基于WIN10的64位系统演示
一、写在前面
上一期,我们构建了多变量的ARIMA时间序列预测模型,其实人家有名字的,叫做ARIMAX模型(X就代表解释变量)。
这一期,我们介绍其他机器学习回归模型如何建立多变量的时间序列模型。与ARIMA一把能输出12个数值不同,其他ML模型还得分多种预测的策略:单步滚动预测、多步滚动预测,其中多步滚动预测还能分成3种类型。
为了便于演示,本期仅仅使用决策树的单步滚动预测进行演示。
二、数据介绍
再介绍一遍:
使用的是一个公共数据集,主要用于做风速预测,包含一个气象站内的5个天气变量传感器的6574个样本数据,如下表:
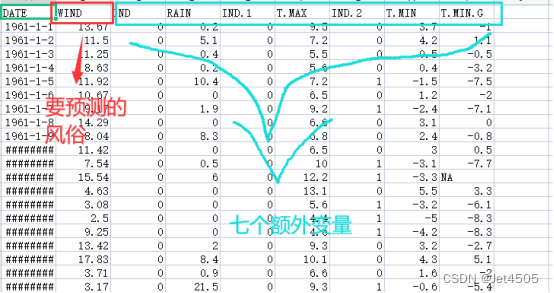
从数据中,我们可以看到以下几列:
DATE:日期。
WIND:风速。
IND 和 IND.1:指标0和指标1(具体啥意思我也不懂)。
RAIN:降雨量。
T.MAX:最高温度。
IND.2:指标2(具体啥意思我也不懂)。
T.MIN:最低温度。
T.MIN.G:09UTC草最低温度(我也不懂是啥意思)。
使用GPT-4分析画个图看看:
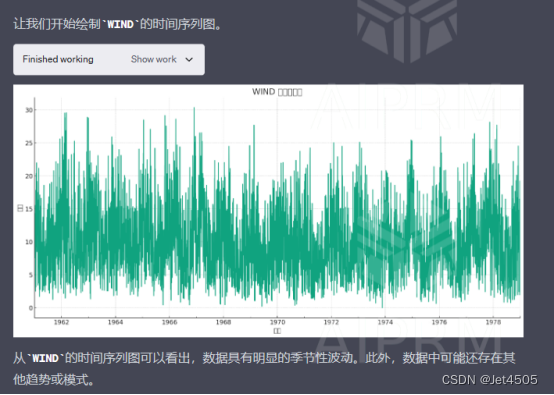
看起来,数据比较潦草。
附上python的代码:
import matplotlib.pyplot as plt
# 将日期列转换为datetime格式,并设置为索引
data['DATE'] = pd.to_datetime(data['DATE'])
data.set_index('DATE', inplace=True)
# 绘制WIND的时间序列图
plt.figure(figsize=(14, 7))
data['WIND'].plot(title='WIND 时间序列图')
plt.ylabel('风速')
plt.xlabel('日期')
plt.grid(True)
plt.tight_layout()
plt.show()三、相关性分析
这一步,有点类似特征工程。
直接沿用上一期的结果:
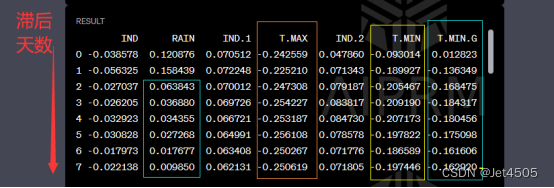
从上表可以看出:
(1)RAIN在当天和滞后1天还不错,在之后就不行了;
(2)T.MAX不管滞后多久,依旧相关;
(3)T.MIN滞后1天之后,开始展现出相关。
综上,我们尝试使用RAIN、T.MAX、T.MIN(lag3)和T.MIN.G(lag3)建立多因素预测模型。
四、决策树回归(未纳入WIND的一次性预测)
这次我们还是用Spyder运行,GPT-4辅助:
(1)数据读取
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
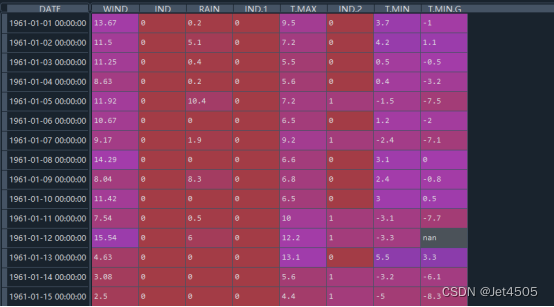
data = pd.read_csv('wind_dataset.csv', index_col=0, parse_dates=True)记住这个data变量:
(2)创建滞后特征
data['T.MIN_lag3'] = data['T.MIN'].shift(3)
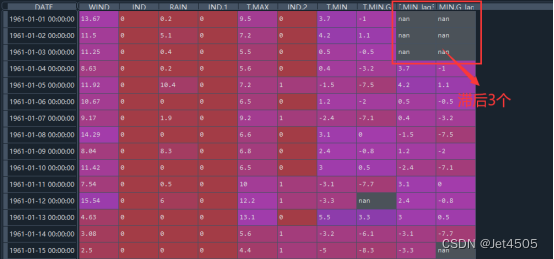
data['T.MIN.G_lag3'] = data['T.MIN.G'].shift(3)看看这个data变量变成了啥:
(3)删除NaN值
data = data.dropna()(4)拆分数据
train_size = int(len(data) * 0.8)
train, test = data[:train_size], data[train_size:]
X_train = train[['RAIN', 'T.MAX', 'T.MIN_lag3', 'T.MIN.G_lag3']]
y_train = train['WIND']
X_test = test[['RAIN', 'T.MAX', 'T.MIN_lag3', 'T.MIN.G_lag3']]
y_test = test['WIND']注意:训练集并没有WIND,所以这个算法的意思是:仅仅使用['RAIN', 'T.MAX', 'T.MIN_lag3', 'T.MIN.G_lag3'去构建一个模型,来预测WIND。个人认为不太行,忽略了WIND本身的时间序列变化的规律。
(5)建模和评估
#使用决策树回归进行拟合
tree = DecisionTreeRegressor()
tree.fit(X_train, y_train)
# 进行预测
train_pred = tree.predict(X_train)
test_pred = tree.predict(X_test)
# 5. 计算误差指标
train_mae = mean_absolute_error(y_train, train_pred)
train_mse = mean_squared_error(y_train, train_pred)
train_rmse = np.sqrt(train_mse)
train_mape = np.mean(np.abs((y_train - train_pred) / y_train)) * 100
test_mae = mean_absolute_error(y_test, test_pred)
test_mse = mean_squared_error(y_test, test_pred)
test_rmse = np.sqrt(test_mse)
test_mape = np.mean(np.abs((y_test - test_pred) / y_test)) * 100
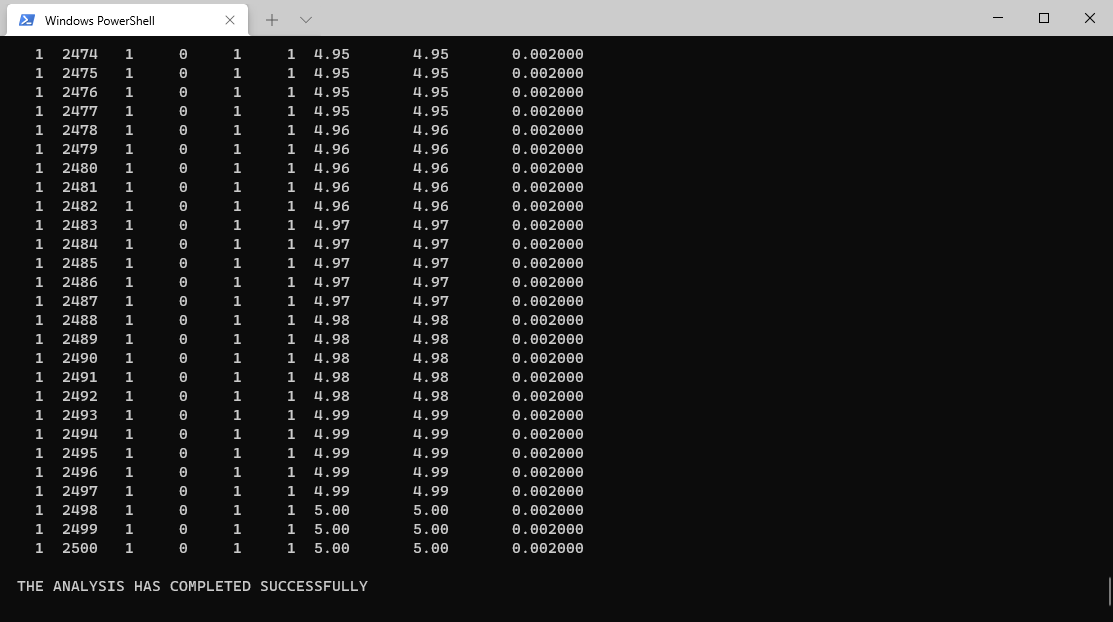
print((train_mae, train_mape, train_mse, train_rmse),
(test_mae, test_mape, test_mse, test_rmse))看看结果,意料之中,测试集的性能不太好:

主要是过拟合啦~
五、决策树回归(纳入WIND的单步滚动预测)
直接上代码:
# 导入必要的库
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error, mean_squared_error
import numpy as np
# 读取数据
uploaded_data = pd.read_csv('wind_dataset.csv')
#中位数填充
uploaded_data = uploaded_data.fillna(uploaded_data.median())
# 删除不必要的列
data = uploaded_data.drop(columns=['IND', 'IND.1', 'IND.2'])
# 将日期列转换为日期格式
data['DATE'] = pd.to_datetime(data['DATE'])
# 创建滞后期特征
lag_period = 6
for i in range(lag_period, 0, -1):
data[f'WIND_lag_{i}'] = data['WIND'].shift(lag_period - i + 1)
data['T.MIN_lag3'] = data['T.MIN'].shift(3)
data['T.MIN.G_lag3'] = data['T.MIN.G'].shift(3)
# 删除包含NaN的行
data = data.dropna().reset_index(drop=True)
# 重新划分训练集和验证集
train_data = data[data['DATE'] < data['DATE'].max() - pd.DateOffset(years=1)]
validation_data = data[data['DATE'] >= data['DATE'].max() - pd.DateOffset(years=1)]
# 定义新的特征和目标变量
features = ['RAIN', 'T.MAX', 'T.MIN_lag3', 'T.MIN.G_lag3'] + [f'WIND_lag_{i}' for i in range(1, lag_period + 1)]
X_train = train_data[features]
y_train = train_data['WIND']
X_validation = validation_data[features]
y_validation = validation_data['WIND']
# 初始化决策树模型,并使用网格搜索寻找最佳参数
tree_model = DecisionTreeRegressor()
param_grid = {
'max_depth': [None, 3, 5, 7, 9],
'min_samples_split': range(2, 11),
'min_samples_leaf': range(1, 11)
}
grid_search = GridSearchCV(tree_model, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
# 使用最佳参数初始化决策树模型并在训练集上训练
best_tree_model = DecisionTreeRegressor(**best_params)
best_tree_model.fit(X_train, y_train)
# 使用滚动预测的方式预测验证集上的风速
y_validation_pred = []
for i in range(len(X_validation)):
if i < 6:
pred = best_tree_model.predict([X_validation.iloc[i]])
else:
new_features = X_validation.iloc[i][0:4].values.tolist() + y_validation_pred[-6:]
pred = best_tree_model.predict([new_features])
y_validation_pred.append(pred[0])
y_validation_pred = np.array(y_validation_pred)
# 计算验证集上的误差
mae_validation = mean_absolute_error(y_validation, y_validation_pred)
mse_validation = mean_squared_error(y_validation, y_validation_pred)
rmse_validation = np.sqrt(mse_validation)
mape_validation = np.mean(np.abs((y_validation - y_validation_pred) / y_validation))
# 计算训练集上的误差
y_train_pred = best_tree_model.predict(X_train)
mae_train = mean_absolute_error(y_train, y_train_pred)
mse_train = mean_squared_error(y_train, y_train_pred)
rmse_train = np.sqrt(mse_train)
mape_train = np.mean(np.abs((y_train - y_train_pred) / y_train))
print((mae_validation, mse_validation, rmse_validation, mape_validation),
(mae_train, mse_train, rmse_train, mape_train))解读:
这里使用前6个WIND,加上1个RAIN、T.MAX、T.MIN(lag3)和T.MIN.G(lag3),一共10个特征去预测下一个WIND。
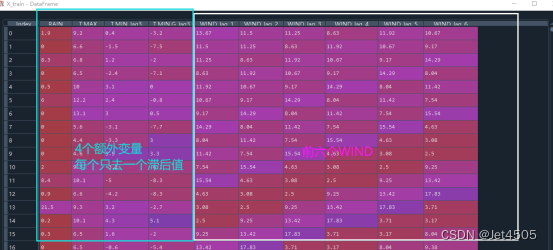
先看看结果:

似乎好一点,至少不是过拟合~
问题来了:RAIN、T.MAX、T.MIN(lag3)和T.MIN.G(lag3)为什么只要1个数值作训练集呢?哈哈哈,也有道理哦,大家自己试试了。
六、总结
(1)策略选择的多样性在多变量时间序列预测中十分常见,大多数情况下,经过一系列复杂操作后,其预测效果仍然无法超越单一变量的时间序列模型。但是,正因为其内在的多元性,也为创新性算法提供了发展空间:例如,如果你经过精细的调整和优化,使得多变量预测性能超过单因素模型,那么这就是值得称赞和骄傲的(灌水)
(2)多变量时间序列预测对数据的需求也非常高,有时候获得十年的序列数据已经相当不易,而要寻找与之匹配的外部解释性变量(同样需要十年的数据),难度更是加倍。
六、数据
链接:https://pan.baidu.com/s/1jnaiJHsPhY9lHDmZsKPuCw?pwd=pr13
提取码:pr13