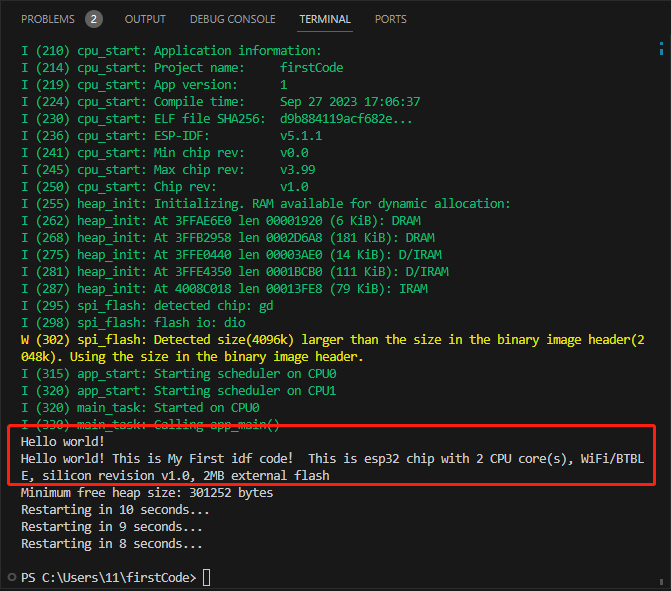
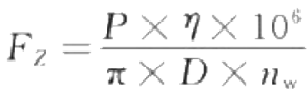作者介绍:李伟超,数据库系统架构师,YashanDB架设技术开发负责人,10年以上数据库内核技术开发经验。
*全文4510个字,阅读时长约11分钟。
背景
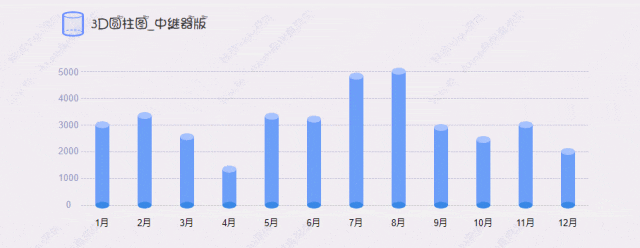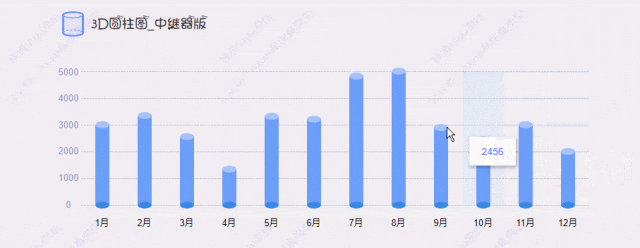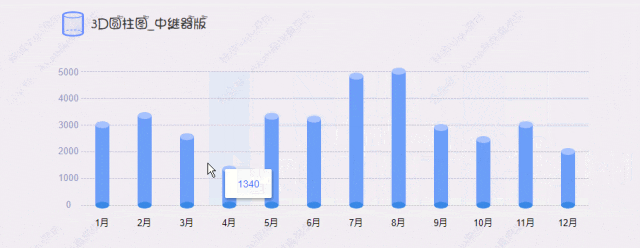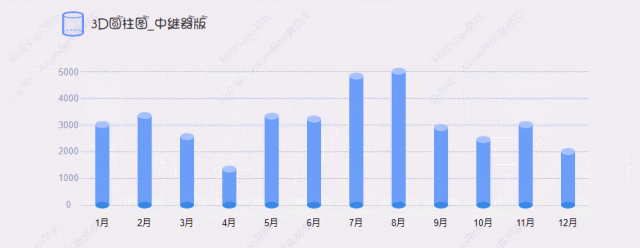
海量数据OLAP场景,通常具有数据规模大、查询复杂度高、处理速度要求高等特点,对SQL引擎的执行效率要求非常高。面向行式存储的行式执行引擎由于逐行扫描的方式,往往会导致大量的函数调用开销,性能方面无法满足业务需求。为了解决这个问题,基于列式存储的向量化执行引擎技术应运而生,该方式通过批量计算和充分利用CPU高速缓存和流水线,使得查询分析的性能相较于行式执行引擎得到数量级的提升。面向OLAP场景,YashanDB在列式存储基础上引入了向量化执行引擎技术,并取得了显著的查询性能提升。如下图,在TPC-H基准测试下,YashanDB基本维持秒级的查询响应时延,达到了行业领先水平。本文将为大家深入介绍向量化执行引擎的场景价值、技术优势以及YashanDB的实现机制。
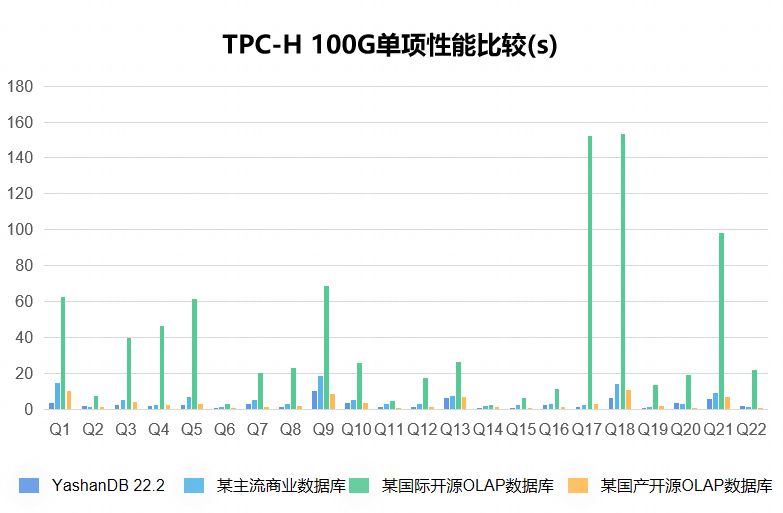
图1 TPC-H测试结果
硬件配置:2288虚拟机(16核,160G内存,3.4T SSD)
软件版本:OS(CentOS 7),DB(YashanDB 22.2)
测试模型:TPC-H 100G数据
为什么需要向量化计算?
火山模型的执行方式是从底层数据源向上拉取数据,这种方式也被称为“Pull模型”。
如下图所示,对于一个查询计划,上层算子每调用一次下层算子的next函数,下层算子向上返回一条记录,持续这个过程直至下层算子不再返回记录。它的逻辑简洁,易于理解和实现,一次一条记录的执行方式比较适合对查询响应时间有较高要求的OLTP场景,但是在面向海量数据分析时存在着严重的不足:每次一条记录的执行模式导致上下层算子之间以及表达式计算存在大量的函数调用开销,并且不能充分利用CPU高速缓存和流水线。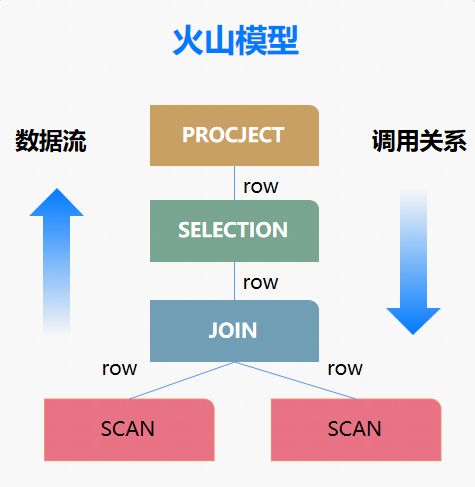
图2 火山模型执行方式
针对上面问题的改进方案,业界目前主要有两种方式:一种是基于JIT即时编译(Just-in-time Compilation)的查询优化,利用LLVM等编译框架对查询计划做运行时优化,通过内联优化等手段消除函数调用开销;另一种方式就是本文要讲的基于列存的向量化计算。要实现基于JIT的查询优化,需要对编译原理和LLVM等编译框架有深入的理解,对开发人员的技术要求以及工程实现的复杂度都较高,并且对编译框架有深度的耦合。相较而言向量化执行模型在OLAP场景批处理方面更有优势:基于局部性原理,对批量数据的计算能够更好的利用CPU缓存和流水线;同时,针对批量数据还可以利用SIMD指令实现向量化计算。

图3 向量化模型执行方式
如何实现向量化执行引擎?
实现向量化执行引擎主要包括以下几个方面的工作:
基于列存的组织结构:为了实现对数据的向量化计算,需要设计按列组织的内存结构,以充分利用CPU的缓存以及使用SIMD指令加速计算。
向量化的计算框架:在列存内存组织的基础上,提供一套基于列存的算子和表达式框架,以支持灵活可扩展的定义和实现各类算子和表达式。
针对查询计划执行的优化技术:通过优化器、向量化执行引擎和存储引擎的紧密配合,实现将查询条件下推到存储引擎以及针对HashJoin实现运行时过滤(Runtime Filter)。
内存管理:包括运行时的动态内存管理和针对物化算子的物化内存管理。
01 基于列存的组织结构
在向量化执行引擎模型中,列式存储占据着天然的优势。因为列存中数据以数组的形式存储,一列中的所有数据都会被同时读取和处理,这种方式与向量化计算非常吻合。向量化执行引擎以每次一批记录的方式执行,每批记录都是以列存的方式组织的。在向量化执行引擎中,列存数据的组织结构非常重要,因为它直接影响着计算效率。我们首先来看一下在向量化执行引擎中列存数据的组织结构。
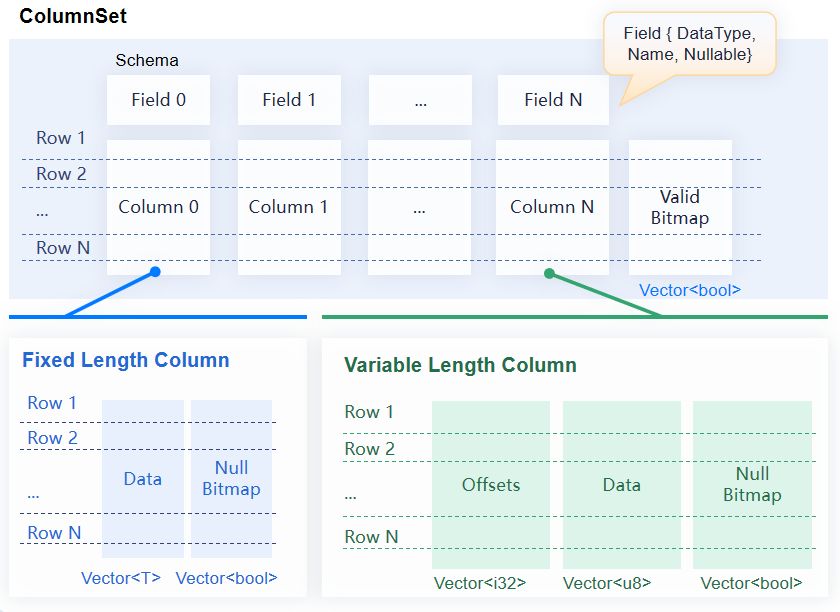
图4:YashanDB基于列存的组织结构
ColumnSet:我们将以列存的方式组织到一起的一批记录称为ColumnSet,它是一个二维的数据集,由许多相邻的向量组成,每个向量的记录数相同,不同向量之间按行逻辑对齐。与表类似,ColumnSet也有一个Schema,该模式必须匹配其向量的数据类型。ColumnSet是一个便于序列化和计算的工作单元,每个ColumnSet还有一个可选的位图用来表示ColumnSet中的行是否有效。
Schema:用来描述二维数据集的结构。它包含一系列Field和一些可选的模式范围的元数据。Field描述列的名称及其元数据。
Column:是一个与Field绑定在一起的分块向量,同时列还有一个可选的位图用来表示列中的值是否为空值。根据数据类型分为定长列(Fixed Length Column)和变长列(Variable Length Column)。定长列可以对数据直接按下标随机访问;而变长列需要先根据偏移向量计算出数据的起始位置和长度,然后访问数据。
Vector:表示已知长度并具有相同数据类型的标量值的序列。向量中的值由一块连续的内存存储,值的数量和意义由向量的数据类型决定。
02 计算框架
内存安全,高性能;
基于ColumnSet的批量计算,实现只读数据、无锁并发的向量化计算;
支持功能丰富的表达式计算和算子,完整支持TPC-H、TPC-DS语法;
高度灵活的可扩展性。
pub trait Operator {
fn bind(&self, ctx: Arc<dyn Context>) -> Result<Box<dyn Cursor>>;
}
pub trait Cursor {
fn next(&mut self) -> Result<Option<ColumnSet>>;
}
pub trait Expression {
fn bind(&self, ctx: Arc<dyn Context>, schema: &Schema) -> Result<Box<dyn BoundExpression>>;
}
pub trait BoundExpression {
fn evaluate(&mut self, column_set: &ColumnSet) -> Result<Arc<dyn Column>>;
}
03 条件下推
条件下推的规格:
支持多个字段的AND条件下推;
单个字段的多个条件,条件是OR的关系;
条件为等值查询和范围查询,比较值必须是常量。
Extent粒度的布隆过滤:支持等值条件;
块粒度的稀疏索引过滤:支持and,or,<,>,=,>=,<=,in等运算下的常量表达式;
支持编码数据的行级过滤;
向量化过滤计算。

图5:YashanDB 条件下推示意
04 运行时过滤
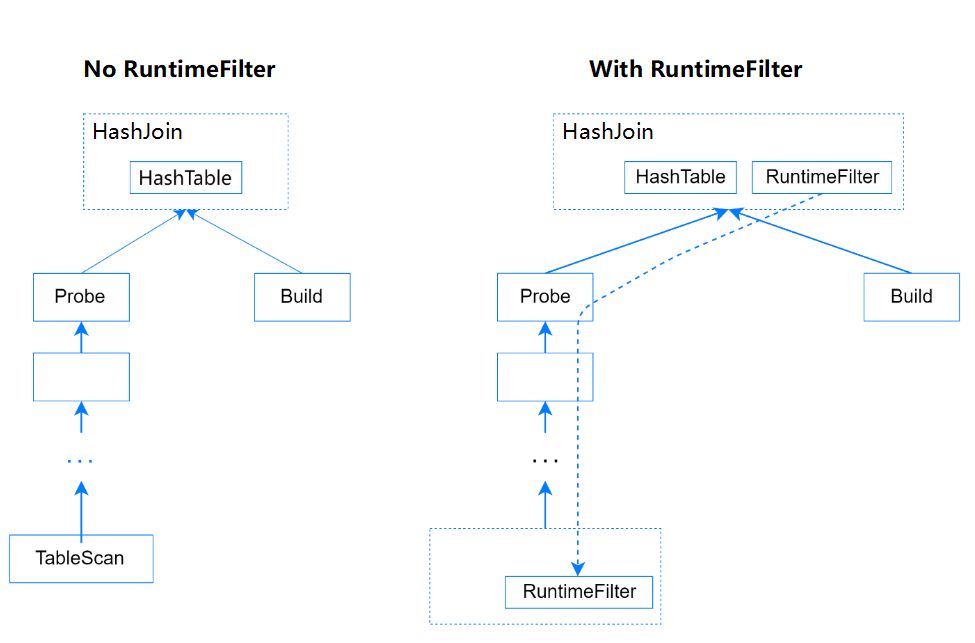 图6 No RuntimeFileter 和 RuntimeFileter示意
图6 No RuntimeFileter 和 RuntimeFileter示意
目前YashanDB实现的Runtime Filter支持的过滤方式是Bloom Filter(布隆过滤器)。HashJoin通常右表为小表,左表为大表,分别称为Build表和Probe表,其执行过程大致为:
取出Build表所有数据;
根据Build表数据构建HashTable;
再取出Probe表所有数据,同时基于HashTable生成Join结果;
针对这种情况,YashanDB在应用Runtime Filter时会检测其过滤效果,过滤效果较差时会禁用掉下推的Runtime Filter,避免性能劣化。以TPC-H模型的Q17为例,开启Runtime Filter之后耗时从7s左右变成1s左右。
05 动态内存管理
在列存组织结构中我们介绍到,计算过程中每次处理一批记录,即一个ColumnSet。每批记录的行数我们称为BulkSize,在一次计算过程中BulkSize是不变的,那么对于定长的数据类型列,比如int类型列,其每批记录占用的内存大小是固定的,都为size_of(int) * BulkSize。这块内存理论上来讲是可以被不同批次的ColumnSet中的相同列重复使用。
为解决这些问题,我们采取了一些优化策略。根据向量化执行引擎的运行时特点,YashanDB实现了一个定制化的动态内存管理机制——基于MemPool和Allocator的两级内存缓存机制,通过一套全局的缓存内存池和细粒度的内存分配器实现了高效的内存管理。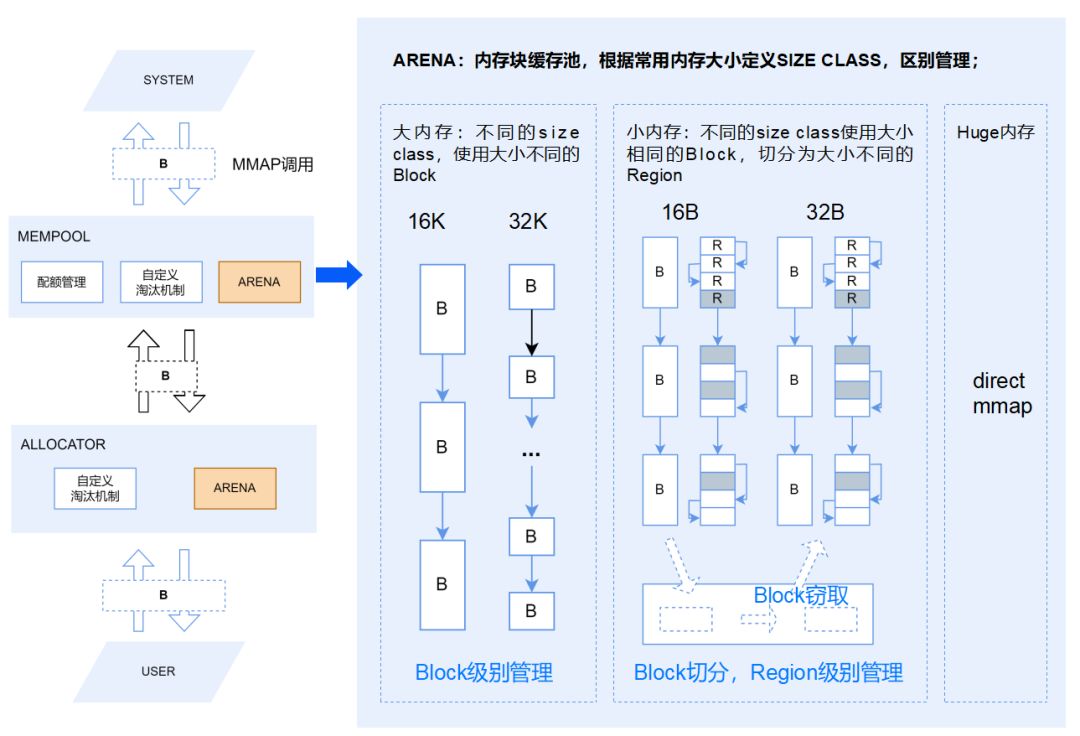 图7 YashanDB动态内存管理机制
图7 YashanDB动态内存管理机制
MemPool是一个全局共享的内存池,通过MMAP/MUNMAP向操作系统申请和释放内存,支持设定内存配额,在达到内存配额上限时,可以按策略淘汰空闲内存。
Stage(YashanDB中可执行的最小单元)粒度的Allocator:每个Stage会分配一个Allocator,Satge执行过程中的内存申请和释放优先在Allocator中进行,可以有效减少并发的内存申请释放的锁冲突。Allocator的内存从MemPool分配,Stage执行结束时,Allocator的内存会全部归还给MemPool。Allocator同样支持自定义的空闲内存淘汰机制。
MemPool和Allocator的内存缓存都是基于Arena实现的。Arena就是一个空闲内存块(Block)的缓存池,以链表进行管理。根据常用的内存大小定义了多个SizeClass,并且根据内存大小进行不同的管理:
大内存:不同的SizeClass使用大小不同的Block,进行Block级别管理;
小内存:不同的SizeClass使用大小相同的Block,Block切分成大小不同的Region,进行Region级别的管理;由于不同SizeClass使用的Block大小是相同的,在某个SizeClass无空闲内存时,可以先从具有相同Block大小的SizeClass中窃取空闲内存块,都没有时,再向内存池申请;
HUGE内存:大于2M的内存块,不进行缓存处理,执行通过MMAP/MUNMAP向操作系统申请和释放。
06 物化内存管理
传统的方法是按照计划给出来的评估值给出一个配额,超过这个值就写盘。这种方式的主要问题是执行所需要的内存是动态的,单一的配额导致不能有效利用内存。
YashanDB采用动态分配配额的方式来管理物化内存,将物化内存分成全局、SQL、Stage、算子四个级别。一条SQL语句执行前,根据计划评估结果,为物化内存分配合理的内存配额,并为其对应的Stage、算子也会分配合理的配额。执行过程中,可以在配额范围内动态申请内存,配额不足时可以自下而上申请更多的配额。当配额用完后,会将数据写到外部存储。 图8 YashanDB物化内存管理
图8 YashanDB物化内存管理
总结
向量化执行引擎是一个复杂的系统工程,随着硬件的不断演进,向量化执行引擎的技术演进将会是一个持续发展和优化的过程。在下一个版本中,我们会进一步提升TPC-DS的查询性能以及在行存列存混合计算场景方面的支持。
随着不断的优化改进,我们相信YashanDB的功能和性能会持续增强,进而更好的满足各种复杂业务场景的需求。