前言:
在前面我们学习了顺序表,相当于数据结构的凉菜,今天我们正式开始数据结构的硬菜了,那就是链表,链表有多种结构,但我们实际中最常用的还是无头单向非循环链表和带头双向循环链表,我们今天先学习无头单向循环链表。
1、链表介绍
1.1链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
结点:因为链表的结点在逻辑上是连续,物理上不一定连续,所以每一个结点的类型有两部分组成:数据域(存储链表的数据)和指针域(存储后继结点的地址)。
结构:
①逻辑图:为了方便理解,想象出来的,用形象方式表示(如箭头)
②物理图:内存中真实存储,实实在在数据在内存中的变化
如上两幅图我们可知:①链式结构在逻辑上是连续的,但是在物理上不一定连续;②现实中结点一般都是malloc从堆上申请出来的;③从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续。


1.2顺序表和链表的优缺点
(1)顺序表的缺点:
①空间不够了,需要扩容,扩容是要付出代价的。
②避免频繁扩容,增容一般都是按倍数去扩(一般2倍适中),可能存在一定空间浪费(如:当前容量为100,满了以后增容到200,我们再继续插入5个数据,后面没有数据插入了,那么就浪费了95个数据空间。)
③头部或者中间位置的插入删除,需要挪动,挪到数据也是有消耗的。
(2)顺序表的优点:
①支持随机,有些算法需要结构支持随机访问,比如:二分查找,优化的快排等等。
(3)链表的优点:
①按需申请空间,不用了就释放空间(更合理的使用了空间)
②头部或者中间插入数据,不需要挪动数据
③不存在浪费空间
(4)链表的缺点:
①每一个结点,都要存一个后继结点的地址去链接后面的数据结点。
②不支持随机访问(就是不能使用下标直接访问第i个数据),必须得走0(N)
tip:单链表的缺陷还是有很多的,单纯单链表增删查改的意义不大但是①很多OJ题考察的都是单链表;②单链表更多用于更复杂数据结构的子结构、哈希桶、邻接表等。链表存储数据还要看双向链表,这个后面在学。
根据顺序表和链表的优缺点我们可以看出,链表与顺序表是互补的,相辅相成!
2、单链表(无头单向非循环链表)的实现
2.1定义单链表结点
代码演示:
//重定义链表结点中数据域的类型(优点:①见名知意;②一改全改)
typedef int SLTDataType;
//定义链表结点
typedef struct SListNode
{
SLTDataType data;//用来存放结点的数据
struct SListNode* next;//用来存放后继结点的地址
}SLTNode;//重命名为SLTNode解读:
①typedef:类型重命名——作用:见名知意;一改全改;
②链表逻辑上是连续,物理上不一定连续,所以它是复杂类型——有两个变量组成,data变量存放结点的数据;next指针变量存放后继结点的地址(这也叫做结构自引用:①注意结构的自引用不能是结构体本身,因为C是自上向下编译的,所以当引用结构本身是结构不完整,报错。②正确的结构自引用是定义成结构体的指针,结构的指针不受结构的内容影响,它只是一个指针,指向你定义的一个结构,至于这个结构完不完整是什么,它都不需要知道。因此编译器能令其通过。)
2.2单链表的打印模块
因为链表不支持随机访问,所以必须从第一个结点开始依次向后访问。(①我们只需知道头指针即可,所以参数只有一个;②又因为只是打印不用改变链表,所以只需值传递即可。)
代码演示:
//单链表打印
void SLTPrint(SLTNode* phead)
{
//assert(phead);//?——错,不用断言,链表为空时也能打印
//定义一个临时指针变量指向链表的第一个结点
SLTNode* cur = phead;
//当链表结点到尾时打印结束:即cur为NULL
while (cur)
{
//打印链表结点的数据
printf("%d->", cur->data);
//得到后继结点的地址
cur = cur->next;
}
printf("NULL\n");
}调试代码演示:
void SLTNodeText01()
{
SLTNode* plist = NULL;
SLTPrint(plist);
}
int main()
{
SLTNodeText01();
return 0;
}解读:
①值传递:形参只是实参的一份临时拷贝,形参的改变不影响实参。
②注意:我们不要形成固定思维,看到参数是指针就断言,要根据实际情况判断。图示:

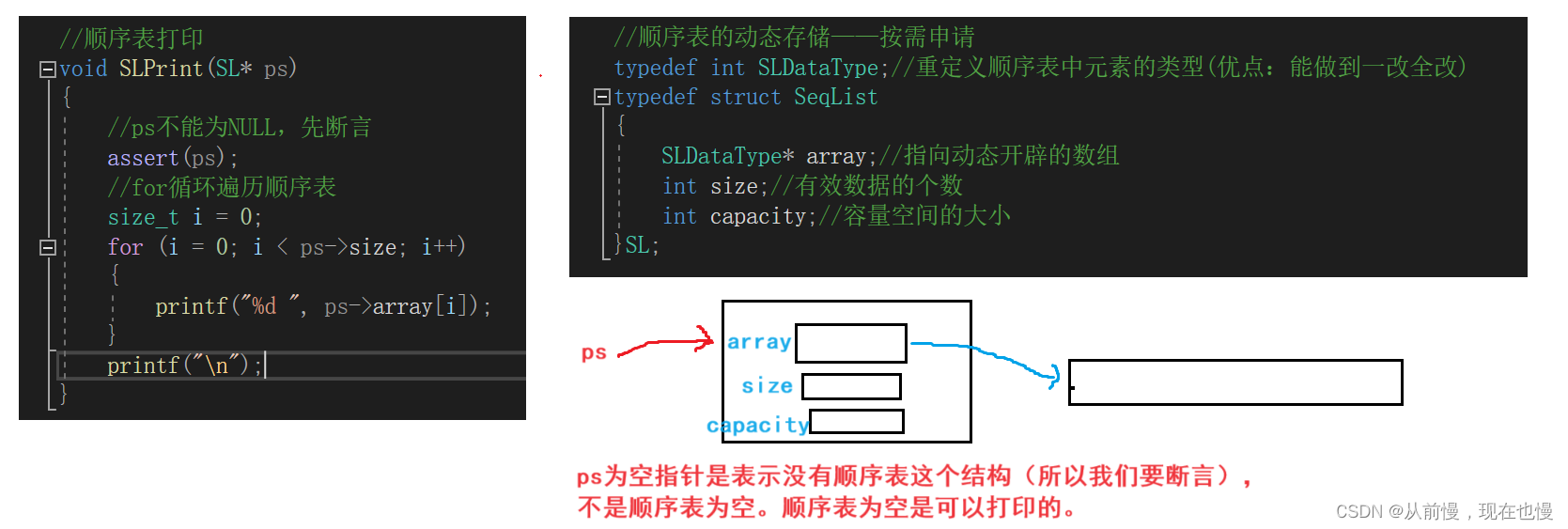
③cur = cur->next,为什么就能得到后继结点的地址——结构体指针访问结构体成员可以通过->操作符访问;结点成员next中存储的是后继结点的地址。图示:

④我们能不能通过cur++找到下一个结点呢——答案是:不能,因为链表在物理上是不一定连续的。
2.3单链表的尾插模块
要尾插一个新节点:①我们先创建好一个新节点;②给新节点初始化;③与原链表链接——先找尾,找到后将新节点的地址拷贝给原来的尾结点的next即可。(注意特殊情况:链表为空时,是将新节点的地址拷贝给头指针)
代码演示:
//单链表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
//创建新节点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
//判断是否开辟成功
if (NULL == newnode)
{
perror("SLTPushBack::malloc");//打印错误信息
exit(-1);
}
//给新节点初始化
newnode->data = x;
newnode->next = NULL;
//判断是否为空链表
if (NULL == *pphead)
{
//为空链表,直接将新节点的地址拷贝给头指针即可
*pphead = newnode;
}
else
{
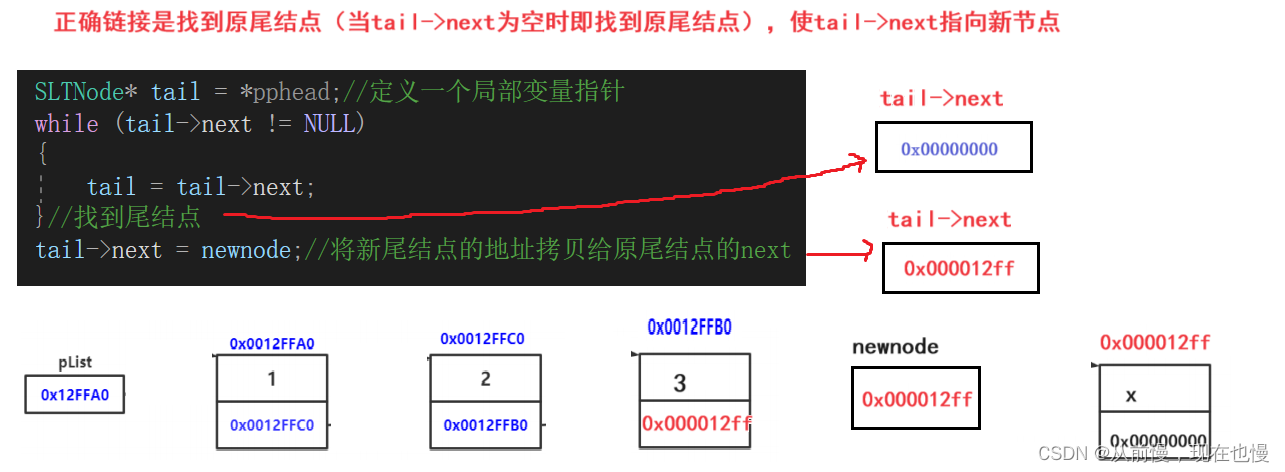
//不为空链表,找到原尾结点,将新尾节点的地址拷贝给原尾结点的next
/*
* 错误代码演示:
SLTNode* tail = *pphead;//定义一个局部变量指针
while (tail)
{
tail = tail->next;
}//将局部变量指针赋值为空指针
tail = newnode;//再将局部变量指针指向新节点
*/
SLTNode* tail = *pphead;//定义一个局部变量指针
while (tail->next != NULL)
{
tail = tail->next;
}//找到尾结点
tail->next = newnode;//将新尾结点的地址拷贝给原尾结点的next
}
}
调试代码演示:
void SLTNodeText02()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
//打印
SLTPrint(plist);
}
int main()
{
SLTNodeText02();
return 0;
}运行结果:
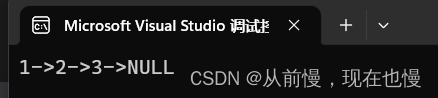
解读:
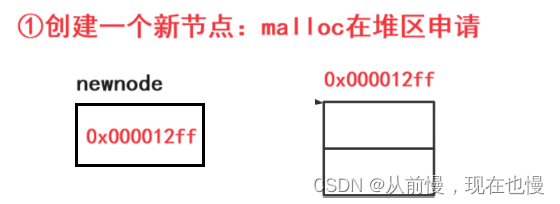
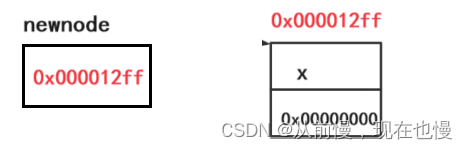
①链表是按需申请空间的,所以malloc在堆区申请空间——使用malloc申请空间需注意:malloc申请的空间没有初始化,使用前要初始化;malloc创建失败会返回NULL,使用前要判断是否开辟成功(一般都能开辟成功);malloc申请空间传的大小单位是字节;图示:
②给新节点初始化——结构体指针访问成员使用操作符->;因为是尾插入的新节点,所以next为空。
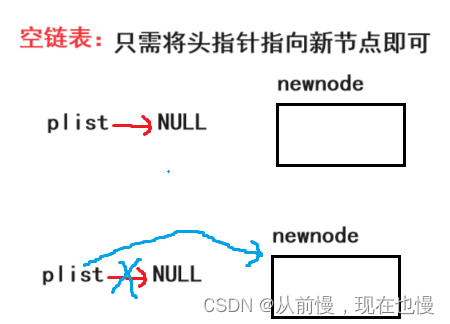
③与原尾结点链接——非空链表:链接就是将原尾结点的next指向新节点;空链表:链接只需将头指针指向新节点即可(形参要影响实参,需要传实参的地址);

④因为形参的改变要影响实参,所以是传址调用——传实参的地址,在函数中可以通过解引用去改变实参,要改变什么类型的值,就传什么类型的指针(如实参是int,就传int*的指针)。
2.4单链表的头插模块&创建新节点模块
新节点模块:因为我们每一次插入数据时,都要创建新节点,操作重复,所以我们可以将其封装为一个单独的模块。
创建新节点代码演示:
//创建新节点
SLTNode* BuySLTNode(SLTDataType x)
{
//创建新节点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
//判断是否开辟成功
if (NULL == newnode)
{
perror("SLTPushBack::malloc");//打印错误信息
exit(-1);
}
//给新节点初始化
newnode->data = x;
newnode->next = NULL;
//返回新节点的地址
return newnode;
}有了该模块,以后我们需要创建新节点,直接调用即可。
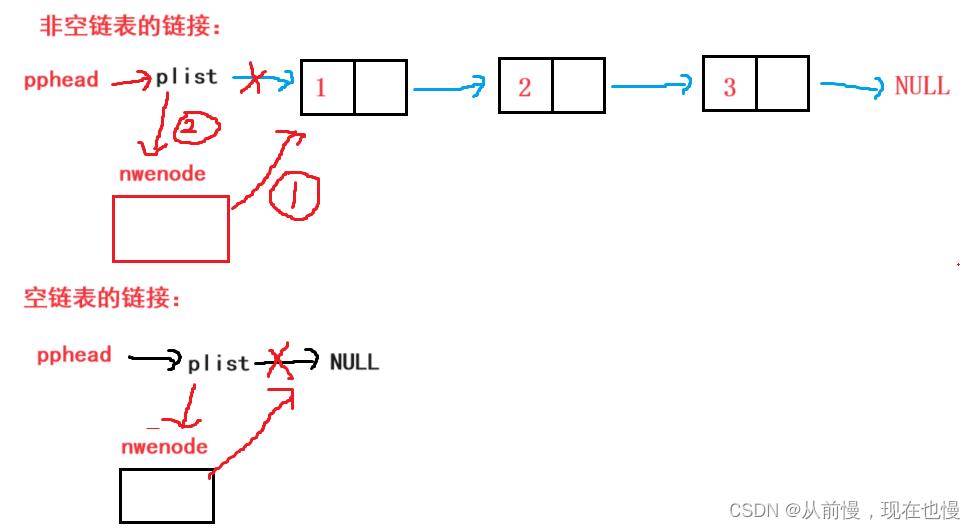
头插模块:头插我们创建好新节点后,我们只需将其链接起来即可——新节点先指向原来的第一个结点,再头指针指向新节点。
头插的代码演示:
//单链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
//创建新节点
SLTNode* newnode = BuySLTNode(x);
//创建链接
//①新节点指向原第一个结点
newnode->next = *pphead;
//②头指针指向新节点
*pphead = newnode;
}测试代码:
void SLTNodeText03()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//头插
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
//打印
SLTPrint(plist);
}
int main()
{
SLTNodeText03();
return 0;
}运行结果:

解读:
①只要是要求形参的改变要影响实参,就需要址传递——传实参的地址,在函数中可以通过解引用去改变实参,要改变什么类型的值,就传什么类型的指针;
②链接(空链表和非空链表的方式一样),图示:
2.5单链表的尾删
单链表的尾删有三种情况:
情况一:空链表——处理方法①温柔的方式:使用if语句判断,如果为空则直接退出;②严格的方式:断言(为空则直接报错)。
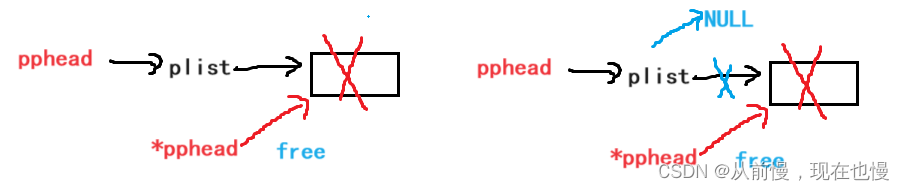
情况二:只有一个结点——①free释放结点(注:free释放完之后的指向动态内存开辟的空间的指针变量不会改变,仍能找到那块空间,有危险(可能非法访问),所以使用完free之后一定记得将其赋值为NULL。);②将头指针置为NULL。图示:
情况三:多个结点——尾删掉最后一个,并且要将原来的倒数第二个节点next置为NULL。图示:
常见性错误:只是释放了尾结点
如图:我们可知问题——可以找到尾结点,但是尾结点的前一位找不到,无法置为空。
解决方案1:双指针——tail指针找原尾结点,prev指针存储原尾结点的前一个结点地址。
解决方案2:找倒数第二个结点——当tail->next->next为NULL时即找到。
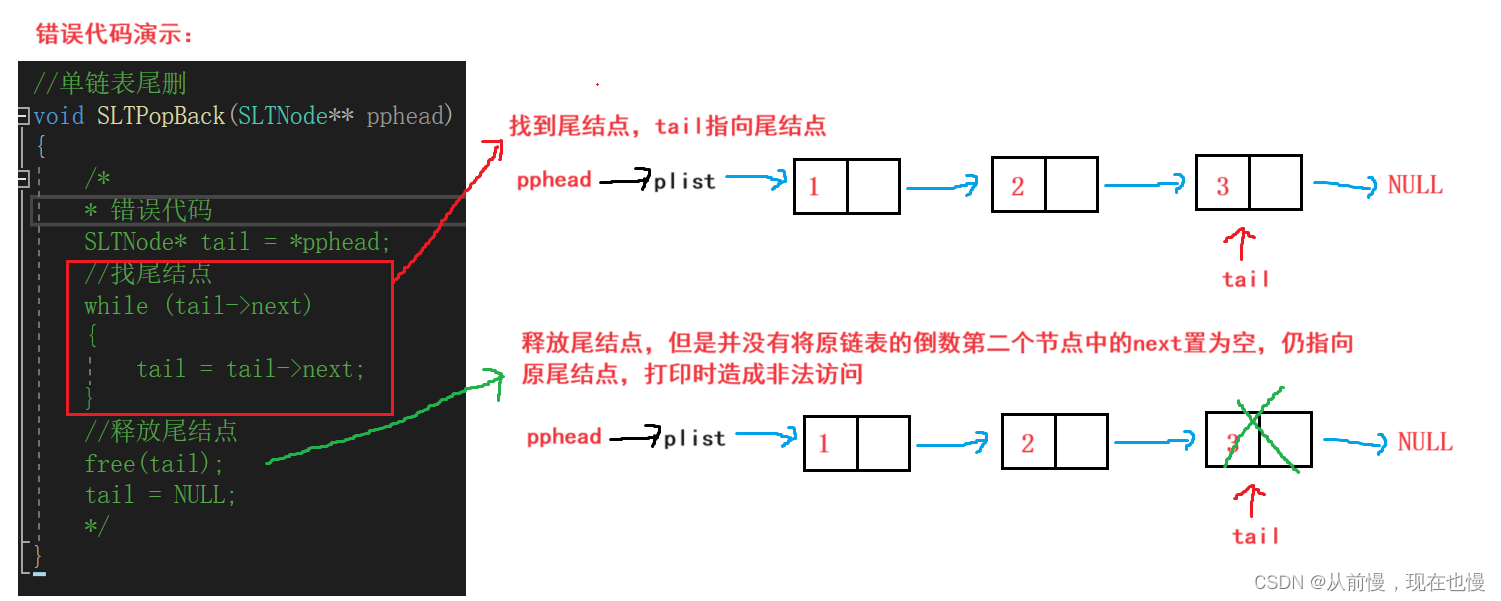
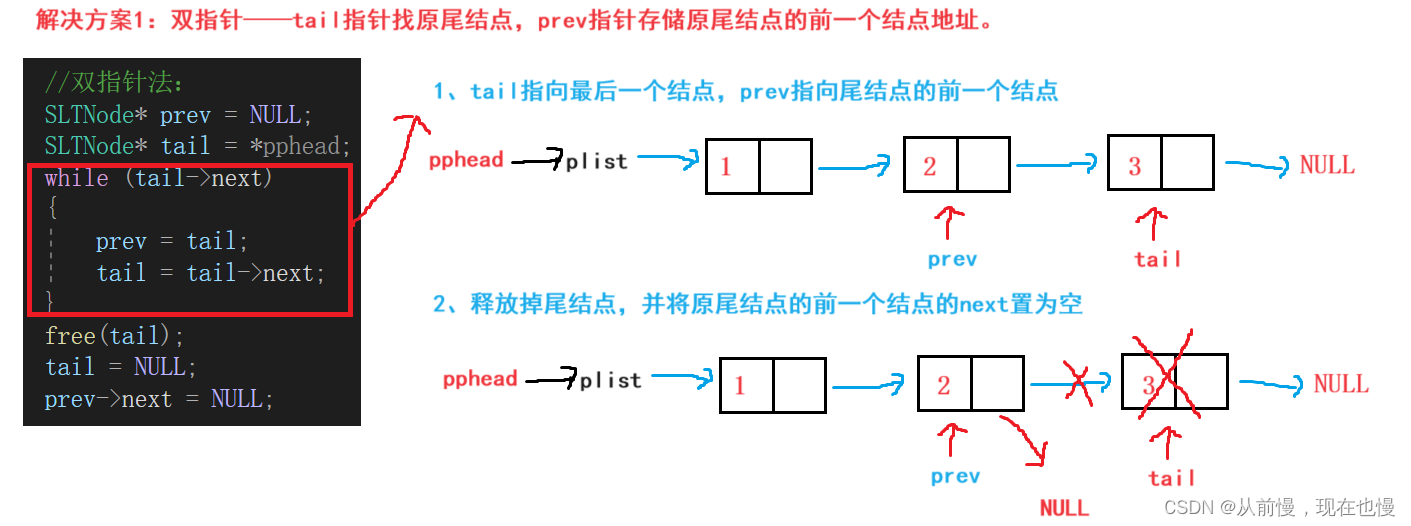
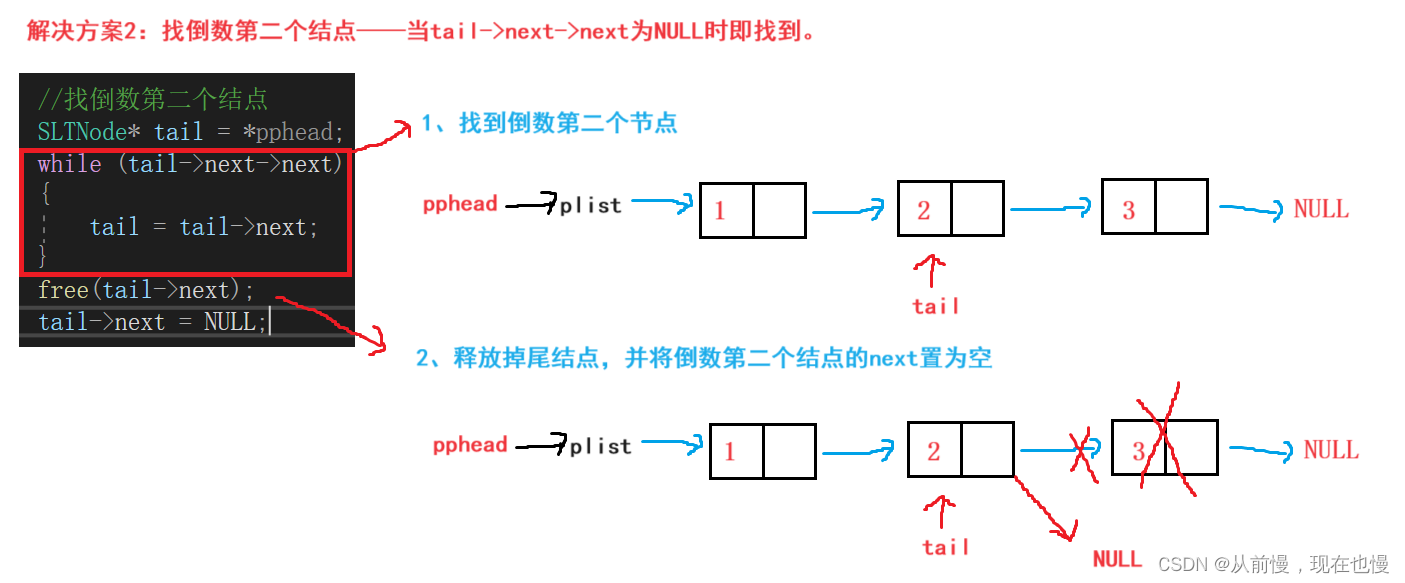
尾删代码演示:
//单链表尾删
void SLTPopBack(SLTNode** pphead)
{
/*
* 错误代码
SLTNode* tail = *pphead;
//找尾结点
while (tail->next)
{
tail = tail->next;
}
//释放尾结点
free(tail);
tail = NULL;
*/
//二级指针不可能为空
assert(pphead);
//1、链表为空
assert(*pphead);
//2、只有一个结点
if ((*pphead)->next == NULL)
{
free(*pphead);
//free只是将该申请的空间还给了操作系统,并没有改变其值,所以将其置空
*pphead = NULL;
}
//3、多个结点
else
{
双指针法:
//SLTNode* prev = NULL;
//SLTNode* tail = *pphead;
//while (tail->next)
//{
// prev = tail;
// tail = tail->next;
//}
//free(tail);
//tail = NULL;
//prev->next = NULL;
//找倒数第二个结点
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
测试代码:
void SLTNodeText03()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//头插
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
}
int main()
{
SLTNodeText03();
return 0;
}运行结果:

2.6单链表的头删
头删就比较简单了,只分为两种情况:
情况1:空链表——直接断言即可(删除就像消费,所以和没钱就不能买都一样)
情况2:非空链表——注意要先将头指针指向第二个结点的地址,再将释放头结点。

头删代码演示:
//单链表头删
void SLTPopFront(SLTNode** pphead)
{
//二级指针一定不为空
assert(pphead);
//断言是否为空链表
assert(*pphead);
//1、修改头指针:使之指向第二个结点
SLTNode* first = *pphead;//保存头结点的地址
*pphead = first->next;
//2、释放头结点
free(first);
}测试代码:
void SLTNodeText04()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//头插
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
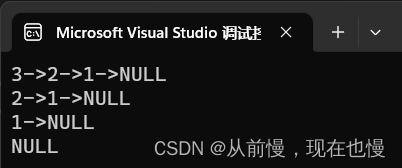
SLTPrint(plist);
/*SLTPopFront(&plist);
SLTPrint(plist);*/
}
int main()
{
SLTNodeText04();
return 0;
}
运行结果:
2.7单链表的查找(修改)
查找:我们只需从头开始遍历链表即可,找到即返回结点的地址,找不到返回空。(查找同时也代表修改功能:我们找到了结点,就会返回结点的地址,通过结点的地址,我们就可以修改了)
查找(修改)代码演示:
//单链表的查找(修改)
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
//遍历链表
while (cur)
{
//找到返回该节点地址,找不到向后遍历
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
//找不到返回空
return NULL;
}
测试代码:
void SLTNodeText05()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 2);
//打印
SLTPrint(plist);
//找到值2的结点将其修改为9
SLTNode* ret = SLTFind(plist, 2);
while (ret)
{
ret->data = 9;
ret = SLTFind(ret, 2);
}
SLTPrint(plist);
}
int main()
{
SLTNodeText05();
return 0;
}运行结果:

2.8单链表指定在pos位置之前插入VS在pos位置之后插入
pos位置之前插入:分两种情况:
情况一:pos指向头结点——即头插
情况二:pos不指向头结点——在pos前插入数据,就要找到pos的前一个结点位置(有效率损失)。

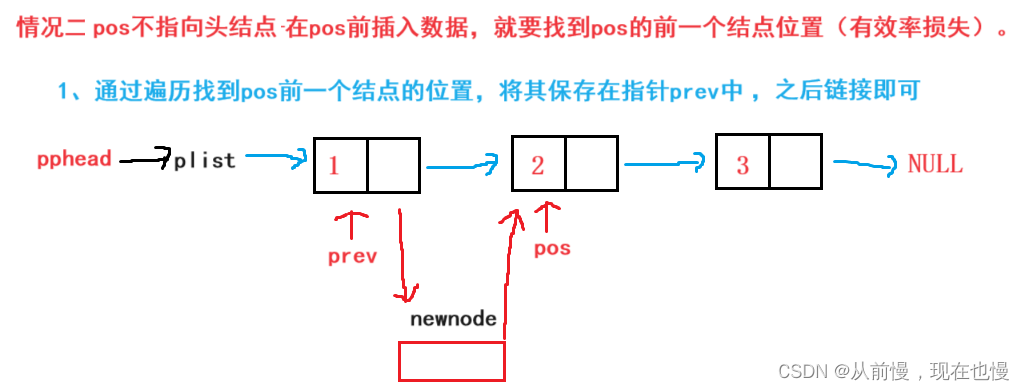
pos之前插入代码演示:
//单链表指定pos位置之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);//pos不能为空(要我们在pos位置插入,那pos位置就得存在)
assert(pphead);
if (*pphead == pos)
{
SLTPushFront(pphead, x);
}//pos指向头结点,在前插入相当于头插
else
{
SLTNode* prev = *pphead;//保存pos前一个结点的地址
while (prev->next != pos)
{
prev = prev->next;
}//找到pos前一个结点
SLTNode* newnode = BuySLTNode(x);
//新节点与原链表链接
prev->next = newnode;
newnode->next = pos;
}//pos不指向头结点
}
测试代码:
void SLTNodeText06()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
//打印
SLTPrint(plist);
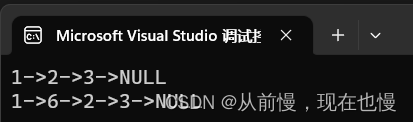
//找到值2的结点在其前面插入6
SLTNode* ret = SLTFind(plist, 2);
SLTInsert(&plist, ret, 6);
SLTPrint(plist);
}
int main()
{
SLTNodeText06();
return 0;
}运行结果:
pos位置之后插入:pos指向头结点和不指向头结点操作都是一样的——创建好新节点之后,只是需要注意新节点先与pos的后继结点链接,再与pos位置结点链接。
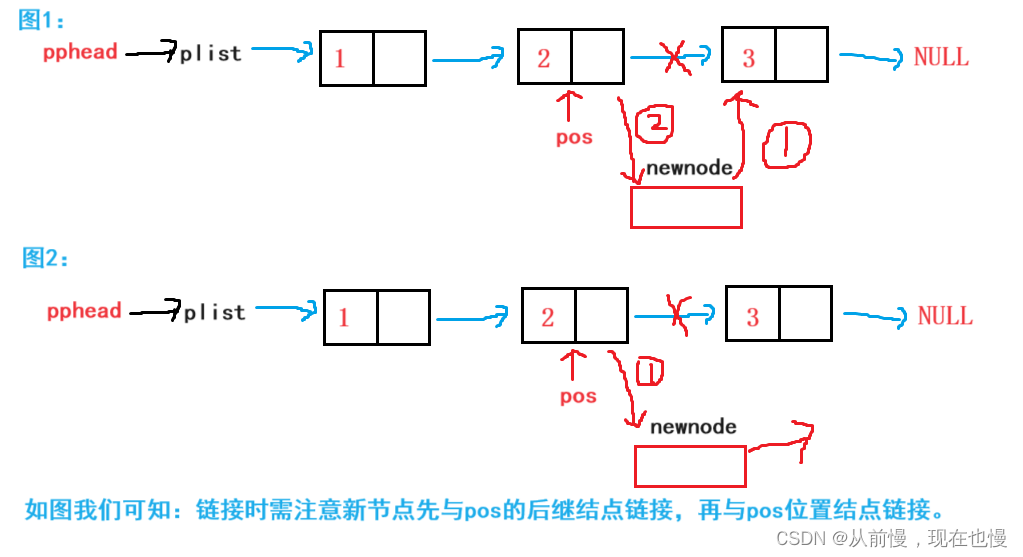
pos位置之后插入代码演示:
//单链表指定pos位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
//创建新节点
SLTNode* newnode = BuySLTNode(x);
//链接
//1、新节点先与pos的后继结点链接
newnode->next = pos->next;
//2、新节点再与pos链接
pos->next = newnode;
}测试代码:
void SLTNodeText07()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
//打印
SLTPrint(plist);
//找到值2的结点在其之后插入6
SLTNode* ret = SLTFind(plist, 2);
SLTInsertAfter(ret, 6);
SLTPrint(plist);
}
int main()
{
SLTNodeText07();
return 0;
}运行结果:
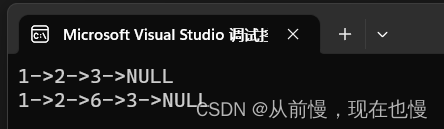
两种插入方式,那种更好呢?
①pos位置之前插入需要分两种情况;pos位置之后插入不用分情况,都一样。
②pos位置之前插入时间复杂度为O(N)——因为之前插入需要找pos的前趋结点位置才能将新节点与链表链接起来;pos位置之后插入时间复杂度为0(1)。
终上,我们链表选择在pos位置之后插入更好。
2.9单链表的pos位置删除VSpos位置之后删除
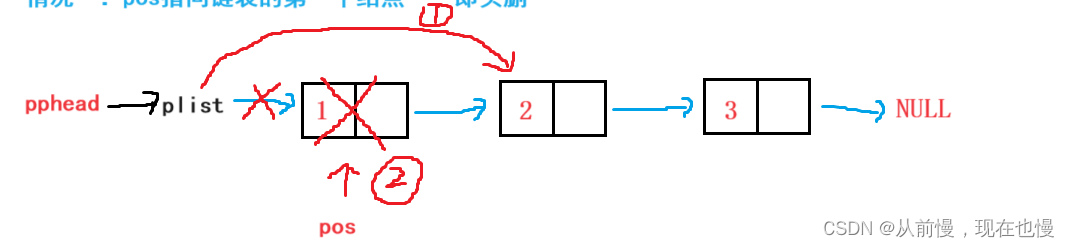
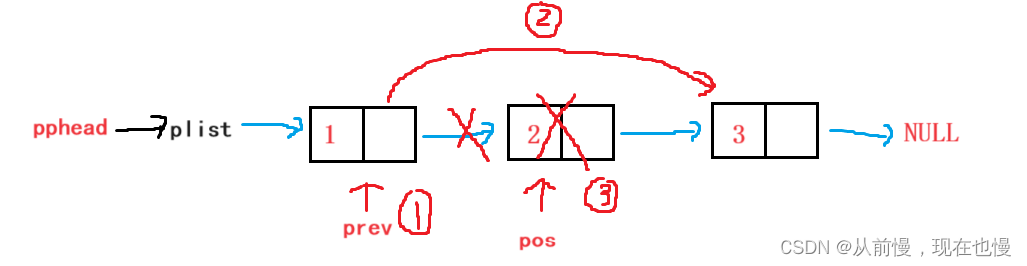
pos位置删除:分两种情况:
情况一:pos指向链表的第一个结点——即头删
情况二:pos不指向链表的头结点——①找到pos的前驱结点;②pos的前驱结点先与pos的后继结点链接好了,再释放pos位置结点(因为先释放pos结点就找不到pos的后继结点了)。
注意:该函数只是将pos位置释放了,并没有将pos指向改变,记得在主调函数置为空,防止非法访问。
pos位置删除代码演示:
//单链表pos位置删除(注意该函数只将pos位置空间释放,并没有将其置为空)
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);//pos位置不能为空(pos位置不为空,链表也不为空)
if (pos == *pphead)
{
SLTPopFront(pphead);
}//pos指向链表头结点
else
{
SLTNode* prev = *pphead;//prev储存pos前一个结点位置
while (prev->next != pos)
{
prev = prev->next;
}//找到pos的前一个结点
//1、先将pos的前驱结点和后继结点链接
prev->next = pos->next;
//2、再将pos位置结点释放
free(pos);
}
}测试代码:
void SLTNodeText08()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
//打印
SLTPrint(plist);
//找到值2的结点再将其删除
SLTNode* ret = SLTFind(plist, 2);
SLTErase(&plist, ret);
ret = NULL;
SLTPrint(plist);
}
int main()
{
SLTNodeText08();
return 0;
}
运行结果:

pos位置之后删除:pos指向头结点和不指向头结点操作都一样,图示:
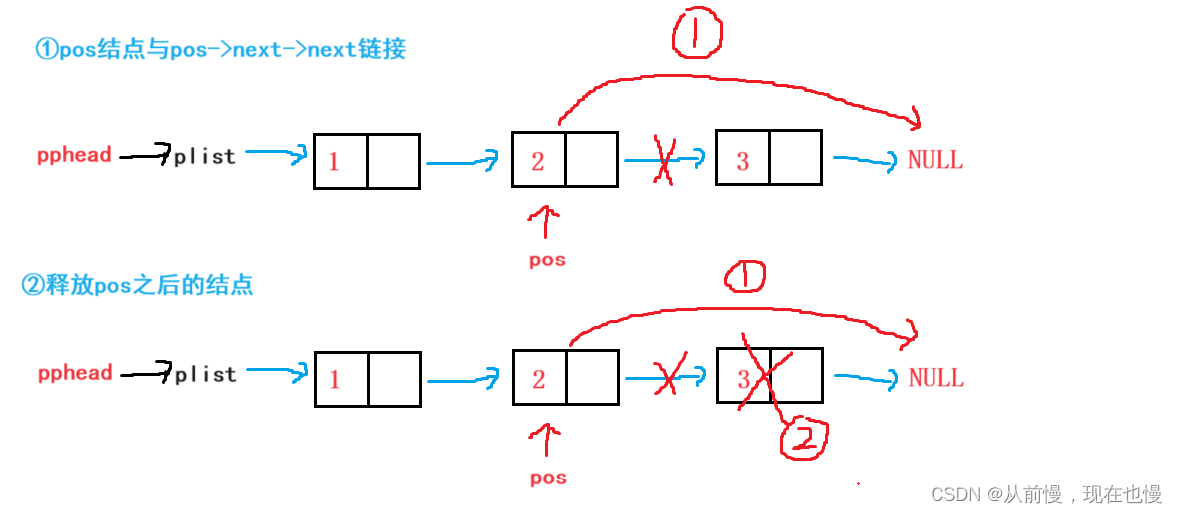
pos之后删除代码演示:
//单链表pos位置之后删除
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;//保存pos后继结点的位置
pos->next = del->next;//链接
free(del);//释放
del = NULL;//free不会改变del的内容
}测试代码:
void SLTNodeText09()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
//打印
SLTPrint(plist);
//找到值2的结点再将其后继结点删除
SLTNode* ret = SLTFind(plist, 2);
SLTEraseAfter(ret);
SLTPrint(plist);
}
int main()
{
SLTNodeText09();
return 0;
}运行结果:

pos位置删除与pos位置之后删除,谁更好呢?
答案是:pos位置之后删除更好,因为①pos位置之后不用分情况更简单;②pos位置之后删除不用找pos的前驱结点,效率更高。pos位置删除时间复杂度为O(N),之后删除时间复杂度为O(1).
2.10单链表的销毁
注意单链表的销毁不是将头指针free就销毁了,是从头结点开始逐个销毁。
注意:
①free释放动态开辟的内存;
②free释放只是是将指针指向的那块动态内存还给操作系统,但是指针仍指向那块空间(为野指针),在使用指针就会造成非法访问,所以free之后记得一般将其置为空。
销毁代码演示:
//单链表的销毁
void SLTDestroy(SLTNode** pphead)
{
assert(pphead);
SLTNode* cur = *pphead;
//从头结点逐个将其释放
while (cur)
{
//保存cur下一个结点的地址,因为free掉cur后内存还给操作系统了
SLTNode* next = cur->next;
free(cur);
cur = next;
}
//销毁完之后将头结点置为空
*pphead = NULL;
}测试代码:
void SLTNodeText10()
{
SLTNode* plist = NULL;//头指针指向链表的第一个结点
//尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
//打印
SLTPrint(plist);
//销毁链表
SLTDestroy(&plist);
SLTPrint(plist);
}
int main()
{
SLTNodeText10();
return 0;
}
运行结果:
3、总代码
3.1单链表的声明模块:SList.h
//预处理:包含,后续常用的头文件
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//重定义链表结点中数据域的类型(优点:①见名知意;②一改全改)
typedef int SLTDataType;
//定义链表结点
typedef struct SListNode
{
SLTDataType data;//用来存放结点的数据
struct SListNode* next;//用来存放后继结点的地址
}SLTNode;//重命名为SLTNode
//单链表打印
void SLTPrint(SLTNode* phead);
//单链表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//创建新节点
SLTNode* BuySLTNode(SLTDataType x);
//单链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//单链表尾删
void SLTPopBack(SLTNode** pphead);
//单链表头删
void SLTPopFront(SLTNode** pphead);
//单链表的查找(修改)
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//单链表指定pos位置之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//单链表指定pos位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//单链表pos位置删除
void SLTErase(SLTNode** pphead, SLTNode* pos);
//单链表pos位置之后删除
void SLTEraseAfter(SLTNode* pos);
//单链表的销毁
void SLTDestroy(SLTNode** pphead);
3.2单链表的实现模块:SList.c
#include"SList.h"
//单链表打印
void SLTPrint(SLTNode* phead)
{
//assert(phead);//?——错,不用断言,链表为空时也能打印
//定义一个临时指针变量指向链表的第一个结点
SLTNode* cur = phead;
//当链表结点到尾时打印结束:即cur为NULL
while (cur)
{
//打印链表结点的数据
printf("%d->", cur->data);
//得到后继结点的地址
cur = cur->next;
}
printf("NULL\n");
}
//创建新节点
SLTNode* BuySLTNode(SLTDataType x)
{
//创建新节点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
//判断是否开辟成功
if (NULL == newnode)
{
perror("SLTPushBack::malloc");//打印错误信息
exit(-1);
}
//给新节点初始化
newnode->data = x;
newnode->next = NULL;
//返回新节点的地址
return newnode;
}
//单链表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
创建新节点
//SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
判断是否开辟成功
//if (NULL == newnode)
//{
// perror("SLTPushBack::malloc");//打印错误信息
// exit(-1);
//}
给新节点初始化
//newnode->data = x;
//newnode->next = NULL;
//
//二级指针一定不为空
assert(pphead);
//创建新节点
SLTNode* newnode = BuySLTNode(x);
//判断是否为空链表
if (NULL == *pphead)
{
//为空链表,直接将新节点的地址拷贝给头指针即可
*pphead = newnode;
}
else
{
//不为空链表,找到原尾结点,将新尾节点的地址拷贝给原尾结点的next
/*
* 错误代码演示:
SLTNode* tail = *pphead;//定义一个局部变量指针
while (tail)
{
tail = tail->next;
}//将局部变量指针赋值为空指针
tail = newnode;//再将局部变量指针指向新节点
*/
SLTNode* tail = *pphead;//定义一个局部变量指针
while (tail->next != NULL)
{
tail = tail->next;
}//找到尾结点
tail->next = newnode;//将新尾结点的地址拷贝给原尾结点的next
}
}
//单链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
//二级指针一定不为空
assert(pphead);
//创建新节点
SLTNode* newnode = BuySLTNode(x);
//创建链接
//①新节点指向原第一个结点
newnode->next = *pphead;
//②头指针指向新节点
*pphead = newnode;
}
//单链表尾删
void SLTPopBack(SLTNode** pphead)
{
/*
* 错误代码
SLTNode* tail = *pphead;
//找尾结点
while (tail->next)
{
tail = tail->next;
}
//释放尾结点
free(tail);
tail = NULL;
*/
//二级指针不可能为空
assert(pphead);
//1、链表为空
assert(*pphead);
//2、只有一个结点
if ((*pphead)->next == NULL)
{
free(*pphead);
//free只是将该申请的空间还给了操作系统,并没有改变其值,所以将其置空
*pphead = NULL;
}
//3、多个结点
else
{
双指针法:
//SLTNode* prev = NULL;
//SLTNode* tail = *pphead;
//while (tail->next)
//{
// prev = tail;
// tail = tail->next;
//}
//free(tail);
//tail = NULL;
//prev->next = NULL;
//找倒数第二个结点
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
//单链表头删
void SLTPopFront(SLTNode** pphead)
{
//二级指针一定不为空
assert(pphead);
//断言是否为空链表
assert(*pphead);
//1、修改头指针:使之指向第二个结点
SLTNode* first = *pphead;//保存头结点的地址
*pphead = first->next;
//2、释放头结点
free(first);
}
//单链表的查找(修改)
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
//遍历链表
while (cur)
{
//找到返回该节点地址,找不到向后遍历
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
//找不到返回空
return NULL;
}
//单链表指定pos位置之前插入
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pos);//pos不能为空(要我们在pos位置插入,那pos位置就得存在)
assert(pphead);
if (*pphead == pos)
{
SLTPushFront(pphead, x);
}//pos指向头结点,在前插入相当于头插
else
{
SLTNode* prev = *pphead;//保存pos前一个结点的地址
while (prev->next != pos)
{
prev = prev->next;
}//找到pos前一个结点
SLTNode* newnode = BuySLTNode(x);
//新节点与原链表链接
prev->next = newnode;
newnode->next = pos;
}//pos不指向头结点
}
//单链表指定pos位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
//创建新节点
SLTNode* newnode = BuySLTNode(x);
//链接
//1、新节点先与pos的后继结点链接
newnode->next = pos->next;
//2、新节点再与pos链接
pos->next = newnode;
}
//单链表pos位置删除(注意该函数只将pos位置空间释放,并没有将其置为空)
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);//pos位置不能为空(pos位置不为空,链表也不为空)
if (pos == *pphead)
{
SLTPopFront(pphead);
}//pos指向链表头结点
else
{
SLTNode* prev = *pphead;//prev储存pos前一个结点位置
while (prev->next != pos)
{
prev = prev->next;
}//找到pos的前一个结点
//1、先将pos的前驱结点和后继结点链接
prev->next = pos->next;
//2、再将pos位置结点释放
free(pos);
}
}
//单链表pos位置之后删除
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;//保存pos后继结点的位置
pos->next = del->next;//链接
free(del);//释放
del = NULL;//free不会改变del的内容
}
//单链表的销毁
void SLTDestroy(SLTNode** pphead)
{
assert(pphead);
SLTNode* cur = *pphead;
//从头结点逐个将其释放
while (cur)
{
//保存cur下一个结点的地址,因为free掉cur后内存还给操作系统了
SLTNode* next = cur->next;
free(cur);
cur = next;
}
//销毁完之后将头结点置为空
*pphead = NULL;
}
今天我们就学完了无头单向非循环链表,下期更新带头双向循环链表,作者水平有限,希望大家多多支持。