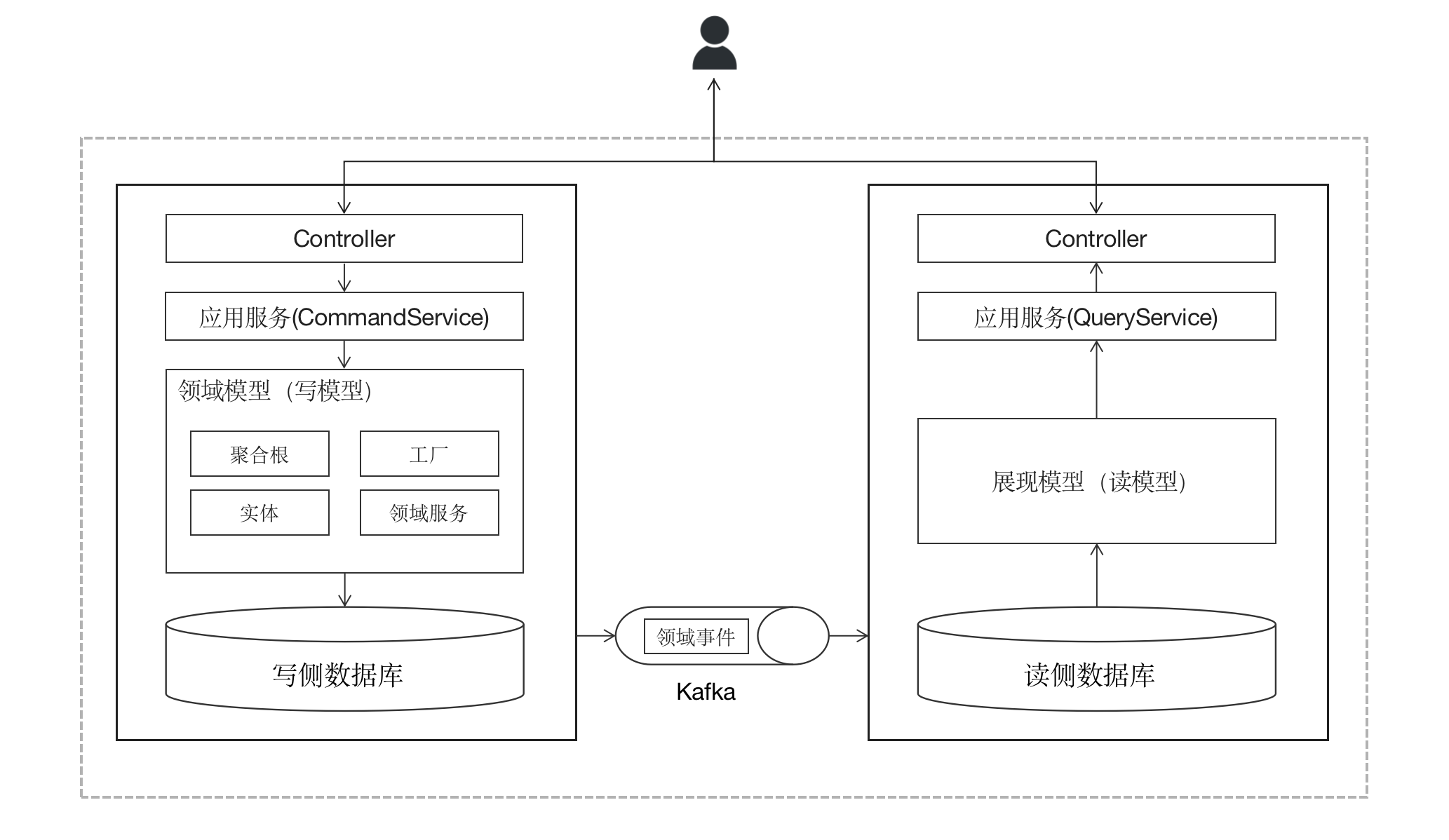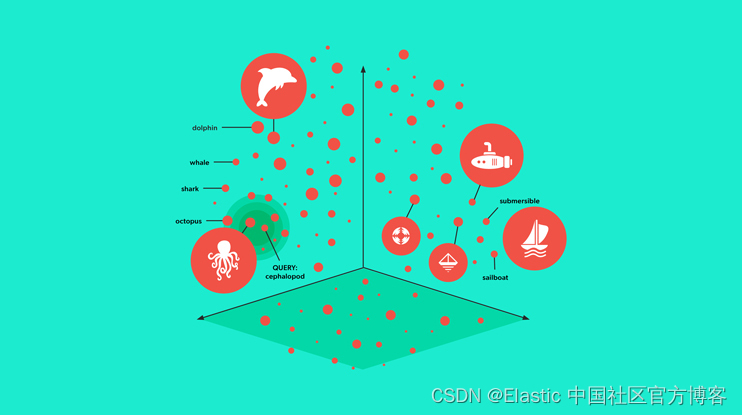
将非结构化数据表示为嵌入向量以及使用向量搜索进行基于嵌入的检索 (embedding-based retrieval - EBR) 比以往任何时候都更加流行。 嵌入到底是什么? Roy Keyes 在《嵌入的最短定义?》中对此进行了很好的解释。
嵌入是学习的转换,使数据更有用 - Embeddings are learned transformations to make data more useful
在学术界,这个过程被称为表征学习 (representation learning),几十年来一直是一个研究领域。 通过将数据转换为向量(计算机原生语言),我们可以使数据更有用。 以文本 BERT 为例。 Transformers 的双向编码器表示 (bidirectional encoder represenations from transformers - BERT)。
这种表示的有用程度取决于我们如何学习这种转换以及学习到的表示数据的方法如何推广到新数据。 这就是我们进行机器学习的方式。 获取一些数据,从中学习一些东西,然后将所学到的知识应用到新数据中。
那么什么是新的呢? 为什么会产生兴趣? 答案是更好的模型架构(例如 Transformer 架构)和自监督表示学习。 再加上一些围绕大型语言模型 (LLMs)(例如 chatGPT)的混乱,
关于自我监督学习。 使用巧妙的目标,我们可以使用大量数据训练模型,而无需人工监督(标记)。 然后,一旦完成,我们就可以针对任务微调模型,其中微调所需的标记数据比从头开始要少。
这种类型的学习管道称为迁移学习。 学习滑雪板也可以转移到滑板、风帆冲浪、冲浪和其他有趣的活动。
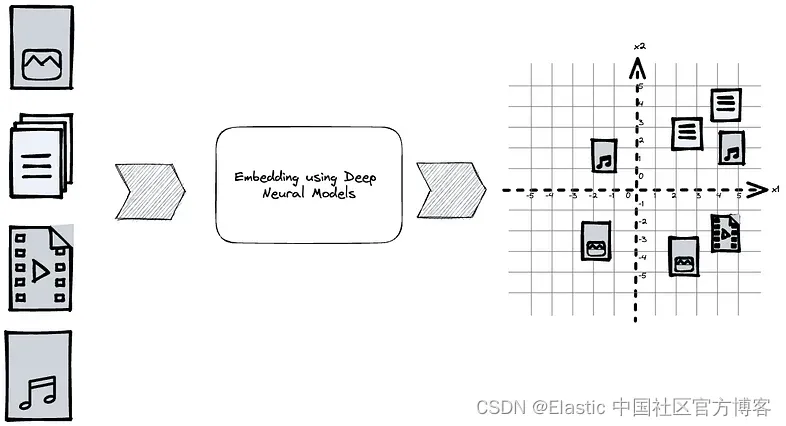
为了缩短这篇博文,让我们专门关注文本模型和 BERT 模型。 我们如何使用基于 Transformer 的模型将数据转换为有用的嵌入表示?

BERT 是一种深度神经网络模型,具有权重、层等,我们将其复杂性隐藏在盒子内。 如果我们从 Huggingface 中提取模型,则模型权重是通过使用掩码语言模型目标进行预训练来分配的。
我们可以获取一些文本并将该文本标记为固定词汇表以获得一组数字 ID。 自由文本和硬编码标识符之间的映射。 词汇量大小取决于语言,但对于英语的普通 BERT 模型来说,约为 30K 单词。 未知单词(词汇表之外)被分配 UNK 并给予专门保留的标识符。 所有未知单词都分配给此标识符,并且如果 “foo” 和 “bar” 都不在词汇表中,则模型无法区分 “foo” 和 “bar”。
BERT 模型最多可以取 512 个单词(输入上下文长度限制),网络输出是 512 个维度为 N 的向量,具体取决于 bert-base 模型的类型。 普通 BERT 模型使用 768 个维度。 对于 512 个单词的输入,我们获得一个 512 x 768 浮点数的矩阵,每个输入单词一个 768 维向量。 与之前的 NLP 模型架构(如 Word2vec)不同,输出上的每个词向量表示都通过 Transformer 架构中的注意力 (attention) 机制进行上下文化。 单个单词的向量表示取决于输入中的所有其他单词。
现在,我们有多个向量代表单个文本; 如果我们想用单个向量表示来表示一段 (a chunk) 文本、一段文本段落 (a paragraph) 或一个文本(a text),我们该怎么办? 一种方法是选择单个输出向量作为表示并忽略其余向量。 另一种方法是池化。 例如,平均池化会将 512 个输出向量平均为单个向量表示。


现在我们有了文本块 (chunk) 的嵌入表示,这会导致错误 1。
错误#1:使用预先训练的模型而没有针对特定任务进行微调

使用仅经过预训练的模型的直接向量表示不会为任何任务产生有用的嵌入表示。 搜索排名就是此类任务的一个例子; 详细信息请参阅如何不使用 BERT 进行搜索排名。
对自由文本查询和文档进行编码并期望两种表示形式之间的余弦相似度可以按相关性对文档进行排名是天真的,并且该方法的结果为你提供了随机排名结果。 你学到的滑雪板技能不会转移到打高尔夫球或游泳上。
错误 #2 使用域外 (out-of-domain) 微调的单向量嵌入模型
为了获得用于搜索排名的有用嵌入表示(优于随机),我们需要调整模型权重。 我们可以通过在训练模型时使用不同的目标来做到这一点。 我们可以使用带标签的示例进行训练(更新权重),例如针对大量查询样本的相关和不相关文档。 MS MARCO 是一个大型网络搜索相关性集合,具有带标签的查询和文档对,可用于训练排名模型。
这种微调创建了基于 BERT 的有用嵌入表示,并在 MS MARCO 数据集上大幅超越了没有可学习参数的传统关键字搜索方法(例如 BM25)。
问题是,当我们采用在 MS MARCO 标签上进行微调的单个向量表示模型时,它无法在文档和问题类型略有不同的不同领域中击败 BM25。
BEIR 基准是一个优秀的框架,用于评估在 MS Marco 上训练的模型的质量以及它们转移到不同领域和任务的情况。
通过使用十种不同检索模型来验证有效性,它证明了域内性能无法预测方法在零样本设置中的泛化程度。 许多方法 (9中方法) 在 MS MARCO 的域内评估中表现优于 BM25,但在 BEIR 数据集上表现不佳。
错误 3:缺乏对向量搜索权衡的理解
所以你在这里做到了并拥有有用的数据嵌入表示。 现在,你需要一种使用最近邻搜索 (nearest neighbor search),也称为 KNN,来搜索矢量数据的方法,并且你可以将令人兴奋的用例部署到生产中。
你应该问自己的第一件事是,我们是否需要引入近似最近邻搜索(approximate nearest neighbor search - ANNS)而不是精确最近邻搜索 (KNN)? 与生活的许多方面一样,这是一个权衡的问题。
在查询服务端。 即使不考虑文档端处理的复杂性,例如 CRUD 的需求、实时与批处理等。
- 延迟服务级别协议 (SLA) — 我们需要多快? 0.001ms、1ms、10ms、100ms、一秒? 也许3秒就可以了?
- 吞吐量——我们对查询吞吐量的期望是多少?我们可以预期的最大值是多少? 1 QPS,也许是 1M QPS,甚至是数十亿?
- 我们的用例可以容忍的准确性影响。 当我们引入近似搜索时,与穷举搜索相比,准确性会有所损失。 根据我们选择的算法,这可能会很大。 我们可以通过使用精确搜索运行查询、比较近似输出并计算两者之间的重叠来评估这种影响。 例如,使用 k=10,我们可以测量 overlap@10,或者 k=1,测量 overlap@1。
鉴于上述情况,这归结为生产部署成本; 我们需要多少台服务器,或者我们根本不需要服务器?
让我们详细讨论精度误差容限以及为什么它依赖于用例。 如果你正在构建包含超过十亿张照片矢量的图像搜索服务,则不一定需要完美的召回。 有许多同样出色的猫照片,并且查询模型认为最相关的最佳猫可能并不那么重要。
另一方面,如果你正在构建一个使用向量搜索来确定用户是否可以访问建筑物的视网膜图像扫描应用程序,那么你最好有很好的 overlap@1。 在 ANN 算法的学术研究中,这些极端、高召回率和低召回率设置之间存在明显的区别。
详尽的搜索可能就是你所需要的
对邻居的精确搜索将暴力计算查询与所有符合条件的文档之间的距离,返回的 k 个文档是真正的最近邻居。 搜索可以是并行的、多线程的,并且在许多情况下,可以使用优化的硬件指令; 向量是机器的语言。 如果我们将向量存储在具有查询引擎过滤功能的引擎中,则搜索也可以有效地限制在子集内。
例如,暴力搜索 128 维的 1M 向量,单线程大约需要 100ms。 我们可以并行化搜索; 例如,通过使用四个线程,我们可以将其降低到 25 毫秒,直到内存带宽达到要求。 如果我们从磁盘中随机分页向量数据,速度会更慢,但仍然可以并行化。 如果我们有 10B 个向量,并且我们没有办法有效地选择执行最近邻搜索的文档子集,那么我们就会遇到成本问题。 我们仍然可以通过将搜索并行分配到多个节点来获得不错的延迟,就像 Vespa 可以做到的那样。 但由于数十亿的嵌入,租用服务器来控制延迟可能会变得昂贵。 再加上高查询吞吐量,我们就遇到了真正的成本问题。
在最新的Elastic Stack 8.10 的发布中,Elasticsearch 开始引入了并行化 kNN 向量搜索开始。
引入近似值
沿着近似向量搜索路线,我们需要一种可以对向量数据建立索引的算法,以便以资源使用和索引处理为代价,使搜索比穷举搜索成本更低。 这里也有很多权衡,比如磁盘使用和内存使用。 该算法在实时 CRUD 操作中的使用效果如何。 ANN 算法理解的来源之一是 https://github.com/erikbern/ann-benchmarks,其中在各种向量数据集上比较了不同的算法和实现。

上图是 SIFT 数据集,有 1M 128 维向量。 该图显示了 recall@10(与 overlap@10相同)与每秒查询数的关系。 基准测试是单线程的,这意味着如果算法的 QPS 为 10²,则延迟为 10 毫秒。 10³ QPS 意味着 1ms 的延迟,依此类推。 这些算法非常快。
如果我们将这些算法部署在具有多个 CPU 核心的服务器上,我们可以获得更高的 QPS。 只要不存在任何争用或锁定扩展问题,2 个核心预计将提供 2 倍的 QPS。 但并不是所有的人工神经网络算法都能给我们同样好的回忆。 向上和向右的算法在性能和准确性之间提供了最佳权衡,而左下象限则更差。 如上所示,一些算法很难达到 50% 以上的召回率。
上图中没有体现的是索引的成本以及算法是否可以支持更新和 CRUD 操作。 有些是面向批处理的,因此它们首先需要大量文档向量样本才能构建索引,而另一些则可以增量构建索引。 请注意,ann-benchmark 只能使用开源算法在同一运行时上进行重现。 一些商业和专有向量搜索供应商在召回与性能之间进行了未知的权衡。
更多学习资源:
-
如何利用 Elastic 的向量数据库得到完美的词汇和 AI 驱动搜索
-
改进 Elastic Stack 中的信息检索:提高搜索相关性的步骤
-
改进 Elastic Stack 中的信息检索:对段落检索进行基准测试