目录
1、启动Hadoop服务
2、创建文本文件
3、上传文本文件
4、显示文件内容
5、完成排序任务
6、计算最大利润和平均利润
7、统计学生总成绩和平均成绩
8、总结
1、启动Hadoop服务
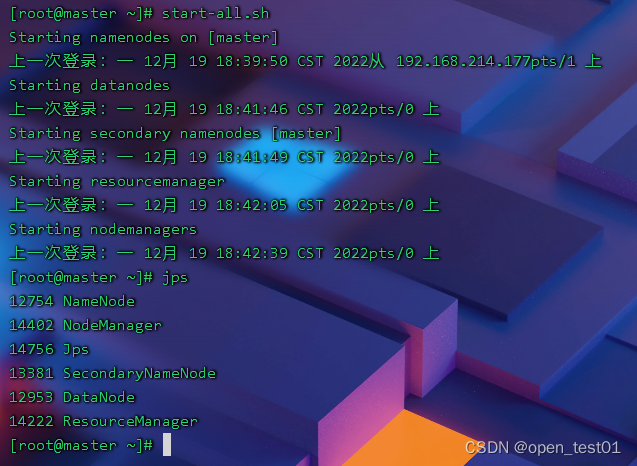
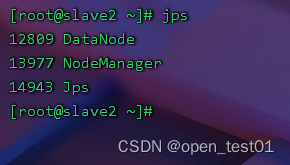
在master虚拟机上执行命令:
start-all.sh启动hadoop服务进程

2、创建文本文件
在master虚拟机上创建本地文件students.txt
李晓文 女 20
张晓航 男 19
郑小刚 男 21
吴文华 女 18
肖云宇 男 22
陈燕文 女 19
李连杰 男 23
艾晓丽 女 21
童安格 男 18
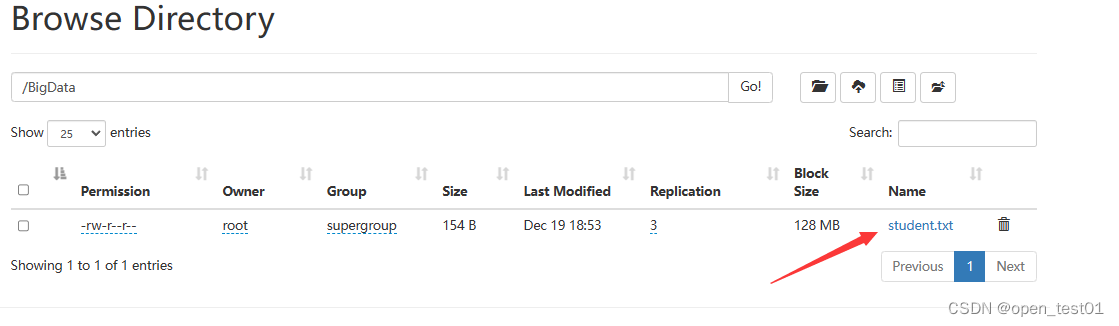
3、上传文本文件
将students.txt上传到HDFS的/BigDtat目录
执行命令将该文件复制到HDFS的HelloHadoop文件夹中
hdfs dfs -put /home/student.txt /BigData
webUI界面中查看上传成功
4、显示文件内容
创建maven工程

创建maven工程并添加依赖
<dependencies>
<!--hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<!--单元测试框架-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
</dependencies> 
在 resources目录里创建 log4j.properties文件
log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/wordcount.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n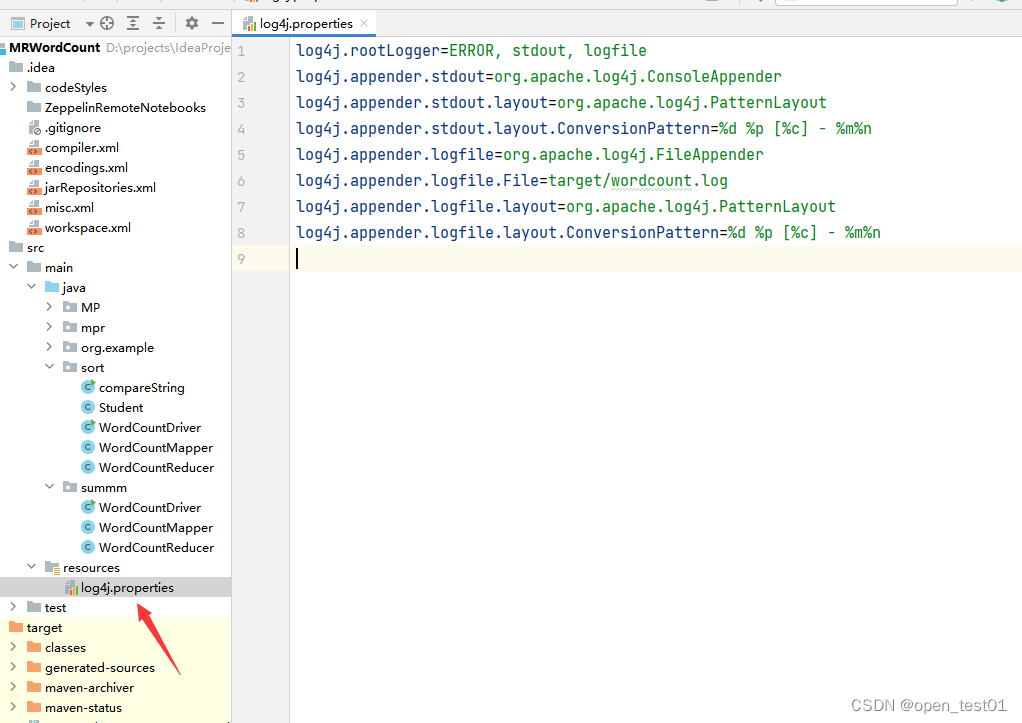
创建displayFile类用于显示文件内容
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
public class displayFile {
@Test
public void read1() throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 定义统一资源标识符(uri: uniform resource identifier)
String uri = "hdfs://master:9000";
// 创建文件系统对象(基于HDFS的文件系统)
FileSystem fs = FileSystem.get(new URI(uri), conf, "root");
// 创建路径对象(指向文件)
Path path = new Path(uri + "/BigData/student.txt");
System.out.println(path);
// 创建文件系统数据字节输入流(进水管:数据从文件到程序)
FSDataInputStream in = fs.open(path);
// 创建缓冲字符输入流,提高读取效率(字节流-->字符流-->缓冲流)
BufferedReader br = new BufferedReader(new InputStreamReader(in));
// 定义行字符串变量
String nextLine = "";
// 通过循环遍历缓冲字符输入流
while ((nextLine = br.readLine()) != null) {
// 在控制台输出读取的行
System.out.println(nextLine);
}
// 关闭缓冲字符输入流
br.close();
// 关闭文件系统数据字节输入流
in.close();
// 关闭文件系统
fs.close();
}
}
5、完成排序任务
创建Maven项目SortByAge,利用MapReduce计算框架,处理/BigData/student.txt文件,输出结果按照年龄降序排列
李晓文 女 20
张晓航 男 19
郑小刚 男 21
吴文华 女 18
肖云宇 男 22
陈燕文 女 19
李连杰 男 23
艾晓丽 女 21
童安格 男 18创建Student类
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Student implements WritableComparable<Student> {
private String name;
private String gender;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", gender='" + gender + '\'' +
", age=" + age + '\''+
'}';
}
public int compareTo(Student o) {
return o.getAge() - this.getAge(); // 降序
}
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeUTF(gender);
out.writeInt(age);
}
public void readFields(DataInput in) throws IOException {
name = in.readUTF();
gender = in.readUTF();
age = in.readInt();
}
}
创建WordCountMapper类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Student, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 按空格拆分得到字段数组
String[] fields = line.split(" ");
// 获取学生信息
String name = fields[0];
String gender = fields[1];
int age = Integer.parseInt(fields[2]);
// 创建学生对象
Student student = new Student();
// 设置学生对象属性
student.setName(name);
student.setGender(gender);
student.setAge(age);
context.write(student, NullWritable.get());
}
}创建WordCountReducer类
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Student, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Student key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
for (NullWritable value : values) {
// 获取学生对象
Student student = key;
// 拼接学生信息
String studentInfo = student.getName() + "\t"
+ student.getGender() + "\t"
+ student.getAge();
context.write(new Text(studentInfo), NullWritable.get());
}
}
}创建WordCountDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(WordCountDriver.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Student.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(NullWritable.class);
// 设置Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Student.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(NullWritable.class);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/BigData");
// 创建输出目录
Path outputPath = new Path(uri + "/output");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 给作业添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 给作业设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待作业完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}运行查看结果

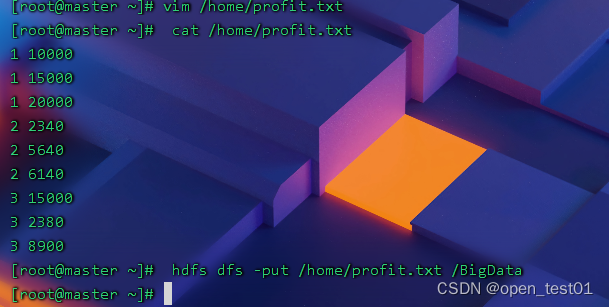
6、计算最大利润和平均利润
利用利用MapReduce计算框架 处理profit.txt文件,输出每月最大利润和平均利润
创建利润信息profit.txt文件并上传HDFS
1 10000
1 15000
1 20000
2 2340
2 5640
2 6140
3 15000
3 2380
3 8900
创建ScoreMapper类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ScoreMapper extends Mapper <LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 按空格拆分得到字段数组
String[] fields = line.split(" ");
// 获取月份
String name = fields[0].trim();
// 遍历各利润信息
for (int i = 1; i < fields.length; i++) {
// 获取利润信息
int score = Integer.parseInt(fields[i].trim());
// 写入<月份,值>键值对
context.write(new Text(name), new IntWritable(score));
}
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ScoreMapper extends Mapper <LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 按空格拆分得到字段数组
String[] fields = line.split(" ");
// 获取月份
String name = fields[0].trim();
// 遍历各利润信息
for (int i = 1; i < fields.length; i++) {
// 获取利润信息
int score = Integer.parseInt(fields[i].trim());
// 写入<月份,值>键值对
context.write(new Text(name), new IntWritable(score));
}
}
}
创建ScoreReducer类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.text.DecimalFormat;
public class ScoreReducer extends Reducer<Text, IntWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// 声明变量
int count = 0; // 科目数
int sum = 0; // 总分
int avg = 0; // 平均分
int max = 20000;
// 遍历迭代器计算总分
for (IntWritable value : values) {
count++; // 科目数累加
sum += value.get(); // 总分累加
}
// 计算平均值
avg = sum * 1 / count;
// 创建小数格式对象
DecimalFormat df = new DecimalFormat("#.#");
// 拼接每个最大利润与平均利润信息
String scoreInfo = key + " maxProfit=" + max + ", avgProfit=" + df.format(avg);
// 写入键值对
context.write(new Text(scoreInfo), NullWritable.get());
}
}
创建ScoreDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class ScoreDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(ScoreDriver.class);
// 设置Mapper类
job.setMapperClass(ScoreMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer类
job.setReducerClass(ScoreReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Text.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(NullWritable.class);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/BigData");
// 创建输出目录
Path outputPath = new Path(uri + "/maxavgprofit/output");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 给作业添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 给作业设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待作业完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
运行查看结果

7、统计学生总成绩和平均成绩
创建利润信息score.txt文件并上传HDFS
姓名 语文 数学 英语 物理 化学
李小双 89 78 94 96 87
王丽霞 94 80 86 78
吴雨涵 90 67 95 92 60
张晓红 87 76 90 79 59
陈燕文 97 95 92 88 86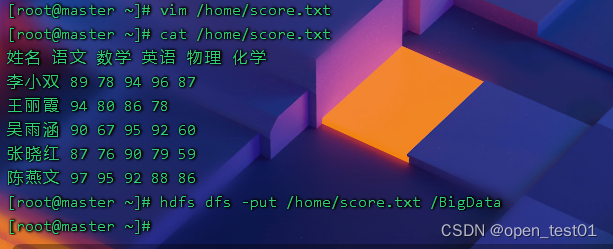

创建WordCountMapper类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//获取行内容
String line = value.toString();
//按空格拆分得到字段数组
String[] fields = line.split(" ");
//获取字段信息
String name = fields[0];
for (int i = 1; i < fields.length; i++){
int score = Integer.parseInt(fields[i]);
context.write(new Text(name),new IntWritable(score));
}
}
}创建WordCountReducer类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.text.DecimalFormat;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
int sum = 0;
double avg = 0;
for (IntWritable value : values){
count++;
sum += value.get();
}
avg = sum * 1.0 /count;
DecimalFormat df = new DecimalFormat("#.#");
String scoreInfo = "("+key+","+sum+","+df.format(avg)+")";
context.write(new Text(scoreInfo),NullWritable.get());
}
}创建WordCountDriver类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(mpr.WordCountDriver.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置Reducer任务输出键类型
job.setOutputKeyClass(Text.class);
// 设置Reducer任务输出值类型
job.setOutputValueClass(NullWritable.class);
//设置分区数量
job.setNumReduceTasks(1);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/BigData");
// 创建输出目录
Path outputPath = new Path(uri + "/outputs");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 给作业添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 给作业设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待作业完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}运行查看结果

8、总结
通过实训,使得更加熟练掌握HDFS操作和MapReduce编程