一、逆向工程介绍
1.1 什么是逆向工程
提到逆向工程可能大多数人第一印象就是非道德层面的软件破解,其实不然,逆向工程又称为逆向技术,是一种产品设计技术再现过程,即对一项目产品进行逆向分析及研究,从而演绎并得出该产品的处理流程、组织结构、功能特性及技术规格等设计要素,以制作出功能相近,但又不完全一样的产品。
逆向技术不仅仅是用在商业方面,在军事领域尤为重要,例如越南战争期间我国通过获取4万多块美军战机碎片逆向获得300多项新技术。从这个案例可以看出来,逆向技术不仅仅包含软件逆向,也包含硬件逆向,材料逆向等等。所以下面就软件逆向来介绍其相关知识。
1.2 软件逆向实际应用
软件逆向技术作用有很多,大多数人应该都使用过逆向出来的盗版软件。实际上这种做法在道德和版权层面来说肯定不被作者所接受,而且会带来较大危害性,会影响到软件开发者的利益,不利于软件市场的健康发展等等。从使用者角度来说其实也有不利影响,例如一些破解软件里可能夹带有病毒或者安全漏洞,被不法人士利用则会造成使用者的数据泄漏或者经济损失等。
对于这种非道德层面的逆向产品我们要知道其危害,但是也要知道逆向技术的正向应用,下面介绍几点:
-
分析恶意软件
恶意软件的作者几乎不会提供源代码,除非是基于脚本的病毒。由于缺乏源代码,要准确地了解恶意软件的运行机制,动态分析和静态分析是分析恶意软件的两种主要技术手段。动态分析是指在严格控制的环境(沙盒)中执行恶意软件并使用系统检测实用工具记录其所有行为。相反,静态分则试图通过浏览程序代码来理解程序的行为。此时,要查看的就是对恶意软件进行逆向之后得到的代码清单,通常是汇编代码。在了解到恶意软件的行为之后就可以制定对应有效的防御措施。

-
漏洞分析
安全审核过程划先简单分成3个步骤:发现漏洞、分析漏洞、开发破解程序。无论是否拥有源代码,都可以采用这些步骤来进行安全审核。在没有源代码只有二进制文件情况下,就只能选择逆向方式进行分析。这个过程的第一个步骤,是发现程序中潜在的可供利用的条件。一旦发现漏洞,通常需要对其进行深入分析,以确定该漏洞是否可被利用,如果可利用,可在什么情况下利用。以帮助研究人员了解漏洞的触发条件、影响范围和控制流程等,从而制定更有效的修复措施。

-
编译器验证
由于编译器(或汇编器)的用途是生成机器语言,不同的编译器对源码翻译出的机器语言可能有差异,这些差异可能不影响功能,但是对性能可能有着巨大差异。所以在这方面可以使用逆向技术来查看编译器翻译出来的机器语言是否符合预期,从而使编译器开发人员能够对编译器进行优化,以达到代码优化验证目的。因此优秀的反汇编工具通常需要验证编译器是否符合设计规范。分析人员还可以从中寻找优化编译器输出的机会,从安全角度来看,还可查知编译器本身是否容易被攻破,以至于可以在生成的代码中插人后门等等。

-
保护知识产权
逆向工程可能会被误认为是对知识产权的严重侵害,但是在实际应用上,反而可能会保护知识产权所有者。例如在软件或者硬件领域,如果怀疑某公司侵犯知识产权,可以用逆向技术逆向对方的产品寻找其侵权证据。

需要注意的是,逆向技术的应用需要遵守相关法律法规和知识产权法律法规的规定,不能用于侵犯他人的合法权益。
二、 软件逆向基础知识
任何领域的逆向都不是一项简单的工作,软件逆向技术的应用也需要具备一定的专业知识和技能,需要经过专门的学习和实践才能掌握。这里列举一些对于入门而言所需要的基本知识:
2.1 计算机体系结构(x86-CPU指令集)
计算机体系结构是指根据属性和功能不同而划分的计算机理论组成部分及计算机基本工作原理、理论的总称。其中计算机理论组成部分并不单与某一个实际硬件相挂钩,如存储部分就包括寄存器、内存、硬盘等。在学习逆向时首选得弄懂什么是CPU,什么是寄存器,什么是内存?(其他如输入设备,输出设备都很重要,这里不做展开介绍)
- CPU即中央处理器,是一块超大规模的集成电路,是计算机的运算核心和控制核心,主要是解释计算机指令以及处理计算机软件中的数据,包括运算器和高速缓冲存储器及实现它们之间联系的数据、控制及状态的总线;
- 寄存器是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据和运算结果。
- 内存是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。
上述提到CPU解释计算机指令的作用,这里的指令一般是由01二进制数据组成,使用助记符一 一对应就形成了汇编指令。汇编指令在不同体系架构有所不同,所以不同计算机体系关系到软件设计体系,例如X86,ARM, MIPS体系架构的寄存器操作,对执行过程操作可能存在一定的差异。例如x86架构采用复杂指令集(CISC)设计,意味着x86处理器具有更多的内建指令和更复杂的硬件,从而能实现更高的计算性。MIPS采用精简指令集(RISC)设计的架构,设计理念强调高吞吐量和高指令并行度。
如下图指令块分别是上述三种不同架构使用的指令集,如果我们对x86指令集比较熟悉,应该能一眼看出哪段是x86。
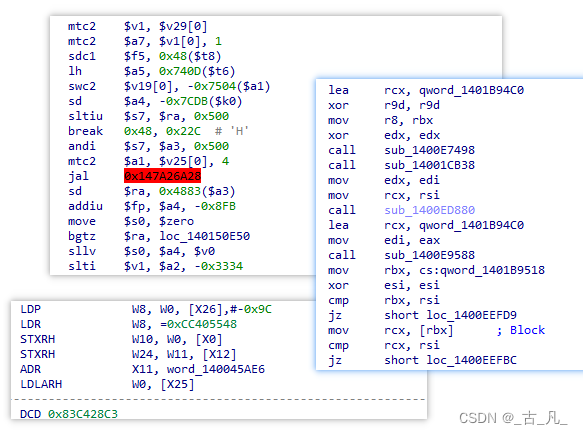
下面介绍这三种架构的几个常见的指令区别:
| 指令类型 / 架构 | x86 | ARM | MIPS |
| 赋值,寻址 | mov | LDR,MOV | move |
| 算术运算符 | add | ADD / ADC | add / addi |
| 跳转 | jz / jnz | BRA | j / jri |
| 比较 | cmp | CMP | bgtz |
| 函数调用 | call | BL | jal |
| 堆栈操作 | push, pop | push, pop | sd,sw |
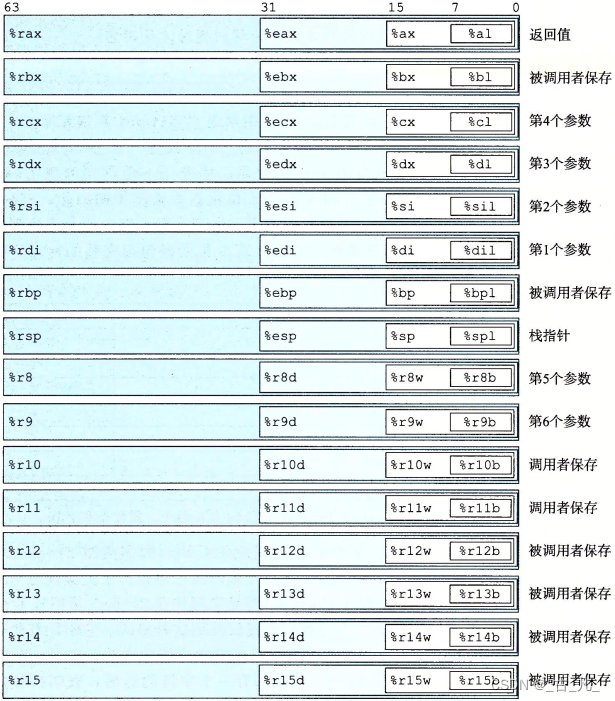
x86的几个通用寄存器(部分),如下图:
根据上图得到的信息:
- rax,eax,ax和al是同一个寄存器,只是位长不同,例如eax的值为0x12345678,那么al的值就是最低位一个字节的值,即0x78,其他寄存器类似。
- eax称为累加器,常用于算数运算、布尔操作、逻辑操作、返回函数结果等。
- ebx称为基址寄存器,常用于存档内存地址。
- ecx称为计数寄存器,常用于存放循环语句的循环次数,字符串操作中也常用。
- edx称为数据寄存器。
- 函数入参第1个入参默认存入rdi/edi,其次是rsi/esi,当超出一定数量(正常是6个)会使用栈空间传参。
- rsp/esp是指向栈指针。
- eip/rip是指向程序运行的寄存器。
- rbp/ebp一般指向函数的栈底。
通用寄存器的专门用途不是一成不变的,编译器在编译程序的时候会根据很多因素来决定作用,例如编译器、编译条件、操作系统等做出相应的改变。
另外还有部分标志位:
- CF(Carry Flag):进位标志位,用于表示加法运算是否产生进位。
- PF(Parity Flag):奇偶校验标志位,用于表示数据中1的个数是否为偶数。
- ZF(Zero Flag):零标志位,用于表示运算结果是否为0。
- SF(Sign Flag):符号标志位,用于表示运算结果的符号位。
- IF(Interrupt Flag):中断标志位,用于控制是否允许硬件中断。
- DF(Direction Flag):方向标志位,用于控制字符串操作时是向前还是向后扫描。
- OF(Overflow Flag):溢出标志位,用于表示加法或减法运算是否产生溢出。
举个例子说明标志位怎么用的。
cmp [esi], 0
jnz 0x152686
上述cmp类似于减法指令,只是不保存结果,判断esi所指内存的值是否等于0, 做差之后标志位ZF就会有结果(等于0就是ZF=1),然后jnz根据ZF表示是否为0决定EIP是否跳转到指定位置。
2.2 程序语言(汇编)
软件逆向出来的代码清单大多以汇编语言为主要呈现形式,也有逆向工具可生成C/C++等语言伪代码。所以入门至少对汇编语言有一定的了解,对高级语言C/C++/Java语言也需要有一定的了解,至少了解基本的判断循环的操作指令。
如下图的C语言编译为汇编语言后,出现很多指令。在C语言粗略看只有加运算符和函数调用,没有其他过多的操作,而到汇编语言后指令变的繁多且出现多种指令。

汇编语言源代码主要采用两种语法: AT&T 语法和 Intel 语法。这二者的语法在变量、常量、寄存器访问、段和指令大小重写、间接寻址和偏移量等方面都存在巨大的差异。AT&T汇编语法以%作为所有寄存器名称的前缀,以$作为立即操作数的前缀。它这样对操作数排序:源操作数位于左边,目的操作数位于右边。使用AT&T语法,EAX寄存器加4的指令为:add $0x4, %eax。GNU汇编器(Gas)和许多其他GNU工具(如gcc和gdb)都使用AT&T语法。
Intel语法与AT&T语法不同,它不需要前缀,它的操作数排序方式与 AT&T语法操作数恰恰相反:源操作数位于右边,目的操作数位于左边。使用 Intel 语法,上述加法的指令为:add eax, 0x4。后面介绍的内容也都是Intel语法。
结合上图的C语言来简单看看这段汇编的执行流程和语法,这里给汇编指令加上地址,如下图:

假设初始状态rbp为0,栈(rsp寄存器)初始地址为0xd2c8,下面是每行指令执行结果和栈变化情况。
| rip值 | 相关寄存器状态 | 栈数据 | 说明 |
| 400513 | rbp : 0 rsp : 0xd2c8 | 0xd2c8 : 0x11111111 | push rbp 将rbp值压入栈,栈指针移动8字节(根据cpu和架构有关) |
| 400514 | rbp : 0 rsp : 0xd2c0 | 0xd2c0 : 0 0xd2c8 : 0x11111111 | mov rbp,rsp 记录栈地址到rbp,一般rbp是栈底地址,rsp是栈顶 |
| 400517 | rbp : 0xd2c0 rsp : 0xd2c0 | 0xd2c0 : 0 0xd2c8 : 0x11111111 | mov edi,0x16 将数值放到第一入参寄存器 |
| 40051c | rbp : 0xd2c0 rsp : 0xd2c0 edi : 0x16 | 0xd2c0 : 0 0xd2c8 : 0x11111111 | call 4004fc 调用函数,控制rip指向指定位置,然后将下一条指定存入到栈中 |
| 400cfc | rbp : 0xd2c0 rsp : 0xd2b8 edi : 0x16 | 0xd2b8 : 0x400521 0xd2c0 : 0 0xd2c8 : 0x11111111 | push rbp 将上个函数的栈底存到栈中,保存上层函数现场 |
| 400cfd | rbp : 0xd2c0 rsp : 0xd2b0 edi : 0x16 | 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 0xd2c0 : 0 | mov rbp,rsp 获取本函数的栈底地址 |
| 400500 | rbp : 0xd2b0 rsp : 0xd2b0 edi : 0x16 | 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 0xd2c0 : 0 | sub rsp,0x8 移动栈顶指针,类似于开辟一块空间 |
| 400504 | rbp : 0xd2b0 rsp : 0xd2a8 edi : 0x16 | 0xd2a8 : 0x???????? 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 0xd2c0 : 0 | mov DWORD PTR [rbp-0x4],edi 栈底往上四个字节存入第一个传参的数值 |
| 400507 | rbp : 0xd2b0 rsp : 0xd2a8 edi : 0x16 | 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 | mov eax,DWORD PTR [rbp-0x4] 再将数值从栈中取出,赋值给eax, |
| 40050a/c | rbp : 0xd2b0 rsp : 0xd2a8 edi : 0x16 eax : 0x16 | 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 | mov edi,eax call 4004ed 将eax赋值给edi,edi寄存器默认是函数入参的第一个入参,后面将要函数跳转到4004ed,保存下一条指令到栈 |
| 40050ed | rbp : 0xd2b0 rsp : 0xd2a0 edi : 0x16 eax : 0x16 | 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 | push rbp 保存前一个函数的栈底,栈顶指针向上移动8字节 |
| 40050ee | rbp : 0xd2b0 rsp : 0xd298 edi : 0x16 eax : 0x16 | 0xd298 : 0xd2b0 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 | mov rbp,rsp 设置新函数的栈底 |
| 4004f1 | rbp : 0xd298 rsp : 0xd298 edi : 0x16 eax : 0x16 | 0xd298 : 0xd2b0 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 | mov DWORD PTR [rbp-0x4],edi 将入参存到栈 |
| 400f4/7 | rbp : 0xd298 rsp : 0xd298 edi : 0x16 eax : 0x16 | 0xd290 : 0x16???????? 0xd298 : 0xd2b0 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? | mov eax,DWORD PTR [rbp-0x4] add eax,0xb 将栈值取出存到eax,eax计算后作为返回值返回 |
| 4004fa | rbp : 0xd298 rsp : 0xd298 edi : 0x16 eax : 0x21 | 0xd290 : 0x16???????? 0xd298 : 0xd2b0 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? | pop rbp 即将返回上一层函数,还原上层函数的栈底位置 |
| 4004fb | rbp : 0xd2b0 rsp : 0xd2a0 edi : 0x16 eax : 0x21 | 0xd298 : 0xd2b0 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 | ret 跳转到当前rsp所指的位置,栈顶还原 |
| 400511 | rbp : 0xd2b0 rsp : 0xd2a8 edi : 0x16 eax : 0x21 | 0xd2a0 : 0x400511 0xd2a8 : 0x16???????? 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 | leave 将函数栈底所指数据存入rsp,再将rsp所指数据弹出到rbp,这是rsp在此基础上会再偏移8字节,等价于: mov rsp, rbp pop rbp |
| 400512 | rbp : 0xd2c0 rsp : 0xd2b8 edi : 0x16 eax : 0x21 | 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 0xd2c0 : 0 | ret 将栈顶地址弹出到rip,即将跳回到上一层函数 |
| 400521 | rbp : 0xd2c0 rsp : 0xd2c0 edi : 0x16 eax : 0x21 | 0xd2b0 : 0xd2c0 0xd2b8 : 0x400521 0xd2c0 : 0 0xd2c8 : 0x11111111 | pop rbp 即将返回上一层函数,还原上层函数的栈底位置 |
| 400522 | rbp : 0 rsp : 0xd2c8 edi : 0x16 eax : 0x21 | 0xd2c0 : 0 0xd2c8 : 0x11111111 | ret 将栈顶地址弹出到rip,即将跳回到上一层函数 |
经过上面的逐步分析流程,假设有过程(函数)A调用过程B,过程B执行完后返回到A,可以总结出函数调用包含下面一个或多个机制,
- 传递控制:在进入函数B的时候,程序计数器必现被设置为B的代码起始地址,然后返回时,要把程序计数器设置为A中的调用B后面那条指令的地址。
- 传递数据:A必须能够向B提供一个或多个参数,B必须能够向A返回一个值。
- 分配和释放内存:在开始时,B可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间。
函数调用过程时,栈的情况如下:
| 本地变量 | 正在执行的函数B |
| 保存的寄存器状态 | |
| 返回地址 | 调用函数A的帧 |
| 入参n | |
| ... | |
| 入参1 | |
| ... | 较早的帧 |
这里详细的过程原理介绍可参考《深入理解计算机系统(第三版)》的第3.7章节,这里不做深入说明。另外这里整明白之后,那么栈溢出攻击原理就会很容易明白。
2.3 数据结构
对于数据结构和算法需要理解,毕竟有“程序 = 数据结构 + 算法”这句古老的公式,这两着是不可分割的关系。想要对逆向出来的程序有一定的理解能力,这方面的知识不可或缺。
在逆向出来的程序中,数据结构呈现不如高级语言那么形象。高级语言结构体里有什么变量成员能够通过变量名一眼看出,而到汇编之后,名称信息全被抛弃,只有寄存器和数值表示结构。看下图实例:
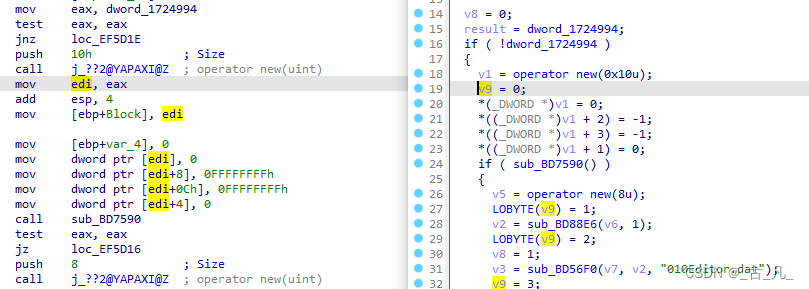
如下结构体和赋值过程是由上图中的汇编反推导出来。可以发现,汇编中表示数据结构是由"基址 + 偏移"的方式表达:

转成伪代码,再做对比确认,发现和反推出来的数据结构仍然有差异,但实际仍然是同一个意思,执行结果相同。

通过上述的案例,知道数据结构在汇编中表达晦涩难懂,没有高级语言的清晰。但是只要知道,像数组,结构体这类连续内存,在汇编中都是以"内存首地址 + 偏移量"存取值,对于基本入门来说则已经不是问题。
2.4 调试基础
在做开发方面的工作其调试(debug)是非常重要的,一般从发现问题到解决问题由下面的几个步骤组成:

- 重现故障:即复现问题,是很重要的一步,如果无法复现故障,那么后面的工作也很难开展。
- 定位根源:定位问题根源即是实际实操的部分,有些问题可能一眼发现问题,而有些问题不得不借助调试器来定位。
- 探索和实现解决方案:在定位到问题后,需要根据问题来给出相应可行的解决方案。
- 验证方案:根据给出的解决方案进行再验证,是否故障再现,如果在再现需要重新根据问题给出新的解决方案,直到问题被彻底解决。
上述过程如果应用到逆向工程中,那么“重现故障”就不再是最重要一步,而确定需要逆向的部分模块或功能点(定位和分析)才是最重要的部分。借助调试器分析问题是其手段之一,下面是调试器中一些基本操作介绍:
- 单步 - 步入(step into):每次只执行一条指令或者一行代码,遇到函数会进入函数内部。
- 单步 - 步过(step over):每次只执行一条指令或者一行代码。
- 断点(breakpoint):程序在运行过程中需要停止的位置。
- 监视 (watches):在调试的过程中,会查看关心的变量值,通过监视来看。
- 设置/修改(set/modify):运行过程中可能希望改变某些变量值,可通过此操作更改。
调试除了上述基本操作外,不同调试器可能还提供更多其他有利于调试的窗口或工具,例如寄存器监控,汇编源码同步,堆栈显示等。
2.5 逆向调试工具
逆向工具种类有很多,有针对安卓的逆向工具,有针对x86的逆向工具,有动态调试分析工具,也有静态分析工具。这里以x86平台的常用调试器为主介绍几款常用工具的优缺点:
| 名称 | 简介 | 优点 | 缺点 | 下载位置 |
| Ollydbg | windows平台上具有可视化界面的32位汇编分析调试器 |
|
| http://www.ollydbg.de/viewer.htm |
| x64dbg | 是一款开源、免费、功能强大的动态反汇编调试器,能够在Windows平台上进行应用程序的反汇编、调试和分析工作 |
|
| x64dbg |
| GDB | UNIX/LINUX操作系统下的、基于命令行的、功能强大的程序调试工具,也具有逆向功能。 |
|
| https://www.sourceware.org/gdb/download/ |
| Windbg | 微软的调试器集合,可以调试其window内核调试等 |
|
| Install WinDbg - Windows drivers | Microsoft Learn |
| IDA Pro | 是专业的交互式反汇编器,支持多平台运行,支持数十种CPU指令集。 |
|
| IDA Free |
下面可以给出几个调试器窗口的观感:
GDB是linux的字符形式呈现调试窗口,可以显示源代码窗口,汇编窗口和寄存器窗口,如下:
ollydbg界面比较精致小巧,最关键就是字小信息显示行多,但是界面仍然是上个时代的风格:
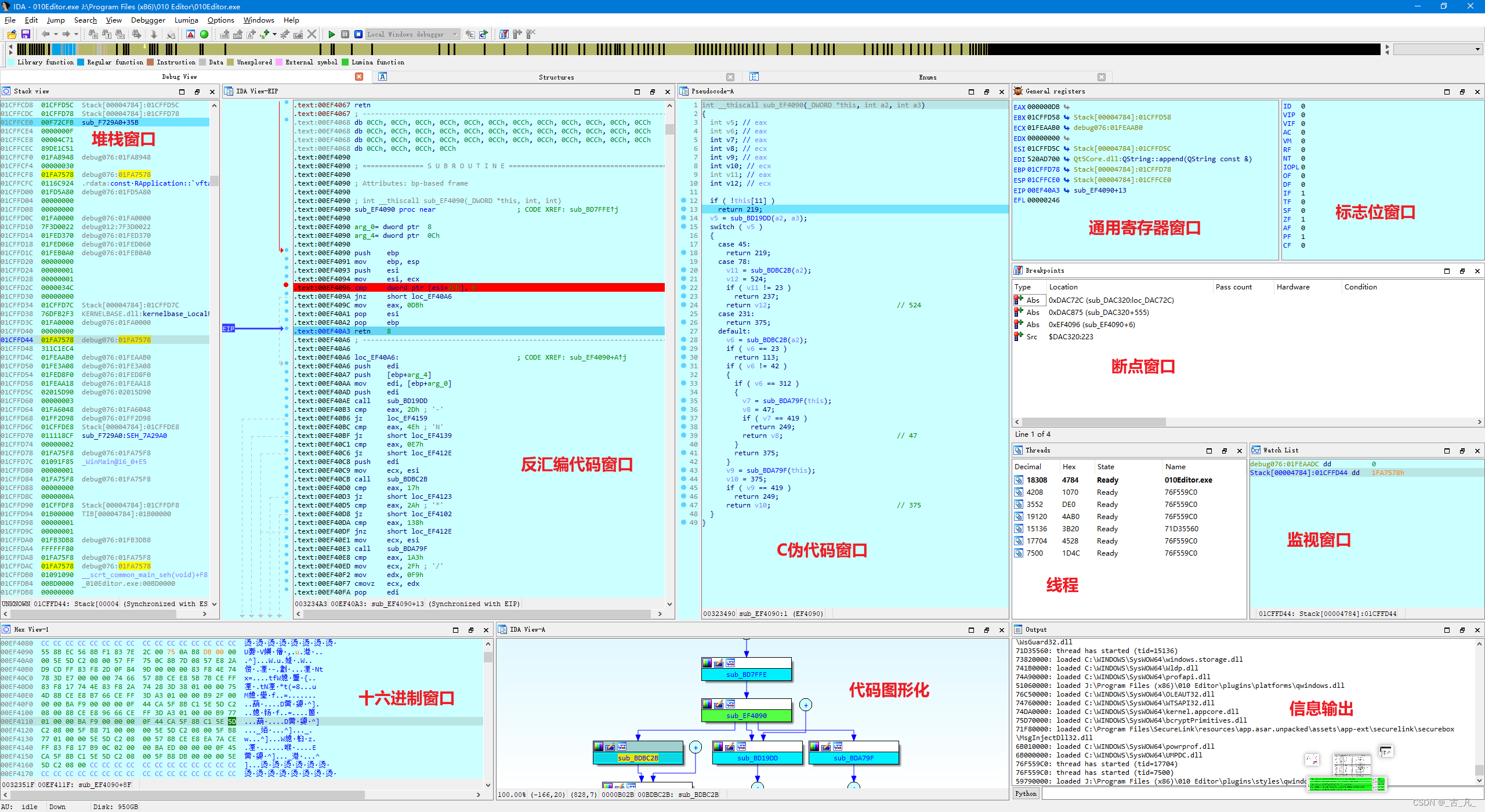
IDA Pro界面清爽,审美在线,信息窗口也有非常多种可用,如下图:
有了以上的基础知识,差不多就可以进入逆向的基本学习了,如果需要进阶更深一层,可能还要了解操作系统原理,网络安全技术和软件分析技术等等。
三、IDA Pro使用简介
从上章节介绍逆向调试工具有多种,这里以IDA Pro为例介绍其大概使用,进行逆向的入门学习。
交互式反汇编器专业版(Interactive Disassembler Professional)人们常称其为IDA Pro,或简称为IDA。是最强的一个静态反编译软件,是一款交互式的,可编程的,可扩展的,多处理器的,交叉Windows或Linux、MacOS平台主机来分析程序,即跨平台能力。 被公认为最好的花钱可以买到的逆向工程利器。IDA Pro已经成为事实上的分析敌意代码的标准并让其自身迅速成为攻击研究领域的重要工具。它支持数十种CPU指令集,其中包括Intel x86,x64,MIPS,PowerPC, ARM, c8051等等。
3.1 工程创建
打开软件后会出现如下对话框,可以直接打开列表中历史已经加载过的程序,

或者也可以点击New按钮,在菜单栏File > Open打开需要分析的exe可执行文件,打开后会出现如下窗口,IDA pro会自动分析该程序适合的加载器,当然也可以自己选择其他的加载方式,需要拥有推翻IDA决定的能力。
当程序加载完之后,在状态栏的左下角位置会有idle标识,或者输出窗口也有完成标识。然后即可开始自己的分析操作。
3.2 基本窗口和操作说明
- 默认工程窗口信息
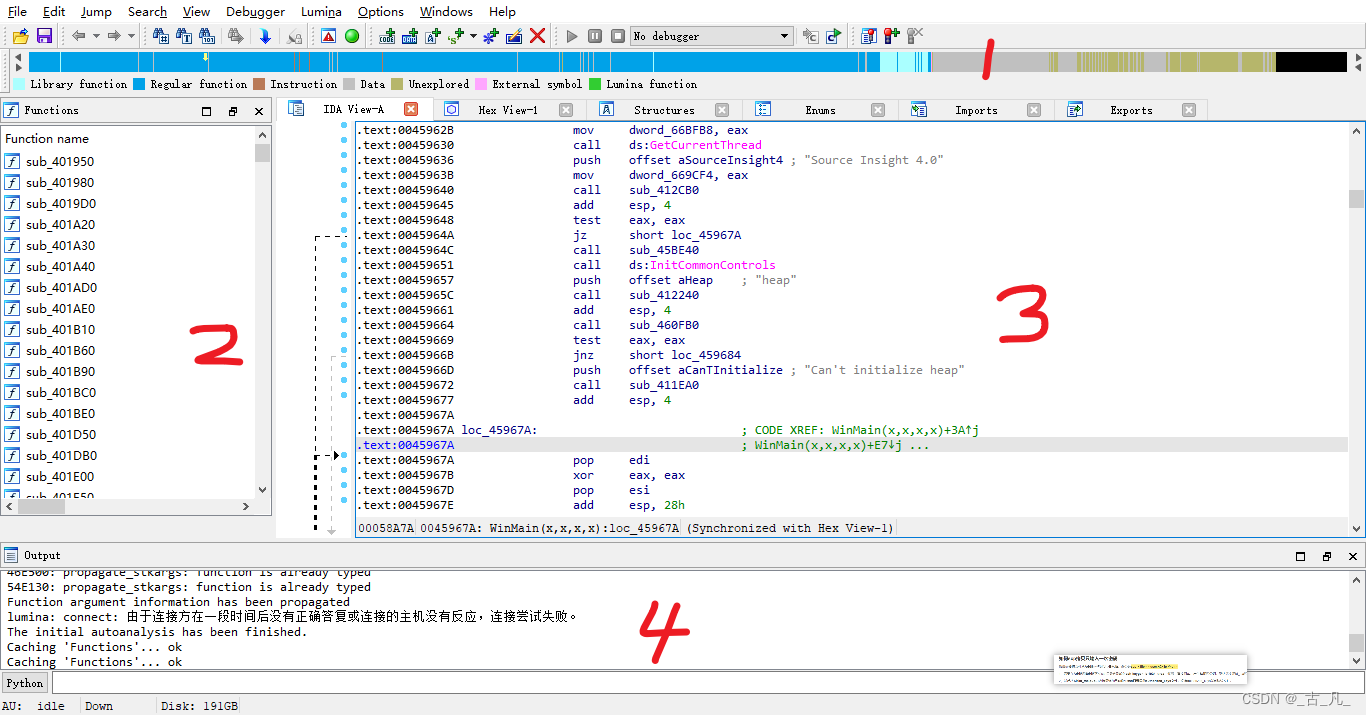
这里介绍入门常用的操作方式和窗口的信息展示。加载完之后,界面的初始状态如下图,各序号窗口如下说明:
1 为程序段的分布图
2 为函数窗口
3 为反汇编代码窗口
4 为信息输出窗口
在反汇编代码窗口按空格键,当前函数段会变为图形化展示:
在反汇编代码窗口按下F5,会呈现C的伪代码,如下,伪代码的命名仅供参考标识用时,不一定准确。

在反汇编窗口中,有很多信息是IDA pro协助加上,如下图:

-
- 标号1:此处对应名称为sub_8C14,属于IDA使用默认方式标识函数名,默认命名规则为:sub_+函数内存相对偏移。可执行程序部分由大量的函数代码组成,属于代码片段基本组成单位。
- 标号2:表示反汇编代码对应内存的相对偏移及所属的节段名称,此处需区分内存偏移和文件偏移,IDA以内存偏移的方式加载可执行文件各节段内容。
- 标号3:表示函数内部的局部代码块,通常以跳转目的地址为规则定义代码块,属于IDA使用默认方式标识函数名。该部分命名规则为:loc _+函数内存相对偏移,通常与跳转操作密切相关。
- 标号4:对应内容为“; CODE XREF: sub_475BC0+C8”,表示当前代码的交叉引用,对应标号的文本含义为:“sub_56B3D0”上层调用由“sub_475BC0”函数内部偏移0xC8处调用,
- 标号5:表示反汇编文本内容,通过反汇编内容可进行逆向分析。
在反汇编窗口呈现的信息都是IDApro给出自动生成的信息和注释,我们也可以对这些信息进行修改和更加。
修改函数名(标号1)和模块名(标号3)将鼠标放到对应的字符上,按N键进行修改。如果想恢复默认名,只需要将原本设置的名字删除即可。

增加修改注释(标号4)是将鼠标移到指定行,然后按分号键进行编辑注释:

修改汇编指令(标号5)稍微的复杂一些,选中待修改的汇编指令行,然后菜单栏点击Edit > Patch program > Assemble出现对话框进行修改:
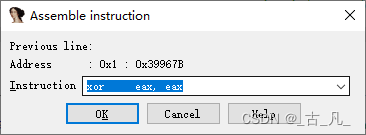
修改完之后,如果需要使其生效,则菜单栏点击Edit > Patch program > Apply patches to input file,这里最好将原程序备份一份,以防修改出错。
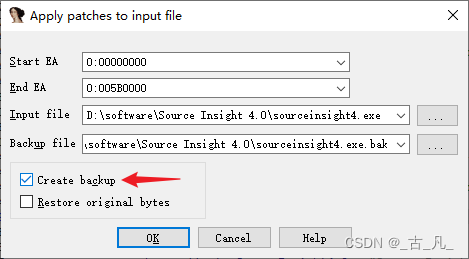
需要注意的是,IDA不提供ctrl+Z撤回操作,如果编辑出错并且无法还原的情况下,只能关闭软件不保存数据库。
- 其他窗口信息
其他常用的窗口默认没有被打开的,可自行通过View > Open subviews > Quick view(Ctrl + 1快捷键)打开窗口,选择需要显示的窗口,如下图:

- 十六进制窗口
用于查看汇编指令对应的十六进制数据,如下图高亮处指令mov esi, 2Dh对应的十六进制数据就是BE 2D 00 00 00,BE为指令,2D 00 00 00为数据0x0000002D,通过十六进制也可直接修改数据。

通过在对应的十六进制数据上右击鼠标,选择Edit对数据编辑数值。
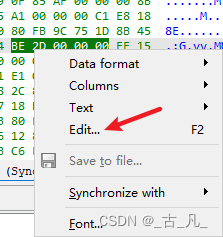
这里将2D 00 00 00改为2D 00 01 00,可以发现,对应指令传输的数据发生了变化,往寄存器赋值的立即数变为0x1002Dh。

至于上述立即数为什么不是0x2D000100,这里牵扯到大小端问题:
小端模式:数据的高字节,存放在高地址中。计算机读取数据的方向,是从高地址开始读取的;
大端模式:数据的高字节,存放在低地址中。计算机读取数据的方向,是从低地址开始读取的;
- 字符串窗口
字符串窗口显示的是可执行程序中所有可见的字符串,可以通过搜索栏找到自己需要查找的字符串,这个是定位分析点的一个好方式。
3.3 调试模式
IDA不仅是很棒的静态分析工具,也具有很强的动态调试功能,可以调试本地程序也可以调试远程程序。进入到调试模式这里介绍2种方式。
- 方法1
从静态分析界面进入到调试模式,点击工具栏中的绿色三角形按钮,注意后面的调试器选择Local Windows debugger。

进入调试界面后默认布局如下,有很多窗口在静态分析模式已经出现,其中需要关注通用寄存器状态窗口和堆栈窗口。
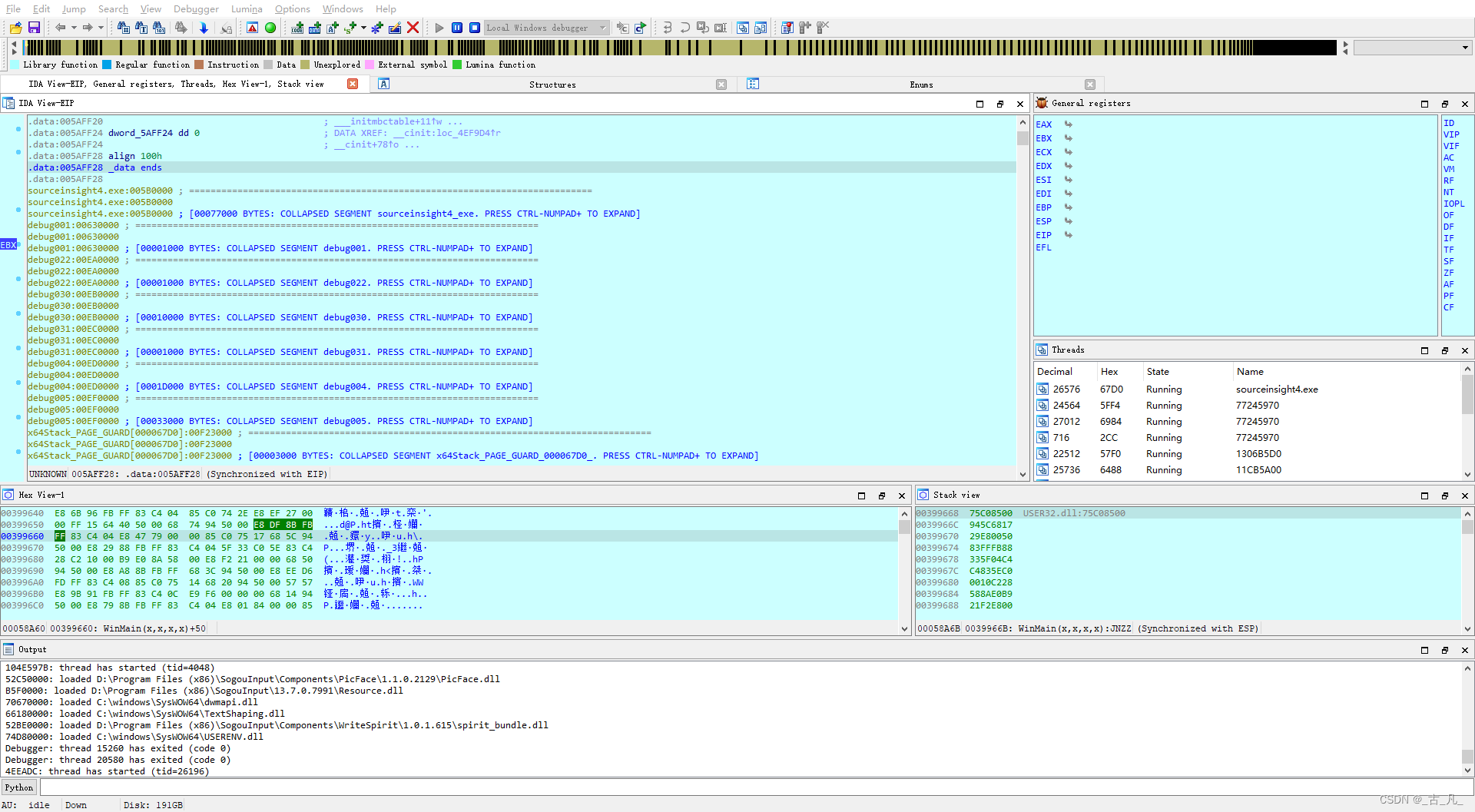
- 通用寄存器状态窗口
如下,单步调试时会实时显示寄存器中的数值,点击蓝色回车箭头可以跳转到对应的指示位置。
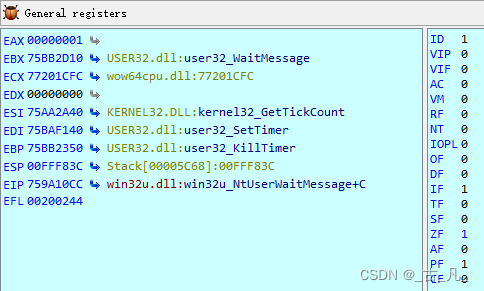
右击寄存器名称,出现弹窗可以修改寄存器变量,复位,增减值等操作。以及右边的标志位也都可以随时修改。
- 方法2
是直接新建动态调试工程,在菜单栏点击Debugger > Run 后能看到下面选项:
可以远程跨平台调试程序。例如远程调试Linux的程序,设置步骤如下
- 将IDA安装目录dbgsrv文件夹里的linux_server64程序拷贝到64位的linux虚拟机中;
- 通过命令chmod +x linux_server64为程序添加可执行权限;
- 通过命令./linux_server64开启服务端;
- 在IDA中点击Debugger,选择Remote Linux Debugger;
- 点击Debugger下的Process Option进行如下配置:
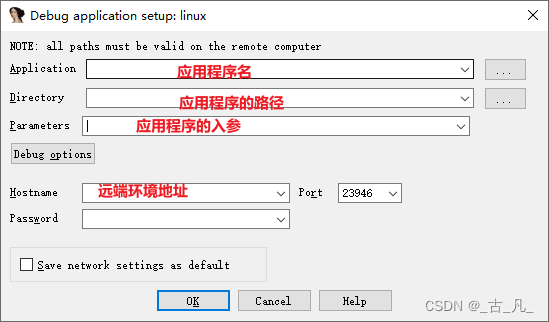
只需要将上述红字部分填写完毕即可进行远端调试。
使用上述方式进入到调试模式之后,就可以单步调试程序了。单步调试按钮图标如下图前2个,IDA还提供了运行到函数返回位置(第3个按钮),运行到光标所在为止(第4个按钮)。
![]()
上述是IDA的使用介绍,如果还想再深入IDA使用可参考《IDA-Pro权威指南(第2版)》。
四、逆向实战
这里以逆向010Editor作为实例仅供个人学习,勿要将其扩展到商业行为构成侵权。
4.1 寻找特征
010Editor是一款十六进制编辑器,有30天的免费试用期的,当超过30天之后,软件就不能再打开,需要注册码才行,如下所示:
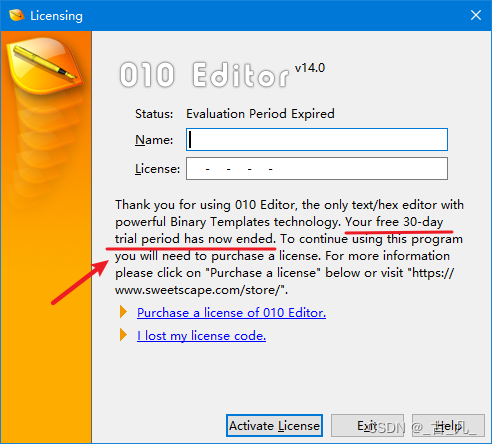
随便输入一串字符串然后点击验证证书,发现出现弹窗提示出错。
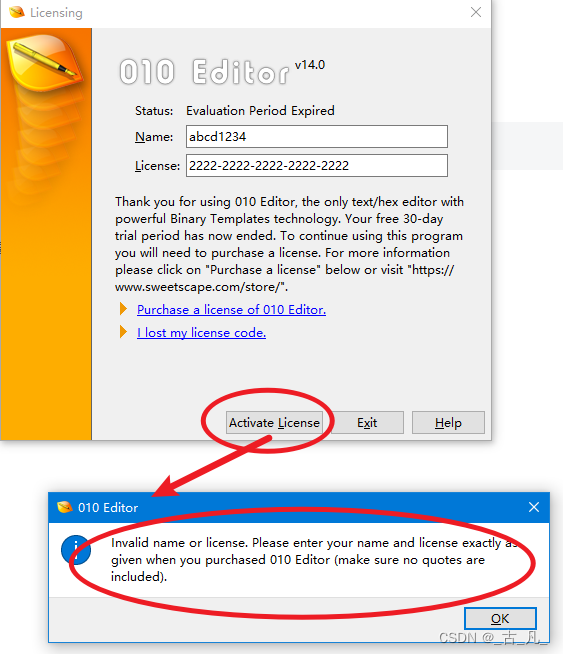
从上面的出错信息可以找一些特征词,例如“Invalid name or license...”这段字符串就是破解的关键词入口。下面打开IDA Pro开始操刀。
4.2 定位分析
首先打开字符串窗口,View > Open subviews > Strings点击顺序打开窗口,然后在窗口中搜索上述加粗的特征关键词。

点击该字符串,会跳转到对应的反汇编代码上,然后点击交叉引用DATA XREF: sub_5DC320+61F↑,会跳转到该字符串调用的地方,如下图:
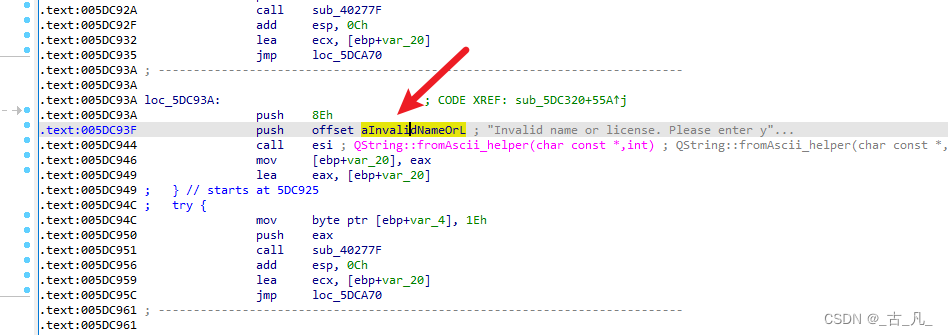
然后按F5将该反汇编代码转为C伪代码,可以看出来一个名为v22的变量值不等于147就会报该信息。
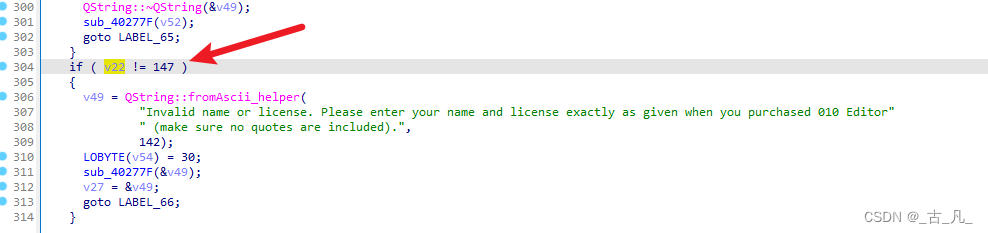
继续往上跟踪v22变量,该过程中发现有证书激活成功的字符串,是由v21变量控制,v21等于219就会激活成功,v21变量由v28或者v19赋值,而v19或者v28都是sub_407FFE函数的返回值。
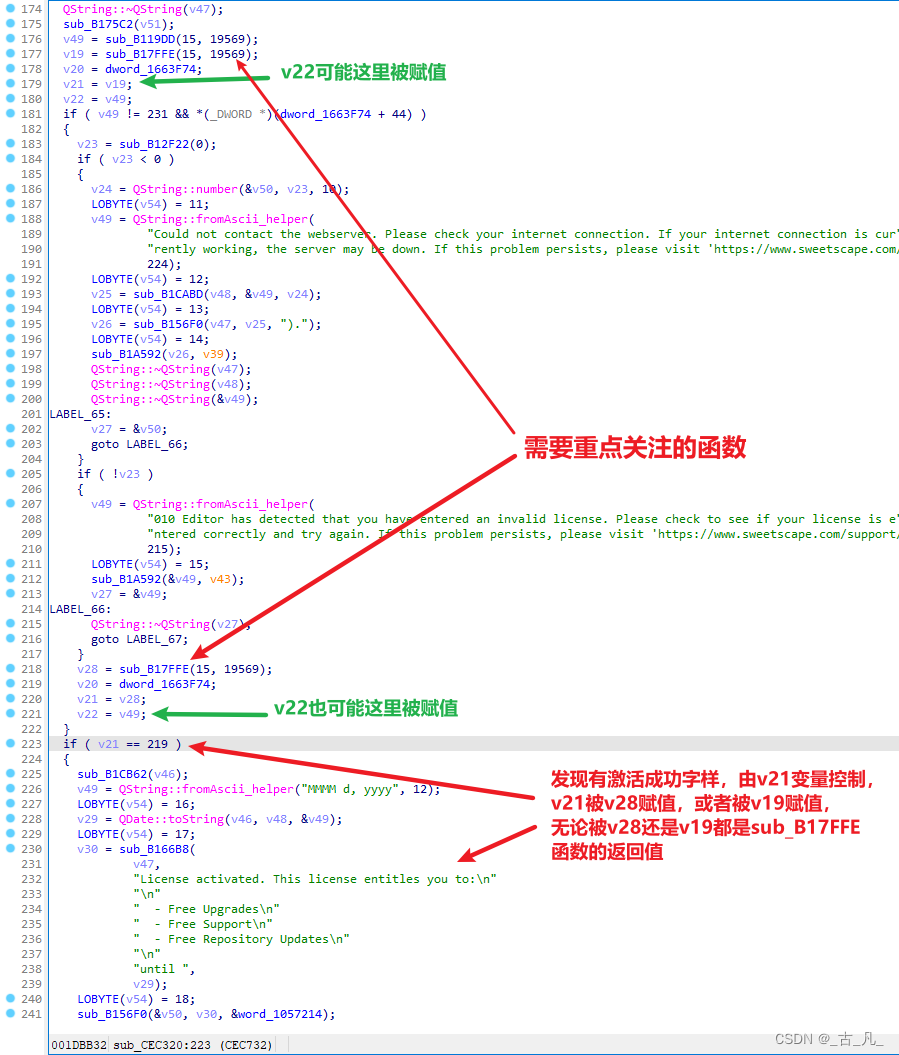
到这里可以停下来思考下,那是不是把v21改为219,把v22改为147就能注册成功呢?可以在第223行对应的反汇编代码处添加断点,进行验证。

添加完断点之后的程序,开始进入调试模式,按照4.1章节的操作顺序操作,发现程序在断点处停止,回到C伪代码模式,可以看到v21变量存在ebx寄存器中,v22变量存在eax寄存器中,可以在通用寄存器窗口对寄存器的值进行修改,也就是对变量的值进行修改。
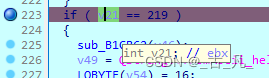
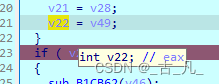
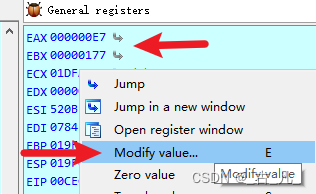
将eax(v22)改为147(0x93h),ebx(v21)改为219(0xDBh),然后再次运行,发现注册成功,并且进入到软件主界面。
4.3 修改代码
上面已经验证没有问题,紧接着就是对可执行文件的修改,否则下次打开还是需要证书验证。
在上面已经发现了重要函数sub_407FFE的返回值是关键,所以可以在该函数内部,将返回值全部改为所需要的0xDB即可,而v22的值可以暂时不用管,因为通过C伪代码发现,只要验证成功了,就不会走到v22值的判断逻辑。
下面进入到sub_407FFE内部查看如何修改:
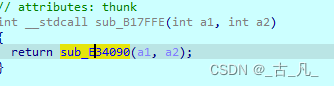
sub_407FFE中调用sub_E34090函数,继续跟进。

如果要返回219发现需要sub_B119DD返回45才行。那么如果想直接返回219,可以在上面if(this[11])判断的地方进行修改,使总是能进入到判断,然后返回219即可。
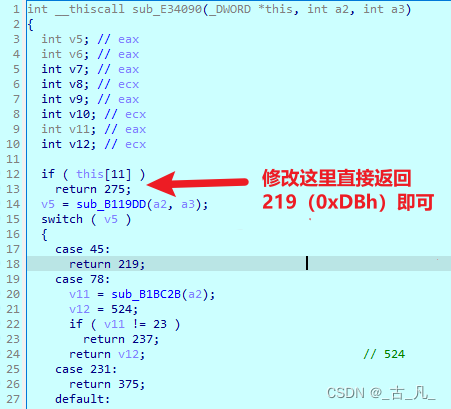
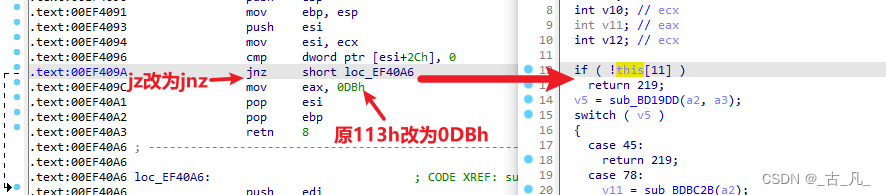
按照上图中方法修改,按tab找到对应的汇编位置,使用Edit > Patch program > Assemble修改代码,修改完之后再使用Edit > Patch program > Apply patches to input file(参考3.2章节修改),保存被修改的可执行文件。下面是修改后的结果:
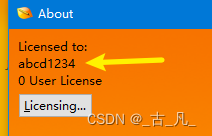
修改之后再次运行,会发现程序打开之后会直接进入到主界面,不会再弹出注册窗口,并且已经显示注册的用户名信息。
至此已经逆向修改成功,本次是最简单的入门逆向实战,通过修改判断值以达到目的,总结步骤可有下几步:
- 寻找特征关键字符;
- 搜索关键字符在反汇编代码中出现的位置;
- 结合上下文找到成功字符的判断变量值;
- 调试模式中设置寄存器变量值,验证猜测正确性;
- 猜想正确后,针对该变量寻找可修改点设置给定值;
- 保存修改的代码到源程序中,即可使用;
五、反逆向技术
实际上所有的软件都可以被破解,只是难度不再像上面实战的那么容易,所谓的反逆向技术不是说绝对的无法逆向,而是使用一些技术让逆向变的困难,例如加壳技术就是其中一种。
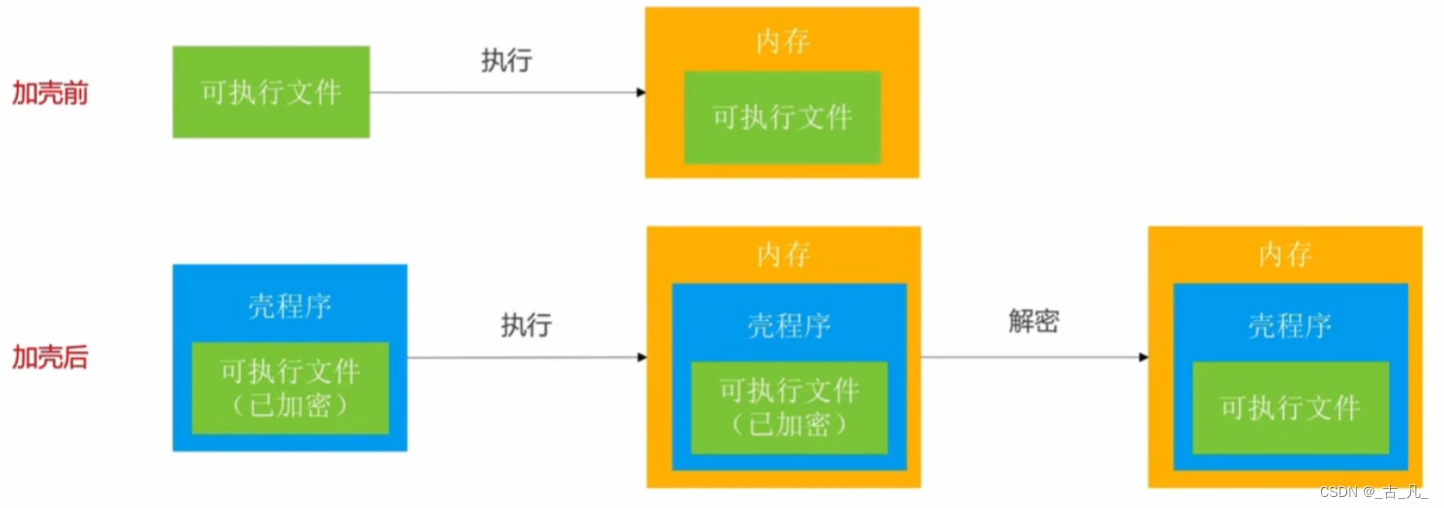
加壳原理是在二进制的程序中植入一段代码,在运行的时候优先取得程序的控制权,之后再把控制权交还给原始代码,如下图对比加壳和没有加壳对比情况,使用特定的算法和技术将应用程序进行包装和保护,以防止逆向工程和恶意攻击者窃取敏感信息、篡改应用程序等手段。
另外要知道加壳不仅仅是反逆向,实际上也有很多其他的用途,例如降低程序的大小,因为对主程序进行了压缩,所以实际程序会比加壳之前的程序要小。如果到非法攻击者手里,加壳技术可能就是用来隐藏病毒的一种方式,逃避杀毒软件查杀。
几种常见的壳类型:
- 加密壳,加密过程复杂,结合网络代码,破解成本较高;
- 虚拟机壳,增加虚拟机保护代码段,保护代码不容易被逆向分析;
- 轻量级壳,压缩代码,改变代码特征;
道高一尺,魔高一丈。逆向分析和反逆向技术都在不断的发展,但终究没有绝对不能逆向的软件,只是逆向难度在不停增加, 只要逆向带来的收益比付出的成本大,那么再难的反逆向也都是浮云。