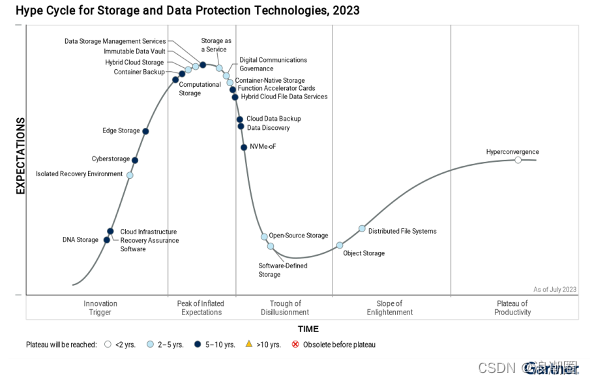
🧡🧡🧡这篇是关于Python中字符串的讲解,涉及到以下内容,欢迎点赞和收藏,你点赞和收藏是我更新的动力🧡🧡🧡
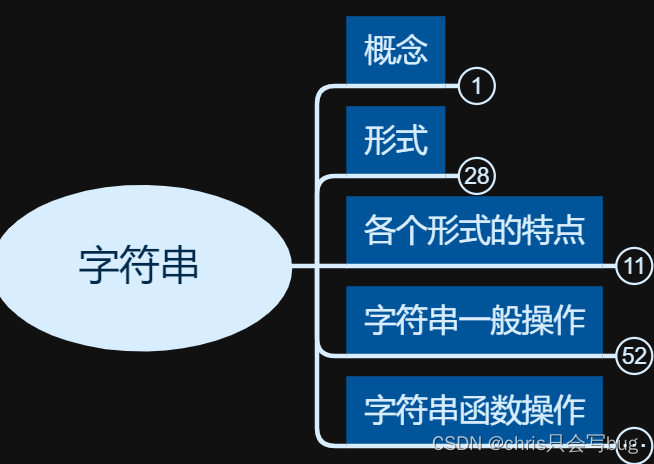
本文将从以下几个方面展开对字符串的讲解:
1、字符串的概念,到底什么是字符串
2、字符串表现形式有哪些
3、字符串每个形式有什么特点
4、字符串的一般操作有哪些
5、字符串有哪些函数、方法需要了解
字符串
- 1 字符串的概念
- 2 字符串表现形式
- 2.1 非原始字符串
- 2.2 转义字符
- 2.3 原始字符
- 3 各个形式字符串的特点
- 4 字符串的一般操作
- 4.1 字符串拼接
- 4.2 字符串切片
- 5 查找操作
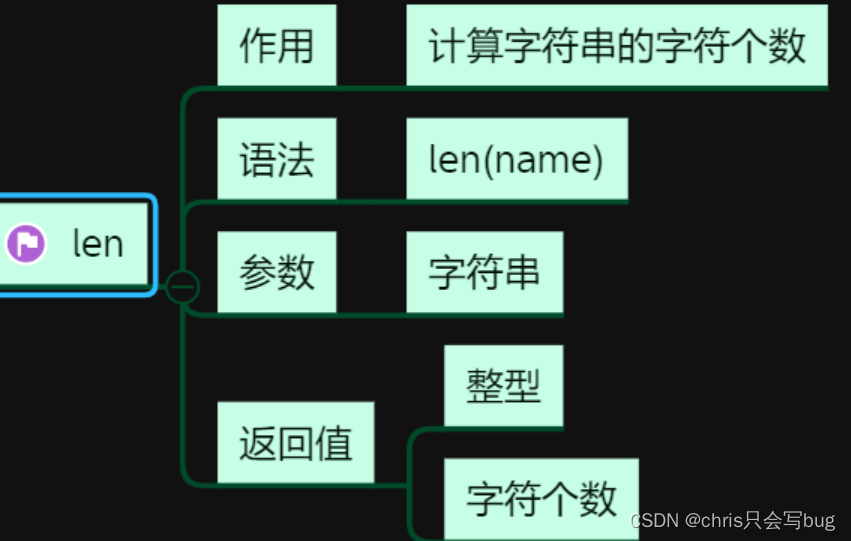
- 5.1 len()函数
- 5.2 find()方法
- 5.3 index()方法
- 5.4 count()方法
- 6 转换
- 6.1 replace()方法
- 6.2 capitalize()方法
- 6.3 title()方法
- 6.4 low()方法
- 6.5 upper()
- 7 填充压缩
- 7.1 ljust()方法
- 7.2 rjust()方法
- 7.3 center()方法
- 7.4 lstrip()方法
- 7.5 rstrip()方法
- 8 分割拼接
- 8.1 split()方法
- 8.2 partition()方法
- 8.3 rpartition()方法
- 8.4 splitlines()方法
- 8.5 join()方法
- 9 判定
- 9.1 isalpha()方法
- 9.2 isdigit()方法
- 9.3 isalnum()方法
- 9.4 isspace()方法
- 9.5 startwith()方法
- 9.6 endswith()方法
- 9.7 in/not in
1 字符串的概念
字符串,字符串,我们日常生活中总是在说字符串,到底什么是字符串呢?

字符串就好像我们吃过的糖葫芦,一串上面有多个糖葫芦
2 字符串表现形式
2.1 非原始字符串
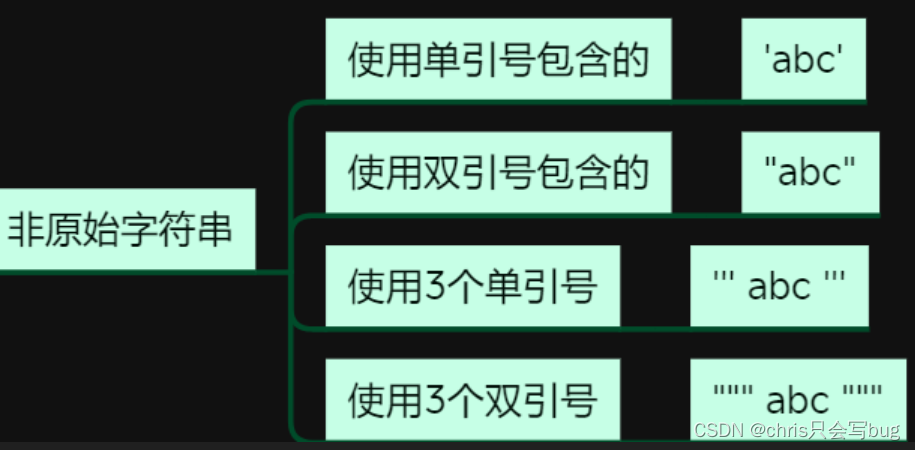
str1 = 'helloword'
str2 = "helloword"
str3 = """helloword"""
str4 = '''helloword'''
print(str1, str2, str3, str4)
创建好了字符串,我们如何验证该数据类型就是字符串呢?
str1 = 'helloword'
str2 = "helloword"
str3 = """helloword"""
str4 = '''helloword'''
# 使用type()函数可以查看数据类型
print(type(str1), type(str2), type(str3), type(str4))
2.2 转义字符
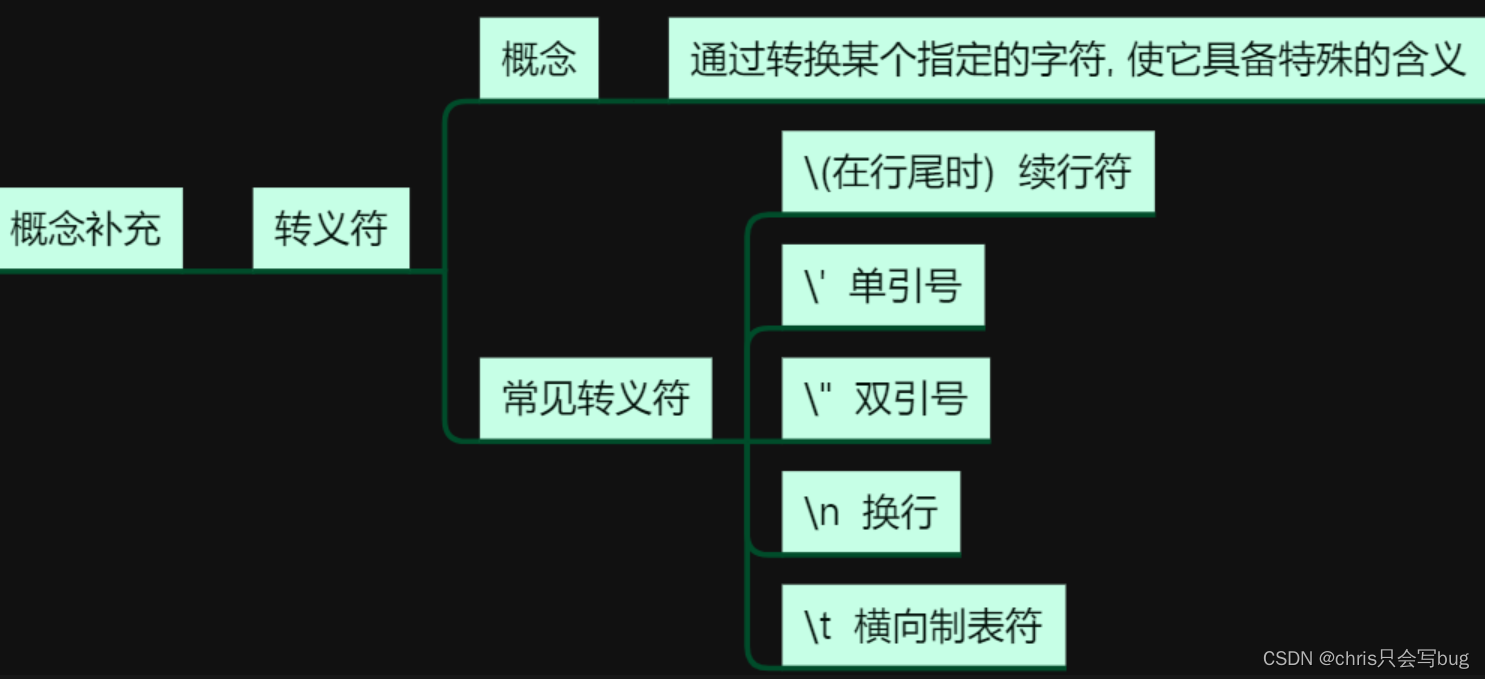
如何理解转义字符?
转义字符就是,通过转换某个指定字符,使它具备特殊的含义
# 比如,我要在单引号的字符串中打印单引号
str1 = 'hell'o'
print(str1)
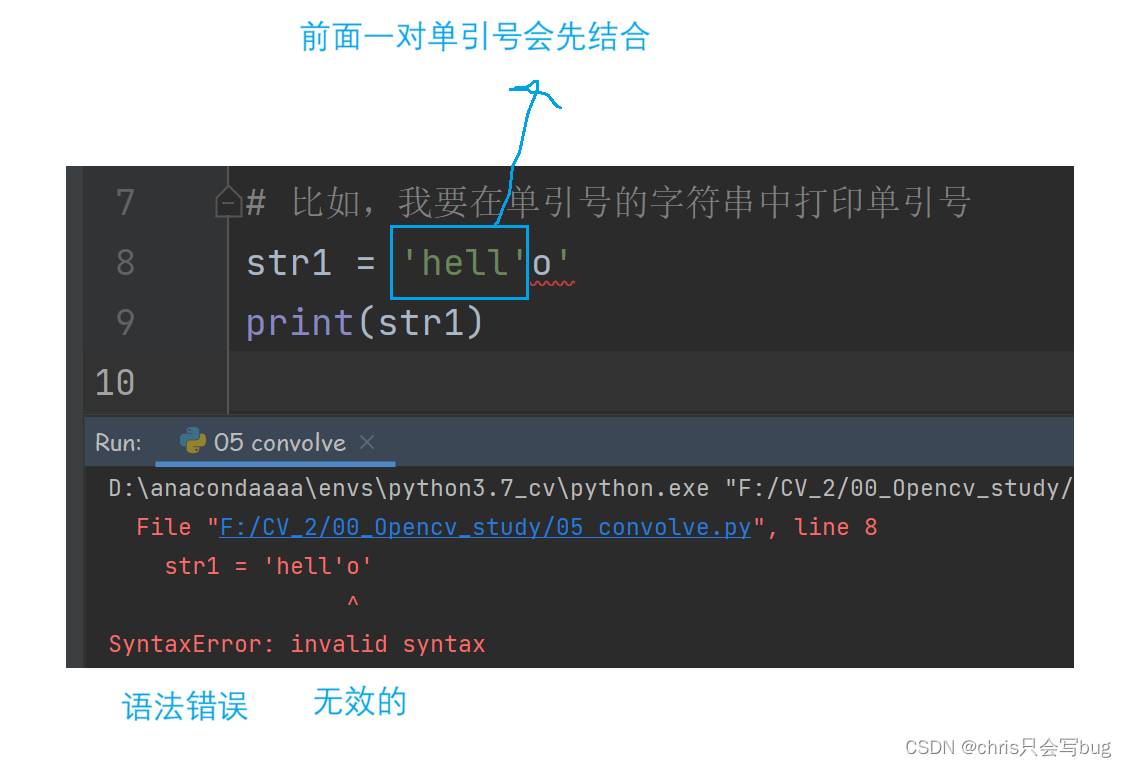
正确的使用转义字符
# 比如,我要在单引号的字符串中打印单引号
str1 = 'hell'o'
print(str1)
2.3 原始字符
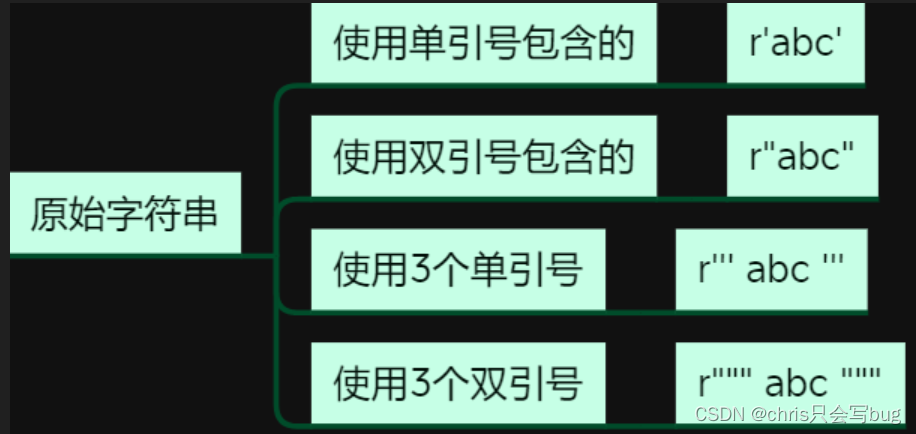
前面说到了转义字符,现在来看看原始字符串
# 原始字符串
# 原始字符串可以让转义字符失效
str1 = r'hell\'o'
print(str1)
str2 = r"hell\"o"
print(str2)
str3 = r'hello\nword'
print(str3)
str4 = r'hello\tword'
print(str4)
3 各个形式字符串的特点
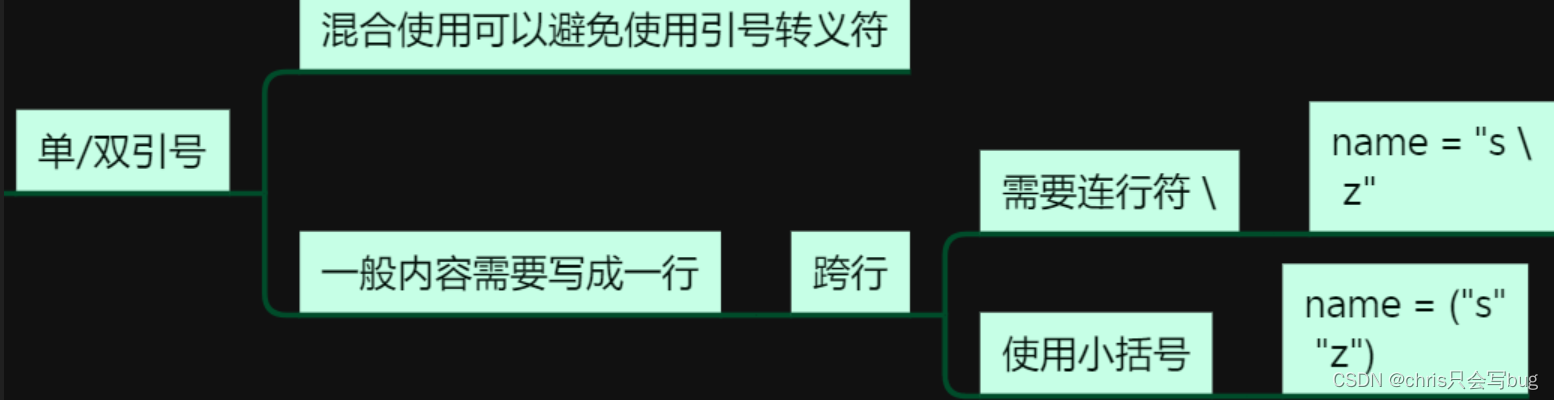
# 单引号、双引号混合使用可以避免使用转义字符
str1 = "hello'sword"
print(str1)
str2 = 'hello"sword'
print(str2)
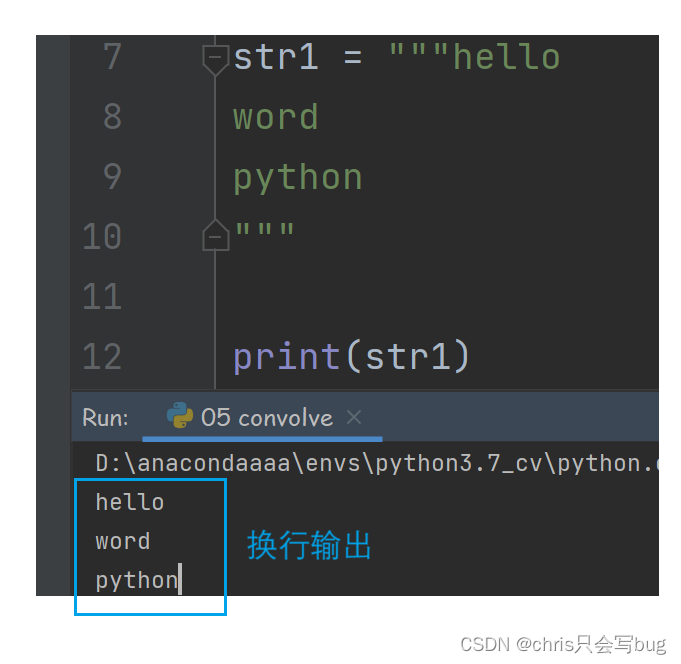
# 在Pycharm中,在字符串中,按下回车,会自动添加换行符
str1 = "hello's" \
"word"
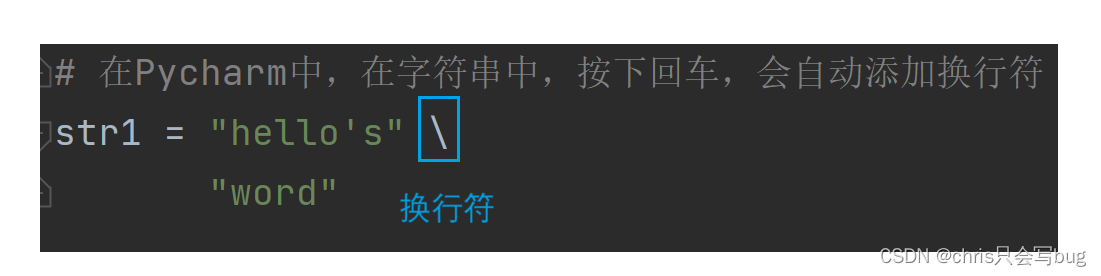
str1 = """hello
word
python
"""
print(str1)
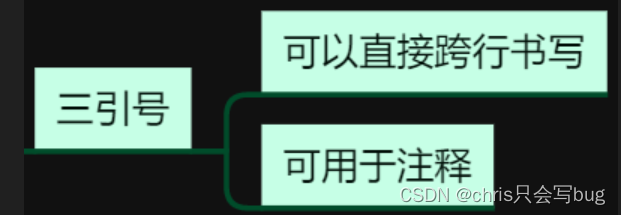
'''
三引号可以直接用于多行注释
对程序起到解释作用
'''
def fun():
"""
三引号可以作为文档字符串,用来解释该函数的作用
:return:
"""
pass
4 字符串的一般操作
4.1 字符串拼接
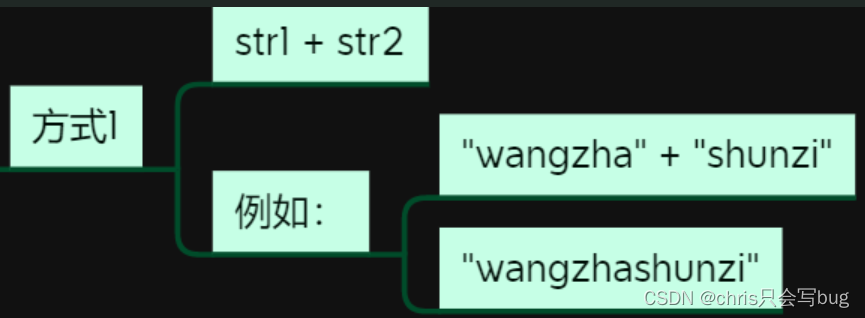
str1 = 'hello'
str2 = 'word'
print(str1+str2)
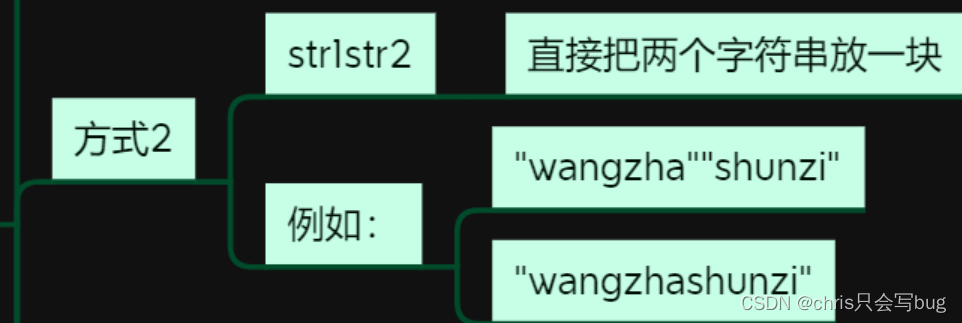
print('hello''word')
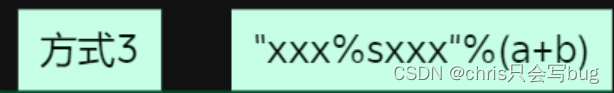
str1 = 'hello'
str2 = 'word'
print('我将要打印:%s' % (str1+str2))


str1 = 'hello'
str2 = 'word'
print(str1 * 10)
print(str2 * 5)
4.2 字符串切片

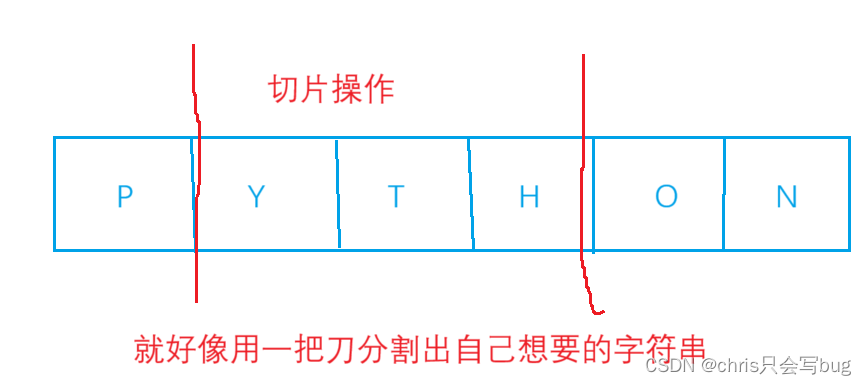
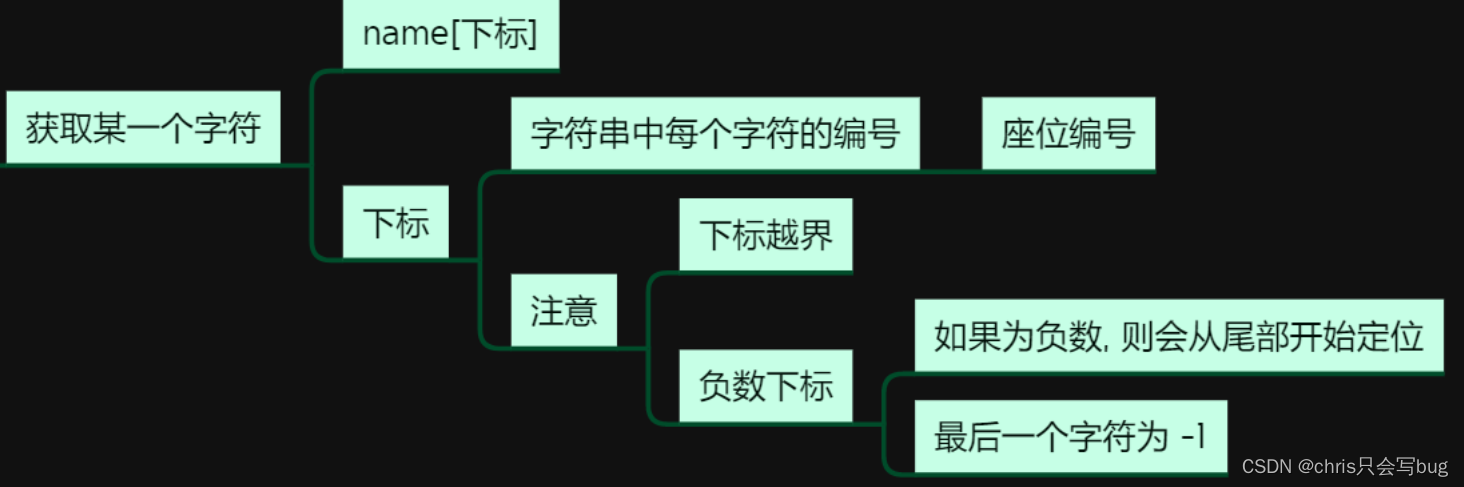
如何理解下标?
下标也可以理解为索引,通过下标我们可以获取某一具体的元素
下标的概念和座位编号的概念很像,我们通过座位编号可以找到座位上的人
有正下标也有负下表
str1 = 'ILovePython'
print(str1[0])
print(str1[-1])
print(str1[20])
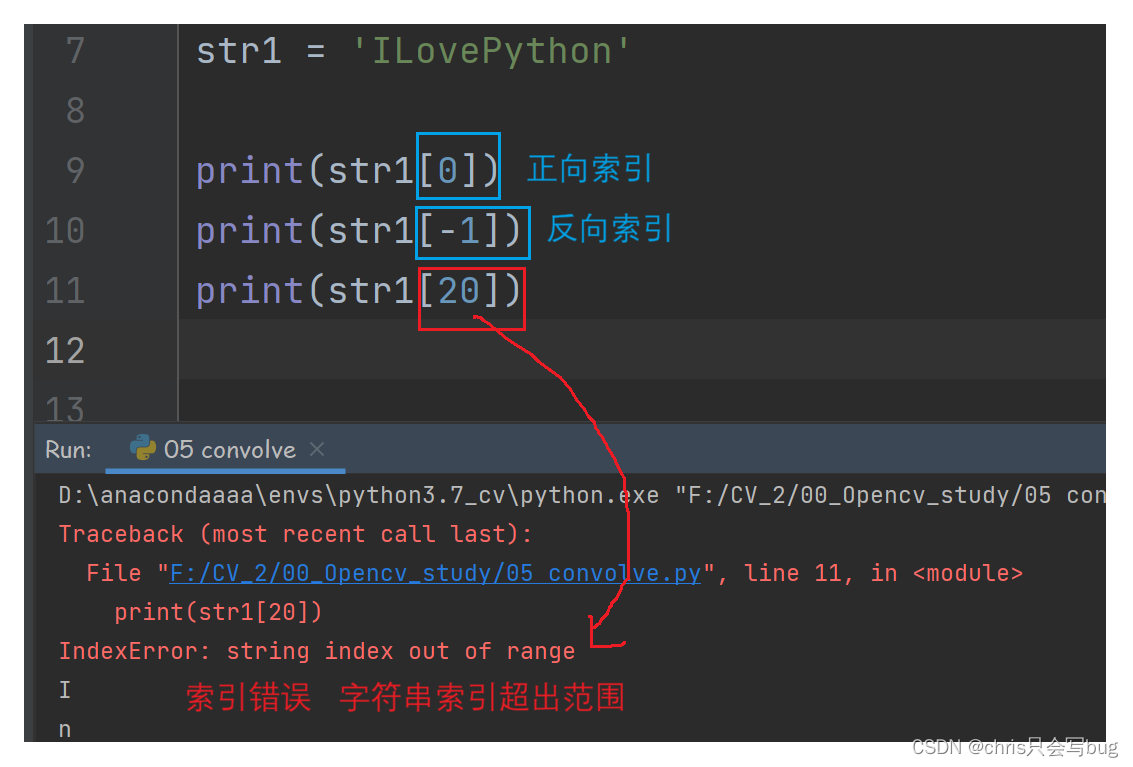
注意 注意 注意
索引下标千万不要越界
索引下标千万不要越界
索引下标千万不要越界
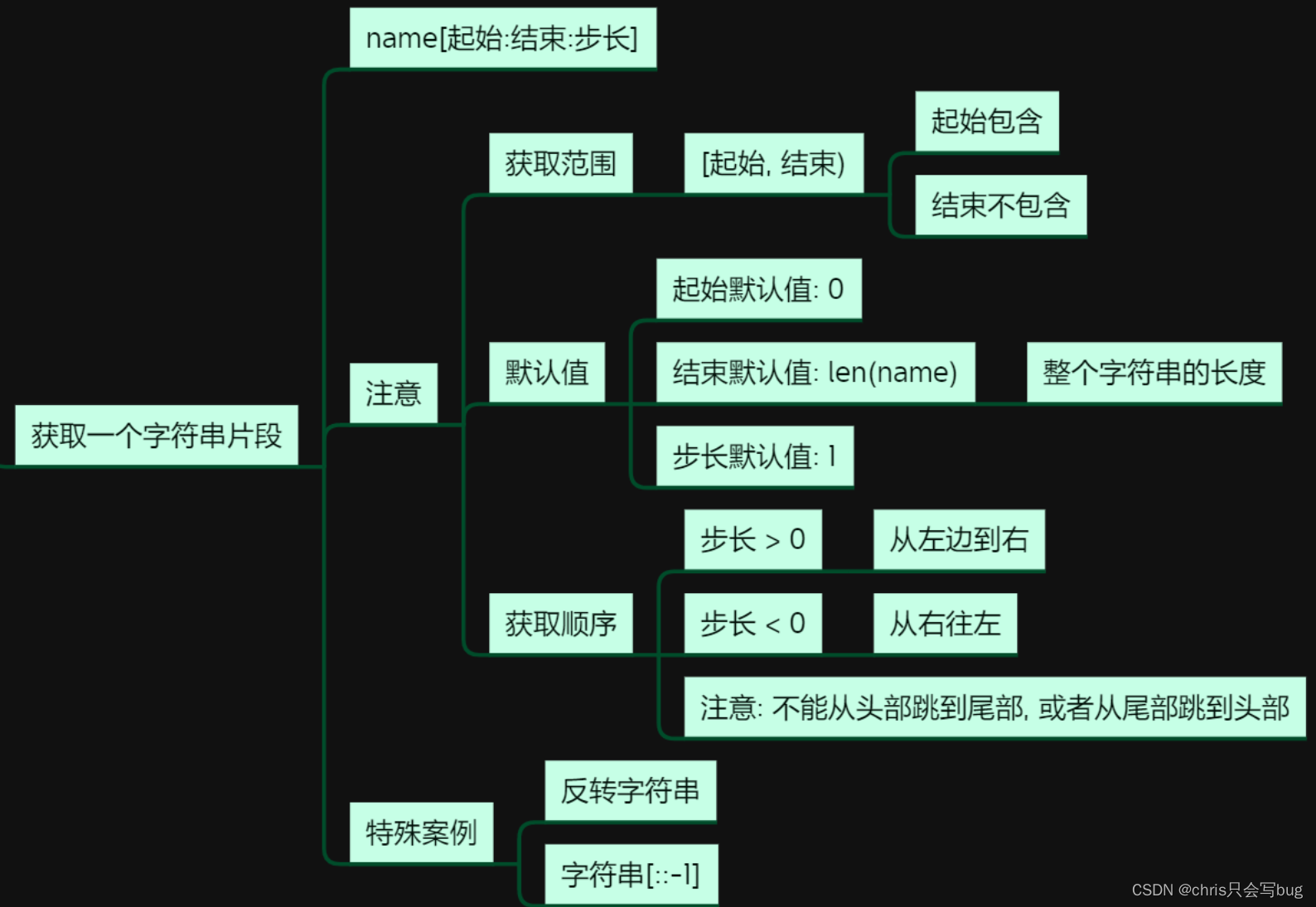
str1 = 'ILovePython'
print(str1[:]) # 默认获取整个字符串
print(str1[::-1]) # 反转字符串
# 切片操作一般有三个参数,起始位置,终止位置以及步长
print(str1[1:4]) # 从左到右切片,步长为正
print(str1[4:1:-1]) # 从右往左切片,步长为负
5 查找操作
5.1 len()函数
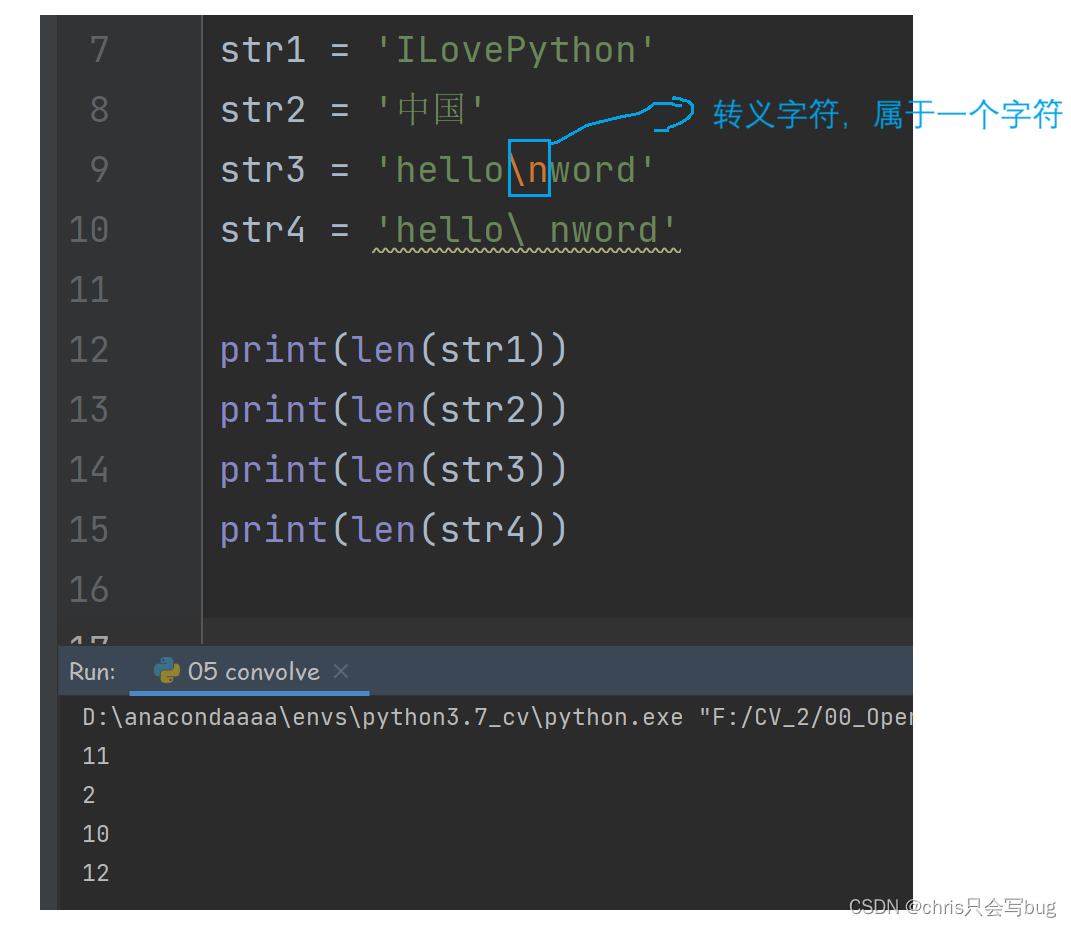
str1 = 'ILovePython'
str2 = '中国'
str3 = 'hello\nword'
str4 = 'hello\ nword'
print(len(str1))
print(len(str2))
print(len(str3))
print(len(str4))
5.2 find()方法
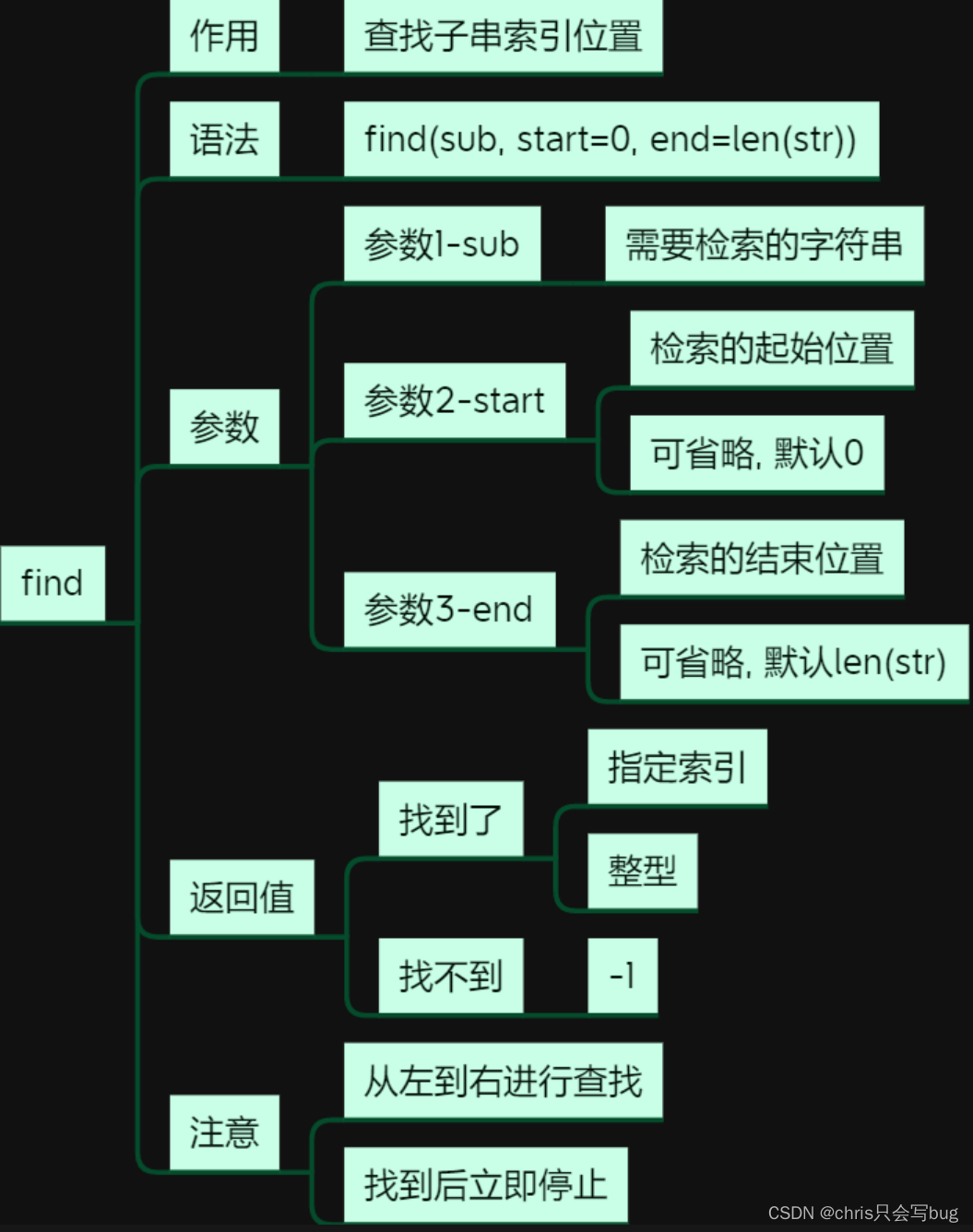
str1 = 'ILovePython'
# 查找子串的索引位置,从左边往右边开始查找
print(str1.find('Py'))
# 可以指定检索起始位置和检索结束位置
# 起始位置可以取,结束位置取不到,是一个半开区间
print(str1.find('Py', 2, len(str1)))

5.3 index()方法
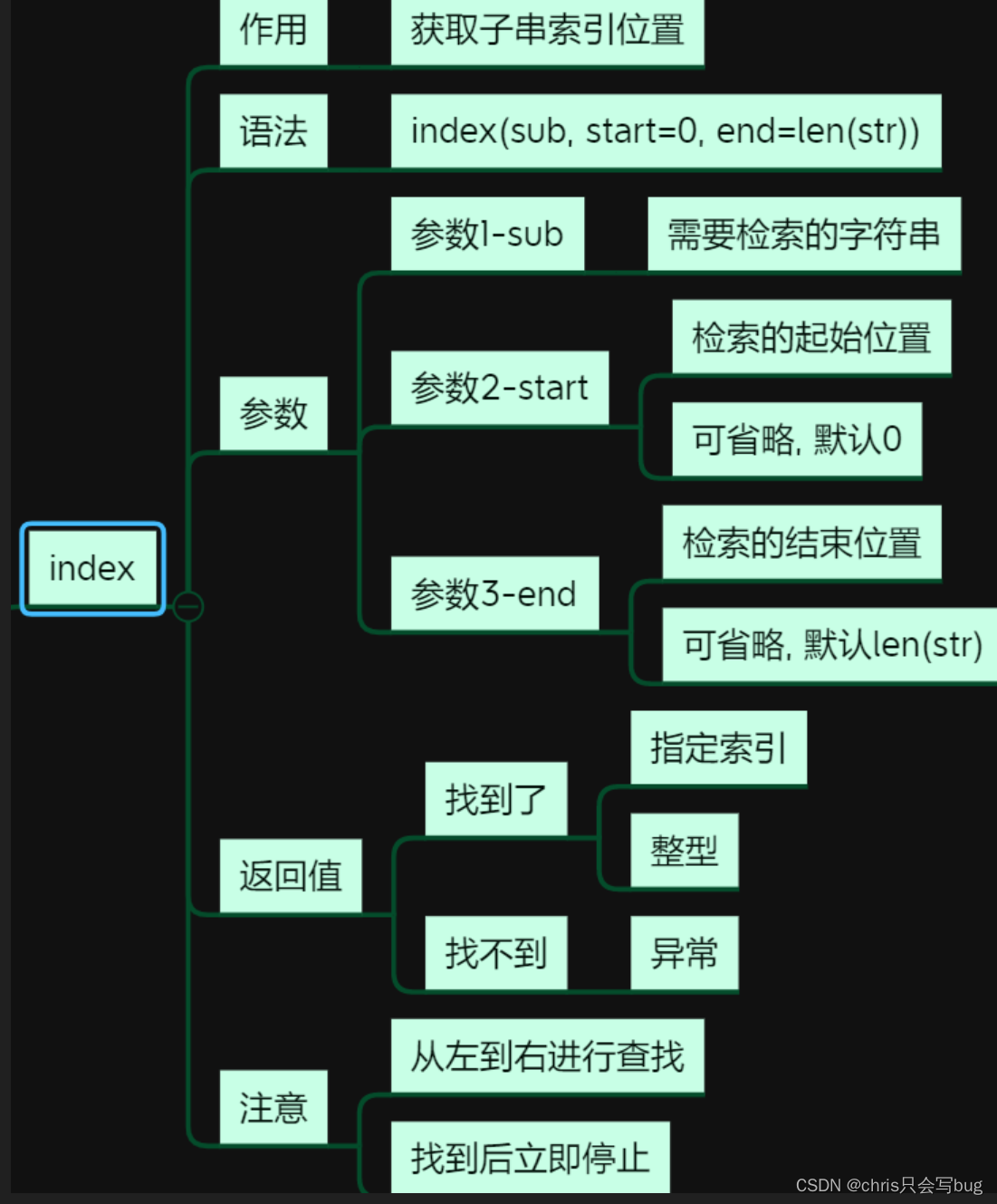
使用方式和index一样,但是当子串没有查询到的时候就不一样
对比index()和find()
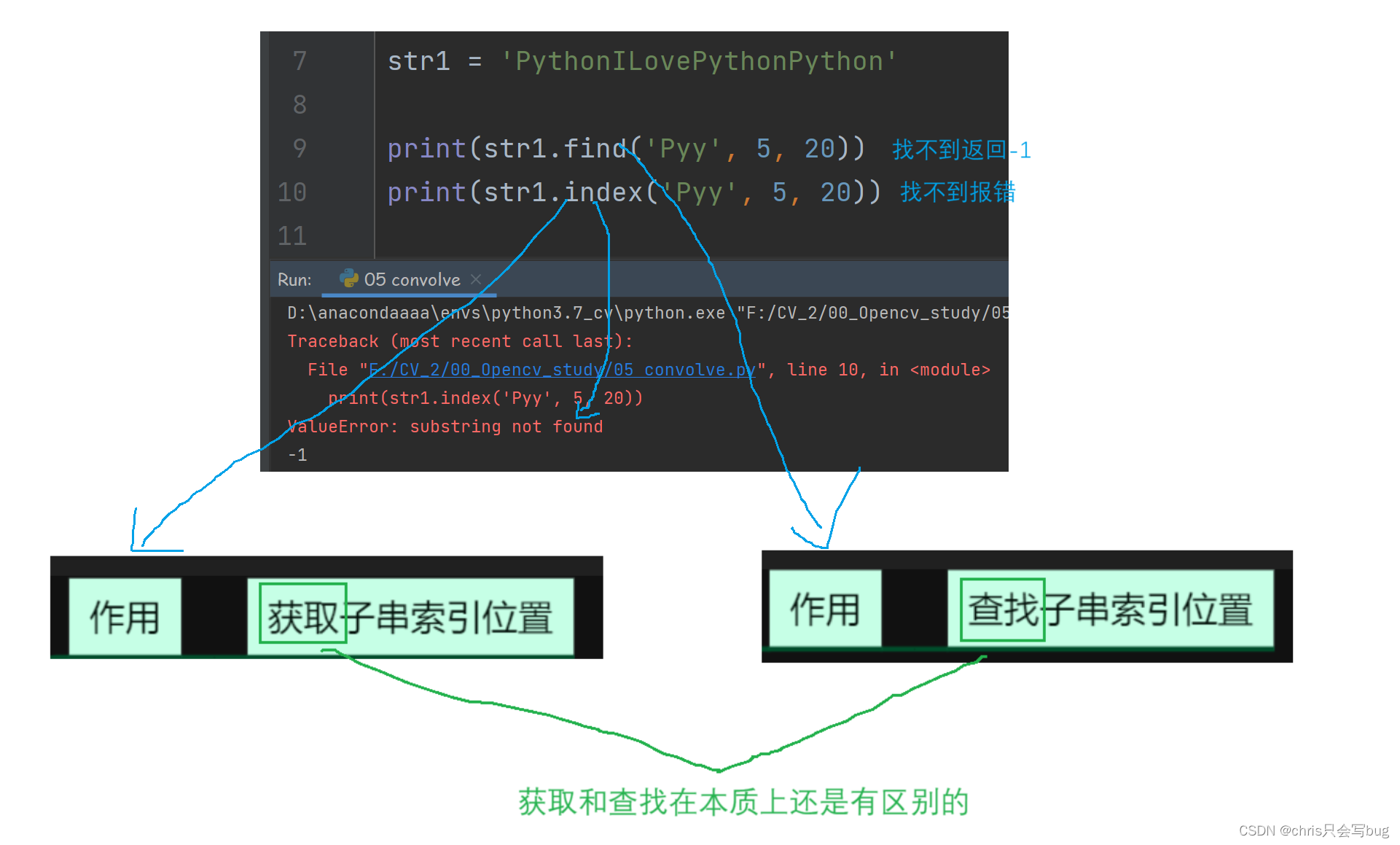

5.4 count()方法
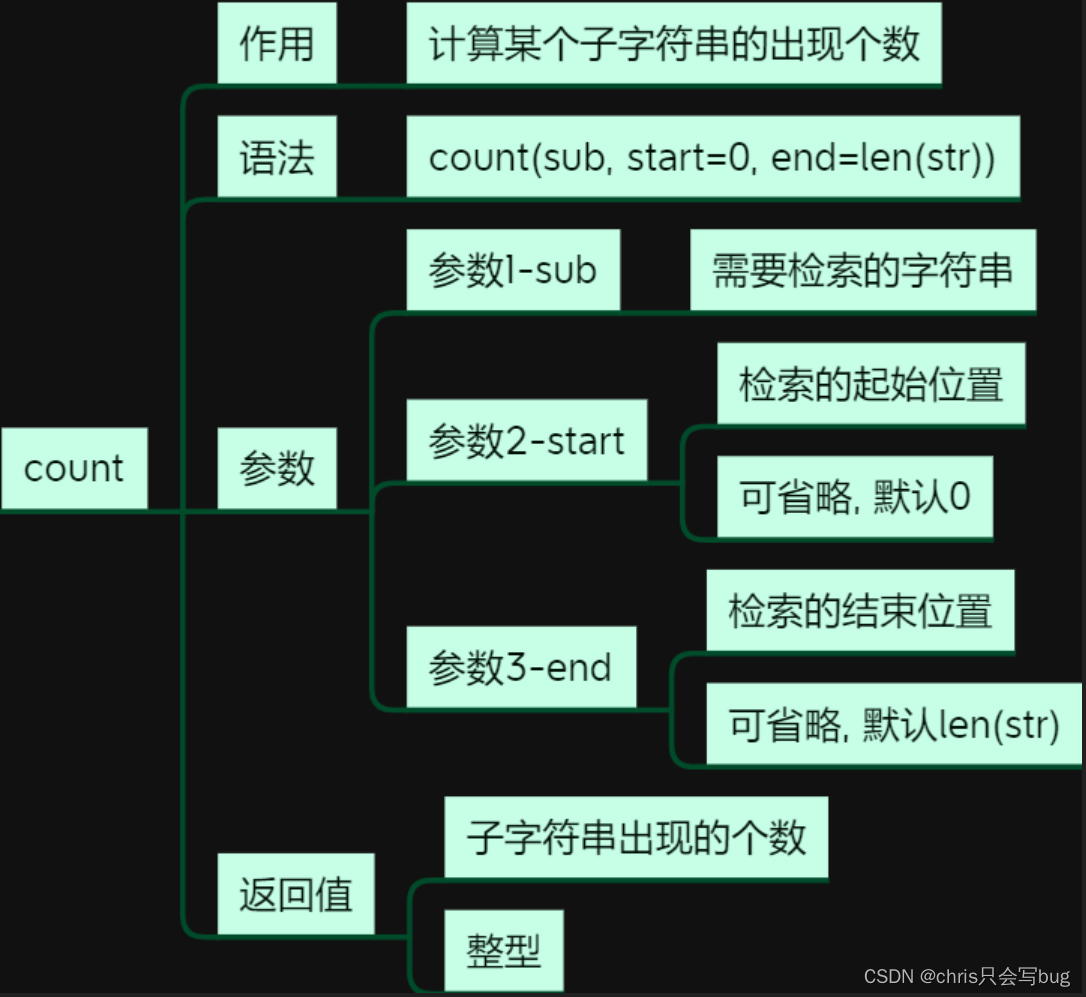
str1 = 'PythonILovePythonPython'
print(str1.count('Py'))
6 转换
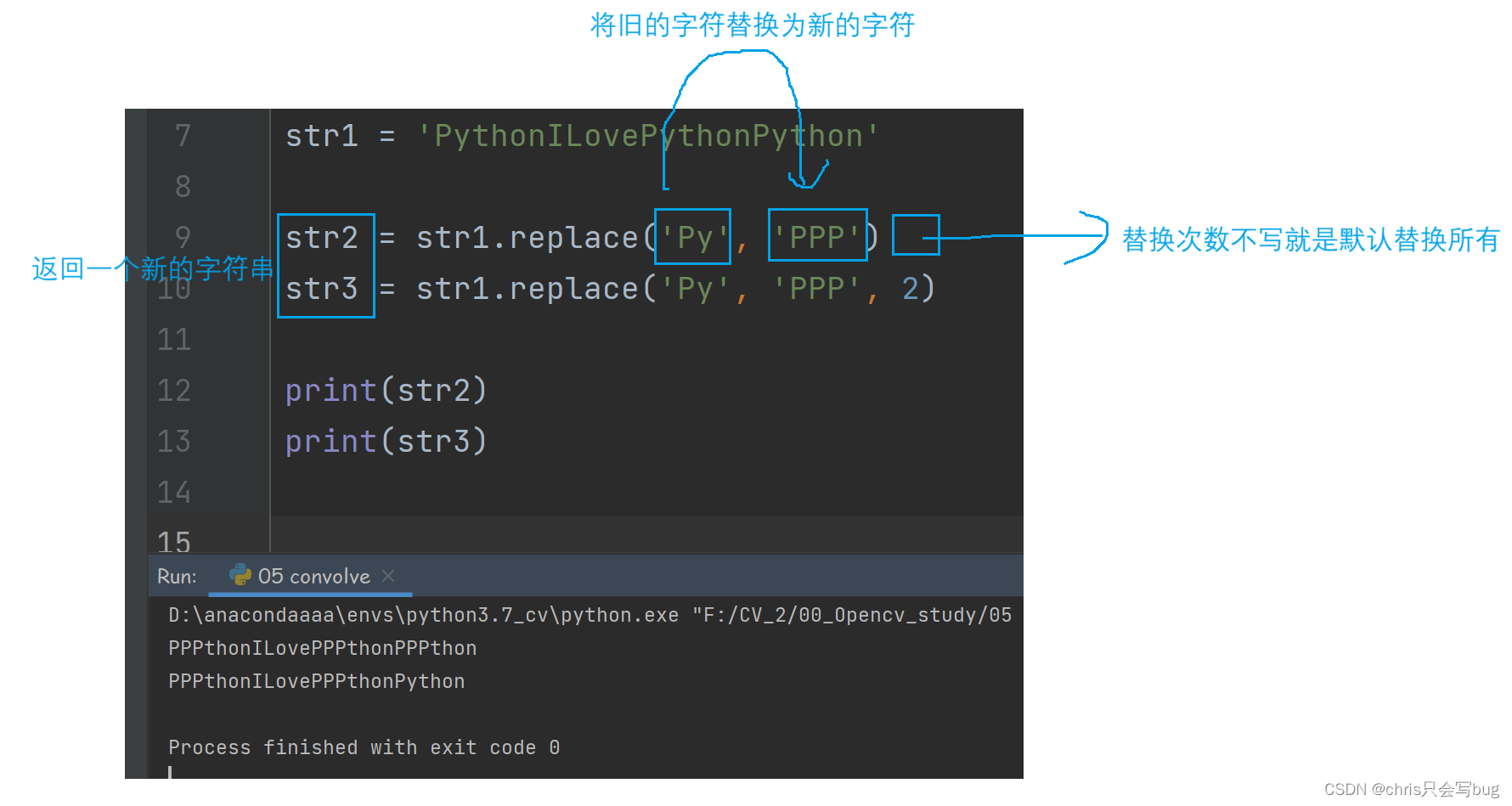
6.1 replace()方法

str1 = 'PythonILovePythonPython'
str2 = str1.replace('Py', 'PPP')
str3 = str1.replace('Py', 'PPP', 2)
print(str2)
print(str3)
6.2 capitalize()方法
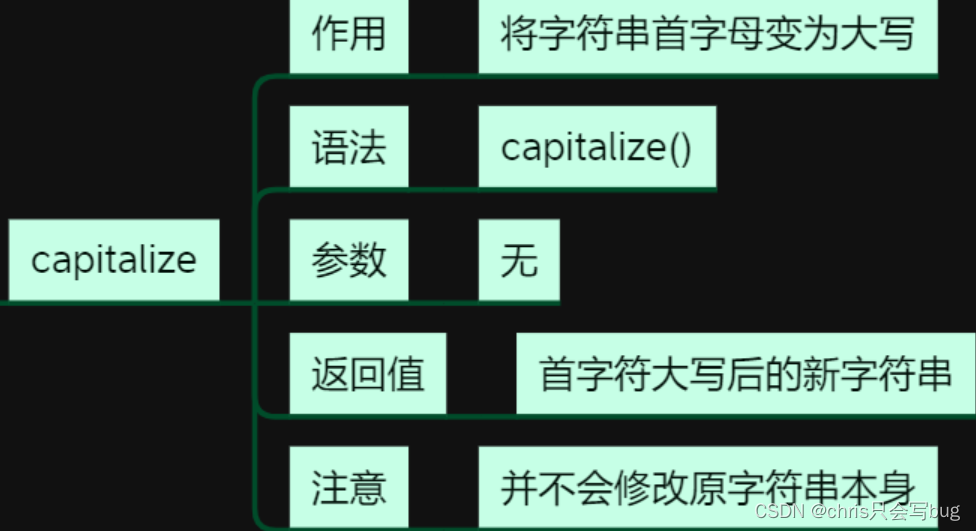
str1 = 'python I Love python python'
print(str1.capitalize())
6.3 title()方法
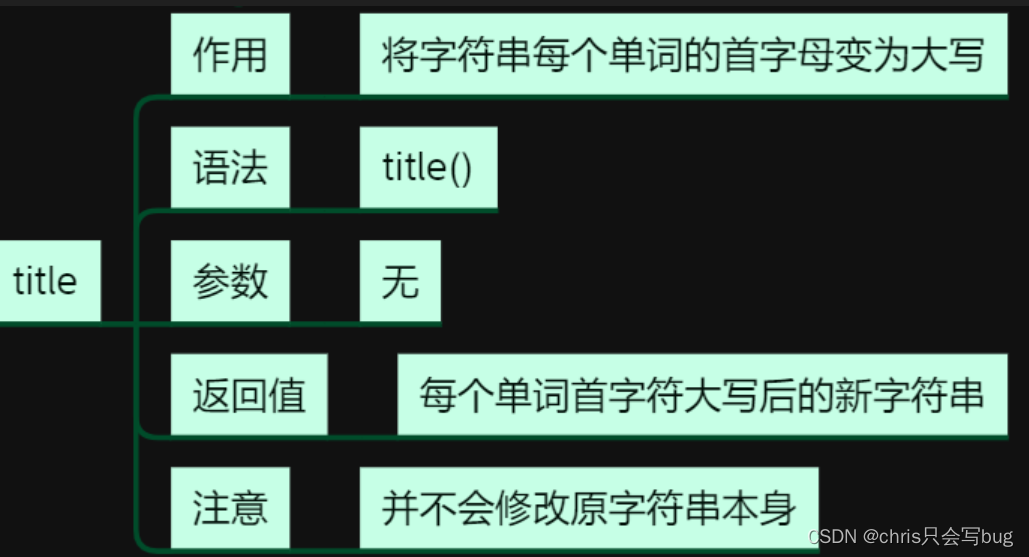
str1 = 'python I Love python python'
print(str1.capitalize())
print(str1.title())
capitalize()和title()区别

6.4 low()方法

str1 = 'python I Love pyTHON python'
print(str1.lower())
6.5 upper()
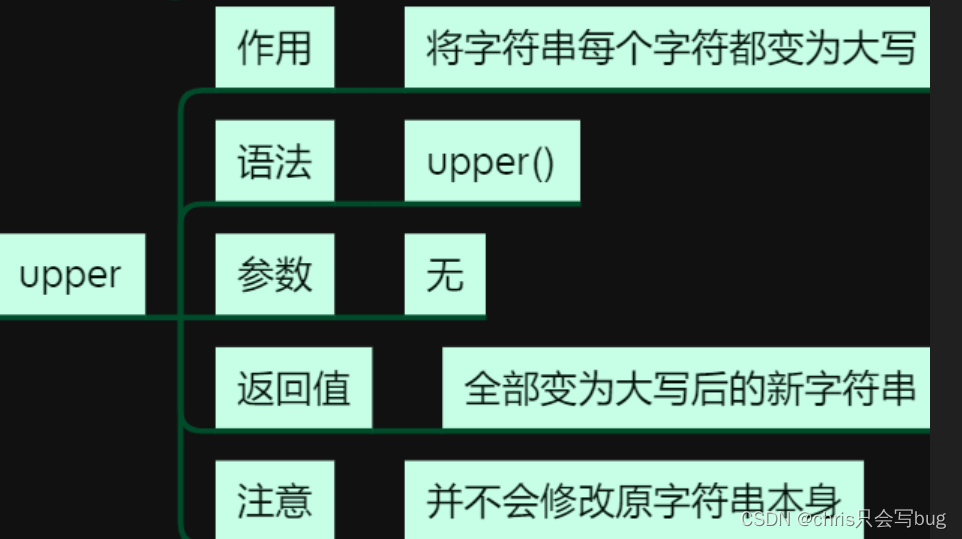
str1 = 'python I Love pyTHON python'
print(str1.upper())
7 填充压缩
7.1 ljust()方法
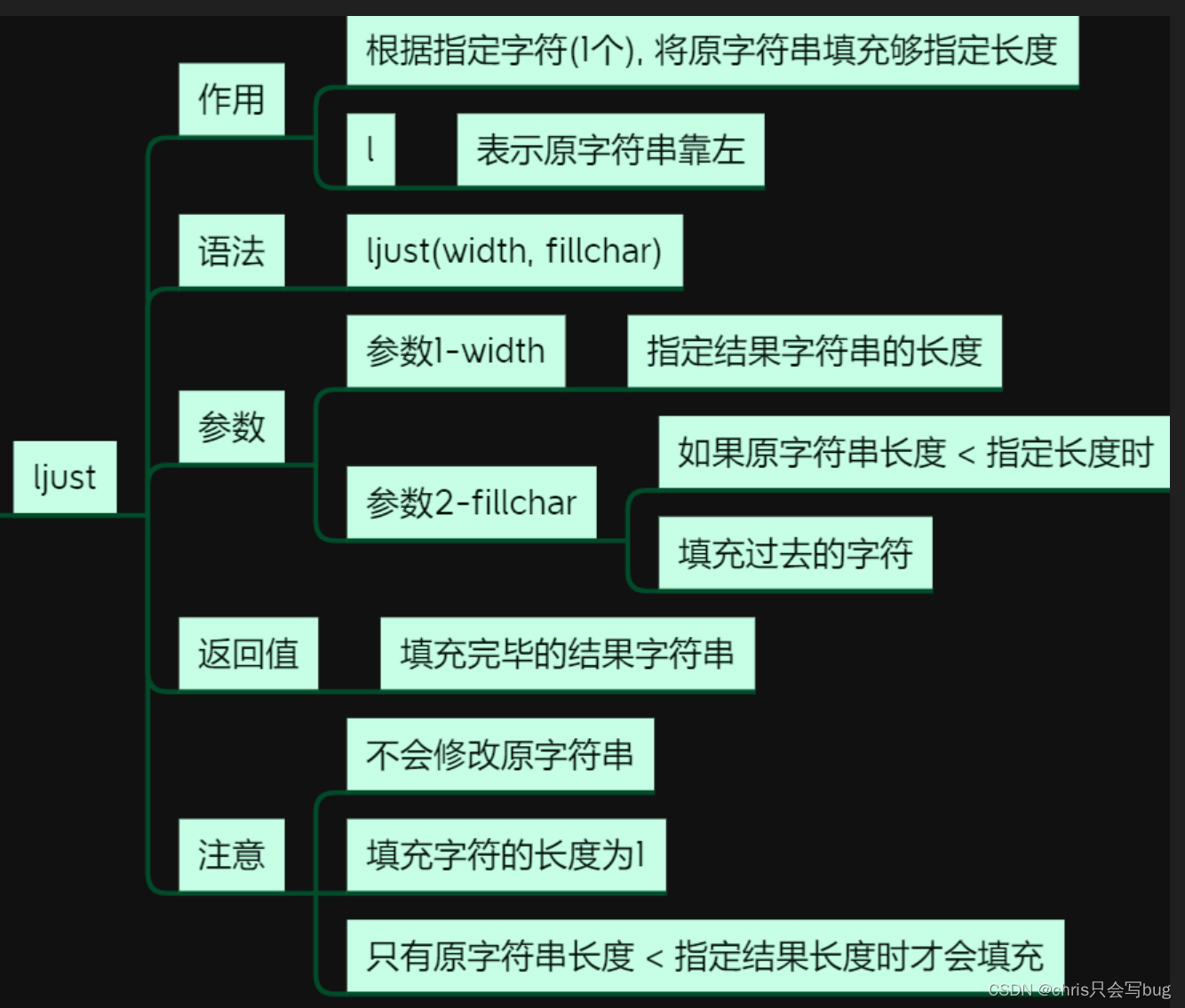
str1 = 'python'
# 指定结果字符串长度,指定填充字符(注意是单个字符)
print(str1.ljust(10, 's'))
# 如果指定结果字符串长度小于原始字符串长度,则不会发生填充,返回原字符串
print(str1.ljust(5, 's'))
7.2 rjust()方法
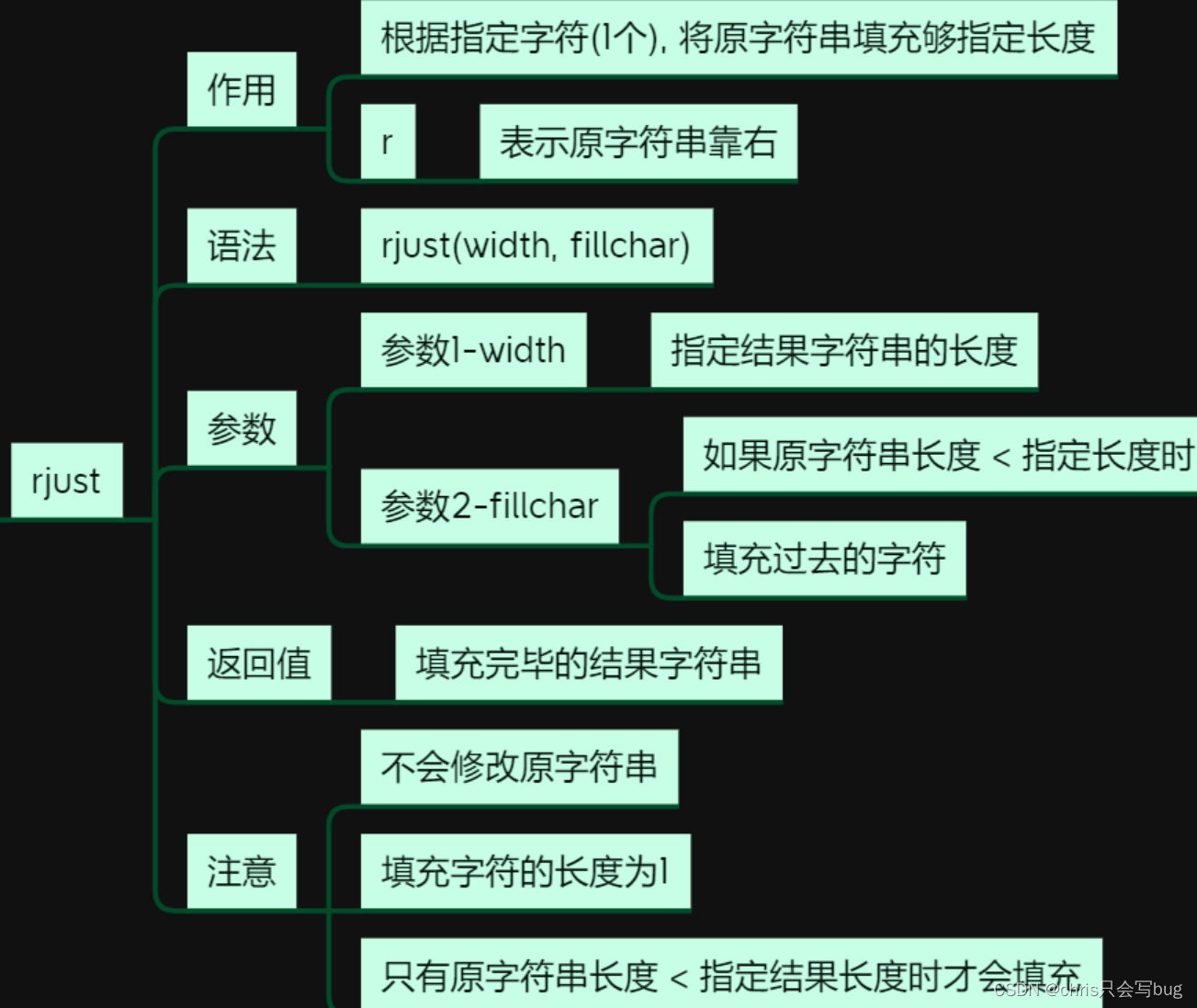
原理和ljust()方法一样,不过这是原字符串靠右
7.3 center()方法
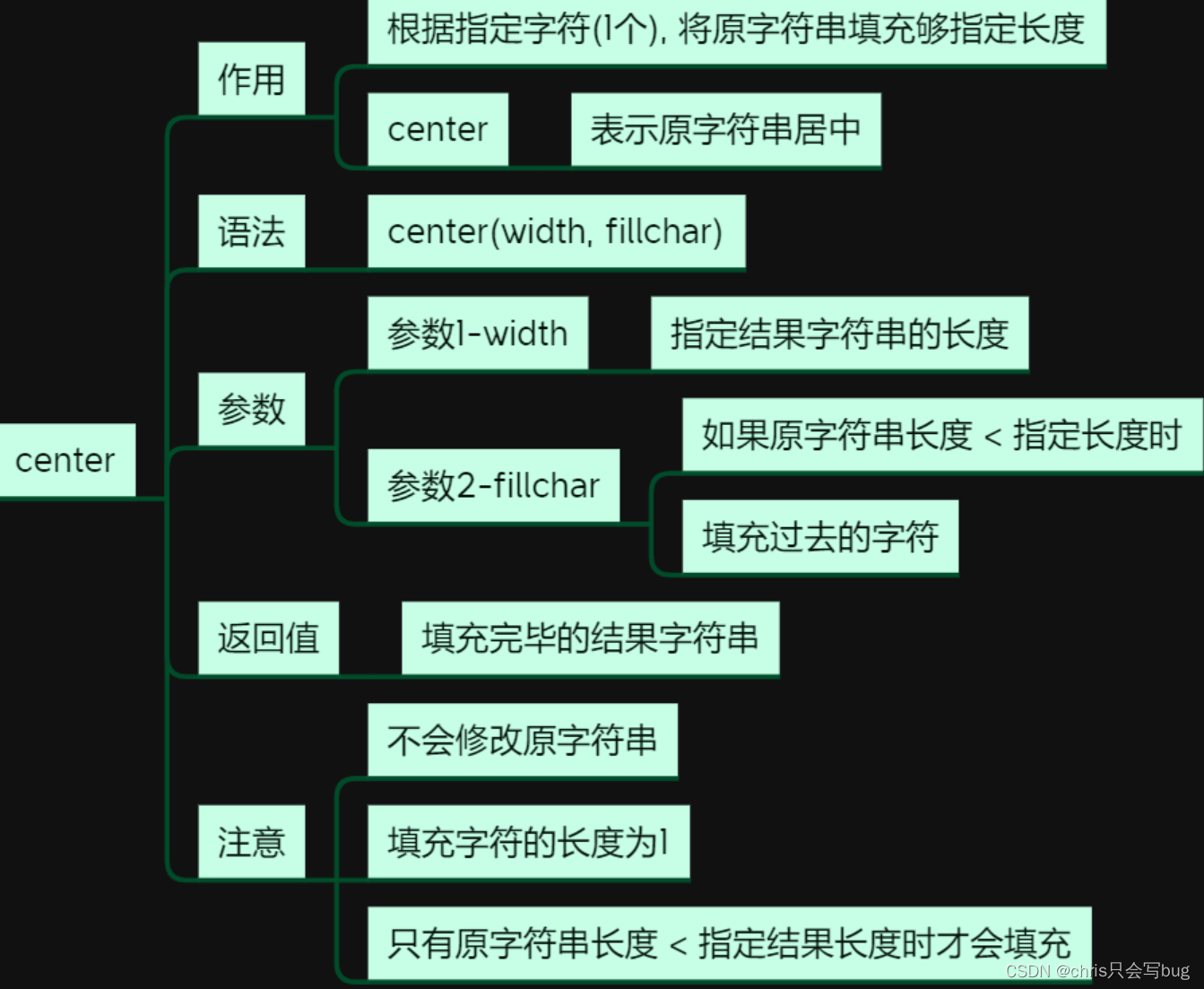
str1 = 'python'
# 指定字符串长度,指定填充字符
print(str1.center(20, 's'))
7.4 lstrip()方法
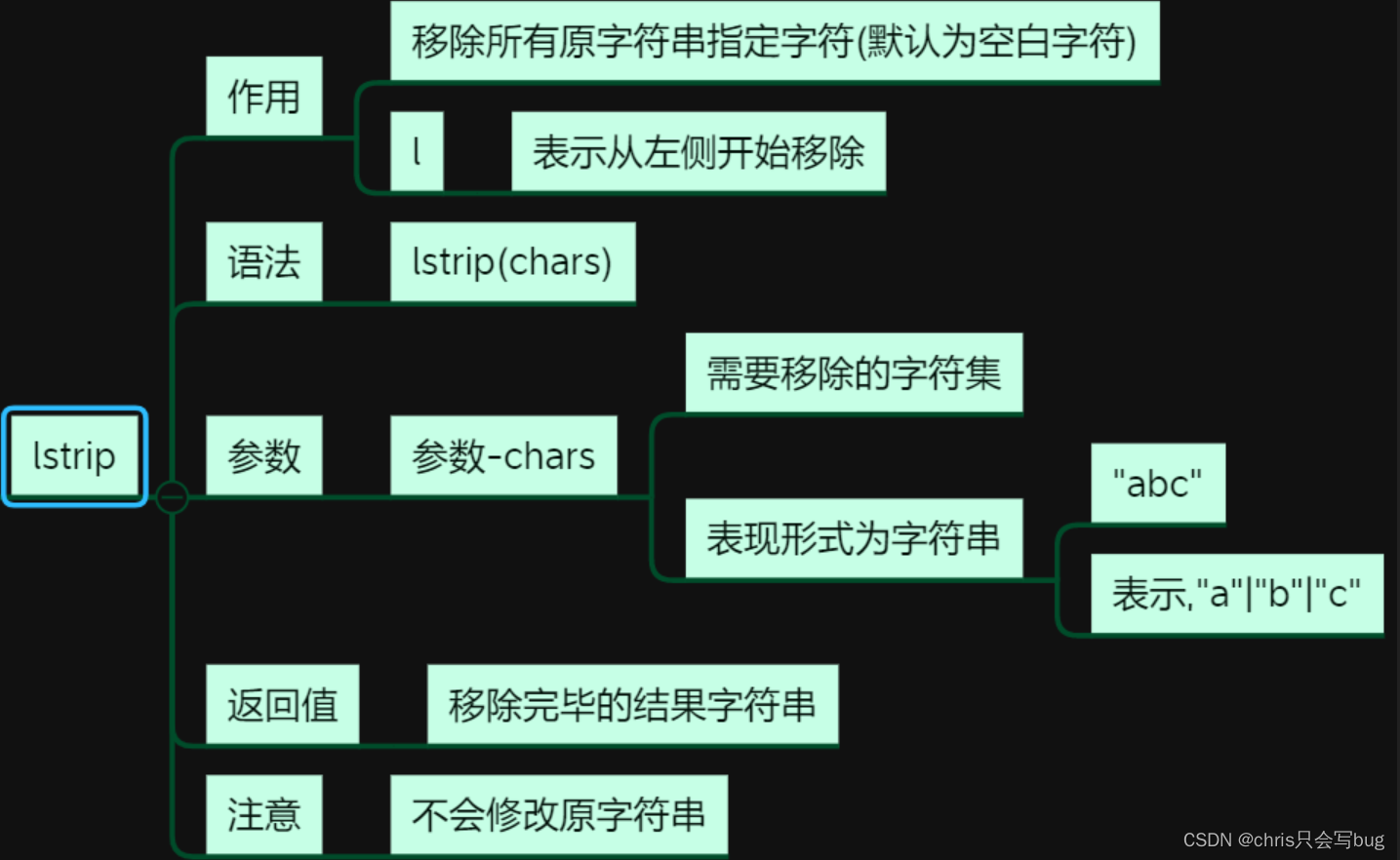
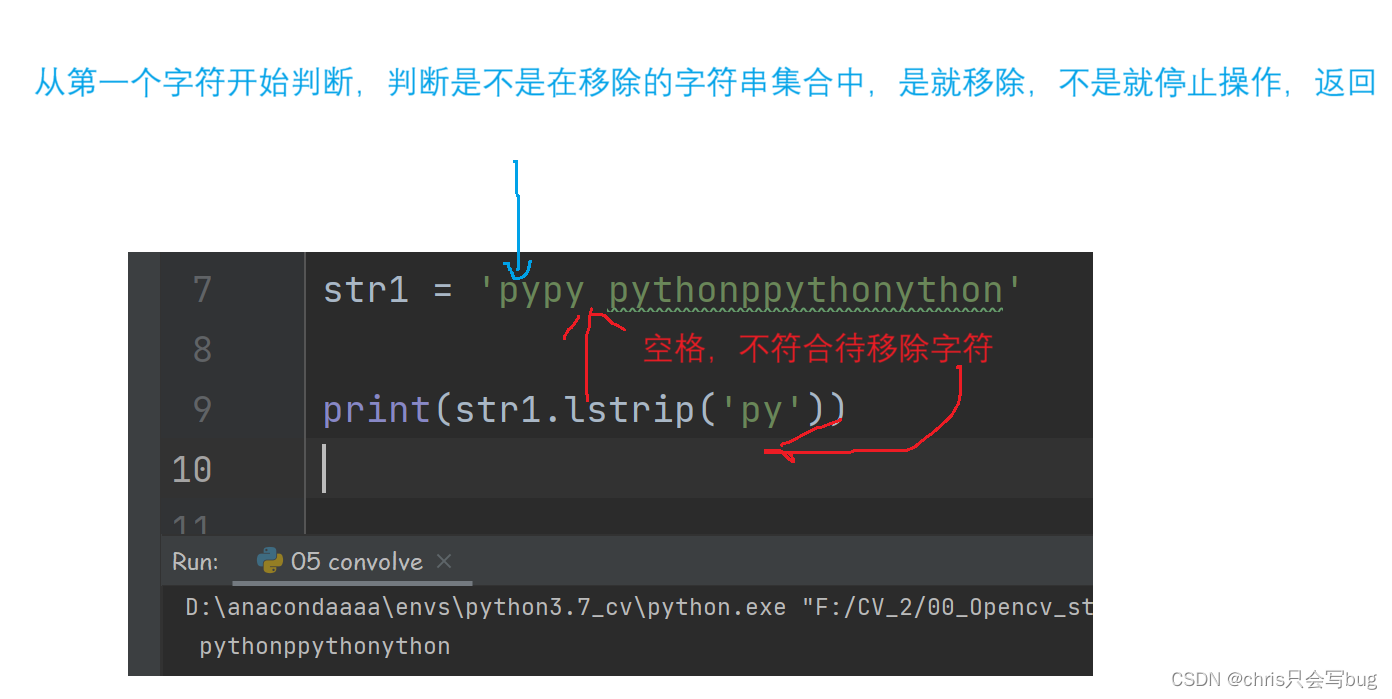
str1 = 'pypy pythonppythonython'
print(str1.lstrip('py'))
7.5 rstrip()方法
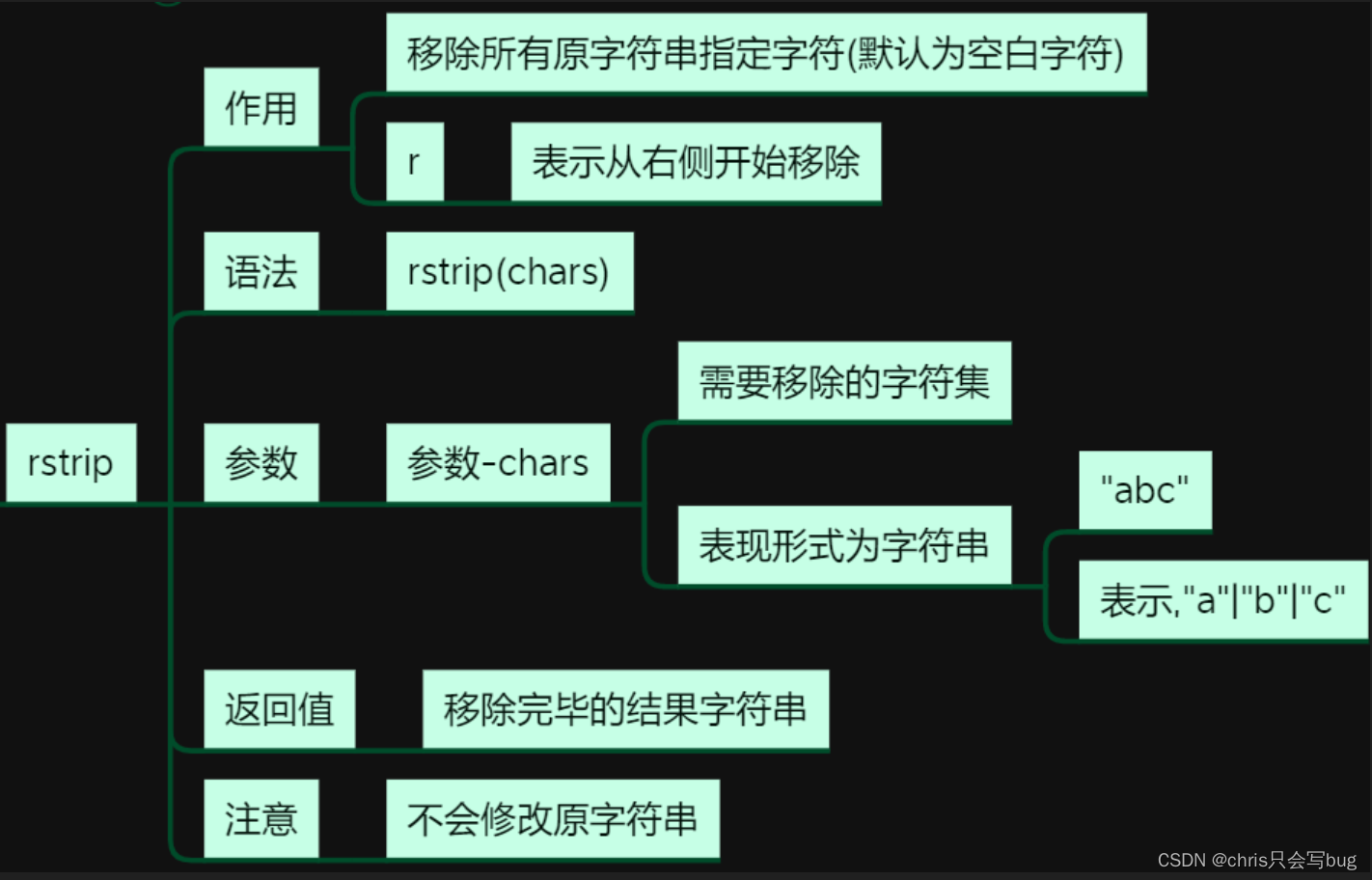
从右侧开始移除
具体使用参考lstrip()
8 分割拼接
8.1 split()方法
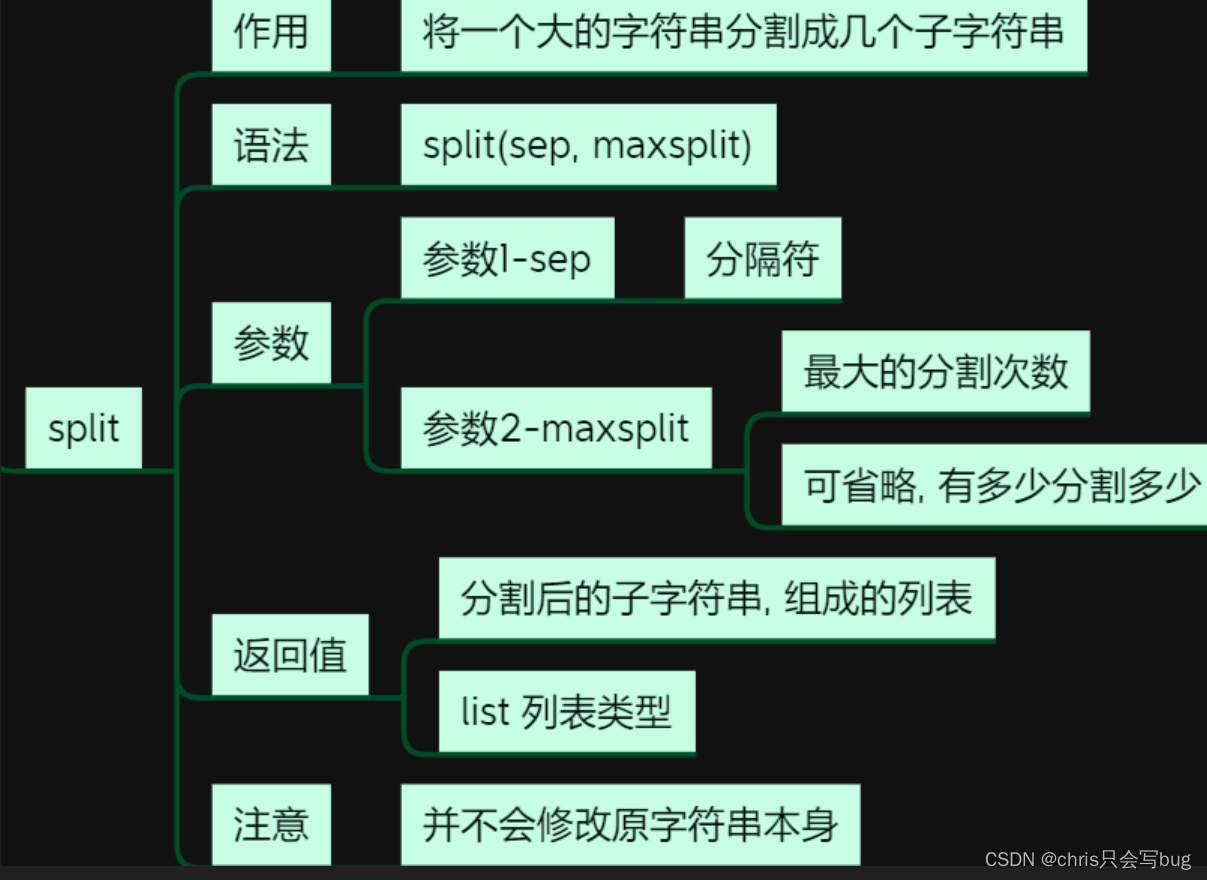
str1 = 'python_python_python_python_python'
# 第一个参数为依据什么进行分割,第二个参数为最大分割次数(可以省略,默认全部分割)
# 返回的是一个分割之后的列表
print(str1.split('_'))
print(str1.split('_', 2))

8.2 partition()方法

str1 = 'python_python_python_python_python'
# 指定分隔符,返回一个含有三个元素的元组
# 分隔符左侧内容 分隔符 分隔符右侧内容
print(str1.partition('_'))
# 如果没有找到分隔符就会返回一个元组,该元组为默认形式
print(str1.partition('!'))
8.3 rpartition()方法

用法参考partition()方法
8.4 splitlines()方法

str1 = 'python\npython\tpython\tpython\npython'
print(str1.splitlines())
print(str1.splitlines(keepends=True))
8.5 join()方法


str1 = 'python'
print(str1.join('hello'))
# 注意:这里的元组、列表以及其他可迭代对象中必须是字符类型数据
tup1 = ('1', '2', '3')
print(str1.join(tup1))
9 判定
9.1 isalpha()方法
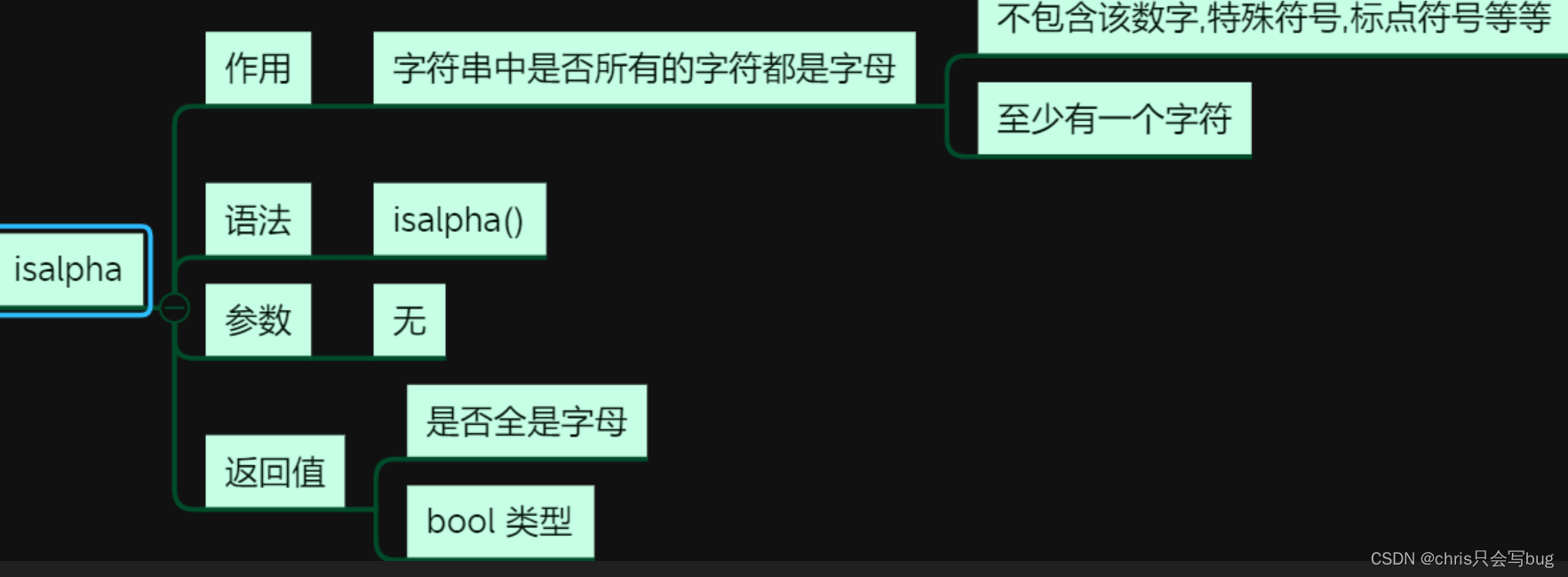
str1 = 'python'
print(str1.isalpha())
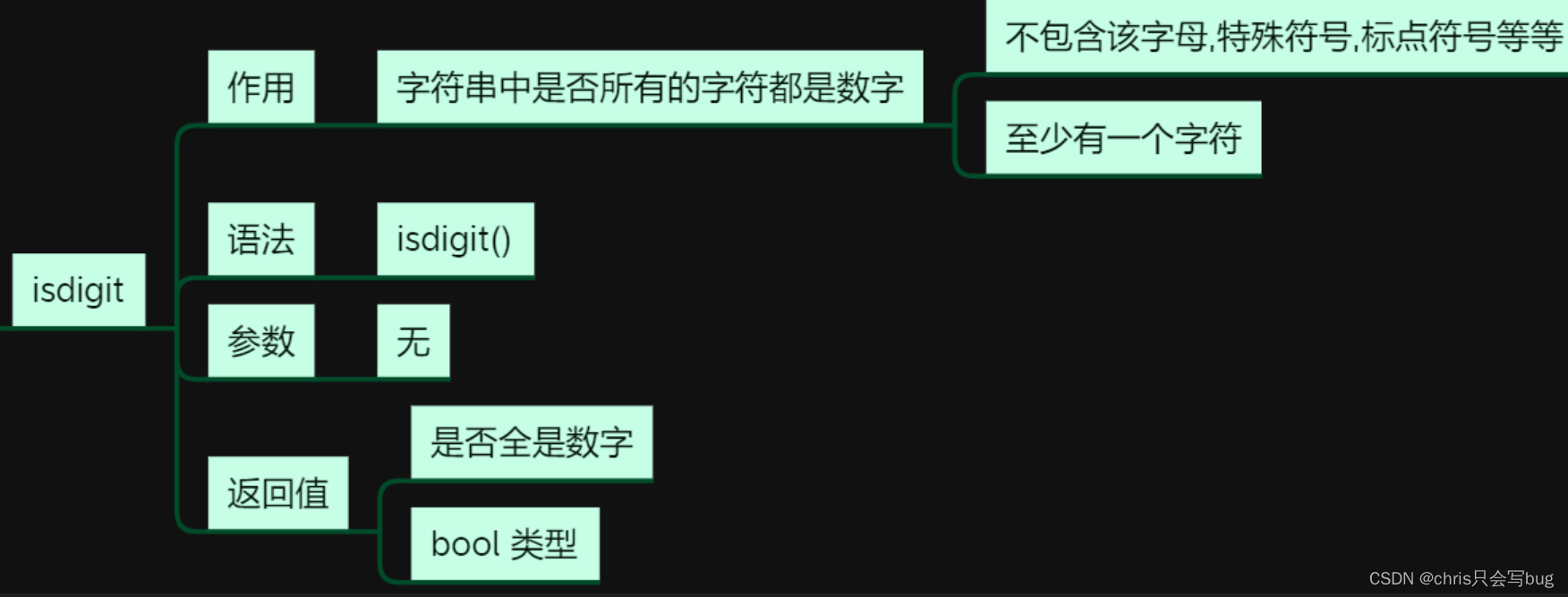
9.2 isdigit()方法
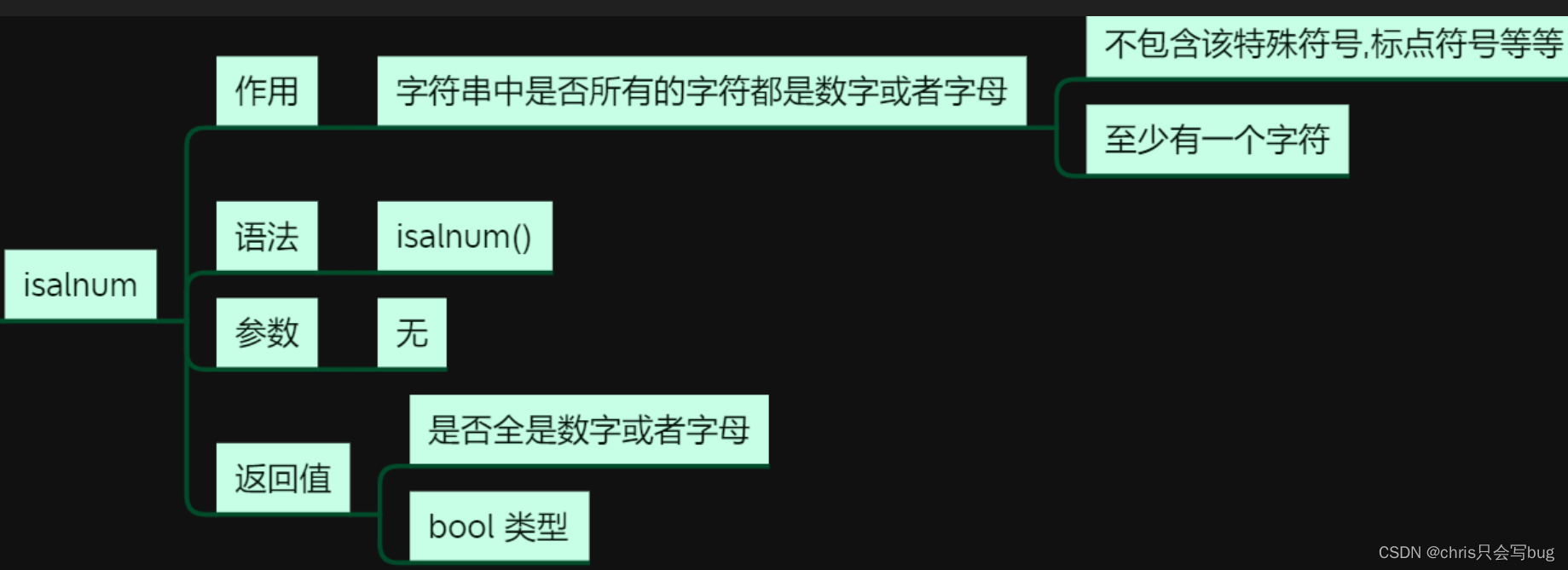
9.3 isalnum()方法
9.4 isspace()方法

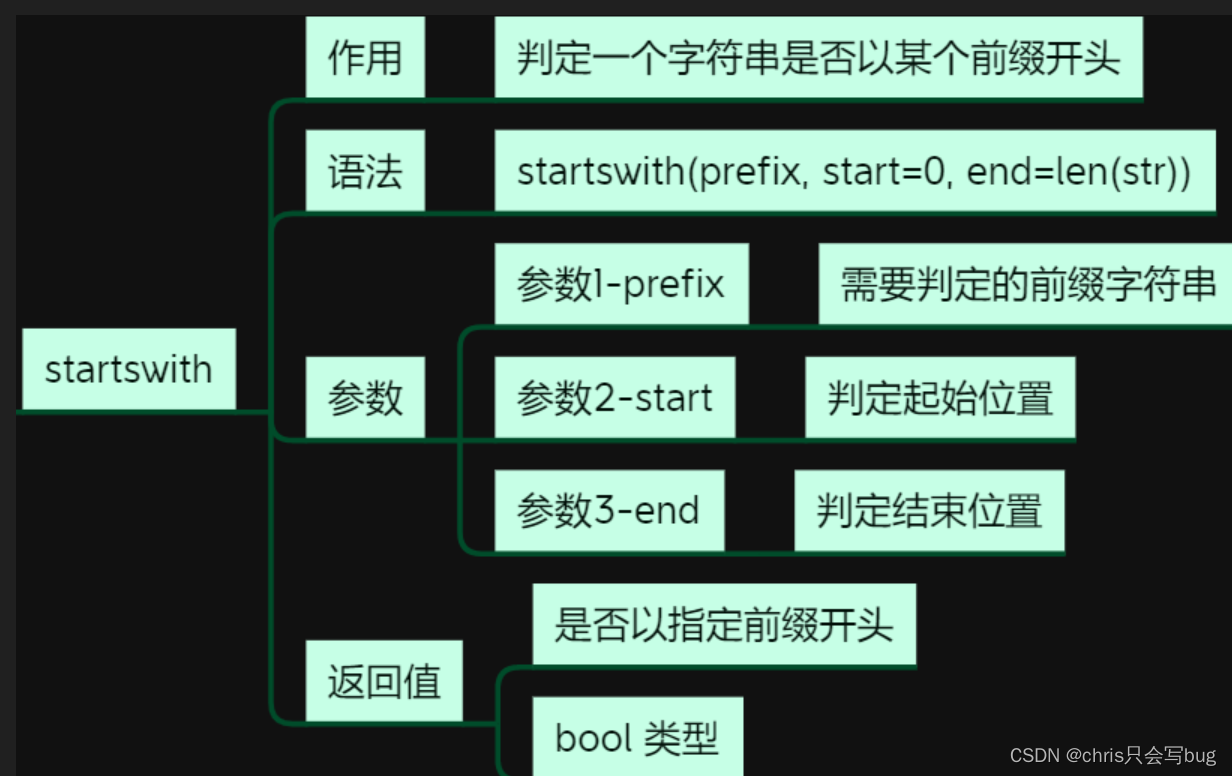
9.5 startwith()方法
9.6 endswith()方法
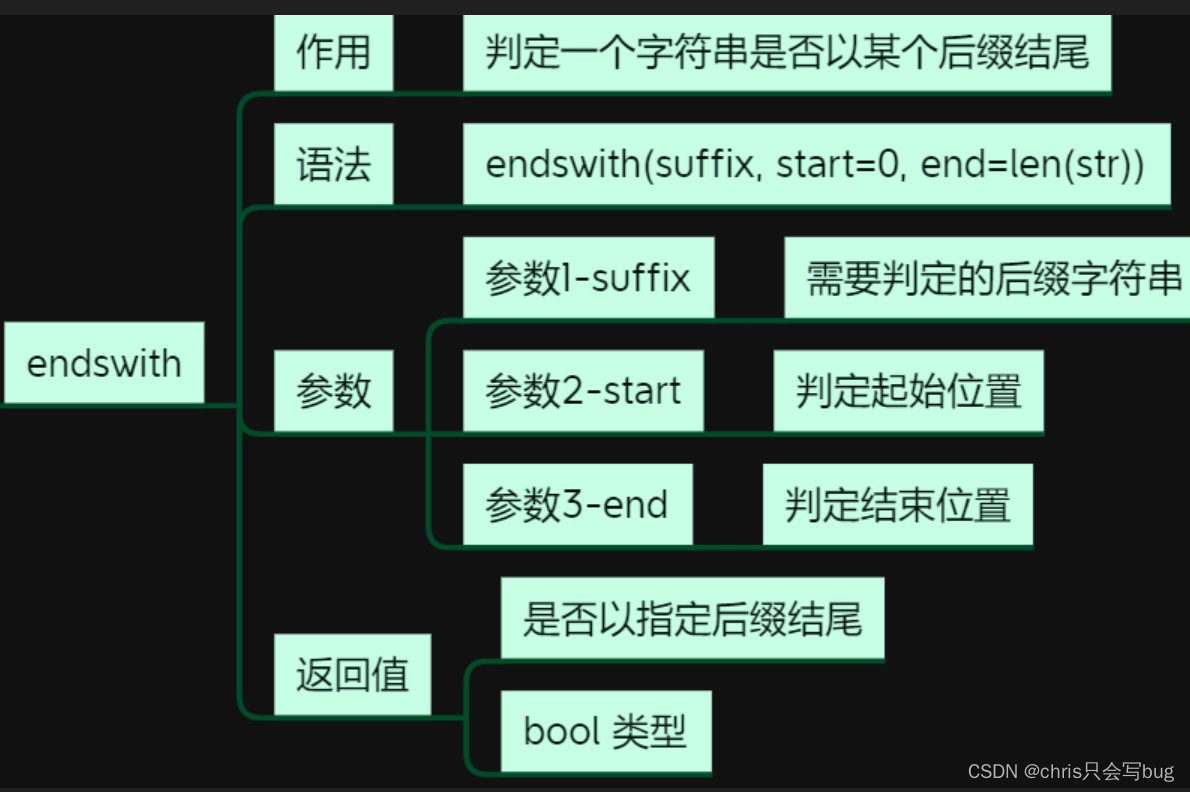
这个方法比较有用,因为我们在读取一个文件的时候,可以判断这个文件是否以某个文件后缀结尾
str1 = 'python.doc'
print(str1.endswith('doc'))
9.7 in/not in

😁😁😁觉得对自己有帮助的小伙伴可以👍关注💡收藏💖😁😁😁
👉👉👉有误的地方也可以在评论区讨论哦👈👈👈
希望本文能够对大家有帮助~!
往期推荐
🚀🚀🚀全网最全Python系列教程(非常详细)—数值篇讲解(学Python入门必收藏)🚀🚀🚀