作者:Denis Rechkunov

在 Filebeat 8.10.0 和 7.17.12 中,我们引入了一种新的指纹(fingerprint)模式,使用户可以选择使用文件内容的哈希来识别它们,而不是依赖文件系统元数据。 此更改在文件流输入中可用。
什么是文件流?
Filestream 是 Filebeat 中的一种输入类型,用于从给定路径摄取文件。
文件流架构
为了解释什么是指纹模式以及我们在 Filestream 中引入它的具体位置,我们首先解释一下 Filestream 输入的基本架构:
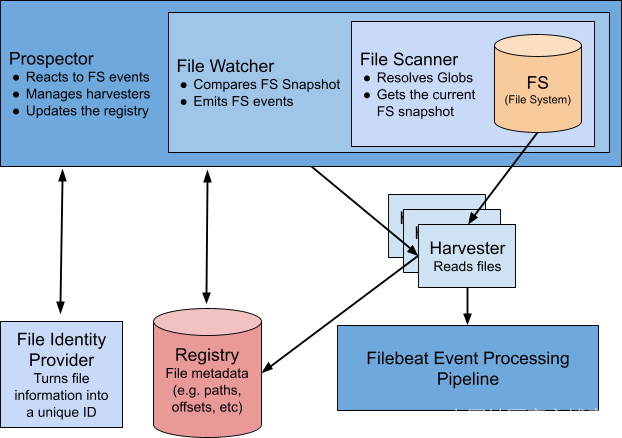
剥掉顶部组件的洋葱皮:
- 文件扫描程序(File Scanner)收集有关与输入路径匹配的所有文件的信息。
- 文件观察器(File Watcher)每隔几秒扫描一次文件系统,如在 prospector.scanner.check_interval 设置中指定的那样,然后比较检查之间的文件系统状态。 如果发生变化,它会发出一个描述变化的事件。
- Prospector 决定如何利用这些文件系统事件:开始/停止收集文件、添加/更新/删除文件的状态等。
- 为了开始处理文件并管理其在注册表中的状态,Prospector 需要该文件的唯一 ID,该 ID 从输入的 file_identity 参数配置的文件身份提供程序获取。
- 所有文件状态(如偏移量)都存储在注册表中 - 内存中的存储,每个在 Filebeat 中配置的 registry.flush 间隔都会刷新到磁盘。 它作为操作日志存储在磁盘上。
- 收集器(havestor)执行实际的文件摄取,并将它们读取的行发送到事件处理管道,该管道执行一些丰富、转换、排队、批处理,并最终将事件传递到输出。
当默认方法不够时
默认情况下,文件扫描程序在搜索重命名/移动时使用文件系统元数据来比较文件,例如:Unix 系统上的 <inode>-<device_id> 字符串(有关 inode 的更多信息可在此处找到)和 Windows 上的 <idxhi>-<idxlo> - <vol> 字符串(分别为 nFileIndexHigh、nFileIndexLow 和 dwVolumeSerialNumber — 请参阅 Microsoft 的官方文档了解更多信息)。 相同的字符串用作文件身份提供程序返回的唯一文件标识符,并且该值用作注册表中每个文件的键以查找文件的当前状态。
文件身份提供程序返回的唯一文件标识符的全部要点是它必须稳定,这意味着在 Filestream 摄取文件期间它不会更改。 它必须是稳定的,因为 Filestream 使用此标识符来跟踪文件元数据,包括文件的当前偏移量,因此它知道在哪里继续摄取。
如果标识符不稳定怎么办? 它会导致数据丢失或数据重复。
数据丢失示例:
- 文件 ID 现在与不同的文件(之前未摄取)相匹配。
- Filestream 没有从偏移量 0 读取此文件,而是将错误的偏移量信息应用于此文件。
- Filestream 继续读取文件中太向前的日志行,跳过日志行。 这些行永远不会到达输出。
数据重复的示例:
- 现有文件的文件 ID 已更改。
- 它现在显示为 Filestream 的新文件。
- 文件流从偏移量 0 开始读取(重新摄取)。
不幸的是,并非所有文件系统都能产生稳定的 device_id 和 inode 值。
文件系统缓存 inode 并重用它们
如果你尝试在不同的文件系统上运行此脚本,你可能会看到不同的结果:
#!/bin/bash
FILENAME=inode-test
touch $FILENAME
INODE=$(ls -i "$FILENAME")
echo "$FILENAME created with inode '$INODE'"
COPY_FILENAME="$FILENAME-copy"
cp -a $FILENAME $COPY_FILENAME
COPY_INODE=$(ls -i "$COPY_FILENAME")
echo "Copied $FILENAME->$COPY_FILENAME, the new inode for the copy '$COPY_INODE'"
rm $FILENAME
echo "$FILENAME has been deleted"
ls $FILENAME
cp -a $COPY_FILENAME $FILENAME
NEW_INODE=$(ls -i "$FILENAME")
echo "After copying $COPY_FILENAME back to $FILENAME the inode is '$NEW_INODE'"
rm $FILENAME $COPY_FILENAME例如,在 Mac (APFS) 上你将看到:
inode-test created with inode '112076744 inode-test'
Copied inode-test->inode-test-copy, the new inode for the copy '112076745 inode-test-copy'
inode-test has been deleted
After copying inode-test-copy back to inode-test the inode is '112076746 inode-test'如你所见,在 APFS 上,所有三个文件都有不同的 inode 值:112076744、112076745 和 112076746。因此,这按预期工作。
但是,如果您在 Ubuntu Docker 容器中运行相同的脚本:
inode-test created with inode '1715023 inode-test'
Copied inode-test->inode-test-copy, the new inode for the copy '1715026 inode-test-copy'
inode-test has been deleted
ls: cannot access 'inode-test': No such file or directory
After copying inode-test-copy back to inode-test the inode is '1715023 inode-test'你可以看到文件系统缓存了我们删除的第一个文件中的 inode 值,并将其重新用于具有相同文件名的第二个副本:1715023、1715026 和 1715023。
它甚至不必是相同的文件名; 不同的文件可以重用相同的 inode:
# touch x
# ls -i x
1715023 x # <-
# rm x
# touch y
# ls -i y
1715023 y # <-我们主要在容器/虚拟化环境中观察到这些问题,但是否缓存和重用 inode 取决于文件系统实现。 理论上,它可以发生在任何地方。
inode 值在非 Ext 文件系统上可能会发生变化
Ext 文件系统(例如 ext4)将 inode 编号存储在 struct inode 内的 i_ino 文件中,并写入磁盘。 在这种情况下,如果文件相同(不是另一个同名文件),则保证 inode 号相同。
如果文件系统不是 Ext,则 inode 号由文件系统驱动程序定义的 inode 操作生成。 由于他们没有 inode 是什么的概念,因此他们必须模仿所有 inode 的内部字段以符合 VFS,因此这个数字在重新启动后可能会有所不同 - 理论上,即使在再次关闭并打开文件后也是如此。
资料来源:
- linux - Inode number after reboot - Stack Overflow
- linux kernel - Inode Number is changing - Stack Overflow
某些文件处理工具会更改 inode 值
- 我们已经看到我们的客户在使用 rsync 和更改 inode 时遇到问题。
- 另外,并不是每个人都知道 sed -i 创建一个临时文件,然后将其移动到原始文件的位置,更改 inode 值(它基本上是一个新文件)。 例如,某些用户可能使用 sed -i 来屏蔽日志中的凭据。
设备 ID 可以更改
除了 inode 问题之外,根据磁盘驱动器的安装方式,device_id 可能会在重新启动后发生更改。 不过,我们前段时间已经针对这个问题推出了解决方案:file_identity: inodemarker。
什么是指纹模式?
文件扫描器组件中实现了新的指纹模式,以避免上述问题。
对于给定的文件字节范围,新的指纹模式将默认文件扫描程序行为从使用文件系统元数据切换为使用 SHA256 哈希。 默认情况下,该范围为 0 到 1024,但可以通过 offset 和 length config 参数进行配置。
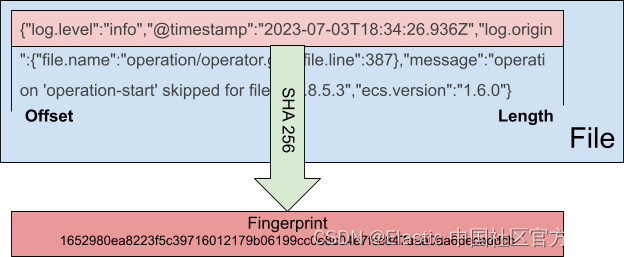
既然我们在文件扫描器中拥有了此指纹信息,它也会随每个文件系统事件一起传播,并且可以使用此指纹哈希作为文件身份提供程序中的唯一文件标识符。 因此,现在还有一个新的 file_identity: fingerprint 选项,它也允许使用指纹值作为注册表中的主文件标识符。
使用指纹模式 + 指纹文件身份时要注意什么
在开始使用这一新功能之前必须考虑以下几点:
- 所有日志文件在配置的字节范围内必须是唯一的。 由于时间戳和日志的纯粹性质,大多数日志文件都是如此,但必须检查日志并决定指纹的 offset 和 length。
- 一旦开始使用 file_identity: fingerprint,你就无法再更改指纹的 offset 和 length; 它将导致与输入路径匹配的所有文件的完全重新摄取。
- 性能受到影响 - 此功能的性能方面值得在本文中单独讨论:
性能
从开发此功能的早期阶段开始,人们就担心它会对文件扫描程序(File Scanner)造成性能影响。 最后,我们需要打开一个文件,读取由 prospector.scanner.fingerprint.length 配置选项设置的字节数,并从中计算 SHA256。 我们需要对与路径中的 glob 匹配的每个文件执行此操作。
这里需要注意一点:为了实现这个新功能,File Scanner 必须进行大量更改。 所以,我在写代码的时候,趁这个机会重构了 File Scanner 的一些部分,同时做了一些优化,主要是减少了 syscalls。 我还添加了很多测试来验证预期的行为。 因此,有人怀疑新的 File Scanner(禁用指纹模式)速度更快,因为它不再进行那么多的系统调用。
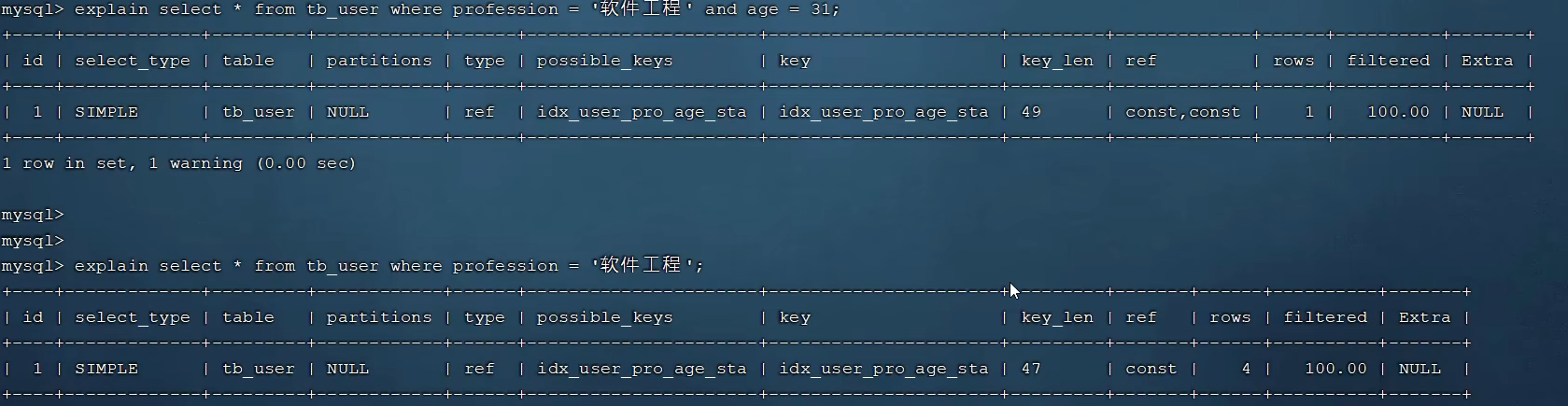
在指纹模式最终交付给 main 后,我运行了一些基准测试,至少可以说结果很有趣:
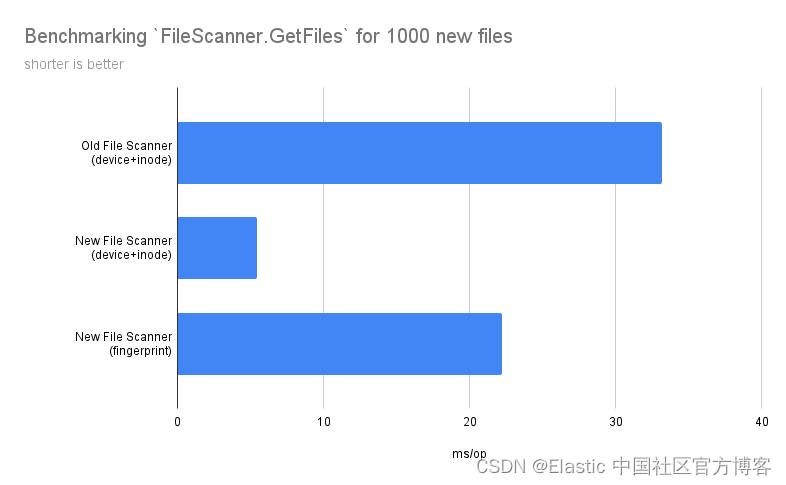
这里可以得出几个结论:
- 通过在 File Scanner 中进行上述优化,性能提升了 84%。
- 新的指纹模式比默认的 device_id+inode(在使用新的 scanner 情况下)模式慢 76%,这使得它比旧 File Scanner 中的默认模式快 8%。 因此,即使启用了指纹模式,我们的客户也将体验到更快的文件流。
- 哈希算法和指纹长度对整体性能的影响都不大 —— 大部分时间都花在打开和关闭文件进行读取上。 所以,指纹模式的默认值似乎没问题。
结论
这种新的指纹模式解决了文件系统上元数据不稳定的许多问题,并且与之前版本的 Filebeat 相比,它甚至比默认模式更快。
此外,默认模式在新的 Filebeat 版本中变得更快,因此时不时地重构一些旧代码并运行基准测试/分析以查看性能如何变化似乎非常有益。
我们将继续关注 Filebeat 的性能。 敬请关注。
Elastic 8.10 中还有哪些新增功能? 查看 8.10 公告帖子以了解更多信息。
跟多阅读:Beats:使用 Filebeat 中的 filestream 输入更快速、更轻松地读取活动日志文件