本文转载自微软 DeepSpeed 团队官方知乎账号:zhihu.com/people/deepspeed,由微软 DeepSpeed 团队翻译自官方英文博客:Announcing the DeepSpeed4Science Initiative: Enabling large-scale scientific discovery through sophisticated AI system technologies,本文略作调整。

在接下来的十年中,深度学习可能会彻底改变自然科学,增强我们对自然现象进行建模和预测的能力。这可能预示着科学探索的新时代,为从药物开发到可再生能源的各个领域带来重大进展。为了响应这一机会以及微软“予力全球每一人、每一组织,成就不凡”的使命,微软 DeepSpeed 团队启动了一个名为 DeepSpeed4Science 的新计划,旨在通过 AI 系统技术创新帮助领域专家解锁当今最大的科学之谜。
DeepSpeed 系统是由微软开发的业界领先的开源 AI 系统框架,它为各种 AI 硬件上的深度学习训练和推理提供了前所未有的规模和速度。图1展示了我们对 DeepSpeed4Science 这一新计划的基本方法。通过利用 DeepSpeed 当前的技术方案(训练、推理和压缩)作为基础技术推动器,DeepSpeed4Science 将创建一套专为加速科学发现而量身定制的 AI 系统技术,以应对其独特的复杂性,超越用于加速通用大型语言模型(LLMs)的常见技术方法。我们与拥有科学 AI 模型的内部和外部团队紧密合作,以发现和解决领域特定 AI 系统的挑战。这包括气候科学、药物设计、生物学理解、分子动力学模拟、癌症诊断和监测、催化剂/材料发现、和其他领域。

图1:DeepSpeed4Science 方法概述:专为加速科学发现和应对其复杂性而量身定制的 AI 系统技术开发。
我们的长期愿景是将 DeepSpeed4Science 发展成一个用于分享支持科学发现的先进 AI 技术的软件平台和统一代码仓库。DeepSpeed4Science 的设计旨在包容性,呼应微软的“AI for Good”承诺。这体现在该计划对一系列标志性科学模型的支持上,他们代表了一些最关键的 AI4Science 应用场景。在这篇博客中,我们展示了 DeepSpeed4Science 如何帮助解决结构生物学研究中的两个关键 AI 系统挑战:(1) 解决了以 Evoformer 为中心的蛋白质结构预测模型中的内存爆炸问题,以及(2)为更好地理解引发大流行的病毒的进化提供 AI 模型长序列支持。
我们的初期主要合作者
DeepSpeed4Science 的新系统技术可以用于很多推动科学边界的标志性模型,赋能 AI 驱动的科学发现。目前,DeepSpeed4Science 很荣幸地支持来自微软研究院 AI4Science(微软研究院科学智能中心)、微软 WebXT/Bing、美国能源部国家实验室和多所大学的几个关键科学模型。
微软内部合作伙伴
- 科学基础模型(Scientific Foundation Model,SFM),微软研究院 AI4Science


图2:科学基础模型(Scientific Foundation Model,SFM)及其当前探索:Distributional Graphormer。
科学基础模型(SFM)旨在创建一个大规模基础模型,以支持自然科学发现。其支持多种输入模态、多个科学领域(例如,药物、材料、生物学、健康等)的计算任务。DeepSpeed4Science 合作伙伴关系将为 SFM 团队提供新的训练和推理技术,以助力他们的新 AI 方法(例如Distributional Graphormer),为其带来更高的效率与更多的研究突破。
- ClimaX,微软研究院 AI4Science

图3:ClimaX 是第一个设计用于执行各种天气和气候建模任务的基础模型
我们的气候正在发生变化,导致极端天气事件的频率增加。为了减轻负面影响,预测这些事件将发生的地方变得越来越重要。ClimaX 是第一个设计用于执行各种天气和气候建模任务的基础模型。它可以吸收许多具有不同变量和分辨率的数据集以提高天气预报的准确性。DeepSpeed4Science 正在为 ClimaX 创建新的系统支持和加速策略,以高效地预训练/微调更大的基础模型,同时处理非常大的高分辨率图像数据(例如,数十到数百PB)和长序列。
- 分子动力学与机器学习力场 (Molecular Dynamics and Machine Learning Force Field),微软研究院 AI4Science

图4:一百万步的分子动力学模拟:RBD-蛋白(RBD-protein)与蛋白抑制剂(protein inhibitor)相互作用。
这个项目模拟了使用 AI 驱动的力场模型进行近似第一性原理计算精度的大型(百万原子)分子系统的动态模拟,同时保持了经典分子动力学的效率和可扩展性。这些模拟足够高效,可以生成足够长的轨迹来观察化学上有意义的事件。通常,这个过程需要数百万至数十亿的推理步骤。这对优化图神经网络(GNN)+ LLM 模型的推理速度提出了重大挑战,DeepSpeed4Science 将为此提供新的加速策略。
- 微软天气,微软WebXT/Bing

图5:微软降水预报(每4分钟一次对接下来4小时进行预测)。
微软天气提供精确的天气信息,帮助用户为他们的生活方式、健康、工作和活动做出更好的决策——包括每小时多次更新的准确的10天全球天气预报。此前,微软天气受益于 DeepSpeed 技术,加速了他们的多 GPU 训练环境。目前,DeepSpeed4Science 正在与微软 WebXT 天气预报团队合作,进一步增强微软天气预报服务的最新功能和改进。
外部合作者
DeepSpeed4Science 的旅程始于两个开创性的基于 LLM 的结构生物学研究 AI 模型:来自哥伦比亚大学的 OpenFold,一个开源的高保真蛋白质结构预测模型;以及来自阿贡国家实验室的 GenSLMs,一个获得 ACM 戈登贝尔奖的用于学习 SARS-CoV-2(COVID-19) 基因组的进化的语言模型。作为此次发布的特色展示,它们代表了当今 AI 驱动的结构生物学研究面临的两个常见 AI 系统挑战。我们将在下一节中讨论 DeepSpeed4Science 如何赋能这些科学研究。
此外,DeepSpeed4Science 最近扩大了其范围,以支持更多样的科学模型。例如,在我们与阿贡国家实验室合作训练 Aurora Exascale 系统上的万亿参数科学模型的工作中,DeepSpeed4Science 技术将帮助他们达到这一关键任务所需的性能要求和可扩展性。此外,通过与橡树岭国家实验室和国家癌症研究所(NCI)合作进行癌症监测,DeepSpeed4Science 将帮助从非结构化的临床文本中高保真地提取和分类信息,以供 MOSSAIC 项目使用。Brookhaven 国家实验室还将采用 DeepSpeed4Science 技术,支持使用 LLMs 开发大型数字双胞胎模型,以便为清洁能源研究产生更真实的模拟数据。您可以在 deepspeed4science.ai 上找到有关我们外部合作者及其科学任务的更多详细信息。
合作展示
展示(I):DeepSpeed4Science 通过 DS4Sci_EvoformerAttention 消除以 Evoformer 为中心的结构生物学模型的内存爆炸问题


图6:在训练过程中 OpenFold 对 PDB 链7B3A_A的预测。
OpenFold 是 DeepMind 的 AlphaFold2 的开源社区再现,使其可以在新数据集上训练或微调 AlphaFold2。研究人员已经使用它从头开始重新训练 AlphaFold2,生成新的模型参数集,研究 AlphaFold2 的早期训练阶段(图6),并开发新的蛋白质折叠系统。

图7:在 OpenFold 中,对多序列比对(MSA)Attention 内核(包含偏差)变体的训练峰值内存需求。DeepSpeed4Science 的一种新解决方案 DS4Sci_EvoformerAttention 在不影响模型品质的条件下显著地减少了 OpenFold 的训练峰值内存需求(最多13倍)。
尽管 OpenFold 有使用最先进的系统技术进行性能和内存优化,但从头开始训练 AlphaFold2 仍然在计算上很昂贵。目前阶段的模型参数很小,只有9300万个参数,但它包含了几个需要非常大的中间内存的特殊 Attention 变体。在标准 AlphaFold2 训练的“微调”阶段,只是这些变体中的其中一个在半精度下就生成了超过 12GB 的张量,使其峰值内存要求远远超过了相同大小的语言模型。即使使用像 activation checkpointing 和 DeepSpeed ZeRO 优化这样的技术,这种内存爆炸问题仍然严重限制了可训练模型的序列长度和 MSA 深度。此外,近似策略可能会显著影响模型的准确性和收敛性,同时仍然导致内存爆炸,如图7左侧(橙色)所示。
为了应对结构生物学研究(例如,蛋白质结构预测和平衡分布预测)中的这一常见系统挑战,DeepSpeed4Science 通过为这类科学模型中广泛出现的注意力变体(即 EvoformerAttention)设计定制的精确注意力内核来解决这一内存效率问题。具体来说,我们设计了一套由复杂的融合/矩阵分块策略和动态内存减少方法而组成的高内存效率 DS4Sci_EvoformerAttention 内核,作为高质量机器学习模块供更广泛的生物学研究社区使用。通过整合到 OpenFold 中,这些定制内核在训练期间提供了显著的加速,并显著减少了模型的训练和推理的峰值内存需求。这使得 OpenFold 可以用更大、更复杂的模型,使用更长的序列在更广泛的硬件上进行实验。关于这项技术的详细信息可以在这里找到:https://deepspeed4science.ai/2023/09/18/model-showcase-openfold/
展示(II):DeepSpeed4Science 通过系统和算法方法为基因组基础模型(例如,GenSLMs)提供长序列支持


图8:GenSLMs:获2022年 ACM 戈登贝尔奖的 COVID 基因组模型(基于 GPT-NeoX 的 25B/33B 模型)。它用于学习描述 SARS-CoV-2 基因组生物学意义的潜在空间。这个 GIF 展示了一个重要的蛋白质家族苹果酸脱氢酶(malate dehydrogenase)的根据重要特征着色的潜在空间的投影。
GenSLMs,一个来自阿贡国家实验室的2022年 ACM 戈登贝尔奖获奖的基因组模型,可以通过大型语言模型(LLMs)的基因组数据训练来学习 SARS-CoV-2(COVID-19)基因组的进化。它旨在改变如何识别和分类引发大流行的病毒(特别是 SARS-CoV-2)的新变种。GenSLMs 代表了第一批可以泛化到其他预测任务的基因组基础模型。对潜在空间的良好理解可以帮助 GenSLMs 处理超出仅仅是病毒序列的新领域,并扩展它们模拟细菌病原体甚至真核生物的能力(例如,理解功能、途径成员资格和进化关系等事物)。为了实现这一科学目标,GenSLMs 和类似的模型需要非常长的序列支持用于训练和推理,这超出了像 FlashAttention 这样的通用 LLM 的长序列策略。通过 DeepSpeed4Science 的新设计,科学家现在可以构建和训练具有显著更长的上下文窗口的模型,允许他们探索以前无法访问的关系。
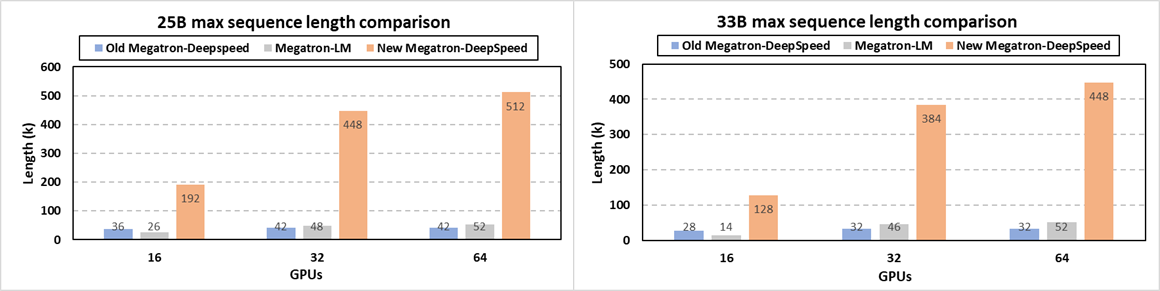
图9:由不同框架在不同规模下支持的两个 GenSLMs 模型的最大序列长度。使用 NVIDIA DGX,每个节点有八个40G A100 GPU。
具体在系统层面,我们发布了包括长序列支持和其他新优化的最新的 Megatron-DeepSpeed 框架。科学家现在可以通过我们新添加的内存优化技术(如注意力掩码异步处理和位置码分割)、张量并行、流水线并行、序列并行、基于 ZeRO 的数据并行和模型状态异步处理等技术的协同组合,用更长的序列训练他们的 GenSLMs 等大型科学模型。图9展示了我们的新版本使 GenSLMs 的25B和33B模型的最长序列长度分别比之前的 Megatron-DeepSpeed 版本增加了12倍和14倍。在支持的序列长度方面,这个新 Megatron-DeepSpeed 框架也显著地超过了 NVIDIA 的 Megatron-LM(对于25B和33B模型分别高达9.8倍和9.1倍)。例如,阿贡实验室团队的 GenSLMs 25B 模型在64个 GPU 上的原始序列长度为42K,而现在可以用512K的核苷酸序列进行训练。这在不损失准确性的条件下大大提高了模型质量和科学发现的范围。对于那些更喜欢相对位置编码技术这样的算法策略的领域科学家,这个新版本也进行了集成。
总结和路线图
我们非常自豪和兴奋地宣布 DeepSpeed4Science 计划以及几个研发亮点和成果。从今天开始,我们将在 deepspeed4science.ai 上介绍我们的新计划,包括关于我们的外部合作者的信息,以及当前和未来的 DeepSpeed4Science 技术发布。我们的一个高层次目标是推广广泛解决大规模科学发现的主要系统痛点的 AI 系统技术。我们希望全球的科学家们能够从 DeepSpeed4Science 通过开源软件解锁的新功能中受益。我们期待更好地了解阻碍您的科学发现的 AI 系统设计挑战。我们真诚地欢迎您的参与,帮助构建一个更有前途的 AI4Science 未来。请给我们发送电子邮件至 deepspeed-info@microsoft.com。我们鼓励您在我们的 DeepSpeed GitHub 上报告问题、贡献 PR、参与讨论。
致谢
Core DeepSpeed4Science Team:
Shuaiwen Leon Song (DeepSpeed4Science lead), Minjia Zhang, Conglong Li, Shiyang Chen, Chengming Zhang, Xiaoxia (Shirley) Wu, Masahiro Tanaka, Martin Cai, Adam Graham, Charlie Zhou, Yuxiong He (DeepSpeed team lead)
Our Founding Collaborators (in alphabetical order):
Argonne National Lab team: Rick Stevens, Cristina Negri, Rao Kotamarthi, Venkatram Vishwanath, Arvind Ramanathan, Sam Foreman, Kyle Hippe, Troy Arcomano, Romit Maulik, Maxim Zvyagin, Alexander Brace, Yuntian Deng, Bin Zhang, Cindy Orozco Bohorquez, Austin Clyde, Bharat Kale, Danilo Perez-Rivera, Heng Ma, Carla M. Mann, Michael Irvin, J. Gregory Pauloski, Logan Ward, Valerie Hayot, Murali Emani, Zhen Xie, Diangen Lin, Maulik Shukla, Weili Nie, Josh Romero, Christian Dallago, Arash Vahdat, Chaowei Xiao, Thomas Gibbs, Ian Foster, James J. Davis, Michael E. Papka, Thomas Brettin, Anima Anandkumar
AMD: Ivo Bolsen, Micheal Schulte, Bo Begole, Angela Dalton, Steve Reinhart, Ashwin Aji, Jalal Mahmud, Mahesh Balashibramanian
Brookhaven National Lab team: Adolfy Hoisie, Shinjae Yoo, Yihui Ren.
Columbia University OpenFold team: Mohammed AlQuraishi, Gustaf Ahdritz
Microsoft Research AI4Science team: Christopher Bishop, Bonnie Kruft, Tie-Yan Liu, Christian Bodnar, Wessel Bruinsma, Chan Cao, Yuan-Jyue Chen, Peggy Dai, Patrick Garvan, Liang He, Elizabeth Heider, PiPi Hu, Peiran Jin, Fusong Ju, Yatao Li, Chang Liu, Renqian Luo, Qi Meng, Frank Noé, Tao Qin, Janwei Zhu, Bin Shao, Yu Shi, Wenlei Shi, Gregor Simm, Megan Stanley, Lixin Sun, Yue Wang, Tong Wang, Zun Wang, Lijun Wu, Yingce Xia, Leo Xia, Shufang Xie, Shuxin Zheng, Jianwei Zhu
Oakridge National Lab team: Prassana Balaprakash, Georgia Tourass
Princeton University: William Tang, Kyle Felker, Alexey Svyatkovskiy (Microsoft liaison)
Rutgers University: Hang Liu
WebXT Weather team: Pete Luferenko, Divya Kumar, Jonathan Weyn, Ruixiong Zhang, Sylwester Klocek, Volodymyr Vragov