目录
模块功能介绍
抽象文件存储引擎顶级接口
高性能单文件上传-sendfile零拷贝
为什么要分片上传
文件存储引擎模块讲解
文件模块具体实现讲解
项目演示博客
-
模块功能介绍
- 文件列表查询
- 聚簇索引和非聚簇索引
- 回表查询
- 最左前缀原则
- 覆盖索引
- 创建文件夹
- 文件重命名
- 文件删除
- 文件删除事件
- 文件秒传
- 抽象文件存储引擎
- 单文件上传
- sendfile零拷贝
- 分片上传
- 上传文件分片
- 查询已上传的分片列表
- 文件分片合并
- 单文件下载
- sendfile零拷贝
- 单文件预览
- sendfile零拷贝
- 查询文件夹树
- Map代替递归操作
- 文件转移
- 文件复制
- 文件搜索
- 半模糊匹配查询
- 文件搜索事件
- 查询用户的搜索历史
- 查询面包屑导航
- 对接FastDFS
- 对接OSS
- 分片上传事件
- 文件列表查询
-
抽象文件存储引擎顶级接口
- 为什么要抽象接口
- 因为本项目需要对接第三方的文件存储组件(OSS和FastDFS),同时需要开发本地的文件存储引擎组件,兼容代码耦合性以及可扩展性等等方面的考虑,需要在开发文件的上传下载等等功能之前,先抽象一套项目的存储引擎框架,之后的业务实现,在抽象框架的基础上去填充
- 抽离接口的设计
- 首先根据实际业务梳理文件存储以及读取的业务,交互流程如下图:

- 根据交互名称可以抽象出文件存储引擎的关系如下图:
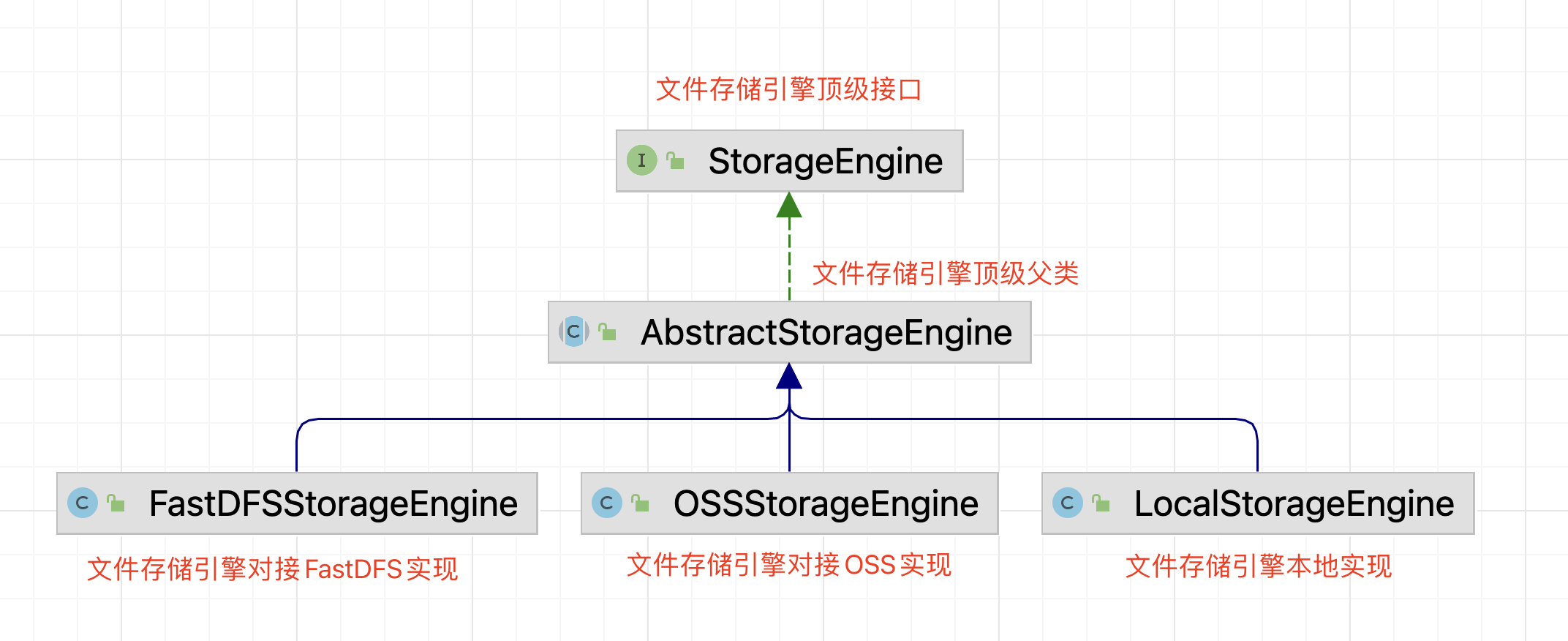
- 首先根据实际业务梳理文件存储以及读取的业务,交互流程如下图:
-
高性能单文件上传-sendfile零拷贝
- 零拷贝基础
- 所谓零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数
- 通常是说在IO读写过程中
- 目前市面上大部分的高性能软件,比如Nginx、Kafka等等,都有零拷贝的身影
- 通过一个传统IO读取文件,然后通过网络发送的例子来入手,详情看下图:
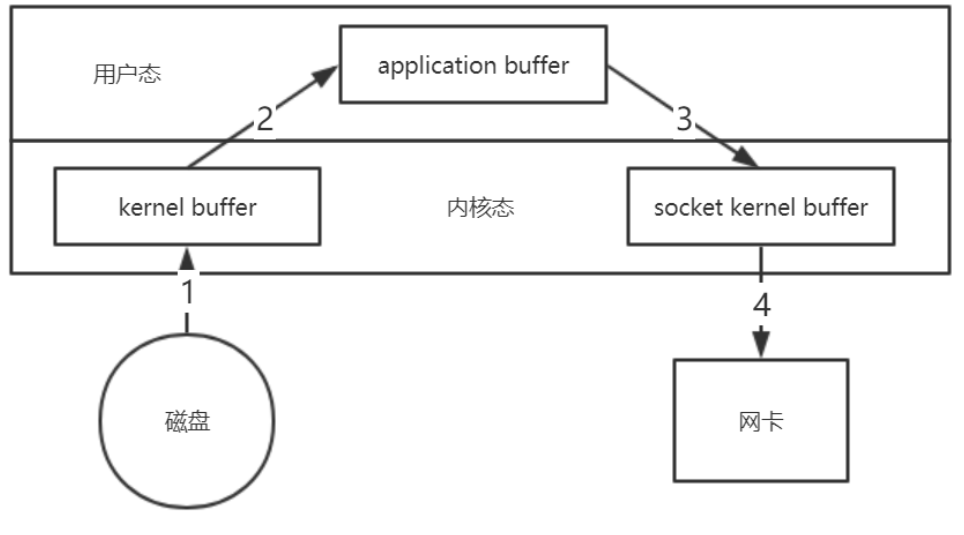
- 由上图可知,在一个简单的文件读取发送的过程中,会经历四次文件拷贝:
- 第一次:将磁盘文件,读取到操作系统内核缓冲区
- 第二次:将内核缓冲区的数据,copy到application应用程序的buffer
- 第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区)
- 第四次:将socket buffer的数据,copy到网络协议栈,由网卡进行网络传输
- 除此之外,实际的IO读写,需要进行IO中断,需要CPU响应中断(内核态到用户态转换),尽管引入DMA(Direct Memory Access,直接存储器访问)来接管CPU的中断请求,但四次copy的过程中,第二个和第三个数据副本的拷贝是不需要的
- 数据可以直接从读缓冲区传输到套接字缓冲区
- 所以,所谓的零拷贝,就是磁盘文件通过网络发送
- 磁盘数据通过DMA(Direct Memory Access,直接存储器访问)拷贝到内核态Buffer
- 之后不经过用户态,而是直接从内核态将数据拷贝到NIO Buffer(socket buffer)
- 零拷贝是需要底层的操作系统支持的,以Linux为例,Linux 2.4+ 内核通过sendfile系统调用,提供了零拷贝
- 除了减少数据拷贝外,Linux整个读文件 ==> 网络发送由一个sendfile调用完成,整个过程只有两次上下文切换,因此大大提高了性能
-
为什么要分片上传
- 分片上传简介
- 单一简单上传的缺点
- 传统的单一单线程文件上传在日常生活中还是很常见的,比如图片、歌曲等等小文件的上传场景
- 但是,该上传方式存在着以下问题:
- 文件特别大的时候,消耗的时间会很长
- 由于网络波动导致的上传失败,只能重新开始上传
- 不能支持文件上传过程中的暂停、继续、断点续传等操作
- 上传速度受带宽影响,会有上限
- ....
- 什么是分片上传
- 分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(称之为Chunk)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件
- 分片上传解决单一简单上传的问题
- 文件的上传过程中的网络崩溃,可以根据已上传的分片来支撑用户继续上传其他的文件分片,解决了不支持文件断点续传,暂停、继续上传的问题
- 将大文件分片,可以利用多线程的优势,在相同带宽的场景下并发上传分片,大大提升了上传的效率,节省了上传的时间
- 分片上传的设计方案
- 实际的上传设计流程如下图:

- 上图中的步骤,就很巧妙的将文件的秒传、利用文件分片上传支持的断点续传等等优化点串联在了一起,在用户使用方面有了很大的提升
- 实际的上传设计流程如下图:
-
文件存储引擎模块讲解
- context层
- 文件存储引擎存储物理文件的上下文实体(StoreFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:上传的文件名称,文件的总大小,文件的输入流信息,文件上传后的物理路径
- 删除物理文件的上下文实体信息(DeleteFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加1个属性:要删除的物理文件路径的集合
- 保存文件分片的上下文信息(StoreFileChunkContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加9个属性:文件名称,文件的唯一标识,文件的总大小,文件输入流,文件的真实存储路径,文件的总分片数,当前分片的下标,当前分片的大小,当前登录用户的ID
- 合并文件上下文对象(MergeFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加5个属性:文件名称,文件唯一标识,当前登录的用户ID,文件分片的真实存储路径集合,文件合并后的真实物理存储路径
- 文件读取的上下文实体信息(ReadFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:文件的真实存储路径,文件的输出流
- 文件存储引擎存储物理文件的上下文实体(StoreFileContext):
- 文件存储引擎模块的顶级接口(StorageEngine):
- 该接口定义所有需要向外暴露给业务层面的相关文件操作的功能
- 业务方只能调用该接口的方法,而不能直接使用具体的实现方案去做业务调用
- 方法包含:
- 存储物理文件
- 删除物理文件
- 存储物理文件的分片
- 合并文件分片
- 读取文件内容写入到输出流中
- 文件存储引擎模块公用抽象类(AbstractStorageEngine):
- 具体的文件存储实现方案的公用逻辑需要抽离到该类中
- 首先需要注入缓存管理器CacheManager,然后通过缓存管理器获取到服务端公用缓存cache
- 存储物理文件(store):
- 它只有1个参数:即StoreFileContext
- 首先需要进行参数校验(checkStoreFileContext)(校验上传物理文件的上下文信息):
- 它只有1个参数:即StoreFileContext
- 通过Assert的notBlank对文件名称判空,notNull对文件的总大小和文件的输入流信息(文件)判空
- 然后进行执行动作(doStore)(执行保存物理文件的动作):
- 它只有1个参数:即StoreFileContext
- 下沉到具体的子类去实现
- 删除物理文件(delete):
- 它只有1个参数:即DeleteFileContext
- 首先需要进行参数校验(checkDeleteFileContext)(校验删除物理文件的上下文信息):
- 它只有1个参数:即DeleteFileContext
- 通过Assert的notEmpty对要删除的文件路径列表判空
- 然后进行执行动作(doDelete)(执行删除物理文件的动作):
- 它只有1个参数:即DeleteFileContext
- 下沉到具体的子类去实现
- 存储物理文件的分片(storeChunk):
- 它只有1个参数:即StoreFileChunkContext
- 首先需要进行参数校验(checkStoreFileChunkContext)(校验保存文件分片的参数):
- 它只有1个参数:即StoreFileChunkContext
- 通过Assert的notBlank和notNull对Context上下文的信息判空
- 然后进行执行动作(doStoreChunk)(执行保存文件分片):
- 它只有1个参数:即StoreFileChunkContext
- 下沉到具体的子类去实现
- 合并文件分片(mergeFile):
- 它只有1个参数:即MergeFileContext
- 首先需要进行参数校验(checkMergeFileContext)(检查文件分片合并的上下文实体信息):
- 它只有1个参数:即MergeFileContext
- 通过Assert的notEmpty,notBlank和notNull对Context上下文的信息判空
- 然后进行执行动作(doMergeFile)(执行文件分片合并的动作):
- 它只有1个参数:即MergeFileContext
- 下沉到具体的子类去实现
- 读取文件内容写入到输出流中(realFile):
- 它只有1个参数:即ReadFileContext
- 首先需要进行参数校验(checkReadFileContext)(文件读取参数校验):
- 它只有1个参数:即ReadFileContext
- 通过Assert的notBlank和notNull对Context上下文的信息判空
- 然后进行执行动作(doReadFile)(读取文件内容并写入到输出流中):
- 它只有1个参数:即ReadFileContext
- 下沉到具体的子类去实现
- 本地的文件存储引擎实现方案(LocalStorageEngine):
- 执行删除物理文件的动作(doDelete):
- 它只有1个参数:即DeleteFileContext
- 首先从上下文Context中获取到要删除的物理文件路径的集合,并对其判空
- 然后进行对应for循环批量删除物理文件,每次循环调用FileUtils.forceDelete删除指定文件夹下所有文件和文件夹
- 执行保存物理文件的动作(doStore):
- 它只有1个参数:即StoreFileContext
- 首先获取到实际存放路径的前缀,即基础路径(basePath)
- 生成默认的文件存储路径,生成规则:当前登录用户的文件目录 + rpan
- 然后利用基础路径和Context中的上传的文件名称生成文件的存储路径(realFilePath)
- 生成规则:基础路径 + 年 + 月 + 日 + 随机的文件名称
- 然后需要从Context获取文件的输入流信息和文件的总大小,同时通过realFilePath创建File对象
- 然后将文件的输入流写入到文件中(writeStream2File):
- 它有3个参数:文件的输入流信息,目标File对象,文件的总大小
- 首先需要创建文件(createFile):
- 它只有1个参数:即目标File对象
- 首先通过目标File对象获取文件对象的父级文件夹目录对象,然后判断其是否存在
- 不存在则需要创建文件与文件夹,因为有的情况绝对路径并没有磁盘中对应的的文件夹与文件
- 同时需要借助getParentFile然后mkdirs,因为在创建过程中,如果直接用mkdirs方法,程序会把最后一个001.txt当作文件夹去创建,这个时候如果调用createNewFile方法去创建文件,程序会因为有了这个文件夹而失败,所以需要这个getParentFile方法来获取父目录,然后createNewFile
- 存在则直接createNewFile
- 然后创建RandomAccessFile以rw模式创建读写流(randomAccessFile)
- 然后通过RandomAccessFile来获取一个FileChannel实例(文件通道)(outputChannel)
- 然后从给定的inputStream中返回一个可读的字节channel(inputChannel)(ReadableByteChannel类型)
- 然后就可以进行文件复制了,通过transferFrom方法实现(使用底层的sendfile零拷贝来提高传输效率)
- 最后进行资源释放(close)
- 最后需要把文件的存储路径(realFilePath)封装进上下文Context,供后续服务使用
- 执行保存文件分片的动作(doStoreChunk):
- 它只有1个参数:即StoreFileChunkContext
- 首先获取到实际存放文件分片的路径的前缀,即基础路径(basePath)
- 生成默认的文件分片的存储路径前缀,有自定义的生成规则:new StringBuffer
- 然后利用基础路径和Context中的(文件的唯一标识和当前分片的下标)生成文件分片的存储路径(realFilePath)
- 生成规则:基础路径 + 年 + 月 + 日 + 唯一标识 + 随机的文件名称 + __,__ + 文件分片的下标
- 然后需要从Context获取文件的输入流信息和文件的总大小,同时通过realFilePath创建File对象
- 然后将文件的输入流写入到文件中(writeStream2File)
- 最后需要把文件的存储路径(realFilePath)封装进上下文Context,供后续服务使用
- 执行文件分片合并的动作(doMergeFile):
- 它只有1个参数:即MergeFileContext
- 首先获取到实际存放路径的前缀,即基础路径(basePath)
- 生成默认的文件存储路径,生成规则:当前登录用户的文件目录 + rpan
- 然后利用基础路径和Context中的上传的文件名称生成文件的存储路径(realFilePath)
- 生成规则:基础路径 + 年 + 月 + 日 + 随机的文件名称
- 然后通过realFilePath创建File对象,调用创建文件(createFile)方法
- 然后通过上下文Context获取到文件分片的真实存储路径集合chunkPaths
- 然后通过循环遍历文件分片的真实存储路径集合chunkPaths,进行追加写文件操作来完成合并(通过Files.write实现)
- 然后传入文件分片的真实存储路径集合chunkPaths来进行批量删除物理文件(合并完成后,分片文件自然不需要存在了)
- 最后需要把文件的存储路径(realFilePath)封装进上下文Context,供后续服务使用
- 读取文件内容并写入到输出流中(doReadFile):
- 它只有1个参数:即ReadFileContext
- 首先通过Context上下文获取到文件的真实存储路径RealPath
- 然后通过RealPath创建File对象file,然后通过file创建文件字节输入流,从Context上下文获取到文件的输出流
- 最后利用零拷贝技术读取文件内容并写入到文件的输出流中(writeFile2OutputStream):
- 它有3个参数:文件字节输入流,文件的输出流,File对象大小
- 首先通过文件字节输入流来获取一个FileChannel实例(文件通道)(fileChannel)
- 然后从给定的outputStream中返回一个可写的字节channel(writableByteChannel)(WritableByteChannel类型)
- 然后就可以进行文件复制了,通过transferTo方法实现(使用底层的sendfile零拷贝来提高传输效率)
- 最后进行资源释放(flush&close)
- 执行删除物理文件的动作(doDelete):
- FastDFS文件存储引擎的实现方案(FastDFSStorageEngine):
- 首先需要注入FastFileStorageClient 和 FastDFS文件存储引擎配置类config
- 执行删除物理文件的动作(doDelete):
- 它只有1个参数:即DeleteFileContext
- 首先从上下文Context中获取到要删除的物理文件路径的集合(realFilePathList),并对其判空
- 不为空则通过Stream流的forEach遍历对realFilePathList的每一个元素都进行deleteFile操作

- 执行保存物理文件的动作(doStore):
- 它只有1个参数:即StoreFileContext
- 首先从上下文Context中获取到 文件的输入流信息,文件的总大小,文件扩展名
- 然后从配置类config获取到 组名称
- 然后调用uploadFile实现文件上传,返回文件存储路径(StorePath对象),以此获取到文件上传后的物理路径,同时将其设置为上下文Context的属性信息

- 执行保存文件分片的动作(doStoreChunk):
- 它只有1个参数:即StoreFileChunkContext
- 直接抛出对应异常"FastDFS不支持分片上传的操作"
- 执行文件分片合并的动作(doMergeFile):
- 它只有1个参数:即MergeFileContext
- 直接抛出对应异常"FastDFS不支持分片上传的操作"
- 读取文件内容并写入到输出流中(doReadFile):
- 它只有1个参数:即ReadFileContext
- 首先通过Context上下文获取到文件的真实存储路径RealPath
- 然后通过substring对RealPath进行截取,截取出group与path
- 然后创建一个DownloadByteArray对象,用于处理文件下载操作
- 然后调用downloadFile实现文件整个下载,返回一个比特类型的数组bytes

- 然后从Context上下文获取到文件的输出流outputStream
- 通过outputStream进行写入bytes的操作
- 最后进行资源释放(flush&close)
- 对接阿里云OSS的文件存储引擎实现方案(OSSStorageEngine):
- 执行删除物理文件的动作(doDelete):
- 1、获取所有需要删除的文件存储路径
- 2、如果该存储路径是一个文件分片的路径,截取出对应的Object的name,然后取消文件分片的操作
- 3、如果是一个正常的文件存储路径,直接执行物理删除即可
- 它只有1个参数:即DeleteFileContext
- 首先从Context上下文获取到要删除的物理文件路径的集合realFilePathList
- 然后通过stream的forEach遍历集合realFilePathList
- 对于每个元素
- 如果是文件分片的存储路径,则通过判空过滤,分析URL参数,jsonObject转换得到对应的cacheKey,然后删除对应缓存,调用ossClient.abortMultipartUpload方法来取消分片上传事件(当一个分片上传事件被取消后,无法再使用这个uploadId做任何操作,已经上传的分片数据会被删除)
- 如果是普通文件,则直接调用deleteObject进行删除
- 执行保存物理文件的动作(doStore):
- 它只有1个参数:即StoreFileContext
- 首先通过Context上下文获取到上传的文件名称,然后通过substring对上传的文件名称进行截取,获取到文件的后缀fileSuffix
- 然后获取对象的完整名称 realPath
- 生成规则:年/月/日/UUID.fileSuffix
- 然后通过putObject方法上传单个文件(Object)
- 最后将realPath设置为上下文Context的属性信息
- 执行保存文件分片的动作(doStoreChunk):
- OSS文件分片上传的步骤:
- 1、初始化文件分片上传,获取一个全局唯一的uploadId
- 2、并发上传文件分片,每一个文件分片都需要带有初始化返回的uploadId
- 3、所有分片上传完成,触发文件分片合并的操作
- 难点:
- 1、我们的分片上传是在一个多线程并发环境下运行的,我们的程序需要保证我们的初始化分片上传的操作只有一个线程可以做
- 2、我们所有的文件分片都需要带有一个全局唯一的uploadId,该uploadId就需要放到一个线程的共享空间中
- 3、我们需要保证每一个文件分片都能够单独的去调用文件分片上传,而不是依赖于全局的uploadId
- 解决方案:
- 1、加锁,我们目前首先按照单体架构去考虑,使用JVM的锁去保证一个线程初始化文件分片上传,如果后续扩展成分布式的架构,需更换分布式锁
- 2、使用缓存,缓存分为本地缓存以及分布式缓存(比如Redis),我们由于当前是一个单体架构,可以考虑使用本地缓存,但是,后期的项目额度分布式架构升级之后,同样要升级我们的缓存为分布式缓存,与其后期升级,我们还是第一版本就支持分布式缓存比较好
- 3、我们要想把每一个文件的Key都能够通过文件的url来获取,就需要定义一种数据格式,支持我们添加附件数据,并且可以很方便的解析出来,我们的实现方案,可以参考网络请求的URL格式:fileRealPath?paramKey=paramValue
- 具体的实现逻辑:
- 1、校验文件分片数不得大于10000
- 2、获取缓存key
- 3、通过缓存key获取初始化后的实体对象,获取全局的uploadId和ObjectName
- 4、如果获取为空,直接初始化
- 5、执行文件分片上传的操作
- 6、上传完成后,将全局的参数封装成一个可识别的url,保存在上下文里面,用于业务的落库操作
- 它只有1个参数:即StoreFileChunkContext
- 首先通过Context上下文获取到文件的总分片数,然后进行校验(校验文件分片数不得大于10000)
- 校验失败则抛出对应异常
- 然后通过String.format格式化字符串(文件的唯一标识和当前登录用户的ID可变(从Context上下文获取))获取分片上传的缓存Key(cacheKey)
- 然后通过缓存管理器获取到服务端公用缓存cache,再通过get返回此缓存将指定键映射到的值(指定返回值将转换为的类型)(entity)
- entity类型为ChunkUploadEntity
- 该实体为文件分片上传初始化之后的全局信息载体
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 有2个属性:分片上传全局唯一的uploadId,文件分片上传的实体名称
- 然后对entity进行判空,为空则代表还未进行初始化,需要初始化文件分片上传(initChunkUpload)
- 初始化文件分片上传(initChunkUpload)
- 它有2个参数:文件名称,分片上传的缓存Key(cacheKey)
- 首先获取对象的完整名称 filePath
- 生成规则:年/月/日/UUID.fileSuffix
- 然后通过 config配置类提供的bucketName 和 对象的完整名称 filePath 创建InitiateMultipartUploadRequest对象request
- 然后通过request初始化一个分片上传事件(调用ossClient.initiateMultipartUpload方法返回OSS创建的全局唯一的uploadId)得到result
- 然后对result进行判空,为空则抛出对应异常"文件分片上传初始化失败"
- 然后需要创建一个ChunkUploadEntity对象entity
- 然后进行一一属性设置(文件分片上传的实体名称(对象的完整名称 filePath),分片上传全局唯一的uploadId(从result获取))
- 然后通过 分片上传的缓存Key(cacheKey) 将entity添加进缓存中
- 最后将entity返回出去
- 然后需要创建一个UploadPartRequest对象request,并进行一一属性设置(从config配置类,entity,Context上下文获取)
- 然后进行上传分片操作(调用ossClient.uploadPart方法上传分片数据),返回OSS的返回结果result
- 然后对result进行判空,为空则抛出对应异常"文件分片上传失败"
- 然后从OSS的返回结果result获取到PartETag
- 然后需要创建一个JSONObject(params),并进行拼装文件分片的url的操作(添加元素从PartETag,entity,Context上下文获取)(通过StringBuffer不断地append来实现),拼装结束后返回拼装完成的url(realPath)
- 最后将拼装完成的url(realPath)设置为Context上下文的文件的真实存储路径属性信息
- 执行文件分片合并的动作(doMergeFile):
- 1、获取缓存信息,拿到全局的uploadId
- 2、从上下文信息里面获取所有的分片的URL,解析出需要执行文件合并请求的参数
- 3、执行文件合并的请求
- 4、清除缓存
- 5、设置返回结果
- 它只有1个参数:即MergeFileContext
- 首先通过String.format格式化字符串(文件的唯一标识和当前登录用户的ID可变(从Context上下文获取))获取分片上传的缓存Key(cacheKey)
- 然后通过缓存管理器获取到服务端公用缓存cache,再通过get返回此缓存将指定键映射到的值(指定返回值将转换为的类型)(entity)
- entity类型为ChunkUploadEntity
- 然后对entity进行判空,为空则抛出对应异常
- 然后从Context上下文获取到文件分片的真实存储路径集合chunkPaths
- 每次上传分片之后,OSS的返回结果会包含一个PartETag
- PartETag将被保存到partETags中(partETags是PartETag的集合;PartETag由分片的ETag和分片号组成)
- 在执行完成分片上传操作时,需要提供所有有效的partETags
- OSS收到提交的partETags后,会逐一验证每个分片的有效性
- 当所有的数据分片验证通过后,OSS将把这些分片组合成一个完整的文件
- 所以需要创建一个partETags,然后通过chunkPaths转化生成partETags的信息参数(通过stream进行判空过滤,分析URL参数,jsonObject转换)
- 然后需要创建一个CompleteMultipartUploadRequest对象request,并进行一一属性构造
- 然后调用ossClient.completeMultipartUpload方法将所有分片合并成完整的文件,返回OSS的返回结果result
- 然后对result进行判空,为空则抛出对应异常
- 既然已经合并完成了,之前的分片上传的缓存Key(cacheKey)就可以移除了(evict)
- 最后将 entity的文件分片上传的实体名称 设置为 Context上下文的文件合并后的真实物理存储路径属性信息
- 读取文件内容并写入到输出流中(doReadFile):
- 它只有1个参数:即ReadFileContext
- 执行删除物理文件的动作(doDelete):
- context层
-
文件模块具体实现讲解
- 用户模块下共分有10层,分别是:
- constants层:存放文件模块常量类
- enums层:存放枚举类
- 文件夹表示枚举类(是非文件夹)(FolderFlagEnum)
- 文件删除标识枚举类(是否删除)(DelFlagEnum)
- entity层:存放实体类,与数据库中的属性值基本保持一致
- 物理文件信息表(RPanFile)
- 文件分片信息表(RPanFileChunk)
- 用户文件信息表(RPanUserFile)
- mapper层:对数据库进行数据持久化操作
- 针对用户文件信息表的数据库操作Mapper(RPanUserFileMapper)
- 针对物理文件信息表的数据库操作Mapper(RPanFileMapper)
- 针对文件分片信息表的数据库操作Mapper(RPanFileChunkMapper)
- service层:业务逻辑层,主要是针对具体的问题的操作
- 针对用户文件信息表的数据库操作Service(IUserFileService)
- 首先需要注入 消息发送实体producer,针对物理文件信息表的数据库操作Service(IFileService)iFileService,文件模块实体转化工具类fileConverter,针对文件分片信息表的数据库操作Service(IFileChunkService)iFileChunkService,文件存储引擎storageEngine
- 创建文件夹信息(createFolder):
- 它只有1个参数:即CreateFolderContext
- 通过保存用户文件的映射记录(saveUserFile)来实现
- 它有7个参数:父文件夹ID,文件名称,文件夹表示枚举类(是非文件夹),文件类型,真实文件ID,用户ID,文件大小展示字符
- 首先需要通过参数构建用户文件信息表(RPanUserFile)的实体对象entity
- 通过用户文件映射关系实体转化(assembleRPanFUserFile)实现
- 它有7个参数:父文件夹ID,文件名称,文件夹表示枚举类(是非文件夹),文件类型,真实文件ID,用户ID,文件大小展示字符
- 它要完成:1、构建并填充实体,2、处理文件命名一致的问题
- 首先new一个RPanUserFile实体对象entity
- 然后设置属性进行填充(FileId通过雪花算法id生成器生成,创建时间与更新时间通过new Date()来生成)
- 然后处理用户文件重复名称(handleDuplicateFilename)
- 它只有1个参数:即entity(RPanUserFile实体对象)
- 它要完成:如果同一文件夹下面有文件名称重复,则按照系统级规则重命名文件
- 首先通过entity获取文件名称,然后定义 没有后缀的文件名(newFilenameWithoutSuffix) 和 文件的后缀(newFilenameSuffix)
- 然后获取到文件名称中"."的位置(newFilenamePointPosition)
- 如果这个位置等于-1则说明这个文件名称它没有后缀
- 所以没有后缀的文件名(newFilenameWithoutSuffix)就等于这个文件名称,同时文件的后缀(newFilenameSuffix)就等于空字符串
- 如果不是这种情况的话,就要进行文件名的截取了
- 所以没有后缀的文件名(newFilenameWithoutSuffix)就等于substring从0截取到"."的位置(newFilenamePointPosition),同时文件的后缀(newFilenameSuffix)就等于文件名称replace掉"."的位置前面的字符串,replace成空字符串
- 然后根据 没有后缀的文件名 去同一父文件夹下面去查有没有同样名称的已存在的文件记录
- 查找同一父文件夹下面的同名文件数量(getDuplicateFilename)
- 它有2个参数:entity(RPanUserFile实体对象),没有后缀的文件名(newFilenameWithoutSuffix)
- 利用QueryWrapper的eq和likeRight进行查找比对
- 返回同名文件集合existRecords
- 如果没有则直接return
- 然后通过stream将文件集合existRecords的文件名称提取出来得到对应集合existFilenames
- 然后循环遍历existFilenames,进行拼装新文件名称(assembleNewFilename)
- 它有3个参数:没有后缀的文件名(newFilenameWithoutSuffix),同名文件数量,文件的后缀(newFilenameSuffix)
- 通过StringBuilder对没有后缀的文件名(newFilenameWithoutSuffix) append "(从1开始的自增数)"
- 最后返回处理好的新文件名称
- 然后将处理好的新文件名称设置进entity实体对象中
- 最后返回处理好的entity实体对象
- 通过用户文件映射关系实体转化(assembleRPanFUserFile)实现
- 然后调用save方法保存entity,保存失败则抛出对应异常
- 保存成功则返回文件记录ID(FileId)
- 查询用户的根文件夹信息(getUserRootFile):
- 它只有1个参数:即userId
- 通过QueryWrapper的eq在数据库中进行查询
- 查询用户的文件列表(getFileList):
- 它只有1个参数:即QueryFileListContext
- 通过Context的属性在数据库中查询对应的文件列表
- 更新文件名称(updateFilename):
- 1、校验更新文件名称的条件
- 2、执行更新文件名称的操作
- 它只有1个参数:即UpdateFilenameContext
- 首先校验更新文件名称的条件(checkUpdateFilenameCondition):
- 它只有1个参数:即UpdateFilenameContext
- 首先通过上下文对象Context获取到fileId
- 然后将fileId传入到getById中调用获取到entity(RPanUserFile实体对象),如果为空则说明该文件ID无效,抛出对应异常
- 然后从entity中获取UserId,并与上下文对象Context中的UserId(当前的登录用户ID)进行比对,不相等则说明当前登录用户没有修改该文件名称的权限,抛出对应异常
- 然后从entity中获取到原有的Filename,并与上下文对象Context中的NewFilename进行比对,相等则说明出现问题,抛出对应异常"请换一个新的文件名称来修改"
- 然后从entity中获取到ParentId,从上下文对象Context中获取到NewFilename,然后在数据库中进行对应的查询,查询成功则说明当前文件夹下面的子文件的名称与新名称重复,抛出对应异常"该文件名称已被占用"
- 最后条件检验全部通过则将获取到的entity封装进上下文对象Context中,供后续服务使用
- 然后执行更新文件名称的操作(doUpdateFilename):
- 它只有1个参数:即UpdateFilenameContext
- 首先通过上下文对象Context获取到entity
- 然后从上下文对象Context中获取到NewFilename和UserId,还有UpdateTime(new Date()),同时将其设置进entity中
- 最后通过传入entity调用updateById进行更新,调用失败则抛出对应异常"文件重命名失败"
- 批量删除用户文件(deleteFile):
- 1、校验删除的条件
- 2、执行批量删除的动作
- 3、发布批量删除文件的事件,给其他模块订阅使用
- 它只有1个参数:即DeleteFileContext
- 首先校验删除的条件(checkFileDeleteCondition):
- 它只有1个参数:即DeleteFileContext
- 首先进行文件ID的合法校验
- 首先通过上下文对象Context获取到fileIdList
- (查询校验)
- 然后通过传入fileIdList调用 listByIds 根据 ID 批量查询,返回一个 List(rPanUserFiles)
- 然后判断 rPanUserFiles 与 fileIdList 的size是否相等,不相等则说明存在不合法的文件记录,抛出对应异常
- (FileId校验)
- 然后通过stream将list(rPanUserFiles)转为set进行FileId数据去重,去重完成后记录size为oldSize
- 再addAll添加fileIdList,添加完成后记录size为newSize
- 因为set的去重特性,所以如果oldSize与newSize不相等则说明存在不合法的文件记录,抛出对应异常
- (UserId校验)
- 然后通过stream将list(rPanUserFiles)转为set进行UserId数据去重得到userIdSet
- 因为set的去重特性,所以如果去重后的userIdSet的size不等于1,则说明存在不合法的文件记录,抛出对应异常
- (用户拥有删除该文件的权限校验)
- 然后通过stream().findFirst()高效简洁获取到dbUserId
- 并与上下文对象Context中的UserId(当前的登录用户ID)进行比对,不相等则说明当前登录用户没有删除该文件的权限,抛出对应异常
- 然后执行批量删除的动作(doDeleteFile):
- 它只有1个参数:即DeleteFileContext
- 首先通过上下文对象Context获取到fileIdList
- 然后通过UpdateWrapper对fileId属于fileIdList的文件的删除标识进行修改,修改为已删除,同时更新更新时间
- 更新失败则抛出对应异常"文件删除失败"
- 最后发布批量删除文件的事件,给其他模块订阅使用(afterFileDelete):
- 它只有1个参数:即DeleteFileContext
- 首先通过上下文对象Context获取到 要删除的文件ID集合
- 然后通过 要删除的文件ID集合 创建一个 文件删除事件deleteFileEvent
- 然后通过注入的 消息发送实体producer 进行对应的发送消息操作
- 文件秒传功能(secUpload):
- 1、判断用户之前是否上传过该文件
- 2、如果上传过该文件,只需要生成一个该文件和当前用户在指定文件夹下面的关联关系即可
- 它只有1个参数:即SecUploadFileContext
- 首先通过上下文对象Context获取到UserId和文件的唯一标识(Identifier)
- 然后根据文件的唯一标识查询用户文件列表(getFileListByUserIdAndIdentifier):
- 它有2个参数:UserId和文件的唯一标识(Identifier)
- 首先需要创建一个 查询用户实际文件列表上下文实体对象(QueryRealFileListContext)context
- 然后将2参数设置为上下文对象Context的属性信息
- 最后通过 针对物理文件信息表的数据库操作Service(IFileService)iFileService 调用getFileList方法来根据条件查询用户的实际文件列表 并将查询结果返回出去
- 然后对其进行判空处理
- 不为空则代表用户之前上传过该文件,所以只需要生成一个该文件和当前用户在指定文件夹下面的关联关系即可(通过保存用户文件的映射记录(saveUserFile)来实现),并返回true,代表用户之前上传过相同文件并成功挂载了关联关系
- 为空则返回false,代表用户没有上传过该文件,请手动执行上传逻辑
- 单文件上传(upload):
- 1、上传文件并保存实体文件的记录
- 2、保存用户文件的关系记录
- 它只有1个参数:即FileUploadContext
- 首先上传文件并保存实体文件的记录(saveFile):
- 它只有1个参数:即FileUploadContext
- 为确保单一职责原则,需要委托给实体文件(物理文件信息表)的Service(saveFile)去完成该操作
- 首先在委托给实体文件的Service去完成该操作前,需要将这个Context对象转换成保存单文件的上下文实体FileSaveContext,通过converter的映射方法来完成转换
- 然后委托给实体文件的Service去完成该操作
- 最后需要将 保存单文件的上下文实体FileSaveContext 中的实体文件记录封装进 FileUploadContext 中,供后续服务使用
- 然后保存用户文件的关系记录,通过saveUserFile来实现,方法参数通过Context来获取
- 文件分片上传(chunkUpload):
- 1、上传实体文件
- 2、保存分片文件记录
- 3、校验是否全部分片上传完成
- 它只有1个参数:即FileChunkUploadContext
- 为确保单一职责原则,需要委托给实体文件(文件分片信息表)的Service(saveChunkFile)去完成该操作
- 首先在委托给实体文件的Service去完成该操作前,需要将这个Context对象转换成保存单文件的上下文实体FileChunkSaveContext,通过converter的映射方法来完成转换
- 然后委托给实体文件的Service去完成该操作
- 然后需要创建一个文件分片上传的响应实体(FileChunkUploadVO),通过文件分片保存的结果(判断是否所有的分片均没上传完成)来设置对应属性(是否需要合并文件)
- 最后返回文件分片上传的响应实体
- 查询用户已上传的分片列表(getUploadedChunks):
- 1、查询已上传的分片列表
- 2、封装返回实体
- 它只有1个参数:即QueryUploadedChunksContext
- 为确保单一职责原则,需要委托给实体文件(文件分片信息表)的mybatis操作去完成该操作
- 首先创建一个QueryWrapper,然后通过QueryWrapper的select,eq和gt在数据库中进行查询比对设置(当前登录的用户id和文件唯一标识)(从Context上下文信息获取)(还有目前时间)
- 同时通过listObjs查询分片编号字段,将查询字段放入list中(uploadedChunks)
- 然后需要创建一个查询用户已上传的文件分片列表返回实体(UploadedChunksVO),通过查询字段结果(uploadedChunks)来设置对应属性(已上传的分片编号列表)
- 最后返回查询用户已上传的文件分片列表返回实体
- 文件分片合并(mergeFile):
- 1、文件分片物理合并
- 2、保存文件实体记录
- 3、保存文件用户关系映射
- 它只有1个参数:即FileChunkMergeContext
- 首先需要合并文件分片并保存物理文件记录(mergeFileChunkAndSaveFile):
- 它只有1个参数:即FileChunkMergeContext
- 为确保单一职责原则,需要委托给实体文件(物理文件信息表)的Service(mergeFileChunkAndSaveFile)去完成该操作
- 首先在委托给实体文件的Service去完成该操作前,需要将这个Context对象转换成文件分片合并的上下文实体对象(FileChunkMergeAndSaveContext)(物理文件信息表Context),通过converter的映射方法来完成转换(fileChunkMergeAndSaveContext)
- 然后委托给实体文件的Service去完成该操作
- 最后需要将 fileChunkMergeAndSaveContext 中的物理文件记录封装进 FileChunkMergeContext 中,供后续服务使用
- 最后保存保存文件用户关系映射,通过saveUserFile来实现,方法参数通过Context来获取
- 文件下载(download):
- 1、参数校验:校验文件是否存在,文件是否属于该用户
- 2、校验该文件是不是一个文件夹
- 3、执行下载的动作
- 它只有1个参数:即FileDownloadContext
- 首先通过上下文Context提供的文件ID进行getById,查询获取到对应的用户文件信息表(文件记录)record(即校验文件是否存在)
- 然后校验用户的操作权限(checkOperatePermission):
- 它有2个参数:用户文件信息表(文件记录)record,当前登录的用户ID
- 需要文件记录必须存在和文件记录的创建者必须是该登录用户这2种条件
- 通过对record进行判空和对record的userId与上下文的userId(当前登录的用户ID)进行判等来实现
- 然后检查当前文件记录是不是一个文件夹(checkIsFolder):
- 它只有1个参数:即用户文件信息表(文件记录)record
- 通过对record进行判空和对record提供的是否是文件夹标识进行判等判断来实现
- 如果是一个文件夹,则抛出对应异常"文件夹暂不支持下载"
- 最后执行文件下载的动作(doDownload):
- 1、查询文件的真实存储路径
- 2、添加跨域的公共响应头
- 3、拼装下载文件的名称、长度等等响应信息
- 4、委托文件存储引擎去读取文件内容到响应的输出流中
- 它有2个参数:用户文件信息表(文件记录)record,请求响应对象
- 为确保单一职责原则,需要委托给实体文件(物理文件信息表)的mybatis操作去完成该操作
- 首先通过用户文件信息表(文件记录)record提供的真实文件ID进行getById,查询获取到对应的物理文件信息表realFileRecord
- 然后对其进行判空,不存在则抛出对应异常"当前的文件记录不存在"
- 然后添加公共的文件读取响应头(addCommonResponseHeader):
- 它有2个参数:请求响应对象,表示“不知道具体媒体类型、或媒体类型不重要”的二进制数据(MediaType.APPLICATION_OCTET_STREAM_VALUE)
- 首先调用reset()方法用于清除缓冲区中的任何数据,以及状态码和头部信息
- 然后添加跨域的响应头
- 然后新增String类型的值到名为Content-Type的Header(addHeader)
- 最后设置发送到客户端的响应的内容类型(setContentType)
- 然后添加文件下载的属性信息(addDownloadAttribute):
- 它有3个参数:请求响应对象,用户文件信息表(文件记录)record,物理文件信息表realFileRecord
- 首先获取到record中的文件名,然后传入addHeader进行调用
- 如新增Header出现问题,则抛出对应异常"文件下载失败"
- 最后通过物理文件信息表realFileRecord提供的文件实际大小fileSize设置文件内容长度
- 最后委托文件存储引擎去读取文件内容并写入到输出流中(realFile2OutputStream):
- 它有2个参数:文件物理路径,请求响应对象
- 首先需要创建一个文件读取的上下文实体信息(ReadFileContext)(context)
- 然后通过 文件物理路径 和 通过请求响应对象获取到的文件的输出流 对context进行属性设置
- context处理完成后,传入文件存储引擎storageEngine的读取文件内容写入到输出流中(realFile)方法完成调用
- 失败则抛出对应异常"文件下载失败"
- 文件下载 不校验用户是否是上传用户(downloadWithoutCheckUser):
- 它只有1个参数:即FileDownloadContext
- 首先通过上下文Context提供的文件ID进行getById,查询获取到对应的用户文件信息表(文件记录)record(即校验文件是否存在)
- 然后对record进行判空,为空则抛出对应异常"当前文件记录不存在"
- 然后检查当前文件记录是不是一个文件夹(checkIsFolder),如果是一个文件夹,则抛出对应异常"文件夹暂不支持下载"
- 最后执行文件下载的动作(doDownload)
- 文件预览(preview):
- 1、参数校验:校验文件是否存在,文件是否属于该用户
- 2、校验该文件是不是一个文件夹
- 3、执行预览的动作
- 它只有1个参数:即FilePreviewContext
- 首先通过上下文Context提供的文件ID进行getById,查询获取到对应的用户文件信息表(文件记录)record(即校验文件是否存在)
- 然后校验用户的操作权限(checkOperatePermission)
- 然后检查当前文件记录是不是一个文件夹(checkIsFolder),如果是一个文件夹,则抛出对应异常"文件夹暂不支持下载"
- 最后执行文件预览的动作(doPreview):
- 1、查询文件的真实存储路径
- 2、添加跨域的公共响应头
- 3、委托文件存储引擎去读取文件内容到响应的输出流中
- 它有2个参数:用户文件信息表(文件记录)record,请求响应对象
- 为确保单一职责原则,需要委托给实体文件(物理文件信息表)的mybatis操作去完成该操作
- 首先通过用户文件信息表(文件记录)record提供的真实文件ID进行getById,查询获取到对应的物理文件信息表realFileRecord
- 然后对其进行判空,不存在则抛出对应异常"当前的文件记录不存在"
- 然后添加公共的文件读取响应头(addCommonResponseHeader)
- 最后委托文件存储引擎去读取文件内容并写入到输出流中(realFile2OutputStream)
- 查询用户的文件夹树(getFolderTree):
- 1、查询出该用户的所有文件夹列表
- 2、在内存中拼装文件夹树
- 它只有1个参数:即QueryFolderTreeContext
- 首先从上下文Context获取到当前登录的用户ID
- 然后查询用户所有有效的文件夹信息(queryFolderRecords):
- 它只有1个参数:即当前登录的用户ID
- 首先创建一个QueryWrapper,然后通过QueryWrapper的eq在数据库中进行查询比对设置(userId,是否是文件夹标识,是否已删除标识)
- 最后通过list使用查询构造器查询,返回查询结果
- 将查询结果放入list中(folderRecords)(元素类型为RPanUserFile)
- 然后拼装文件夹树列表(assembleFolderTreeNodeVOList):
- 它只有1个参数:即查询用户所有有效的文件夹信息列表(folderRecords)
- 首先需要判断folderRecords是否为空,为空则直接返回空的列表
- 然后通过stream流的形式把列表中元素的类型通过converter的映射方法来完成转换并生成 文件夹树节点实体(FolderTreeNodeVO)列表mappedFolderTreeNodeVOList
- 然后因为这还是个平级的集合,需要转换成树状的集合,所以需要通过stream流对父文件ID进行分组操作,得到一个map(mappedFolderTreeNodeVOMap)(键为id,值为子节点集合)
- 然后循环遍历mappedFolderTreeNodeVOList的节点
- 循环中首先通过以此节点的id为键获取到mappedFolderTreeNodeVOMap中对应的值
- 因为经过分组,所以获取到的是它的子节点集合
- 然后对子节点集合判空,不为空则加入到此节点的子节点集合中
- 最后返回mappedFolderTreeNodeVOList中经过过滤(通过equals 0)的顶级父文件ID节点集合result
- 最后返回result即可
- 文件转移(transfer):
- 1、权限校验
- 2、执行工作
- 它只有1个参数:即TransferFileContext
- 首先进行文件转移的条件校验(checkTransferCondition):
- 1、目标文件必须是一个文件夹
- 2、选中的要转移的文件列表中不能含有目标文件夹以及其子文件夹
- 它只有1个参数:即TransferFileContext
- 首先从上下文Context获取到目标文件夹ID(targetParentId),同时通过getById获取到对应文件记录
- 然后调用checkIsFolder方法,检查当前文件记录是不是一个文件夹
- 如果不是一个文件夹,则抛出对应异常"目标文件不是一个文件夹"
- 然后从上下文Context获取到要转移的文件ID集合fileIdList
- 然后通过listByIds获取到要转移的文件实体集合(即要准备转移的记录)prepareRecords
- 然后设置上下文Context的 要转移的文件列表 属性
- 最后校验目标文件夹ID是否是要操作的文件记录的文件夹ID以及其子文件夹ID(checkIsChildFolder):
- 1、如果要操作的文件列表中没有文件夹,那就直接返回false
- 2、拼装文件夹ID以及所有子文件夹ID,判断存在即可
- 它有3个参数:要转移的文件实体集合(即要准备转移的记录)prepareRecords,目标文件夹ID(targetParentId),当前登录的用户ID
- 首先prepareRecords通过stream().filter进行过滤(通过equals是否是文件夹标识)获取到只包含文件夹的List(prepareRecords)
- 然后对其进行判空,不存在则直接返回false
- 然后通过当前登录的用户ID查询用户所有有效的文件夹信息(queryFolderRecords),得到folderRecords
- 然后通过stream流对上级文件夹ID(顶级文件夹为0)进行分组操作,得到一个map(folderRecordMap)(键为id,值为子文件夹集合)
- 然后创建一个不可用文件夹记录集合(unavailableFolderRecords),再添加(addAll)prepareRecords
- 然后通过Stream流的forEach遍历对prepareRecords的每一个元素(文件记录)都进行findAllChildFolderRecords操作(查找文件夹的所有子文件夹记录)
- 查找文件夹的所有子文件夹记录(findAllChildFolderRecords):
- 它有3个参数:不可用文件夹记录集合(unavailableFolderRecords),获取子文件夹集合需要的map(folderRecordMap),文件记录record
- 首先对record进行判空,为空则直接返回
- 然后通过文件记录record获取到文件记录ID,然后文件记录ID通过map(folderRecordMap)获取到子文件夹集合childFolderRecords
- 然后对其进行判空,不存在则直接返回
- 存在则加入进 不可用文件夹记录集合(unavailableFolderRecords) 中,然后对子文件夹集合childFolderRecords进行下一级的Stream流的forEach遍历(进行findAllChildFolderRecords操作)递归
- 然后通过stream流的形式把不可用文件夹记录集合(unavailableFolderRecords)中文件记录ID取出并生成列表unavailableFolderRecordIds
- 最后unavailableFolderRecordIds通过contains判断目标文件夹ID(targetParentId)是否在不可用文件夹记录集合中
- 返回判断值(返回true则代表在其中)
- 校验失败则抛出对应异常"目标文件夹ID不能是选中文件列表的文件夹ID或其子文件夹ID"
- 然后执行文件转移的动作(doTransfer):
- 它只有1个参数:即TransferFileContext
- 首先通过上下文Context获取到要转移的文件列表prepareRecords
- 然后通过Stream流的forEach遍历对prepareRecords的每一个元素(文件记录)都进行设置更新操作(上级文件夹ID(顶级文件夹为0),用户ID,创建人,创建时间,更新人,更新时间)
- 然后处理用户文件重复名称(handleDuplicateFilename)
- 最后调用updateBatchById进行批量更新,更新失败则抛出对应异常"文件转移失败"
- 文件复制(copy):
- 1、条件校验
- 2、执行动作
- 它只有1个参数:即CopyFileContext
- 首先进行文件复制的条件校验(checkCopyCondition):
- 1、目标文件必须是一个文件夹
- 2、选中的要复制的文件列表中不能含有目标文件夹以及其子文件夹
- 它只有1个参数:即CopyFileContext
- 首先从上下文Context获取到目标文件夹ID(targetParentId),同时通过getById获取到对应文件记录
- 然后调用checkIsFolder方法,检查当前文件记录是不是一个文件夹
- 如果不是一个文件夹,则抛出对应异常"目标文件不是一个文件夹"
- 然后从上下文Context获取到要复制的文件ID集合fileIdList
- 然后通过listByIds获取到要复制的文件实体集合(即要准备复制的记录)prepareRecords
- 然后设置上下文Context的 要复制的文件列表 属性
- 最后校验目标文件夹ID是否是要操作的文件记录的文件夹ID以及其子文件夹ID(checkIsChildFolder)
- 校验失败则抛出对应异常"目标文件夹ID不能是选中文件列表的文件夹ID或其子文件夹ID"
- 然后执行文件复制的动作(doCopy):
- 它只有1个参数:即CopyFileContext
- 首先通过上下文Context获取到要复制的文件列表prepareRecords
- 然后对其进行判空
- 不为空则需要创建一个新列表allRecords,然后通过Stream流的forEach遍历对prepareRecords的每一个元素进行拼装和加入新列表allRecords的操作(assembleCopyChildRecord)
- 这是因为文件列表prepareRecords可能包含文件夹,复制过程中还需要把文件夹结构和子文件夹结构都复制拼装一遍
- 拼装当前文件记录以及所有的子文件记录(assembleCopyChildRecord):
- 它有4个参数:新列表allRecords,文件记录record,目标文件夹ID(targetParentId),当前登录的用户ID
- 首先通过雪花算法id生成器生成新文件记录ID(newFileId)
- 然后从文件记录record获取到旧文件记录ID(oldFileId)
- 然后进行一一属性设置(ParentId(上级文件夹ID)设置为目标文件夹ID(targetParentId),文件记录ID设置为新文件记录ID(newFileId),用户ID,创建人,创建时间,更新人,更新时间)
- 然后处理用户文件重复名称(handleDuplicateFilename)
- 然后将处理好的record添加进新列表allRecords
- 然后调用checkIsFolder方法,检查当前文件记录是不是一个文件夹
- 如果当前文件记录是一个文件夹,则需要通过旧文件记录ID(oldFileId)调用findChildRecords去查找下一级的文件记录childRecords
- 查找下一级的文件记录(findChildRecords):
- 它只有1个参数:即ParentId(上级文件夹ID)
- 首先创建一个QueryWrapper,然后通过QueryWrapper的eq在数据库中进行查询比对设置(ParentId(上级文件夹ID)和标识未删除)
- 同时通过list使用查询构造器查询,将查询结果返回即可
- 然后对childRecords进行判空,为空则直接返回
- 不为空则对下一级的文件记录childRecords进行Stream流的forEach遍历(进行assembleCopyChildRecord操作)递归
- 最后调用saveBatch进行批量插入(allRecords),插入失败则抛出对应异常"文件复制失败"
- 文件列表搜索(search):
- 1、执行文件搜索
- 2、拼装文件的父文件夹名称
- 3、执行文件搜索后的后置动作
- 它只有1个参数:即FileSearchContext
- 首先执行文件搜索(doSearch):
- 它只有1个参数:即FileSearchContext
- 通过Mapper进行SQL语句查询实现
- 得到文件搜索列表result
- 然后拼装文件的父文件夹名称(fillParentFilename):
- 它只有1个参数:即文件搜索列表result
- 首先对文件搜索列表result进行判空,为空则直接返回
- 然后通过stream流的形式把列表中(父文件夹ID)取出并生成列表parentIdList
- 然后parentIdList通过listByIds查询出所有父文件夹记录列表parentRecords
- 然后将父文件夹记录列表parentRecords转化为map(fileId2filenameMap)(文件记录ID为键,文件名为值)
- 然后通过Stream流的forEach遍历对result的每一个元素进行设置父文件夹名称属性的操作(result的元素通过获取父文件夹ID,父文件夹ID再通过fileId2filenameMap获取到文件名)
- 之所以需要拼装文件的父文件夹名称,是因为文件搜索列表可能存在同名文件,所以需要通过父文件夹名称进行区分
- 然后执行文件搜索后的后置动作(afterSearch):
- 发布文件搜索的事件
- 它只有1个参数:即FileSearchContext
- 首先通过上下文对象Context获取到 搜索的关键字 和 当前登录的用户ID
- 然后通过 搜索的关键字 和 当前登录的用户ID 创建一个 用户搜索事件event
- 然后通过注入的 消息发送实体producer 进行对应的发送消息操作
- 最后将处理完成的result返回出去
- 获取面包屑列表(getBreadcrumbs):
- 1、获取用户所有文件夹信息
- 2、拼接需要用到的面包屑的列表
- 它只有1个参数:即QueryBreadcrumbsContext
- 首先通过queryFolderRecords查询用户所有有效的文件夹信息,得到folderRecords列表
- 然后需要把文件夹列表转化为面包屑列表,即通过Stream流的forEach遍历对folderRecords的每一个元素进行transfer转换,同时由List转换为Map(prepareBreadcrumbVOMap)(键为文件ID,值为面包屑列表本身(BreadcrumbVO))
- 首先定义一个面包屑列表展示实体(BreadcrumbVO)currentNode
- 然后从上下文Context获取到文件ID(fileId)
- 然后创建一个存储类型为 面包屑列表展示实体(BreadcrumbVO) 的LinkedList列表result
- 然后进行do-while循环进行拼接需要用到的面包屑的列表
- 首先通过 文件ID(fileId) 去 prepareBreadcrumbVOMap 获取到对应的面包屑列表展示实体,并赋值初始化给currentNode
- 然后对其进行判空,不为空则将其添加到result的头部,并重置 文件ID(fileId) 为该currentNode的父文件夹ID
- 循环会在遍历到根节点时停止(因为根节点的fileId为0,在map中无法查到,判断currentNode为空则停止循环)
- 这样周而复始,则形成所需的面包屑列表
- 最后将处理完成的result返回出去
- 针对物理文件信息表的数据库操作Service(IFileService)
- 首先需要注入 文件存储引擎storageEngine,消息发送实体producer,针对文件分片信息表的数据库操作Service(IFileChunkService)iFileChunkService
- 根据条件查询用户的实际文件列表(getFileList):
- 它只有1个参数:即QueryRealFileListContext
- 首先从上下文Context获取到 用户ID和文件的唯一标识
- 首先创建一个LambdaQueryWrapper,然后通过LambdaQueryWrapper的eq在数据库中进行查询比对设置(用户ID和文件的唯一标识)
- 同时通过list使用查询构造器查询,将查询结果返回即可
- 上传单文件并保存实体记录(saveFile):
- 它只有1个参数:即FileSaveContext
- 首先上传单文件(storeMultipartFile):
- 它只有1个参数:即FileSaveContext
- 该方法委托文件存储引擎实现
- 首先需要创建一个文件存储引擎存储物理文件的上下文实体(StoreFileContext)(storeFileContext)
- 然后通过FileSaveContext上下文提供的信息对storeFileContext进行属性设置
- storeFileContext处理完成后,传入文件存储引擎storageEngine的存储物理文件(store)方法完成调用
- 最后需要把文件上传后的物理路径(realPath)封装进上下文FileSaveContext,供后续服务使用
- 失败则抛出对应异常"文件上传失败"
- 然后从Context中获取保存实体记录所需的属性
- 然后保存实体记录(doSaveFile):
- 它有5个参数:文件名称,文件物理路径,文件实际大小,文件唯一标识,创建人
- 首先需要拼装文件实体对象(assembleRPanFile):
- 它有5个参数:文件名称,文件物理路径,文件实际大小,文件唯一标识,创建人
- 首先需要创建一个物理文件信息表(record)实体对象
- 然后通过传进来的参数进行一一属性设置
- 最后将设置完成的record返回出去,供后续服务使用
- 获取到返回的record后,然后调用mybatis的save方法进行保存
- 如果保存失败的话,因为已经完成上传单文件(storeMultipartFile)了,所以需要将上传文件给删掉
- 通过委托给存储引擎去删除,删除已上传的物理文件
- 删除过程中若出现异常,则创建对应错误日志事件
- 然后通过注入的 消息发送实体producer 进行对应的发送消息操作
- 最后因为没有相关上下文实体,所以需要直接返回record供后续服务使用
- 最后则将获取到的record封装进上下文对象Context中,供后续服务使用
- 合并物理文件并保存物理文件记录(mergeFileChunkAndSaveFile):
- 1、委托文件存储引擎合并文件分片
- 2、保存物理文件记录
- 它只有1个参数:即FileChunkMergeAndSaveContext
- 首先需要委托文件存储引擎合并文件分片(doMergeFileChunk):
- 1、查询文件分片的记录
- 2、根据文件分片的记录去合并物理文件
- 3、删除文件分片记录
- 4、封装合并文件的真实存储路径到上下文信息中
- 它只有1个参数:即FileChunkMergeAndSaveContext
- 首先创建一个QueryWrapper,然后通过QueryWrapper的eq和ge在数据库中进行查询比对设置(当前登录的用户id和文件唯一标识)(从Context上下文信息获取)(还有目前时间)
- 同时通过list使用查询构造器查询,将查询结果放入list中(chunkRecoredList)
- 然后进行判空,为空则抛出对应异常"该文件未找到分片记录"
- 然后通过stream流的形式把列表中(分片真实的存储路径的值(同时对分片编号排序))取出并生成列表realPathList
- 然后需要创建一个合并文件上下文对象(MergeFileContext)
- 然后通过Context上下文提供的信息进行一一属性设置
- 然后传入合并文件上下文对象(MergeFileContext)委托给文件存储引擎的mergeFile去完成该操作
- 然后需要把文件合并后的真实物理存储路径(realPath)封装进上下文FileChunkMergeAndSaveContext,供后续服务使用
- 合并过程出现异常则抛出"文件分片合并失败"
- 最后通过stream流的形式把列表中(主键id的值)取出并生成列表fileChunkRecordIdList,然后调用removeByIds删除文件分片记录
- 然后保存实体记录(doSaveFile),返回处理好的物理文件信息表record
- 最后则将获取到的record封装进上下文对象Context中,供后续服务使用
- 针对文件分片信息表的数据库操作Service(IFileChunkService)
- 文件分片保存(saveChunkFile):
- 它只有1个参数:即FileChunkSaveContext
- 需要添加对应分布式锁(通过@Lock 进行)
- 首先需要保存文件分片和记录(doSaveChunkFile):
- 它只有1个参数:即FileChunkSaveContext
- 首先需要委托文件存储引擎保存文件分片(doStoreFileChunk):
- 它只有1个参数:即FileChunkSaveContext
- 首先在委托给文件存储引擎的storeChunk去完成该操作前,需要将这个FileChunkSaveContext对象转换成保存文件分片的上下文信息(StoreFileChunkContext),通过converter的映射方法来完成转换
- 同时通过FileChunkSaveContext对象获取到文件输入流,并将其设置进保存文件分片的上下文信息(StoreFileChunkContext)中
- 然后委托给文件存储引擎的storeChunk去完成该操作
- 然后通过保存文件分片的上下文信息(StoreFileChunkContext)获取到文件分片的真实存储路径
- 最后需要把文件分片的真实存储路径(realPath)封装进上下文FileChunkSaveContext,供后续服务使用
- 然后保存文件分片记录(doSaveRecord):
- 它只有1个参数:即FileChunkSaveContext
- 首先需要创建一个文件分片信息表(RPanFileChunk)
- 然后通过Context上下文提供的信息进行一一属性设置
- 然后调用mybatis的save方法进行保存
- 保存失败则抛出对应异常"文件分片上传失败"
- 然后判断文件分片是否全部上传完成(doJudgeMergeFile):
- 它只有1个参数:即FileChunkSaveContext
- 首先通过QueryWrapper的eq在数据库中进行查询比对(当前登录的用户id和文件唯一标识)(从Context上下文信息获取)
- 然后计算上传了多少分片数
- 然后与Context上下文信息中的总体的分片数进行比对
- 相等则代表全部上传完成,设置Context上下文信息中的合并文件标识为1,代表需要合并文件
- 文件分片保存(saveChunkFile):
- 针对用户文件信息表的数据库操作Service(IUserFileService)
- controller层:负责请求转发,接收页面过来的参数,传给service处理,接到返回值,并再次传给页面
- 文件模块控制器(FileController):
- 首先注入service和converter
- list(查询文件列表):
- 它有2个参数:需要查询文件夹的ID(parentId),需要查询的文件类型(fileTypes)
- 首先通过IdUtil对parentId进行解密,获取到realParentId
- 然后定义一个Integer类型的文件类型列表fileTypeArray
- 然后判断是不是要查询所有类型的文件,不是的话,fileTypes需要通过Splitter分割字符串再转化为Integer类型的List
- 然后new一个查询文件列表上下文实体(QueryFileListContext),并设置父文件夹ID(realParentId),文件类型的集合(fileTypeArray),当前的登录用户ID和文件的删除标识等属性
- 最后调用service的getFileList方法把这个context给它传进去完成调用,返回list的vo对象和相关状态码
- createFolder(创建文件夹):
- 它只有1个参数:即CreateFolderPO
- 首先在调用service的createFolder方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的createFolder方法把这个context给它传进去完成调用,返回一个新创建的fileId
- 最后把这id加密下,返回给客户端去使用,返回相关状态码
- updateFilename(文件重命名):
- 它只有1个参数:即UpdateFilenamePO
- 首先在调用service的updateFilename方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的updateFilename方法把这个context给它传进去完成调用,返回相关状态码即可
- deleteFile(批量删除文件):
- 它只有1个参数:即DeleteFilePO
- 首先在调用service的deleteFile方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 同时从PO获取到要删除的文件ID并需要通过Splitter分割字符串并解密ID再转化为Long类型的List(fileIdList)
- 然后将fileIdList封装进上下文对象context中
- 最后调用service的deleteFile方法把这个context给它传进去完成调用,返回相关状态码即可
- secUpload(文件秒传):
- 它只有1个参数:即SecUploadFilePO
- 首先在调用service的secUpload方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的secUpload方法把这个context给它传进去完成调用,返回一个布尔标识,标识前端传过来的唯一标识在后端能不能找到
- 如果找到并且成功挂载上了关联关系,那文件秒传的功能就执行完毕了,返回相关状态码即可
- 如果失败就返回相关提示"文件唯一标识不存在,请手动执行文件上传"
- upload(单文件上传):
- 它只有1个参数:即FileUploadPO
- 首先在调用service的upload方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的upload方法把这个context给它传进去完成调用,返回相关状态码即可
- chunkUpload(文件分片上传):
- 它只有1个参数:即FileChunkUploadPO
- 首先在调用service的chunkUpload方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的chunkUpload方法把这个context给它传进去完成调用,返回文件分片上传的响应实体,返回相关状态码
- getUploadedChunks(查询已经上传的文件分片列表):
- 它只有1个参数:即QueryUploadedChunksPO
- 首先在调用service的getUploadedChunks方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的getUploadedChunks方法把这个context给它传进去完成调用,返回查询用户已上传的文件分片列表返回实体,返回相关状态码
- mergeFile(文件分片合并):
- 它只有1个参数:即FileChunkMergePO
- 首先在调用service的mergeFile方法前,需要将这个po对象转换成上下文对象,通过converter的映射方法来完成转换
- 转换了实体之后,调用service的mergeFile方法把这个context给它传进去完成调用,返回相关状态码即可
- download(文件下载):
- 它有2个参数:文件ID,请求响应对象
- 首先需要创建一个文件下载的上下文实体对象(FileDownloadContext)
- 然后通过参数提供的信息进行一一属性设置
- 最后调用service的download方法把这个context给它传进去完成调用
- preview(文件预览):
- 它有2个参数:文件ID,请求响应对象
- 首先需要创建一个文件预览的上下文实体对象(FilePreviewContext)
- 然后通过参数提供的信息进行一一属性设置
- 最后调用service的preview方法把这个context给它传进去完成调用
- getFolderTree(查询文件夹树):
- 没有参数
- 首先需要创建一个查询文件夹树的上下文实体信息(QueryFolderTreeContext)
- 然后通过用户ID存储工具类进行属性设置
- 最后调用service的getFolderTree方法把这个context给它传进去完成调用,返回顶级父文件ID节点集合result,返回相关状态码
- transfer(文件转移):
- 它只有1个参数:即TransferFilePO
- 首先通过TransferFilePO获取到 要转移的文件ID集合(fileIds) 和 要转移到的目标文件夹的ID(targetParentId)
- 然后需要通过Splitter分割字符串并解密ID再转化为Long类型的List(fileIdList)
- 然后需要创建一个文件转移操作上下文实体对象(TransferFileContext)
- 然后通过 fileIdList,要转移到的目标文件夹的ID(targetParentId),用户ID存储工具类获取当前线程的用户ID 进行Context一一属性设置
- 最后调用service的transfer方法把这个context给它传进去完成调用,返回相关状态码即可
- copy(文件复制):
- 它只有1个参数:即CopyFilePO
- 首先通过CopyFilePO获取到 要复制的文件ID集合(fileIds) 和 要复制到的目标文件夹的ID(targetParentId)
- 然后需要通过Splitter分割字符串并解密ID再转化为Long类型的List(fileIdList)
- 然后需要创建一个文件复制操作上下文实体对象(CopyFileContext)
- 然后通过 fileIdList,要复制到的目标文件夹的ID(targetParentId),用户ID存储工具类获取当前线程的用户ID 进行Context一一属性设置
- 最后调用service的copy方法把这个context给它传进去完成调用,返回相关状态码即可
- search(文件搜索):
- 它只有1个参数:即FileSearchPO
- 首先需要创建一个搜索文件上下文实体信息(FileSearchContext)
- 然后通过 PO获取到搜索的关键字,用户ID存储工具类获取当前线程的用户ID 进行Context一一属性设置
- 然后通过PO获取到文件类型fileTypes
- 然后对文件类型fileTypes进行判空,不为空再判断是否存在对文件类型的限制
- 存在则fileTypes需要通过Splitter分割字符串再转化为Integer类型的List(fileTypeArray)
- 然后将fileTypeArray设置为上下文Context的(搜索的文件类型集合)属性
- 最后调用service的search方法把这个context给它传进去完成调用,返回处理完成的文件搜索列表result,返回相关状态码
- getBreadcrumbs(查询面包屑列表):
- 它只有1个参数:即文件ID(fileId)
- 首先需要创建一个搜索文件面包屑列表的上下文信息实体(QueryBreadcrumbsContext)
- 然后通过 雪花算法id生成器解密ID(fileId),用户ID存储工具类获取当前线程的用户ID 进行Context一一属性设置
- 最后调用service的getBreadcrumbs方法把这个context给它传进去完成调用,返回处理完成的查询面包屑列表result,返回相关状态码
- 文件模块控制器(FileController):
- po层:controller层向外接参的实体对象
- 创建文件夹参数实体(CreateFolderPO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:加密的父文件夹ID,文件夹名称
- 最后利用@NotBlank 进行非空校验
- 文件重命名参数对象(UpdateFilenamePO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:更新的文件ID,新的文件名称
- 最后利用@NotBlank 进行非空校验
- 批量删除文件入参对象实体(DeleteFilePO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加1个属性:要删除的文件ID(多个使用公用的分隔符分割)
- 最后利用@NotBlank 进行非空校验
- 秒传文件接口参数对象实体(SecUploadFilePO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加3个属性:秒传的父文件夹ID,文件名称,文件的唯一标识
- 最后利用@NotBlank 进行非空校验
- 单文件上传参数实体对象(FileUploadPO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加5个属性:文件名称,文件的唯一标识,文件的总大小,文件的父文件夹ID,文件实体
- 最后利用@NotBlank 进行非空校验
- 文件分片上传参数实体(FileChunkUploadPO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加7个属性:文件名称,文件唯一标识,总体的分片数,当前分片的下标,当前分片的大小,文件总大小,分片文件实体
- 最后利用@NotBlank @NotNull 进行非空校验
- 查询用户已上传分片列表的参数实体(QueryUploadedChunksPO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加1个属性:文件的唯一标识
- 最后利用@NotBlank 进行非空校验
- 文件分片合并参数对象(FileChunkMergePO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:文件名称,文件唯一标识,文件总大小,文件的父文件夹ID
- 最后利用@NotBlank @NotNull 进行非空校验
- 文件转移参数实体对象(TransferFilePO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:要转移的文件ID集合(多个使用公用分隔符隔开),要转移到的目标文件夹的ID
- 最后利用@NotBlank 进行非空校验
- 文件复制参数实体对象(CopyFilePO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:要复制的文件ID集合(多个使用公用分隔符隔开),要转移到的目标文件夹的ID
- 最后利用@NotBlank 进行非空校验
- 文件搜索参数实体(FileSearchPO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:搜索的关键字,文件类型(多个文件类型使用公用分隔符拼接)
- 最后利用@NotBlank 进行非空校验
- 创建文件夹参数实体(CreateFolderPO):
- context层:上下文的实体对象
- 创建文件夹上下文实体(CreateFolderContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加3个属性:父文件夹ID,用户ID,文件夹名称
- 查询文件列表上下文实体(QueryFileListContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加5个属性:父文件夹ID,文件类型的集合,当前的登录用户ID,文件的删除标识,文件ID集合
- 文件重命名参数上下文对象(UpdateFilenameContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:要更新的文件ID,新的文件名称,当前的登录用户ID,要更新的文件记录实体
- 批量删除文件上下文实体对象(DeleteFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:要删除的文件ID集合,当前的登录用户ID
- 秒传文件接口上下文对象实体(SecUploadFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:文件的父ID,文件名称,文件的唯一标识,当前登录用户的ID
- 查询用户实际文件列表上下文实体对象(QueryRealFileListContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:用户ID,文件的唯一标识
- 单文件上传的上下文实体(FileUploadContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加7个属性:文件名称,文件唯一标识,文件大小,文件的父文件夹ID,要上传的文件实体,当前登录的用户ID,实体文件记录
- 保存单文件的上下文实体(FileSaveContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加7个属性:文件名称,文件唯一标识,文件大小,要上传的文件实体,当前登录的用户ID,实体文件记录,文件上传的物理路径
- 文件分片上传上下文实体(FileChunkUploadContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加8个属性:文件名称,文件唯一标识,总体的分片数,当前分片下标(从1开始),当前分片的大小,文件的总大小,文件实体,当前登录的用户ID
- 文件分片保存的上下文实体信息(FileChunkSaveContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加10个属性:文件名称,文件唯一标识,总体的分片数,当前分片下标(从1开始),当前分片的大小,文件的总大小,文件实体,当前登录的用户ID,文件合并标识,文件分片的真实存储路径
- 查询用户已上传的分片列表的上下文信息实体(QueryUploadedChunksContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:文件的唯一标识,当前登录的用户ID
- 文件分片合并的上下文实体对象(FileChunkMergeContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加6个属性:文件名称,文件唯一标识,文件总大小,文件的父文件夹ID,当前登录的用户ID,物理文件记录
- 文件分片合并的上下文实体对象(FileChunkMergeAndSaveContext)(物理文件信息表Context):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加7个属性:文件名称,文件唯一标识,文件总大小,文件的父文件夹ID,当前登录的用户ID,物理文件记录,文件合并之后存储的真实的物理路径
- 文件下载的上下文实体对象(FileDownloadContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加3个属性:文件ID,请求响应对象,当前登录的用户ID
- 文件预览的上下文实体对象(FilePreviewContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加3个属性:文件ID,请求响应对象,当前登录的用户ID
- 查询文件夹树的上下文实体信息(QueryFolderTreeContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加1个属性:当前登录的用户ID
- 文件转移操作上下文实体对象(TransferFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:要转移的文件ID集合,目标文件夹ID,当前登录的用户ID,要转移的文件列表
- 文件复制操作上下文实体对象(CopyFileContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:要复制的文件ID集合,目标文件夹ID,当前登录的用户ID,要复制的文件列表
- 搜索文件上下文实体信息(FileSearchContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加3个属性:搜索的关键字,搜索的文件类型集合,当前登录的用户ID
- 搜索文件面包屑列表的上下文信息实体(QueryBreadcrumbsContext):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加2个属性:文件ID,当前登录的用户ID
- 创建文件夹上下文实体(CreateFolderContext):
- vo层:视图对象,用于展示层,把某个指定页面的所有数据封装起来,方便前端获取数据
- 用户查询文件列表相应实体(RPanUserFileVO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加7个属性:文件ID,父文件夹ID,文件名称,文件大小描述,文件夹标识(0 否 1 是),文件类型(1 普通文件 2 压缩文件 3 excel 4 word 5 pdf 6 txt 7 图片 8 音频 9 视频 10 ppt 11 源码文件 12 csv),文件更新时间
- 同时通过@JsonSerialize 自定义序列化类对ID进行自动加密
- 文件分片上传的响应实体(FileChunkUploadVO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加1个属性:是否需要合并文件标识(0 不需要 1 需要)(默认为0)
- 查询用户已上传的文件分片列表返回实体(UploadedChunksVO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加1个属性:已上传的分片编号列表
- 文件夹树节点实体(FolderTreeNodeVO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加4个属性:文件夹名称,文件ID,父文件ID,子节点集合
- 用户搜索文件列表相应实体(FileSearchResultVO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加8个属性:文件ID,父文件夹ID,父文件夹名称,文件名称,文件大小描述,文件夹标识(0 否 1 是),文件类型,文件更新时间
- 面包屑列表展示实体(BreadcrumbVO):
- 首先它要实现Serializable序列化接口
- 然后给它添加序列化UID这一属性
- 再添加3个属性:文件ID,父文件夹ID,文件夹名称
- 还有1个方法:transfer(实体转换方法)(将用户文件信息表(RPanUserFile)转为面包屑列表展示实体(BreadcrumbVO))
- 用户查询文件列表相应实体(RPanUserFileVO):
- converter层:实体对象转换器
- 文件模块实体转化工具类(FileConverter):
- 首先利用MapStruct的@Mapper 注解标记这个接口作为一个映射接口,并且是编译时MapStruct处理器的入口,简化不同的Java Bean之间映射的处理
- 同时指定@Mapper 注解的componentModel属性为spring,这样生成的实现类上面会自动添加一个@Component注解,可以通过Spring的 @Autowired 方式进行注入
- 然后添加若干映射方法,MapStruct会自动生成转换
- 文件模块实体转化工具类(FileConverter):