前言
前面我们介绍了C++11列表初始化、新的类功能以及右值引用等新特性,本文继续介绍关于可变参数模板以及lambda表达式等新语法;
一、可变参数模板
在C++11前,我们有普通固定数量模板参数,但对于可变参数,我们无从下手,而在C++11后,推出了可变模板参数;使形参可以接收0个至多个不同或同种类型的参数;以下为具体代码;
template<class ...Args>
void showList(Args... args)
{
// ...
}其中,Args就是可变参数类型名,也可以取别的名字,args我们称这个为参数包,同样也可以取别的名字;该参数包可以接收0个甚至多个参数;关于这个参数包的解析方式,我们可以使用以下两种方式;
1、关于解包的两种方式
// 方法一:递归取参
void showList()
{
cout << endl;
}
template<class T, class ...Args>
void showList(const T& t, Args... args)
{
cout << t << " ";
showList(args...);
}
void test13()
{
showList();
showList(1);
showList(1, 'x');
showList(1, 1.11, 'y');
}// 方式二:利用数组自动推导元素个数
template <class T>
void PrintArg(T t)
{
cout << t << " ";
}
template <class ...Args>
void ShowList(Args... args)
{
// 逗号表达式
int arr[] = { 0, (PrintArg(args), 0)...};
cout << endl;
}
void test13()
{
ShowList();
ShowList(1);
ShowList(1, 'x');
ShowList(1, 1.11, 'y');
}2、emplace系类接口
emplace系列接口都为插入接口;其是采用了参数包的方式进行传参;STL中大部分容器都提供了这个插入接口;例如下面几个;


那么emplace插入接口与普通的插入接口有什么区别呢?这里我用vector来举例;
void test14()
{
list<MySpace::string> l1;
MySpace::string str1("hello");
// 无区别
l1.push_back(str1); // 深拷贝
l1.emplace_back(str1); // 深拷贝
cout << endl << endl;
// 无区别
l1.push_back(move(str1)); // 移动构造
l1.emplace_back(move(str1)); // 移动构造
cout << endl << endl;
// 有区别
l1.push_back("11111"); // 拷贝构造 + 移动构造
l1.emplace_back("11111"); // 直接构造
}二、lambda
1、初始lambda
我们经常会写出类似以下代码;
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
struct CmpByPriceLess
{
bool operator()(const Goods& x, const Goods& y)
{
return x._price < y._price;
}
};
struct CmpByPriceGreater
{
bool operator()(const Goods& x, const Goods& y)
{
return x._price > y._price;
}
};
void test1()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
// 价格升序
sort(v.begin(), v.end(), CmpByPriceLess());
// 价格降序
sort(v.begin(), v.end(), CmpByPriceGreater());
}使用sort的时候我们需要使用传入仿函数;你会不会有给这个仿函数传入何名称而感到烦恼呢?C++11中,推出了一种新玩法,便是我们的lambda;
2、lambda的使用
lambda的具体格式如下;
[ capture-list ]( parameters ) mutable -> return-type { statement };
看了上面的你或许还是有点懵,我们粗略的使用一下;
void test1()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
// 价格升序
//sort(v.begin(), v.end(), CmpByPriceLess());
// 价格降序
//sort(v.begin(), v.end(), CmpByPriceGreater());
// 价格升序
sort(v.begin(), v.end(), [](const Goods& x, const Goods& y)mutable->bool
{
return x._price < x._price;
});
// 价格降序
sort(v.begin(), v.end(), [](const Goods& x, const Goods& y)mutable->bool
{
return x._price > x._price;
});
}首先我们介绍方括号中的是我们的捕捉列表,可以捕捉上下文中的变量供lambda函数使用;具体有以下几种捕捉方式;
[var]:值捕捉;此时我们仅仅只是传值,lambda函数内修改值不会影响lambda外被捕捉的值;默认情况下,我们捕捉的值都是带const属性的,我们增肌mutable关键字可以使var可以修改(不改变lambda外被捕捉的值);
[ = ]:全部值传递,捕捉上文中所有变量,且值传递给lambda函数;
void test2()
{
int a = 3;
int b = 5;
// 值捕捉
auto add = [a, b]()mutable->int
{
a++;
return a + b;
};
// 全部值捕捉(若无参数,括号可省略;一般情况下,返回值也可以省略)
// 如果不期望修改值传递进来的值,mutable也可以省略;
auto sub = [=] { return a - b; };
cout << add() << endl;
cout << sub() << endl;
cout << a << endl;
}[ var& ]:引用传递,将某个值通过引用传递的方式传给lambda函数;我们在lambda函数内修改该值,由于是引用传递,也会影响该值本身;
[ & ]:将上文的所有变量通过引用的方式进行捕捉;
void test3()
{
int x = 3;
int y = 4;
// 若添加了mutable则圆括号不可省略
auto f1 = [&x, y]()mutable {x = 1; y = 2; };
f1();
cout << x << " " << y << endl;
// 将上文所有变量以引用的方式进行捕捉
auto f2 = [&] {x = 10; y = 20; };
cout << x << " " << y << endl;
}[ this ]:捕获当前类的this指针;实际上之前的=在类内也会捕捉this指针,只不过是以值传递的方式;而&则是以引用的传递方式;
class A
{
public:
void func()
{
// 捕获当前类的this指针
auto f1 = [this] {cout << _a << endl; };
}
private:
int _a = 0;
};我们再看圆括号,实际上,圆括号类似于函数中的圆括号,是用来进行接收参数的;mutable前面已经介绍过了, 对于普通值传递通常加上了const修饰,加了mutable以后,值传递就没有用const修饰了;箭头后面为返回值,返回值一般可有可无;花括号则是我们的函数体了;
3、lambda的底层原理
前面我们看了lambda的使用,那么lambda的底层原理又是什么呢?在此之前,我们回答一个问题,类似的lambda可以相互赋值吗?如下代码;
// 是否正确?
void test3()
{
auto f1 = [](int x, int y) {return x + y; };
//auto f2 = [](int x, int y) {return x + y; };
auto f2 = [](int x, int y) {return x - y; };
f1 = f2;
}实际上,不管我们是类似还是完全相同,我们都不能进行赋值,这是为什么呢?看起来不是完全相同吗?还有我们的lambda函数的本质到底是什么类型呢?我用下面一段代码来解释这些问题;
struct Fun
{
int operator()(int x, int y)
{
return x + y;
}
};
void test4()
{
auto f1 = [](int x, int y) { return x + y; };
Fun f2;
// 调用lambda函数
f1(2, 5);
// 调用仿函数
f2(2, 5);
}我们看到代码转汇编后的结果;
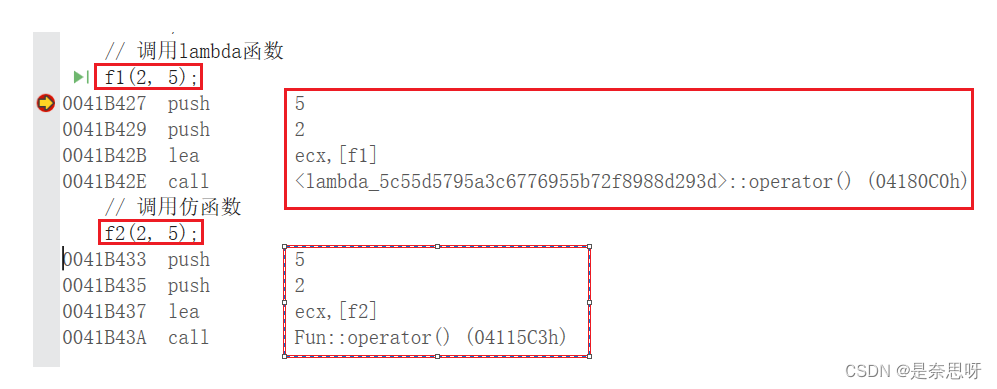
我们发现两段代码转汇编后的结果几乎相同;没错,我们的lambda实际上就是仿函数,只不过编译器会自动帮我们生成类型,这个类名是lambda_ + UUID;UUID是唯一标识符;因此我们虽然看起来像相同的lambda函数,实际上,它们是类名不同的仿函数,既然类型不同,又如何相互赋值呢?前面的问题不就迎刃而解了么;
三、包装器
1、初始function
我们的包装器,也叫做适配器;主要包装可调用对象;C++中,可调用对象有哪些呢?有我们C语言学的函数指针,有我们前面学的仿函数,还有我们刚刚学的lambda函数;我们可以对其进行同一的封装;如下代码所示;
struct ADD
{
int operator()(int x, int y)
{
return x + y;
}
};
int add(int x, int y)
{
return x + y;
}
void test5()
{
// 包装器封装仿函数
function<int(int, int)> f1 = ADD();
// 包装器封装函数指针
int(*pf)(int, int) = add;
function<int(int, int)> f1 = pf;
// 包装器封装lambda函数
function<int(int, int)> f1 = [](int x, int y) { return x + y; };
}包装器出了可以封装上面的一些常规函数,还可以包装我们类中的成员函数;如下所示;
class A
{
public:
// 静态成员函数
static int func1(int x, int y)
{
return x + y;
}
// 普通成员函数
int func2(int x, int y)
{
return x + y;
}
private:
};
void test6()
{
// 封装静态成员函数(类名前可加&也可不加)
//function<int(int, int)> f1 = A::func1;
function<int(int, int)> f1 = &A::func1;
// 封装普通成员函数(类型前必须加&,语法规定,且参数列表中声明类名)
function<int(A, int, int)> f2 = &A::func2;
}2、包装器的使用场景
包装器的主要使用在一些需要对函数统一处理的场景,比如,我们有一个vector,其中存的是一些返回值,形参相同的可调用对象;但这些可调用对象可能是仿函数,可能是函数指针,也可能是lambda函数,这时它们并不是同一类,我们只能通过仿函数将其封装归为一类;
struct functor
{
int operator()(int x, int y)
{
return x - y;
}
};
int mul(int x, int y)
{
return x * y;
}
void test7()
{
vector<function<int(int x, int y)>> vfs;
// lambda函数
vfs.push_back([](int x, int y)-> int {return x + y; });
// 仿函数
functor ft;
vfs.push_back(ft);
// 函数指针
int(*ptr)(int, int) = mul;
vfs.push_back(ptr);
}3、bind
bind定义在头文件functional中,它更像一个函数模板的适配器,而上面的function是类模板的适配器;bind主要有两个功能,分别为调整参数顺序与调整参数个数;下面我们一一进行展示;
// 调整参数顺序
void Func1(int x, int y)
{
cout << x << " " << y << endl;
}
void test8()
{
// 调整参数顺序
Func1(10, 20);
// placeholder为命名空间,_1,_2....._n都为调整的参数顺序
auto f1 = bind(Func1, placeholders::_2, placeholders::_1);
// 写法二
function<void(int, int)> f2 = bind(Func1, placeholders::_2, placeholders::_1);
f1(10, 20);
}// 调整参数个数
class Cal
{
public:
Cal(double rate = 2.5)
:_rate(rate)
{}
double cal(int x, int y)
{
return (x + y) * _rate;
}
private:
double _rate;
};
void test9()
{
int x = 3;
int y = 6;
Cal c1;
cout << c1.cal(x, y) << endl;
// 调整参数个数
auto func2 = bind(&Cal::cal, c1, placeholders::_1, placeholders::_2);
cout << func2(x, y) << endl;
}实际上,调整参数个数就是在我们的bind中显示的传入该参数;
四、线程库
在C++11后,推出了一种面向对象的线程操作手段;对比于以前不仅仅是有面向对象这一好处,实际上,还解决了跨平台的问题;我们linux下线程操作的接口与我们window下线程操作接口是不同的,因此在C++11以前,我们对于有线程相关操作的程序拥有跨平台性,我们必须通过条件编译实现两套实现方案;但是在C++11后,我们可以通过使用我们的线程库实现跨平台(实际上底层还是条件编译,只是人家写好了);
1、线程库相关接口
线程库给我们提供了如下相关接口;

如果你曾有过Linux或Windows下多线程开发经历,上述接口可能看一眼就会使用了;首先我们来看构造函数;

析构函数我们无需关心,会自动调用; 我们的赋值重载只有右值版本,左值版本被删除了;

其他一些接口使用也非常简单,都是一些无参公有成员函数,具体功能如下图所示;

2、关于线程库中的一些细节问题
细节一:这里的get_id返回的线程id并不是与Linux下相同是一个整型,而是一个结构化数据;具体如下所示;
// vs下查看
typedef struct
{
/* thread identifier for Win32 */
void *_Hnd; /* Win32 HANDLE */
unsigned int _Id;
} _Thrd_imp_t;细节二:对于创建线程时的第一个参数,可以是函数指针,可以是仿函数,可以是lambda函数;
void Func1()
{
cout << "thread 1" << endl;
}
struct Func2
{
void operator()()
{
cout << "thread 2" << endl;
}
};
int main()
{
// 函数指针
thread t1(Func1);
// 传仿函数对象
Func2 f2;
thread t2(f2);
// 传lambda函数
thread t3([] { cout << "thread 3" << endl; });
t1.join();
t2.join();
t3.join();
return 0;
}
细节三:关于线程函数的传参,线程函数若想传引用,则必须调用ref函数;并且当我们传引用与传指针时,若我们调用的detach,将线程分离时,我们需要注意该引用/指针指向的对象若为栈上的对象,有可能会出现越界访问的现象;即该对象所在线程若结束,或出该对象作用域,该对象会被销毁,而子线程仍然访问会引起越界访问的现象;
3、线程相关接口
除了thread类的成员函数还有以下这些来自this_thread这个命名空间中的函数;

4、线程安全相关问题
同样我们C++11封装的线程库使用时也会存在线程安全问题;下面代码便是一段有线程安全的代码;
static int sum = 0;
void transaction(int num)
{
for (int i = 0; i < num; i++)
{
sum++;
}
}
int main()
{
// 创建线程
//template <class Fn, class... Args>
//explicit thread(Fn && fn, Args&&... args);
// 参数一fn通常是一个函数指针,表示该线程调用的函数
// 参数二是可变模板参数,会自动解析,并传给我们参数函数指针所指向的函数
thread t1(transaction, 100000);
thread t2(transaction, 200000);
// 线程等待(必须进行线程等待,除非子线程执行函数中进行了detach)
t1.join();
t2.join();
cout << sum << endl;
return 0;
}
明明是同一段代码,差距竟然如此之大; 我们原本意料的结果是300000;却有如上各种不同的结果,通常我们会采用加锁的方式进行处理;C++11也为我们的锁也进行了封装;具体如下;
5、锁的分类
C++11具体提供了如下四种锁,我们主要讲解mutex,普通互斥锁,因为会普通互斥锁,其他锁理解起来也就很简单了;

互斥锁主要有以下几个接口;

lock为上锁(阻塞调用),unlock为解锁;try_lock为尝试申请锁,若未申请到则返回false,是一种非阻塞调用; 我们通过这些接口可以对上述代码加以线程安全;
static int sum = 0;
mutex mx; // 创建锁变量
void transaction(int num)
{
// 上锁
mx.lock();
for (int i = 0; i < num; i++)
{
sum++;
}
mx.unlock(); // 解锁
}
int main()
{
thread t1(transaction, 100000);
thread t2(transaction, 200000);
t1.join();
t2.join();
cout << sum << endl;
return 0;
}6、lockguard
lockguard是mutex使用RAII机制对锁进行了封装,通过这种机制,我们可以使锁在某个局部作用域生效,实际原理是使用类的构造函数与析构函数实现的;因为构造函数在对象定义时调用,在出作用域时调用析构函数,我们可以在构造函数lock申请锁,在析构函数unlock解锁;下面是我模拟实现的一个lockguard;
#pragma once
#include <mutex>
template<class Lock>
class Lockguard
{
public:
Lockguard(std::Lock& mt)
:_mt(mt)
{
_mt.lock();
}
~Lockguard()
{
_mt.unlock();
}
private:
std::Lock& _mt;
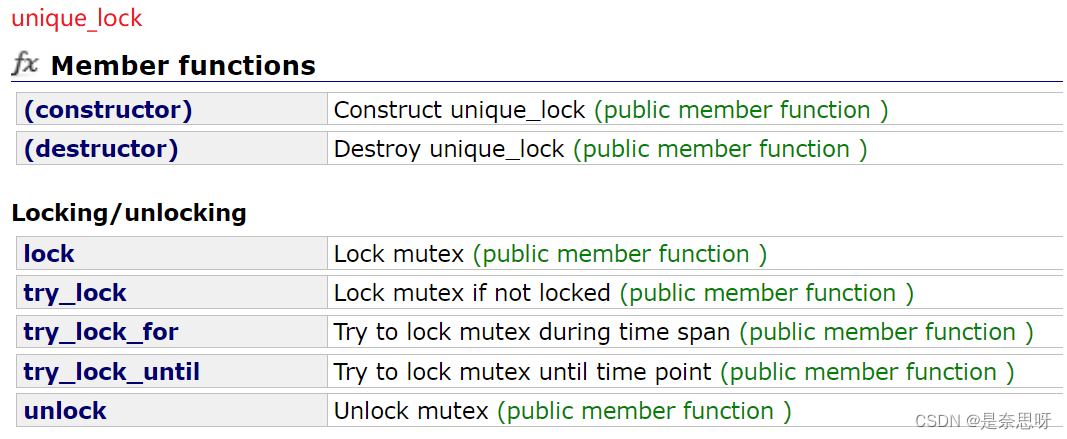
};实际上库里也有这样的类;分别叫做lock_gurad和unique_lock;lock_guard与我们上述实现的几乎相同;而unique_lock仅仅只是给我们多增加了一些加锁解锁的接口;

下面,我们用lock_guard再次升级一下我们之前写的代码;
static int sum = 0;
mutex mx; // 创建锁变量
void transaction(int num)
{
// 出作用域自动销毁
lock_guard<mutex> lg(mx);
for (int i = 0; i < num; i++)
{
sum++;
}
}
int main()
{
thread t1(transaction, 100000);
thread t2(transaction, 200000);
t1.join();
t2.join();
cout << sum << endl;
return 0;
}7、条件变量
C++封装的条件变量与Linux下的条件变量使用差不多,只是进行了封装,提供了跨平台性;具体接口如下图所示;

关于条件变量的使用我们用一道题进行展示;
使用两个线程,一个打印奇数,一个打印偶数,交替打印至100;








![[Machine learning][Part3] numpy 矢量矩阵操作的基础知识](https://img-blog.csdnimg.cn/5ebe08b97ac94f8283df2adfd4a95054.png)