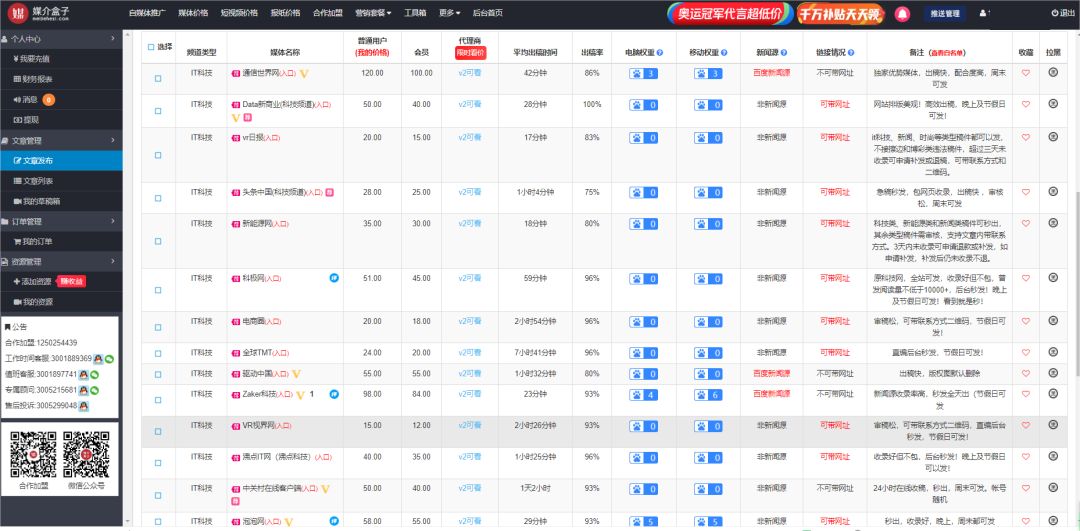
这篇文章基于本文的发现
一、说明
关于注意力机制,关于transformer等存在大量的研究和尝试,这些研究有的被沙汰,有的被采用并发扬光大,本篇对可变卷积、可变局部注意力机制和全局注意力机制做详细解释。因为这些模型规模巨大,环节琐碎,需要一点点积累才能掌握全局。本文不力求面向宏大叙事,而是就注意力机制的变革进行有限的注解。
二、文中术语注解
术语和缩写:
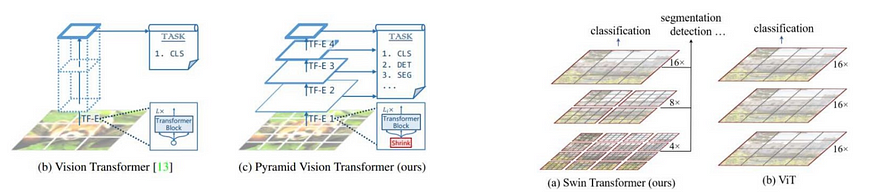
- Pyramid Vision Transformer (PVT)
- Vision Transformer (ViT)
- Deformable Attention Transformer (DAT)
- Deformable convolution network (DCN)
- Region of Interest (RoI)
术语的注解:
三、相关历史综述
近年来,采用注意力机制的变形金刚在自然语言处理领域表现出了显著的表现,成为自然语言领域事实上的标准。在图像处理领域,使用卷积机制的CNN是事实上的标准,但从那时起,人们一直试图将Transformer纳入图像处理领域。
最初,设计了与CNN相结合的模型,但是在宣布了视觉变压器(ViT)之后,它消除了CNN并且仅使用变压器构建,仅基于该变压器的模型也已用于图像处理和识别领域。此外,众所周知,它将图像视为由一系列图像补丁组成的“序列数据”。
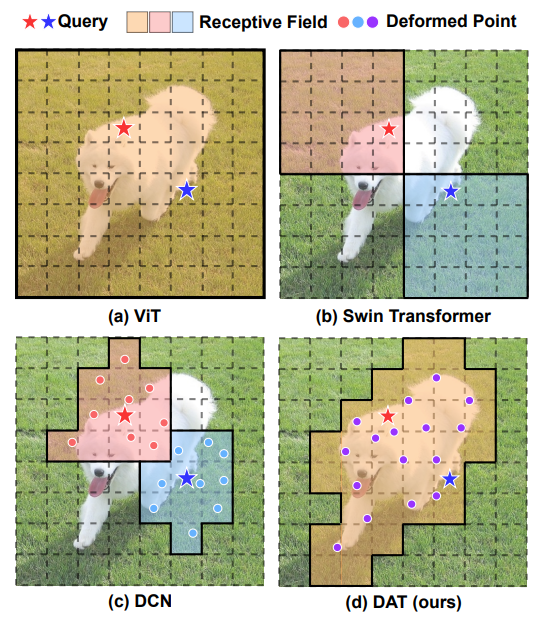
像ViT一样使用变压器进行图像处理的优势在于其广泛的感受野。通过抑制比CNN等更广泛的区域,可以获得更好的特征值。
另一方面,ViT只是一个重新利用的变形金刚,也被称为密集变形金刚,其主要缺点是内存需求增加,计算成本高,学习收敛延迟和过度学习的危险。由于得到了所有图像的关系,计算成本巨大,并且不存在具有深度关系的近像素等归纳偏差,只有通过大量数据学习才能超越CNN。存在无法达到准确性的问题。另一个问题是不相关的位置可能会影响要素。
因此,金字塔视觉变压器(PVT),也称为稀疏变压器,和SwinTransformer是作为ViT的改进而创建的。这些模型通过关注图像中已在一定程度上缩小的区域来提高记忆效率和计算效率。与ViT相比,性能有所提高,但另一方面,由于图像中的区域缩小了,因此有可能丢失从原始区域获得的广泛关系信息。
另一方面,Swin不会计算整个图像的自我注意,而是将图像划分为小区域并在小区域内执行自我注意。与ViT相比,Swin在ImageNet-1k中的准确性有所提高,但它只能在很小的区域内获取关系,并且可能会丢失全局关系的信息。在像Swin这样手动确定的自我注意的接受领域,重要信息可能会被遗漏。
但是,手动构建的注意力范围(例如 Swin 变压器)可能无法在效率方面进行优化。也可能在使用不必要的键/值关系时删除了重要的键/值关系。理想情况下,每个输入图像的注意力范围应该是可自由变换的,同时只允许使用重要的区域。
提出了可变形注意力转换器(DAT)来解决这个问题。它是一个通用的主干模型,对图像分类和密集预测任务都具有可变形的注意力。
Transformer模型通过消除重复和卷积,或者依靠自我注意,彻底改变了注意力的实现。这允许模型适应输入数据并提高其性能。这次提出的可变形注意力转换器(DAT)使用可变形自注意力,在缩小PVT和Swin变压器等区域时,可以选择具有更多影响关系的区域。
这是一个改进的模型,它利用可变形的自我注意,以便在限制自我注意范围时可以选择更多相关区域。换句话说,它是一个可以更灵活地控制自我注意范围的模型。因此,它以依赖于数据的方式为每个查询学习不同的变形点。因此,与传统的图像处理模型相比,它成功地提高了效率和性能。因此,由于这个原因,该模型已被用于各种应用,包括图像分类和密集预测任务。
因此,它在类分类、对象检测和分割任务中实现了 SOTA,达到了超过 Swin 的精度。
四、可变形卷积网络的简短概述
如前所述,视觉识别任务,如物体检测或图像分类,经常要处理物体比例、姿势、视点和失真。以前的方法虽然在某种程度上有效,但也有固有的缺点。
让我们看一下两种流行的方法:
1. 一种策略是通过增强和增加模型容量来增强数据多样性。虽然这可能会产生更细微的模型,但它伴随着对大型数据集和潜在庞大模型的需求。
2. 另一种方法涉及利用变形不变特征和算法,如 SIFT 和最大池化。然而,这些通常是手工制作的,限制了它们的通用性。
此外,传统的卷积神经网络(CNN)由于其几何结构,可能容易受到几何变形的影响。它们在固定位置执行操作,并且所有层共享相同的感受野形状和大小,这可能并不总是适合对象语义识别等任务。
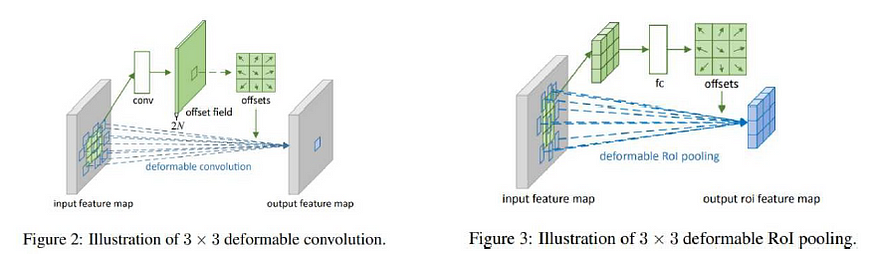
为了克服这些挑战,提出了可变形卷积网络(DCN)作为涉及可变形卷积,感兴趣区域(RoI)池化的新解决方案。
为了更好地理解可变形注意力转换器,我们先来谈谈可变形卷积网络。后者是基于“感受野应该根据物体的规模和形状进行调整”的想法。
五、可变形卷积和 RoI 池化
该解决方案将可调节的 2D 偏移引入标准网格状卷积中,并在 RoI 池中对箱位置进行可学习的偏移。这种灵活性使模型能够处理图像中更多形状和大小的对象。
而普通卷积试图将 y (p0) 计算为:
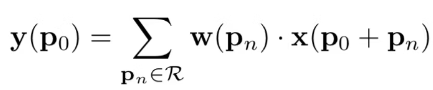
在可变形卷积中,偏移量添加为

将DCN中完成的工作简单应用到变压器中需要很高的内存和计算成本,因此不切实际。
5.1 DAT 及其周边地区
可变形注意力转换器(DAT)可以作为图像分类、目标检测和分割任务的核心网络,为图像识别领域带来灵活性和效率。
DAT的关键组成部分是可变形注意力(DA)。它通过关注特征图中的重要区域来有效地对令牌之间的关系进行建模。注意力区域是使用从偏移网络的查询中学习的可变形采样点获得的。
与学习特征图中不同像素的不同区域的可变形卷积网络 (DCN) 不同,DAT 学习与查询无关的区域组。最近的研究表明,对于不同的查询,全局注意力会导致几乎相同的注意力模式,从而可以在重要区域集中键/值,并提高计算效率。
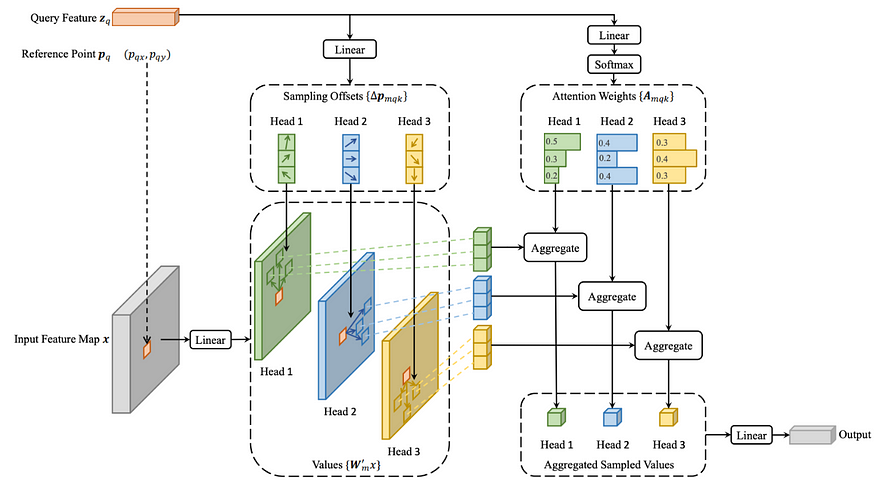
5.2 克服高昂的计算成本
但是,尽管有这些好处,计算成本可能很高。为了解决这个问题,提出了一种策略,包括从输入特征图生成参考点,对这些参考点进行归一化,使用子网生成偏移,然后在变形的参考点上执行双线性完成。
5.3 促进变形点的多样性
特征通道分为几组,以鼓励变形点的多样性。与多头自我注意 (MHSA) 方法类似,基于每个组的要素利用共享子网来生成合理的偏移。
5.4 使用可变形相对位置偏差增强空间信息
将可变形的相对位置偏差合并到 DAT 中还可以增强注意力操作中的空间信息。
5.5 DAT 的模型架构
在计算成本方面,可变形多头注意力(DMHA)与PVT和Swin变压器等模型相比具有优势。区别主要在于偏移网络的计算复杂度。
DAT 使用多尺度特征图,并在后期阶段使用可变形注意力来模拟更广泛区域中的关系。对于分类任务,我们使用具有池化特征的线性分类器。对于对象检测和分割任务,DAT充当模型的主干,提取多尺度特征。
(a) ViT(视觉转换器):ViT将自我注意力应用于整个图像,利用全局感受野来捕获总体特征。
(b) Swin 变压器:与 ViT 不同,Swin 变压器限制其感受野,在这些定义的边界内执行自我注意。
(c) DCN(可变形卷积网络):DCN是基于卷积神经网络(CNN)的模型,它对可变形感受野进行操作。
5.6 DAT 结构概述
DAT的整体结构遵循类似于ResNet的四阶段分层设计。随着每个阶段的进展,特征图的空间大小减半,而通道数增加一倍,利用卷积层在阶段之间进行下采样。
为了减少计算工作量,第一个 4x4 卷积将采样下采样到图像大小的 1/4。阶段 1 和 2 实现局部注意力和移位窗口注意力 — 来自 Swin 变压器的限制感受场自我注意识别方法。同时,阶段3和4采用局部注意力和可变形注意力,执行交替的局部和全局识别以提高精度。
有趣的是,DAT只在过程的后半部分采用可变形的注意力。这是由于ViT模型倾向于在早期识别阶段进行局部识别,并努力减少计算。
六、模型结构
整体模型结构采用像ResNet这样的四阶段层次结构。随着阶段的进展,特征图的空间大小减半,通道数加倍。阶段之间的这种下采样使用卷积层。(k=内核大小,s=步幅)。
第一个 4x4 卷积被下采样到图像大小的 1/4,以减少计算工作量。
阶段 1 和 2 采用本地注意力和移位窗口注意力。这些是Swin变压器中使用的具有受限感受野的自我注意识别方法。
阶段 3 和 4 采用局部注意力和可变形注意力。通过交替执行本地识别和全局识别,有助于提高准确性。
之所以只在后半段采用可变形注意力,是因为ViT模型在识别的早期阶段倾向于局部识别,为了减少计算量,只在后半段采用可变形注意力。
七、可变形注意力模块
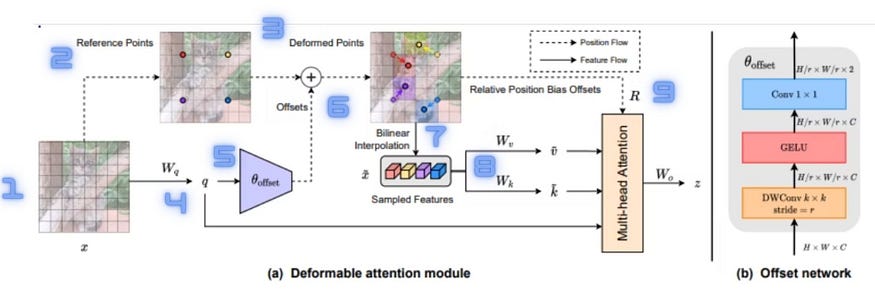
输入图像 x (H×W×C) 具有参考点 (Hg×Wg= HxW/r²),其中 are 是手动确定的,处理如下,其中 Hg=H/r 和 Wg=W/r:
(i) 输入是尺寸为 H × W × C 的特征图 x。
(ii) 我们从尺寸为 HG × WG × 2 的均匀网格中选择像素 p 作为参考点(其中 HG = H/r,WG = W/r,有效地对原始网格进行降采样)。
(iii) 这些参考点线性投影到二维坐标系上,其点范围从 (0,0) 到 (HG — 1, WG — 1),并在 [-1, +1] 之间归一化,其中左上角对应于 (-1,-1)。
(iv) 为了获取每个参考点的偏移量,对特征图进行线性投影,从而得到查询令牌 q = xWq。
(v) 然后将查询令牌 q 传递到子网 θ 偏移量以生成偏移量。
![]()
为了确保稳定的学习过程,通过变换 Δp ← s tanh(Δp) 来采用预定义的值 s 来防止 Δp 变得太大。
(六)将参考点和偏移信息结合起来得到变形的参考点。
(vii) 然后,我们对这些变形的参考点进行双线性插值,对特征 x ̃ 进行采样。
(viii) 对步骤 (viii) 的结果进行线性投影,以保护密钥令牌 k ̃ = x ̃ Wk 和值标记 v ̃ = x ̃ Wv。
(九) 最后,以整合类似位置嵌入的信息的方式应用注意力,最终产生最终输出。
7.1 偏移网络简介(子网)
在此子网中,将使用查询为每个参考点计算偏移值。由于输入图像X经过线性变换以获得查询(Q),然后将其输入到偏移网络中。实现具有两个具有非线性激活函数的卷积模块的子网。
首先使用kxk(本文中的5×5)深度卷积来获取局部特征。然后偏移网络利用两个卷积之间的 GelU 函数。DW 卷积中的卷积内核卷积空间信息。
然后,在通道方向上卷积的 1x1 卷积压缩为 2 个通道(水平、垂直)。特征图存储对应于每个参考点的垂直和水平距离值。
7.2 键和值
使用偏移网络确定的值平移参考点。通过双线性插值(处理浮点数)确定
其移动到的参考点的值。
特征图使用参考点确定值 x(Hg×Wg×C) 并创建 x 然后线性变换 to 键和值。
为了鼓励变形点的多样性,将特征通道分成G组,这种策略让人联想到多头自我注意(MHSA)技术。每个组中的要素子集利用共享子网来生成相关偏移。实际上,多头注意力单元的计数是偏移组数的 G 倍,确保为每个转换后的键和值标记组分配多个注意力头。
此外,相对位置偏差(介于 7 和 9 之间)封装了所有可能的查询键对之间的相对位置,从而增强了具有空间数据的传统注意力机制。最后,在DAT的框架内,归一化值用作位置嵌入,考虑连续的相对位移以覆盖所有潜在的偏移值。
因此,多头注意适用,其中输入查询、键和值通过以下方式派生:

自我注意应用以下等式,其中B表示可变形的相对位置偏差:
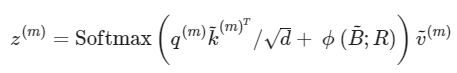
可变形多头衰减(DMHA)具有类似的计算成本,例如PVT和Swin变压器。区别在于偏移网络的计算复杂度。

其中 Ns= HgxWg
虽然Swin Transformer的计算系数为79.63M Flops,但添加子网产生的计算成本约为5.08M Flops。请注意,通过增加 r 的值(缩减采样因子),可以进一步降低计算成本。
八、模型体系结构

该模型的整体架构遵循四阶段层次结构,让人联想到ResNet。随着阶段的进展,特征图的空间维度减半,而通道数翻倍,这是通过卷积层的实现的。在初始步骤中,第一个 4x4 卷积减少到图像大小的四分之一,以减少计算工作量。
DAT认识到图像任务需要多尺度特征图,采用类似的分层排列来形成特征金字塔。在第一阶段和第二阶段,没有实现可变形注意力(DA),因为主要目标是掌握更多的局部特征。由于相当大的空间开销和计算成本,这里避免了DA。相反,该模型将本地信息与 Shift-Window 注意力集成在一起,Shift-Window 注意力是 Swin Transformer 中使用的一种基于窗口的局部注意力机制。
第三和第四阶段引入了可变形的注意力,允许对从更局部的区域过渡到更广泛的区域的关系进行建模。在分类任务中,线性分类器与池化特征一起使用,以首先规范化最后阶段的特征图输出,然后再预测 logit。
对于对象检测和分割任务,DAT 作为模型的主干,提取多尺度特征。此外,在对象检测和语义分割解码器等任务中,在将规范化层馈送到后续模块之前,将规范化层合并到每个阶段的功能中,该过程类似于 FPN 方法。这种结构化方法平衡了本地和全球识别并管理计算成本,从而提高了各种任务的准确性和效率。
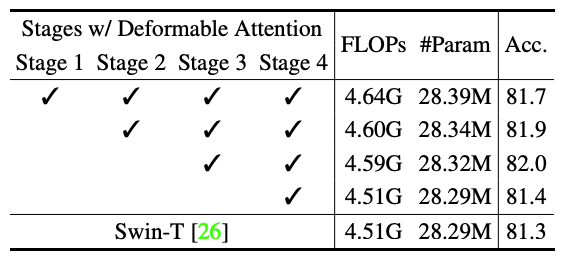
九、可变形注意力和结果采用的阶段
可以看出,在ImageNet-3k分类任务的可变形注意采用的阶段4和1中采用它,精度很高。
DAT在图像分类(ImageNet-1K)、对象检测(COCO)和分割(ADE20K)等任务中优于传统方法。特别是在 ImageNet-1k 分类中,可变形注意力采用的第 3 阶段和第 4 阶段实现了高精度。

虽然顶部的SWIN无法区分前景和背景

DAT将参考点转移到长颈鹿身上,也关注另一只长颈鹿。
因此,DAT通过将参考点移近识别目标来改善识别并减少计算负载。
总之,该解决方案提供了一种克服视觉识别任务中现有挑战的有希望的方法。通过使用可变形注意力转换器,旨在为图像识别领域带来更大的灵活性、效率和实用性。
十、参考资料
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., & Polosukhin, I. (2017).注意力就是你所需要的。在NeurIPS(第5998-6008页)中。
多索维茨基,A.,拜尔,L.,科列斯尼科夫,A.,魏森伯恩,D.,翟,X.,Unterthiner,T.,Dehghani,M.,Minderer,M.等人(2020)。一张图像价值 16x16 个字:用于大规模图像识别的变压器。arXiv预印本arXiv:2010.11929.
刘志忠,林,Y.,曹彦,胡,H.,魏,Y.,张,Z.,林,S.和郭,B.(2021)。使用移位窗口的分层视觉转换器。国际刑事法庭。
Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., & Wei, Y. (2017).可变形卷积网络。在ICCV(第764-773页)。
王伟文、谢磊、李晓、范德平、宋、梁、卢、T.、罗、P.和邵林(2021)。金字塔视觉变压器:多功能。在ICCV中。乔·埃尔·库里
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., & Dai, J. (2020).可变形变压器:用于端到端物体检测的可变形变压器。arXiv预印本arXiv:2010.04159.