能简单说一下索引的分类吗?

例如从基本使用使用的角度来讲:
- 主键索引: InnoDB 主键是默认的索引,数据列不允许重复,不允许为 NULL,一个表只能有一个主键。
- 唯一索引: 数据列不允许重复,允许为 NULL 值,一个表允许多个列创建唯一索引。
- 普通索引: 基本的索引类型,没有唯一性的限制,允许为 NULL 值。
- 组合索引:多列值组成一个索引,用于组合搜索,效率大于索引合并
为什么使用索引会加快查询?
传统的查询方法,是按照表的顺序遍历的,不论查询几条数据,MySQL 需要将表的数据从头到尾遍历一遍。
在我们添加完索引之后,MySQL 一般通过 BTREE 算法生成一个索引文件,在查询数据库时,找到索引文件进行遍历,在比较小的索引数据里查找,然后映射到对应的数据,能大幅提升查找的效率
创建索引有哪些注意点?
索引虽然是 sql 性能优化的利器,但是索引的维护也是需要成本的,所以创建索引,也要注意:
- 索引应该建在查询应用频繁的字段
在用于 where 判断、 order 排序和 join 的(on)字段上创建索引。
- 索引的个数应该适量
索引需要占用空间;更新时候也需要维护。
- 区分度低的字段,例如性别,不要建索引。
离散度太低的字段,扫描的行数降低的有限。
- 频繁更新的值,不要作为主键或者索引
维护索引文件需要成本;还会导致页分裂,IO 次数增多。
- 组合索引把散列性高(区分度高)的值放在前面
为了满足最左前缀匹配原则
- 创建组合索引,而不是修改单列索引。
组合索引代替多个单列索引(对于单列索引,MySQL 基本只能使用一个索引,所以经常使用多个条件查询时更适合使用组合索引)
- 过长的字段,使用前缀索引。当字段值比较长的时候,建立索引会消耗很多的空间,搜索起来也会很慢。我们可以通过截取字段的前面一部分内容建立索引,这个就叫前缀索引。
- 不建议用无序的值(例如身份证、UUID )作为索引
当主键具有不确定性,会造成叶子节点频繁分裂,出现磁盘存储的碎片化
索引哪些情况下会失效呢?
- 查询条件包含 or,可能导致索引失效
- 如果字段类型是字符串,where 时一定用引号括起来,否则会因为隐式类型转换,索引失效
- like 通配符可能导致索引失效。
- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用 mysql 的内置函数,索引失效。
- 对索引列运算(如,+、-、*、/),索引失效。
- 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
- 索引字段上使用 is null, is not null,可能导致索引失效。
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- MySQL 优化器估计使用全表扫描要比使用索引快,则不使用索引。
索引不适合哪些场景呢?
- 数据量比较少的表不适合加索引
- 更新比较频繁的字段也不适合加索引
- 离散低的字段不适合加索引(如性别)
索引是不是建的越多越好呢?
当然不是。
- 索引会占据磁盘空间
- 索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL 不仅要保存数据,还有保存或者更新对应的索引文件。
为什么要用 B+ 树,而不用普通二叉树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,以及查找磁盘次数。
为什么不用普通二叉树?
普通二叉树存在退化的情况,如果它退化成链表,相当于全表扫描。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
为什么不用平衡二叉树呢?
读取数据的时候,是从磁盘读到内存。如果树这种数据结构作为索引,那每查找一次数据就需要从磁盘中读取一个节点,也就是一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果是 B+ 树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就降下来啦,查询效率就快。
为什么用 B+ 树而不用 B 树呢?
B+相比较 B 树,有这些优势:
- 它是 B Tree 的变种,B Tree 能解决的问题,它都能解决。
B Tree 解决的两大问题:每个节点存储更多关键字;路数更多
- 扫库、扫表能力更强
如果我们要对表进行全表扫描,只需要遍历叶子节点就可以 了,不需要遍历整棵 B+Tree 拿到所有的数据。
- B+Tree 的磁盘读写能力相对于 B Tree 来说更强,IO 次数更少
根节点和枝节点不保存数据区, 所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多,IO 次数更少。
- 排序能力更强
因为叶子节点上有下一个数据区的指针,数据形成了链表。
- 效率更加稳定
B+Tree 永远是在叶子节点拿到数据,所以 IO 次数是稳定的。
Hash 索引和 B+ 树索引区别是什么?
- B+ 树可以进行范围查询,Hash 索引不能。
- B+ 树支持联合索引的最左侧原则,Hash 索引不支持。
- B+ 树支持 order by 排序,Hash 索引不支持。
- Hash 索引在等值查询上比 B+ 树效率更高。
- B+ 树使用 like 进行模糊查询的时候,like 后面(比如 % 开头)的话可以起到优化的作用,Hash 索引根本无法进行模糊查询。
聚簇索引与非聚簇索引的区别?
首先理解聚簇索引不是一种新的索引,而是一种数据存储方式。聚簇表示数据行和相邻的键值紧凑地存储在一起。我们熟悉的两种存储引擎——MyISAM 采用的是非聚簇索引,InnoDB 采用的是聚簇索引。
可以这么说:
- 索引的数据结构是树,聚簇索引的索引和数据存储在一棵树上,树的叶子节点就是数据,非聚簇索引索引和数据不在一棵树上。
回表了解吗?
在 InnoDB 存储引擎里,利用辅助索引查询,先通过辅助索引找到主键索引的键值,再通过主键值查出主键索引里面没有符合要求的数据,它比基于主键索引的查询多扫描了一棵索引树,这个过程就叫回表。
什么是最左前缀原则/最左匹配原则?
注意:最左前缀原则、最左匹配原则、最左前缀匹配原则这三个都是一个概念。
最左匹配原则:在 InnoDB 的联合索引中,查询的时候只有匹配了前一个/左边的值之后,才能匹配下一个。
根据最左匹配原则,我们创建了一个组合索引,如 (a1,a2,a3),相当于创建了(a1)、(a1,a2)和 (a1,a2,a3) 三个索引。
为什么不从最左开始查,就无法匹配呢?
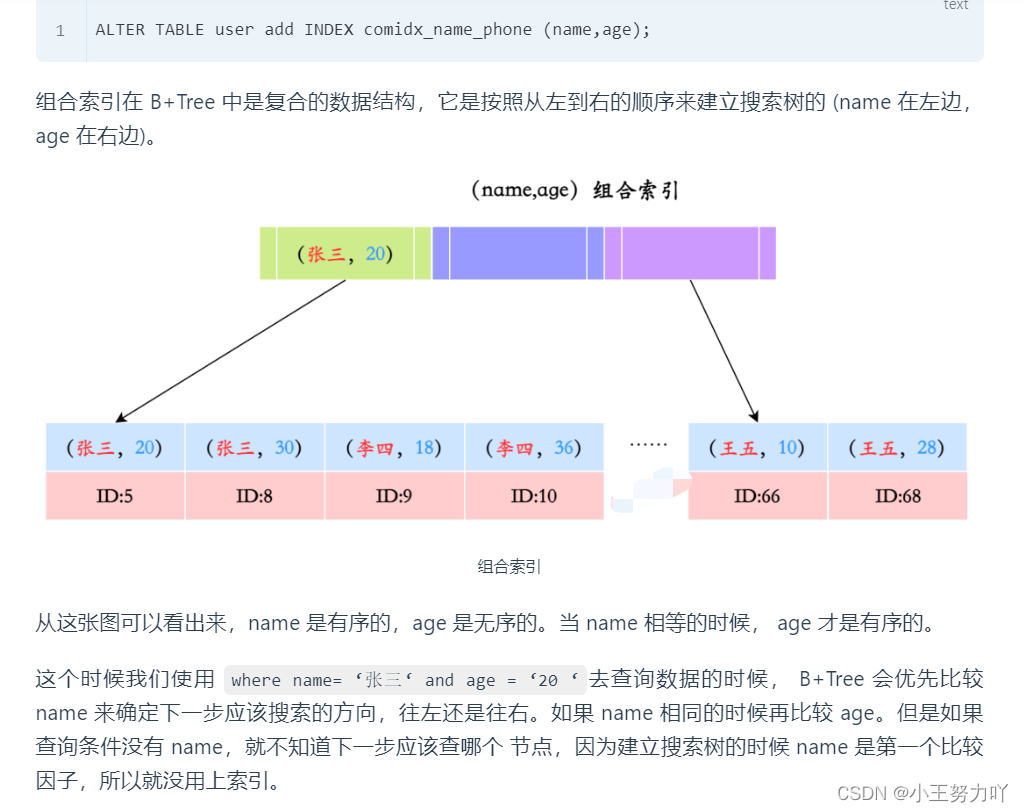
比如有一个 user 表,我们给 name 和 age 建立了一个组合索引。
什么是最左前缀原则/最左匹配原则?
注意:最左前缀原则、最左匹配原则、最左前缀匹配原则这三个都是一个概念。
最左匹配原则:在 InnoDB 的联合索引中,查询的时候只有匹配了前一个/左边的值之后,才能匹配下一个。
根据最左匹配原则,我们创建了一个组合索引,如 (a1,a2,a3),相当于创建了(a1)、(a1,a2)和 (a1,a2,a3) 三个索引。
为什么不从最左开始查,就无法匹配呢?
比如有一个 user 表,我们给 name 和 age 建立了一个组合索引。


![[计算机入门] Windows附件程序介绍(办公类)](https://img-blog.csdnimg.cn/fec3f49cb1d74848aaf61e91b556390f.png)