文章目录
- 💯前言
- 💯问题描述与数学模型
- 1.1 题目概述
- 1.2 输入输出要求
- 1.3 数学建模
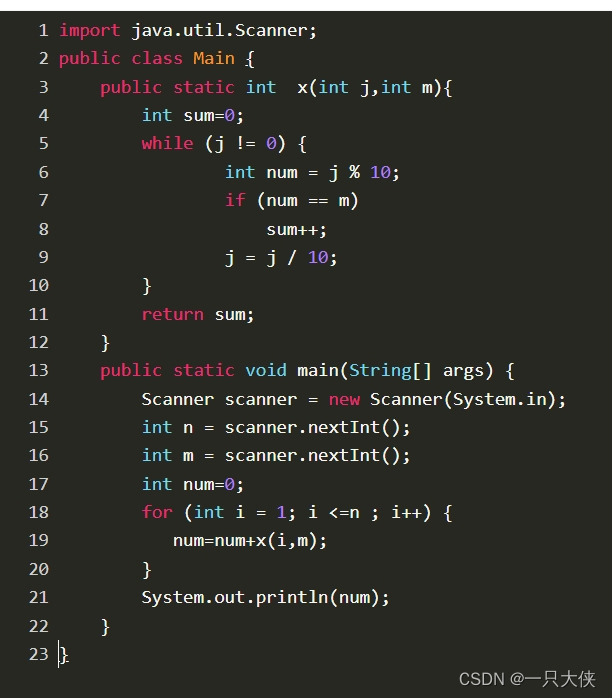
- 💯方法一:朴素循环求和法
- 2.1 实现原理
- 2.2 分析与问题
- 2.3 改进方案
- 2.4 性能瓶颈与结论
- 💯方法二:数学公式法
- 3.1 实现原理
- 3.2 代码实现
- 3.3 理论优势
- 3.4 与方法一的对比
- 💯等差数列求和公式的理论推导与扩展
- 4.1 公式推导
- 4.2 理论扩展:大规模数据的存储与表示
- 💯小结
![]()

💯前言
- 求和问题是计算机科学中的基础问题,尤其在算法与数值计算中经常出现。然而,当数据规模扩展到极限时,解决方案的性能和精度变得至关重要。本篇文章深入剖析一道典型的求和问题,重点探讨不同方法的
时间复杂度、空间复杂度及其实际应用场景。同时,通过理论与代码的详细对比,展示如何通过数学优化实现计算的高效性与准确性,帮助研究生级读者理解算法的本质与优化策略。此外,文章扩展探讨等差数列的数学性质、程序优化的核心思维,并在理论基础之上结合实际应用,为解决类似问题提供系统性的思维框架。
C++ 参考手册

💯问题描述与数学模型
我们需要解决的问题如下:
1.1 题目概述
小乐乐求和

计算从 1 到 n 的整数和:
S
=
∑
i
=
1
n
i
S = \sum_{i=1}^n i
S=i=1∑ni
其中,n 是一个正整数,满足
1
≤
n
≤
1
0
9
1 \leq n \leq 10^9
1≤n≤109。
1.2 输入输出要求
- 输入:一个正整数 n。
- 输出:求和结果 S。
示例:
| 输入 | 输出 |
|---|---|
| 1 | 1 |
| 10 | 55 |
1.3 数学建模
该问题实质上是等差数列求和的问题,等差数列的求和公式如下:
S
=
n
×
(
n
+
1
)
2
S = \frac{n \times (n + 1)}{2}
S=2n×(n+1)
通过这个数学公式,我们可以在常数时间内( O ( 1 ) O(1) O(1))直接计算出结果。此外,从复杂度的角度来看,使用该公式能够在理论上实现最优的计算性能。
💯方法一:朴素循环求和法
2.1 实现原理
朴素循环求和法通过遍历从 1 到 n 的所有整数,将每个整数累加到一个和变量中,最终得到结果。代码如下:
#include <iostream>
using namespace std;
int main() {
int a, sum = 0; // 定义输入变量和存储求和的变量
cin >> a; // 读取输入
int i = 1; // 初始化计数变量
while (i <= a) {
sum += i; // 累加当前数值
i++;
}
cout << sum; // 输出最终结果
return 0;
}

2.2 分析与问题
-
时间复杂度:O(n)
- 循环从 1 执行到 n,每一步执行一个加法操作,时间复杂度随输入规模线性增加。对于大规模输入,例如 n = 1 0 9 n = 10^9 n=109,执行时间难以接受。
-
整数溢出:
- 使用
int数据类型存储求和结果时,最大可表示范围为 2 31 − 1 ≈ 2.1 × 1 0 9 2^{31} - 1 \approx 2.1 \times 10^9 231−1≈2.1×109。 - 当 n n n 接近 1 0 9 10^9 109 时,累加和会超出范围,导致数据溢出。
- 使用
2.3 改进方案
将求和结果的数据类型修改为 long long,以支持大整数计算:
#include <iostream>
using namespace std;
int main() {
long long a, sum = 0; // 使用long long存储大数
cin >> a;
for (int i = 1; i <= a; i++) {
sum += i;
}
cout << sum; // 输出结果
return 0;
}


2.4 性能瓶颈与结论
虽然使用 long long 解决了溢出问题,但朴素循环法的时间复杂度仍为
O
(
n
)
O(n)
O(n),对于大规模输入,计算效率极低。该方法的瓶颈在于其依赖线性次数的加法操作,无法避免冗余的计算开销。因此,在处理上限数据规模时,朴素方法往往不适用。
💯方法二:数学公式法
3.1 实现原理
数学公式法基于等差数列求和公式:
S
=
n
×
(
n
+
1
)
2
S = \frac{n \times (n + 1)}{2}
S=2n×(n+1)
该公式利用数列的性质,通过一次乘法和一次除法即可得到结果,时间复杂度为
O
(
1
)
O(1)
O(1)。
3.2 代码实现
#include <iostream>
using namespace std;
int main() {
long long n; // 使用long long处理大输入
cin >> n;
long long sum = (n * (n + 1)) / 2; // 利用公式计算结果
cout << sum << endl;
return 0;
}


3.3 理论优势
-
时间复杂度: O ( 1 ) O(1) O(1)
- 仅需常数次运算即可得出结果,与输入规模无关。理论上,该方法在计算复杂度上已达到最优。
-
数据安全:
- 使用
long long类型确保中间计算过程不会溢出,能够正确处理大规模输入数据。
- 使用
-
简洁性与可维护性:
- 代码逻辑清晰且易于维护。数学公式法避免了冗余的循环操作,使代码更加简洁高效。
3.4 与方法一的对比
| 方法 | 时间复杂度 | 空间复杂度 | 执行效率 | 代码复杂度 |
|---|---|---|---|---|
| 循环求和法 | O(n) | O(1) | 随 n 增大而效率降低 | 较复杂 |
| 数学公式法 | O(1) | O(1) | 执行效率恒定,极高效 | 简单易懂 |
💯等差数列求和公式的理论推导与扩展
4.1 公式推导
等差数列求和公式的核心在于数列的对称性。假设数列为:
1
,
2
,
3
,
…
,
n
1, 2, 3, \dots, n
1,2,3,…,n
我们将其正向与反向相加:
S
=
1
+
2
+
3
+
⋯
+
n
(正序)
S = 1 + 2 + 3 + \dots + n \quad \text{(正序)}
S=1+2+3+⋯+n(正序)
S
=
n
+
(
n
−
1
)
+
(
n
−
2
)
+
⋯
+
1
(反序)
S = n + (n-1) + (n-2) + \dots + 1 \quad \text{(反序)}
S=n+(n−1)+(n−2)+⋯+1(反序)
两式相加:
2
S
=
(
1
+
n
)
+
(
2
+
(
n
−
1
)
)
+
⋯
+
(
n
+
1
)
2S = (1 + n) + (2 + (n-1)) + \dots + (n + 1)
2S=(1+n)+(2+(n−1))+⋯+(n+1)
数列中共有
n
n
n 项,每一对的和为
n
+
1
n + 1
n+1,因此:
2
S
=
n
×
(
n
+
1
)
2S = n \times (n + 1)
2S=n×(n+1)
将结果除以 2:
S
=
n
×
(
n
+
1
)
2
S = \frac{n \times (n + 1)}{2}
S=2n×(n+1)
4.2 理论扩展:大规模数据的存储与表示
在数值计算中,当处理极大规模数据时,选择合适的数据类型尤为重要。在 C++ 中,long long 类型可以存储 64 位整数,最大值为
9.2
×
1
0
18
9.2 \times 10^{18}
9.2×1018。此外,为了进一步处理超大数值,可以引入库如 GMP(GNU Multiple Precision Arithmetic Library)以进行多精度计算。
💯小结

本篇文章详细解析了求和问题的两种解决方案,并深入对比了它们的时间复杂度与实际应用场景:
-
朴素循环法:
- 适用于小规模数据,但在大规模输入下性能欠佳。
-
数学公式法:
- 依托数学优化,时间复杂度为 O ( 1 ) O(1) O(1),是解决此类问题的最佳方案。
- 数学公式法 是大规模求和问题的高效解决方案。
- 数据类型选择:使用
long long避免溢出。 - 理论与实践结合:通过数学推导理解公式的本质,提高代码优化的意识。
- 扩展思维:掌握数据类型的选择及大规模数值计算的解决方案。
通过本文的深入剖析,读者能够全面理解求和问题的不同解法,并掌握优化代码性能与理论推导的核心技能。这不仅适用于编程竞赛和工程实践,也为进一步研究算法优化与数值计算奠定了坚实的基础。