1 问题描述
在训练lstm网络过程中出现如下错误:
Traceback (most recent call last):
File "D:\code\lstm_emotion_analyse\text_analyse.py", line 82, in <module>
loss.backward()
File "C:\Users\lishu\anaconda3\envs\pt2\lib\site-packages\torch\_tensor.py", line 487, in backward
torch.autograd.backward(
File "C:\Users\lishu\anaconda3\envs\pt2\lib\site-packages\torch\autograd\__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
2 问题分析
按照错误提示查阅相关资料了解到,实际上在大多数情况下retain_graph都应采用默认的False,除了几种特殊情况:
- 一个网络有两个output分别执行backward进行回传的时候: output1.backward(), output2.backward().
- 一个网络有两个loss需要分别执行backward进行回传的时候: loss1.backward(), loss2.backward().
但本项目的LSTM训练模型不属于以上情况,再次查找资料,在在pytorch的官方论坛上找到了真正的原因:
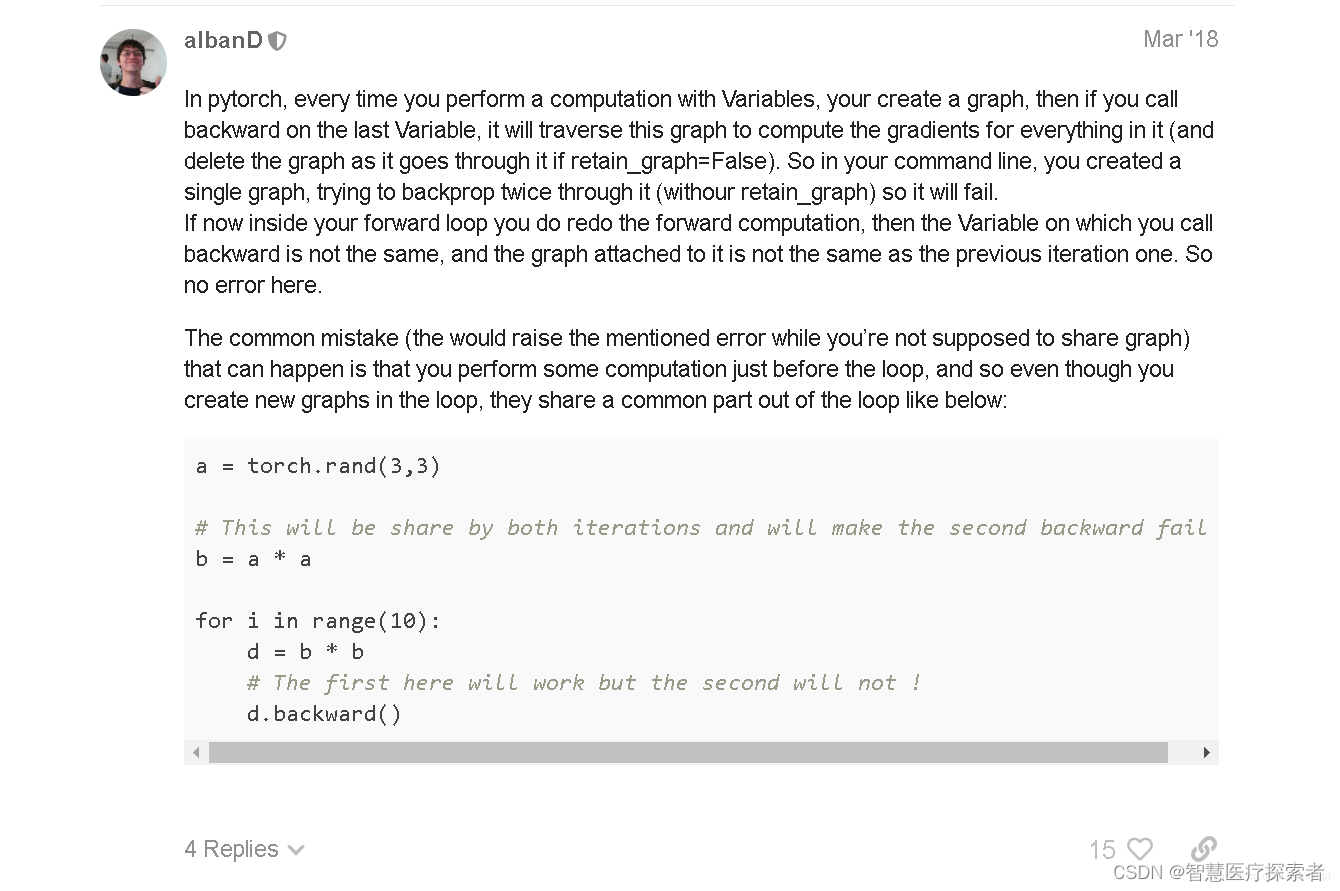
如截图中的描述,只要我们对变量进行运算了,就会加进计算图中。所以本项目的问题在于在for循环梯度反向传播中,使用了循环外部的变量h,如下所示:
epochs = 128
step = 0
model.train() # 开启训练模式
for epoch in range(epochs):
h = model.init_hidden(batch_size) # 初始化第一个Hidden_state
for data in tqdm(train_loader):
x_train, y_train = data
x_train, y_train = x_train.to(device), y_train.to(device)
step += 1 # 训练次数+1
x_input = x_train.to(device)
model.zero_grad()
output, h = model(x_input, h)
# 计算损失
loss = criterion(output, y_train.float().view(-1))
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step()
if step % 10 == 0:
print("Epoch: {}/{}...".format(epoch + 1, epochs),
"Step: {}...".format(step),
"Loss: {:.6f}...".format(loss.item()))3 问题解决
代码修改如下:
epochs = 128
step = 0
model.train() # 开启训练模式
for epoch in range(epochs):
h = model.init_hidden(batch_size) # 初始化第一个Hidden_state
for data in tqdm(train_loader):
x_train, y_train = data
x_train, y_train = x_train.to(device), y_train.to(device)
step += 1 # 训练次数+1
x_input = x_train.to(device)
model.zero_grad()
h = tuple([e.data for e in h])
output, h = model(x_input, h)
# 计算损失
loss = criterion(output, y_train.float().view(-1))
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step()
if step % 10 == 0:
print("Epoch: {}/{}...".format(epoch + 1, epochs),
"Step: {}...".format(step),
"Loss: {:.6f}...".format(loss.item()))增加for循环内部变量,对外部变量进行复制,内部变量参与梯度传播,问题解决。








![[谷粒商城笔记]07、Linux环境-虚拟机网络设置](https://img-blog.csdnimg.cn/8cbdc14ff1da498686597b1d66ebbdeb.png)