手撕string目录:
一、 Member functions
1.1 constructor
1.2 Copy constructor(代码重构:传统写法和现代写法)
1.3 operator=(代码重构:现代写法超级牛逼)
1.4 destructor
二、Other member functions
2.1 Iterators(在string类中,迭代器基本上就是指针)
2.1.1 begin()&& end()
2.1.2 范围for的底层原理(鱼香肉丝,夫妻肺片)(这是编译器的活,而且是死活)
2.2Capacity
2.2.1 size() && capacity()
2.2.2 reserve(C++语法不存在原地扩容)
2.2.3 resize(三种情况都得考虑清楚)
2.2.4 clear
三、 Element access
operator[ ] (返回值返回引用,因为支持修改)
四、Modifiers(难啃但很重要)
4.1 push_back
4.2 append
4.3 operator+=(大佬其实也是用了push_back与append小弟)
4.4 insert(头插痛苦面具)
4.5 npos 不可缺少的静态成员变量
4.6 erase(删除部分字符很惊艳)
4.7 swap
五、String operations(find与c_str)
5.1 find
5.2 c_str
六、<< 与 >> 与 getline
6.1 operator<<(必须全局(要不然就是对象 << cout),但不一定必须友元)
6.2 operator>>
6.3 getline
七、讨论内置类型到底能否调用构造函数

前言:在手撕string类的时候,完全按照国外文档的逻辑顺序一层一层向下剖析:

一、 Member functions
1.1 constructor
1. 库里面的构造函数实现了多个版本,我们这里就实现最常用的参数为const char *的版本,为了同时支持无参的默认构造,这里就不在多写一个无参的默认构造,而是用全缺省的const char *参数来替代无参和const char *参数的两个构造函数版本。
2. _size代表数组中有效字符的个数,在vs下_capacity代表数组中有效字符所占空间的大小,在g++下包含了标识字符\0的空间大小,我们这里就实现和vs编译器一样的_capacity,然后在底层实际开空间的时候多开一个空间存放字符串的\0就可以。
3. 代码中利用了strlen和strcpy来进行字符串有效字符的计算和字符串的拷贝,值得注意的是strcpy在拷贝时会自动将字符串末尾的\0也拷贝过去。
对于构造函数的缺省参数,也是大有讲究:
- '\0' -- 字符0,ascll码值为0
- "\0" -- 字符串有两个\0,因为默认有一个\0
- "" -- 有一个\0,字符串默认以\0结尾
class string
{
public:
string(const char* str="")//:_str(str)//权限会放大,不能这样初始化
{
_size=strlen(str);
_capacity=_size;
_str=new char[_capacity+1];//实际开空间的时候多开一个位置给\0,但capacity还是和size一样
strcpy(_str,str);
}1.2 Copy constructor(代码重构:传统写法和现代写法)
1. 传统写法就是我们自己手动给被拷贝对象开辟一块与拷贝对象相同大小的空间,然后手动将s的数据拷贝到新空间,最后再手动将不涉及资源申请的成员变量进行赋值。
2. 现代写法就是我们自己不去手动开空间,手动进行成员变量的赋值,而是将这些工作交给其他的接口去做,就是去找一个打工人,让打工人去替我们做这份工作,在下面代码中,构造函数就是这个打工人。
所以构造出来的tmp和s就拥有一样大小的空间和数据,然后我们再调用string类的swap成员函数,进行被拷贝对象this和tmp对象的交换,这样只需两行代码就能解决拷贝构造的实现,但真的解决了吗?
3. 实际上,还需要一个初始化列表,因为s2的内容不初始化,则s2的_str就是野指针,随机指向一块不属于他的空间,这块空间应该属于操作系统,那么在交换完毕之后,tmp的_pstr就变为了空指针,在出函数作用域之后tmp对象会被销毁自动调用析构函数,则释放野指针所指向的空间就会发生越界访问,程序就会崩溃,所以最好的解决办法就是利用初始化列表先将this的成员变量初始化一下,对于有资源的_pstr我们利用nullptr来进行初始化,避免出现野指针。
4. 可能会有人有疑问,释放nullptr指向的空间时,程序不会崩吗?实际上无论是delete、delete[]还是free,他们在内部实现的时候,如果遇到空指针则什么都不做,也就是没有任何事情发生,因为这也没有做的理由,空指针指向的空间没有任何数据,我为什么要处理它呢?只有说一个空间中有数据需要清理的时候,也就是这个指针不为空的时候,free和delete、delete[]才有处理它的理由。
string (const string& s)//现代写法
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);//调用构造函数,tmp和s有一样大的空间和一样的值
this->swap(tmp);可以不用this指针调用,因为在类里面,swap默认的左边第一个参数就是this,直接调用就可以。
}
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}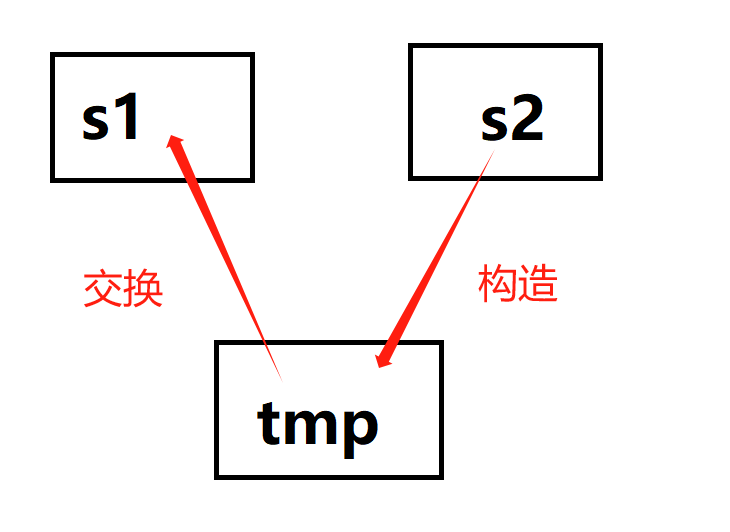
补充:如果要进行两个对象的交换,不要调用std里的swap,因为会进行三次深拷贝,效率非常低,所以我们利用某一个对象的swap类成员函数来进行两个对象的交换。
在利用左侧的swap函数的时候,里面用到了一次拷贝构造+俩次赋值运算符重载,这都是深拷贝
在利用右侧找个打工人的时候,发现只需要一次深拷贝就可以完成!!

1.3 operator=(代码重构:现代写法超级牛逼)
1. 赋值重载的传统写法和拷贝构造非常的相似,都是我们自己手动开空间,手动进行无资源申请的成员变量的赋值,手动进行数据的拷贝。但需要额外关注的一点是,一个对象可能被多次赋值,那我们就需要对原来可能存在的资源进行释放,所以需要手动delete[]或者调用clear()函数来进行原来可能存在的资源的释放
2. 只要让打工人拷贝构造构造出来tmp,然后我们再利用类成员函数swap将tmp和this对象进行交换,则赋值工作就完成了,本质和拷贝构造是一样的,都是先让一个打工人帮我们搞好一个和拷贝对象一样的对象,然后再用自己的对象和打工人搞好的这个对象进行交换,等离开函数时打工人搞的对象就被销毁,this对象成功就完成了赋值工作
3. 其实还有一个最为简洁的办法就是用传值传递,这样的话,函数参数天然的就是我们的打工人拷贝构造函数搞出来的对象,那我们实际上什么都不用做,直接调用swap函数进行this和参数对象的交换即可,以后我们写赋值重载就用这个最简洁的方法(但是拷贝构造是必须传引用的,否则就会出现递归)
string& operator=(string s)//现代写法的另一种更为常用的写法,s是现成的打工人,身份地位和tmp一样
//传值传参不存在权限的放大和缩小,指针和引用才有权限的放大和缩小,传值只是权限的平移,无论是const还是非const,直接拷贝就行
{
swap(s);
return *this;
}1.4 destructor
析构函数的实现就比较简单了,只要将指针指向的空间进行释放,然后将其置为空指针,防止野指针的误操作,然后再将剩余两个成员变量赋值为0即可完成工作
~string()
{
delete[] _str;
_str=nullptr;
_size=_capacity=0;
}二、Other member functions
2.1 Iterators(在string类中,迭代器基本上就是指针)
2.1.1 begin()&& end()
现阶段我们无法完全透彻的理解迭代器,但是目前我们确实可以将其理解为指针,所以在模拟实现这里我们用typedef来将iterator定义为char型的指针类型。而对于begin和end来说较为简单,只要返回 首元素 和 末尾的\0元素 对应的地址就可以,而_size对应的下标正好就是\0,所以直接返回就好。
typedef char* iterator;
iterator begin()const{
return _str;
}
iterator end() const{
return _str+_size;
}2.1.2 范围for的底层原理(鱼香肉丝,夫妻肺片)(这是编译器的活,而且是死活)
实际上C++11的新特性基于范围的for循环,他的本质实现就是迭代器,所以只要有begin()和end()这两个返回迭代器的函数,我们就可以使用范围for,范围for代码的执行实际上可以理解为宏的替换,就是在执行for时,编译器会在这个地方作处理,等到实际执行时,执行的就是迭代器,并且范围for只能调用begin和end,这是写死的,如果这两个函数的名字变一下,那范围for就用不了了,因为局部的返回迭代器的函数名有问题
lzy::string s2("0000");
lzy::string::iterator it2=s2.Begin();
while(it2!=s2.end())
{
(*it2)++;
it2++;
}
// cout << s2 << endl;
for(auto ch : s2)
{
cout << ch << " ";
}
cout << endl;
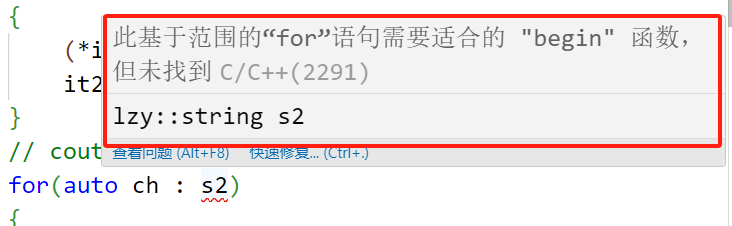
解释:范围for就是用迭代器实现的,在编译范围for的代码之前先将代码替换为迭代器的实现,有
点类似于宏。所以在实际编译的时候编译的是替换之后的迭代器的代码,替换的迭代器必须是
begin和end,如果我们将自己的begin改成Begin,则iterator的调用还可以进行,但范围for就无法
通过,因为范围for只能调用begin()和end(),这是写死的。范围for调用我们自己写的迭代器的原因
是因为,它会先去局部找,然后再去全局找,局部有我们自己实现的begin和end,则范围for就会
自动调用。只要一个容器有迭代器,那么这个容器就可以支持范围for,迭代器必须是原模原样的begin 和 end
void test1()
{
string s1("0000");
string::iterator it1 = s1.begin();
while(it1 != s1.end())
{
(*it1)++;
it1++;
}
cout <<"迭代器实现:" <<s1 << endl;
string s2("0000");
cout << "范围for实现:";
for(auto& ch : s2)
{
cout << ++ch;
}
}
int main()
{
test1();
return 0;
}
2.2Capacity
2.2.1 size() && capacity()
size_t size()const
//const 修饰类成员函数实际上修饰该成员函数隐含的 this 指针
//表明在该成员函数中不能对 this 指向的类中的任何成员变量进行修改
{
return _size;
}
size_t capacity()const//写俩个共有函数接收私有变量
{
return _capacity;
}
2.2.2 reserve(C++语法不存在原地扩容)
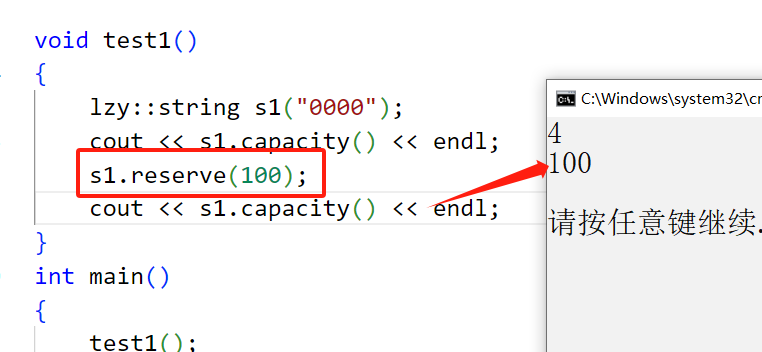
reserve的参数代表你要将数组的现有的有效字符所占空间大小调整为的大小,注意是有效字符,这是不包含标识字符的,而在具体实现的时候,我们在底层多开一个空间给\0,在C++中所有的扩容都是异地扩容,而不是原地扩容,所以每一次扩容都需要进行原数据拷贝到新空间,代价确实很大。reserve尽量不要缩容,最好是扩容。 下面代码只有扩容,如果是缩容,则什么都不做。(realloc本质上再次扩容也是异地)
void reserve(size_t n)
{
if(n>_capacity)
{
char* tmp=new char[n+1];
strcpy(tmp,_str);
delete[] _str;
_str=tmp;
_capacity=n;
}
}
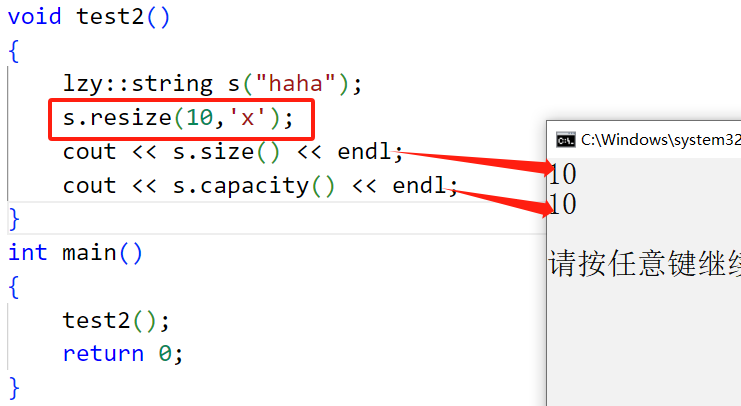
2.2.3 resize(三种情况都得考虑清楚)
对于resize来说,根据所传空间大小的值来看,可以分为插入数据和删除数据两种情况
1. 对于插入数据直接调用reserve提前预留好空间,然后搞一个for循环将字符ch尾插到数组里面去,最后再在数组末尾插入一个\0标识字符,此刻就体现出来为什么我们在reserve开空间的时候要多开一个空间了,因为这个空间就是给\0留的。
2. 对于删除数据就比较简单了,直接在n位置插入\0即可,依旧采用惰性删除的方式,然后重置一下_size的大小为n即可。
void resize(size_t n,char ch='\0')
{
//分三种情况,删除数据,不扩容增加数据,扩容增加数据,后两种情况可以合起来,因为是插入数据
if(n>_size)
{
reserve(n);
for(size_t i=_size;i<n;i++)
{
_str[i]=ch;
}
_size=n;
_str[_size]='\0'; //在末尾位置加上斜杠0
}
else
{
//删除
_str[n]='\0';
_size=n;
}
}
2.2.4 clear
这里的clear实现的很巧,我们只要将_size搞成0,然后将第一个元素赋值为\0就完成资源的清理了,这个操作进行了直接覆盖,这实际上是一种惰性删除的方式。
void clear()
{
_size = 0;
_pstr[0] = '\0';
}
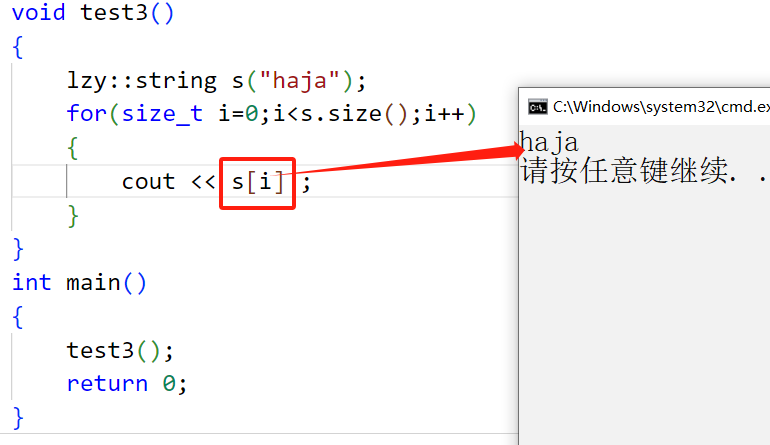
三、 Element access
operator[ ] (返回值返回引用,因为支持修改)
对于operator[ ]来说,调用它时既有可能进行写操作,又有可能进行读操作,所以为了适应const和非const对象,operator[ ]应该实现两个版本的函数,并且这个函数对待越界访问的态度就是assert直接断言,对于越界访问的态度是抛异常
//普通对象:可读可写
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
//const对象:只读
char& operator[](size_t pos)const
{
assert(pos < _size);
return _str[pos];
}
四、Modifiers(难啃但很重要)
4.1 push_back
1. push_back有一个需要注意的地方就是在扩容的地方
如果是一个空对象进行push_back的话,我们采取的二倍扩容就有问题,因为0*2还是0,所以对于空对象的情况我们应该给他一个初始的capacity值。
这里我们就给成4,其他情况的话只要空间满了我们就二倍扩容。
2. 很容易忘记的就是在尾插字符之后,忘记补\0了,千万不要忘记这里,否则在打印的时候就会有麻烦了。我们只要记住一个字符串就是由有效字符和结尾的标识字符组成的,所以在进行完修改操作的时候,就得多加思考。
void push_back(char ch)
{
if(_size==_capacity)
{
int newCapacity=_capacity == 0 ? 4 : _capacity*2;
reserve(newCapacity);
}
_str[_size]=ch;
_size++;
_str[_size]='\0';
}4.2 append
1. 对于append的实现,我们其实可以直接调用strcpy接口来进行字符串的尾插,并且我们知道strcpy是会将\0也拷贝过去的,这样的话,我们就不需要在末尾手动补充\0了。
2. 值得注意的是,string系列的字符串函数是不会进行自动扩容的,所以我们需要判断一下是否需要进行扩容,在空间预留好的情况下进行字符串的尾插,调整strcpy的插入位置为_pstr+_size即可实现字符串尾插的工作。
void append(const char* str)
{
//string系列的库函数是不会自动扩容的,都需要在有足够空间的情况下进行操作
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);//这里开空间不需要加1,只需要传有效字符的个数就可以了,底层实际多开一个\0空间的工作交给reserve
}
strcpy(_str + _size, str);//strcpy会把\0也拷贝过去
_size += len;
}
4.3 operator+=(大佬其实也是用了push_back与append小弟)
1.我们这里实现两个最常用的版本,参数分别为字符和字符串的版本。
2.返回引用是因为担心连续赋值,接着返回左值
3.返回值是*this
a+=b a就是this b就去当函数参数去了 所以将来返回的是左值
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;//返回对象的引用
}
4.4 insert(头插痛苦面具)
基本逻辑:先判断是否需要进行扩容,然后就是向后挪动数据,最后将目标数据插入到对应的位置即可。但是实现起来坑还是非常多的,出现坑的情况实际就是因为头插
插入字符:
将end定义为字符将要被挪动到的位置的下标,所以我们就将end-1位置的元素挪到end位置上去,在while循环条件的判断位置,我们用end来和pos位置进行比较,end应该大于pos的位置,一旦end=pos我们就跳出循环,这样就不会出现bug了。
string& insert(size_t pos,char ch)//支持任意位置的插入
{
assert(pos<=_size);
if(_size==_capacity)//当相等的时候,被判定为满了,需要扩容
{
int newCapacity=_capacity == 0 ? 4 : _capacity * 2;
reserve(newCapacity);
}
size_t end=_size+1; // 指向斜杠0的位置
while(end>pos)
{
_str[end]=_str[end-1];//必须写成这样的 前往后传
--end;
}
_str[pos]=ch;
_size++;//插入一个字符 size++
return *this;
}插入字符串:(有点晕)
1. 对于字符串的插入逻辑也是相同的,我们需要提前预留好存放字符串的有效字符的空间大小,然后进行挪动字符串,最后将字符串的所有有效字符插入到对应的位置上去即可
2. 插入字符串的情况种类和上面插入字符一样,我推荐使用字符的位置来作为end的定义,将end下标的元素挪到end+len之后的位置上去,因为我们只插入有效字符,所以strlen的结果刚好满足我们的要求,同样在while判断条件进行比较的时候,还是要讲pos强转为int类型来和end进行比较,这样的逻辑非常的清晰明了
3. 在使用size_t作为end类型的情况下,我们需要用字符将要被挪动到的位置来作为end的定义,然后将end-len位置的元素赋值到end位置上去,我们可以将判断条件控制 end>pos+len-1,因为pos+len位置是pos位置元素需要被挪动到的位置,-1之后就是需要存放的字符串的最后一个有效字符的位置,所以我们应该将条件控制为end>pos+len-1或者是end>=pos+len,这两种条件都成立
4. 与插入字符稍有不同的是,我们插入的字符串是有标识字符作为结尾的,所以在进行字符串拷贝到数组里面时,我们需要控制不要将\0拷贝进去,因为原来数组的末尾就有\0,这个时候就不适合用strcpy函数来进行拷贝,可以使用strncpy然后传有效字符大小作为拷贝字符串的字符个数,这样就可以解决不拷贝\0的问题
string& insert(size_t pos, const char* str) {
assert(pos <= _size);
// 检查是否需要扩容
size_t len=strlen(str);
if (_size + len > _capacity) { //对于字符串来说,判断条件发生改变
reserve(_size+len);
}
int end=_size;
while (end >= (int)pos)//这样的代码是可以支持头插的。因为end是int,pos也被强转为int了。
{
_str[end + len] = _str[end];
end--;
}
//难理解
strncpy(_str + pos, str, len);
_size += len;//不要忘了将_size+=,如果不+=,那么扩容就无法正常进行
return *this;
}4.5 npos 不可缺少的静态成员变量
对于静态成员变量,我们知道必须在类外定义,类内只是声明,定义时不加static关键字。但如果静态成员变量有了const修饰之后,情况就不一样了,它可以在类内直接进行定义,值得注意的是,这样的特性只针对于整型,如果你换成浮点型就不适用了。我们的npos就是const static修饰的成员变量,可以直接在类内进行定义。
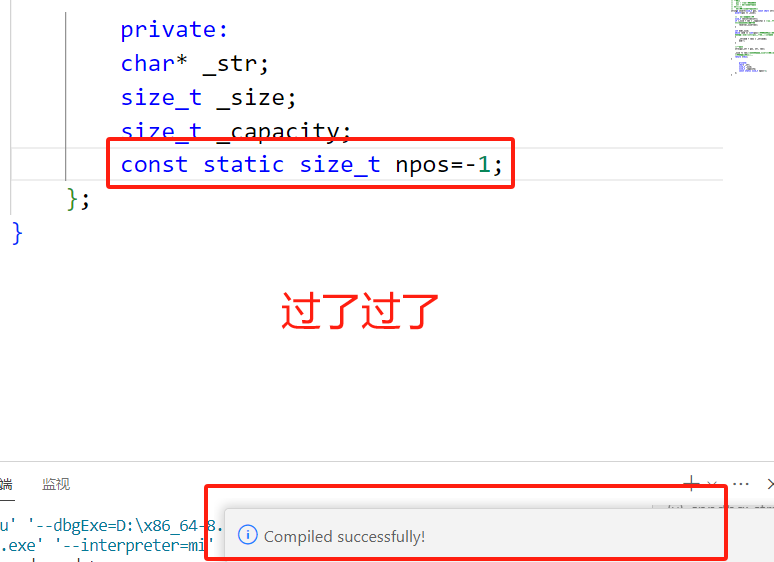
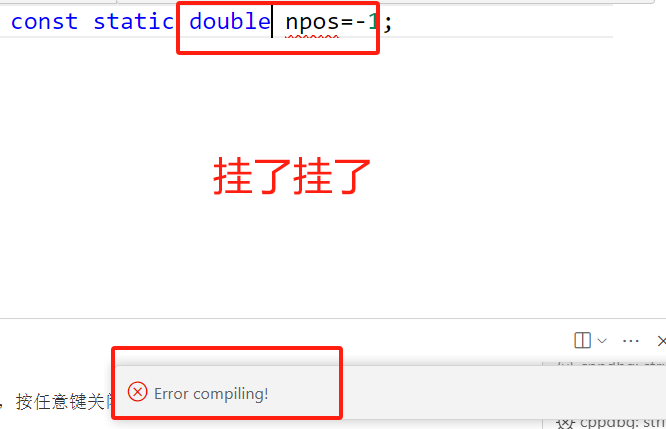

摘自我之前类和对象的博客
class string
{
public:
private:
//类模板不支持分离编译,因为用的地方进行了实例化,但用的地方只有声明没有定义,而有定义的地方却没有实例化,所以发生链接错误
//1.如果在定义的地方进行了实例化,则通过.h文件找到方法之后,方法已经发生实例化了,那么就不会发生链接错误。
//2.或者直接将声明和定义放到.hpp文件中,只要用的地方包含了.hpp文件,则类定义的地方就会进行实例化。
char* _pstr;
size_t _size;//理论上不可能为负数,所以我们用size_t类型进行定义
size_t _capacity;
//如果在调用构造函数的时候没有显示传参初始化成员变量,则成员变量会利用C++11的缺省值在构造函数的初始化列表进行初始化
const static size_t npos = -1;
//静态成员变量在类中声明,定义必须在类外面,因为它属于整个类。但const修饰的静态成员变量可以直接在类中进行定义,算特例。
//但const修饰静态成员变量在类中可以进行定义的特性,只针对于整型类型,换个类型就不支持了。***给整型开绿灯***
//const static double X ;
};
4.6 erase(删除部分字符很惊艳)
1 2 为删除全部字符 3 为删除部分字符
1. erase的参数分别为删除的起始位置和需要删除的长度,库中实现时,如果你不传则默认使用缺省值npos,转换过来的意思就是,如果你不传删除长度,那就默认从删除的起始位置开始将后面的所有字符都进行删除。
2. 如果len+pos之后的下标大于或者等于_size的话,那处理结果和没传删除长度参数一样,都是将pos位置之后的元素全部删除,我们依旧采用惰性删除的方式来进行删除,直接将pos位置下标对应的元素赋值为\0即可。
3. 对于仅删除字符串的部分字符情况的话,我们可以利用strcpy来进行,将pos+len之后的字符串直接覆盖到pos位置,这样实际上就完成了删除的工作。
string& erase(size_t pos,size_t len=npos)
{
assert(pos<=_size);
if(len==npos || len+pos>=_size)//全部干掉
{
_str[pos]='\0';
_size=pos;
}
else
{
strcpy(_str+pos,_str+pos+len);
_size=_size-len;
}
return *this;
如果不搞引用返回的话,则会发生浅拷贝因为我们没写拷贝构造,临时对象离开函数会被销毁4.7 swap
调用std里面的swap将对象的内置类型的每个成员变量进行交换,即可完成对象的交换
void swap(string& str)
{
std::swap(_pstr, str._pstr);
std::swap(_capacity, str._capacity);
std::swap(_size, str._size);
}
五、String operations(find与c_str)
5.1 find
1. 对于字符的查找,遍历一遍即可,如果找不到我们就返回npos,找到就返回下标
2. 对于字串的查找,我们调用strstr来进行解决,如果找到就利用指针减去指针来返回字串的首元素下标,找不到就返回npos。
size_t find(const char ch, size_t pos = 0)const
{
assert(pos < _size);
while (pos < _size)//一般来说不会查找空字符,所以这里就不加=
{
if (_str[pos] == ch)
{
return pos;
}
pos++;//找不到就往后走
}
return npos;//找不到返回npos
}
size_t find(const char* str, size_t pos = 0)const
{
assert(pos < _size);
const char* findp = strstr(_str + pos, str);//在字符串的pos位置开始找子串
if (findp == nullptr)
return npos;
return findp - _str;//由于返回值是整形,所以利用findp减去初始指针即可得位置
}5.2 c_str
c_str是C++为了兼容C语言增加的一个接口,其作用就是返回string类对象的成员变量,也就是char *的指针
const char* c_str()
{
return _str;
}
六、<< 与 >> 与 getline
6.1 operator<<(必须全局(要不然就是对象 << cout),但不一定必须友元)
类外获得类内私有成员变量,一般有两种方法
一种是通过友元函数来进行解决,另一种是调用公有成员函数来访问私有成员变量。
这里的流插入重载还是非常简单的,我们利用范围for就可以输出字符串的每个字符,最后返回ostream类对象的引用即可,以此来符合连续流插入的情景。
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
ch++;
}
/*for (size_t i = 0; i < s.size(); i++)
{
out << s[i];
}*/
return out;
}6.2 operator>>

istream& operator>>(istream& in, string& s)//这里不能用const了,因为要将控制台输入后的内容拷贝到对象s里面
{
s.clear();//上来就清空一下,这样就可以支持已初始化对象的流提取了
/*char ch;
in >> ch;*/
//流提取就是从语言级缓冲区中拿数据,但是他拿不到空格和换行符,因为istream类的流提取重载就是这么规定的
//所以要解决的话,我们就不用流提取重载,我们改用istream类的get()函数来一个一个获取缓冲区里面的每个字符。
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
s += ch;//如果输入到缓冲区里的字符串非常非常的长,那么+=就需要频繁的扩容,则效率就会降低。
// //in >> ch;
ch = in.get();//C++的get()和C语言的getchar()的功能是一样的,都是获取缓冲区的字符
}
//方法1.reserve解决方案
//reserve大了,空间浪费,如果小了,一旦字符串又过大,则还会需要频繁的扩容,reserve可以,但是不是特别好的方法。
//方法2.开辟buff数组
/*如果你输入的字符个数过于少,有效字符的个数不到127的话,跳出while循环之后,我们还需要另外判断,
再将buff中还没有满的数据 += 到对象s里面去。
如果输入的字符个数过于多,无需担心,我们以127个有效字符为一组,每组满了就将这一组的数据 += 到对象s里面去,
库里面大概就是这么实现的。*/
char buff[128] = { '\0' };
size_t i = 0;
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
//if (i < 127)//这里的大小必须是127,最后得留一个位置给\0,要不然没有标识字符,字符串的结尾具体在哪里找不到,打印出错
//{
// buff[i++] = ch;
//}
//else
//{
// s += buff;
// i = 0;
//}
//ch = in.get();
//上面这种逻辑,输入的有效字符个数超过127或者更大的时候,实际存到s里面的字符个数会变少,下面的逻辑是正确的。
if(i == 127)
{
s += buff;//+=的字符串buff是以\0结尾的
i = 0;
}
buff[i++] = ch;
ch = in.get();
}
if (i >= 0)//i代表已经插入的有效字符的个数,个数对应的下标位置正好是最后一个有效元素的下一个位置。
{
buff[i] = '\0';
s += buff;//将上面插入的\0之前的字符串+=到对象s里。
}
return in;
}
6.3 getline
1. 这里实现getline的时候,有一点小问题,对于istream类的对象在传参时,不能使用传值拷贝,编译器会自动删除掉istream类的拷贝构造(这个是死的,和引用提高效率语法无关,之前问过飞哥),防止出现浅拷贝等不确定的问题,如果想要进行解决,则需要用引用,或者自己实现深拷贝的拷贝构造函数。
2. getline和cin>>不同的地方在于,cin>>是以空格和\n作为分隔符,而getline是以\n作为分隔符的,所以在模拟实现的时候不能使用流提取来进行字符的读取,应该用istream类中的读取字符的成员函数get()来进行缓冲区的字符读取。
3. 在实现内部,我们利用+=来进行string类对象的字符的尾插。
istream& getline(istream& in, string& s)
//vs编译器会将istream类的默认构造自动删除,防止出现浅拷贝等不确定问题,所以需要用引用或者自己定义深拷贝的拷贝构造函数。
{
char ch = in.get();
while (ch != '\n')
{
s += ch;
ch = in.get();//get()一点一点从缓冲区里面拿字符,直到遇到\n,这才是getline,遇到空格和\n的应该是>>
}
return in;
}
七、讨论内置类型到底能否调用构造函数
std中的swap实际上是支持内置类型和自定义类型的函数模板,并且对于内置类型的定义,也支持了像自定义类型一样的拷贝构造、赋值重载等用法,但在平常写代码中对于内置类型我们还是用原来的写法,下面的模板写法只是为了方便兼容内置和自定义类型
template <class T> void swap ( T& a, T& b )
{
T c(a); a=b; b=c;
}
void test_string9()
{
//下面这样的写法是为了支持函数模板,有时候模板参数可能是自定义类型或内置类型,所以为了兼容内置类型,就搞了这样的写法。
int i(10);//等价于int i = 10;
int j = int();//匿名对象的赋值重载
}
所以说模板可以理解成构造函数的一个小绿灯,它可以使得内置类型也调用构造函数
希望给大家带来帮助!!!