世界里,网络通道和服务器都是黑盒子,它能看到的只有URL链接以及对URL链接的操作。
理解PATCH和PUT的区别
假设URL位置有一组数据UserInfo, 包括UserID、 UserName等20个字段。
需求:用户修改了UserName,其他不变。
采用PATCH,仅向URL提交UserName的局部更新请求。
采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除。
PATCH的最主要好处:节省网络带宽
![[React] React高阶组件(HOC)](https://img-blog.csdnimg.cn/be8e8a46e294468ba9112d4e77ee66a8.png)