聊聊复杂网络环境下hdfs的BlockMissingException异常|参数dfs.client.use.datanode.hostname
1 从一个复杂网络环境下的 hdfs 报错问题聊起
大家知道,企业真实的网络环境是复杂多变的,这可能有多种原因:
- 一方面,单台服务器可以安装多块网卡配置多个IP,而且还可以做网卡绑定NIC bonding/NIC teaming,链路聚合Link Aggregation等;
- 另一方面,容器技术如 docker/k8s,也通过 linux 的 network namespace 提供了多个隔离的网络命名空间和对应的多个IP;
- 还有一个原因,在采用公有云私有云混合云的部署架构时,单台服务器经常会配置一个面向外部的公网IP,和面向内部的私网IP。
在复杂的网络环境中部署并使用 hadoop 时,如果服务端的配置或客户端的使用不当,就可能会遇见各种问题:
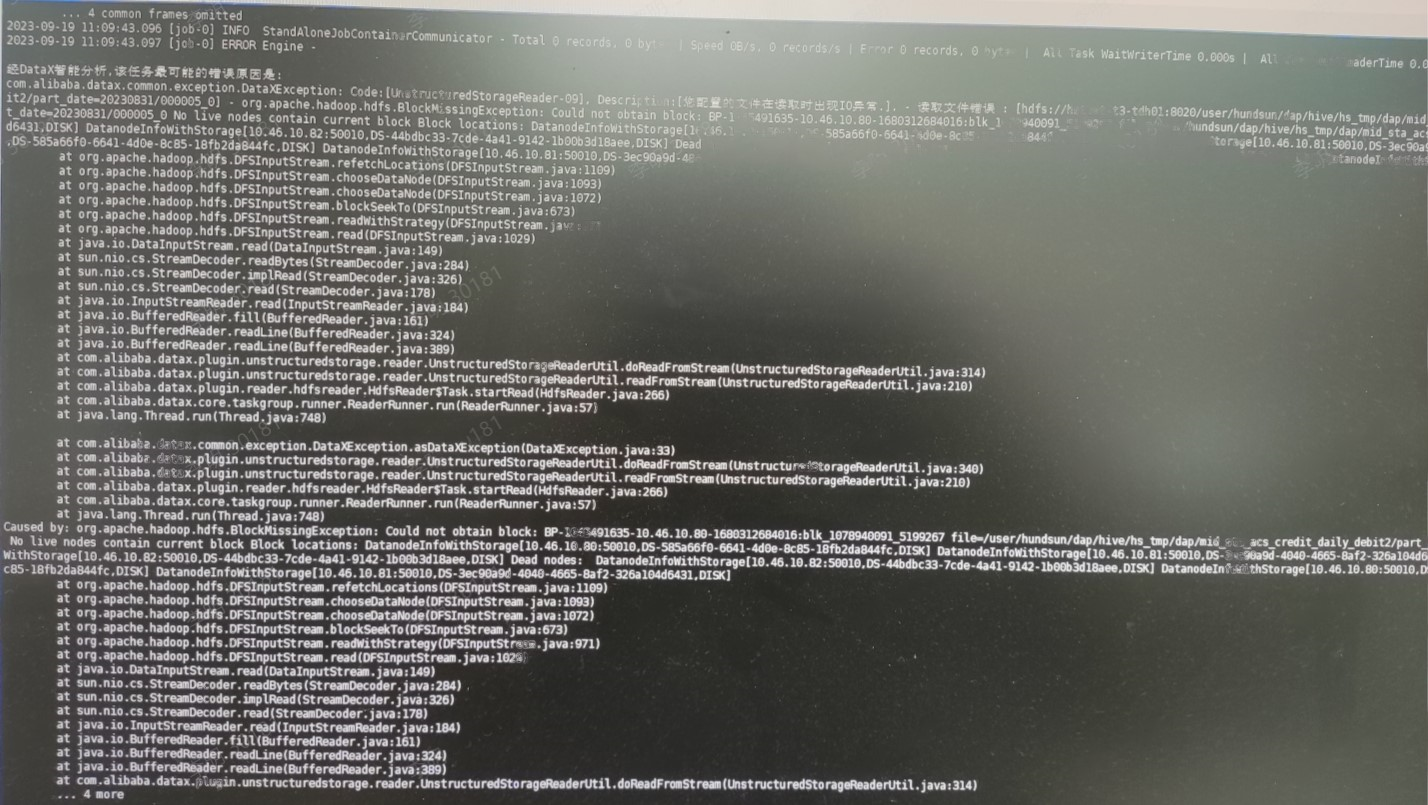
- 其中一个常见的问题是,hdfs 客户端读写 datanode 数据时报错 BlockMissingException- 在公有云如 aws EC2或阿里云 ecs上搭建 hadoop 集群时,就经常会出现该错误;
- 某示例报错的详细错误信息如下:
读取文件错误: xxx - org.apache.hadoop.hdfs.BlockMissingException: could not obtain block: BP-XXXX-10.46.10.80-XXXX:blk_xx_xx file=xxxxx: no live nodes contain current block Block locations: DatanodeInfoWithStorage[10.46.10.80:50010,DS-XX,DISK] DatanodeInfoWithStorage[10.46.10.81:50010,DS-XX,DISK] DatanodeInfoWithStorage[10.46.10.82:50010,DS-XX,DISK] Dead nodes: DatanodeInfoWithStorage[10.46.10.82:50010,DS-XX,DISK] DatanodeInfoWithStorage[10.46.10.80:50010,DS-XX,DISK] DatanodeInfoWithStorage[10.46.10.81:50010,DS-XX,DISK]
at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:1109)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:1093)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:1072)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:673)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:971)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:1029)
2 BlockMissingException 的问题原因和解决方案
BlockMissingException 的问题原因,主要有两个:
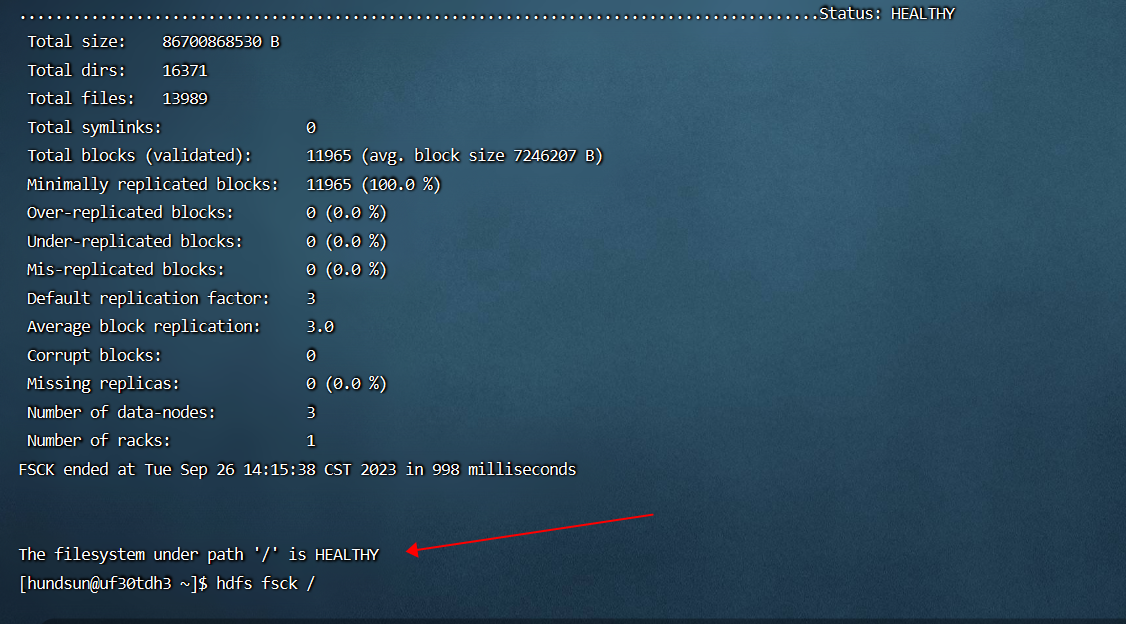
- 第一个原因是,hdfs 文件系统发生了异常,报错信息中所提示的 hdfs 块确实丢失了:此时通过命令 “hdfs fsck /”验证文件系统的完整性时,会报告丢失的块信息;(也可以由系统管理员通过命令 “hadoop dfsadmin -report”检查文件系统状态);
- 第二个原因是,hdfs 文件系统正常且没有 hdfs 块丢失,但是报错信息中所提示的 hdfs 块(比如BP-XXXX-10.46.10.80-XXXX:blk_xx_xx file=xxxxx),客户端无法通过特定的IP或HOSTNAME创建到对应 datanode 的 TCP 连接进而读取hdfs 块数据:此时通过命令 “hdfs fsck /”或 “hadoop dfsadmin -report” 检查hdfs文件系统健康状况时,都是提示文件系统时健康且完整的;
对应于上述 BlockMissingException 的两个原因,主要的解决方案也有两大类:
- 对于真实发生了hdfs block 块丢失的情形:可以进一步分析 hdfs block 丢失的原因,常见的有部分 datanode 进程启动异常,或部分 datanode节点的磁盘故障,此时针对性地进行修复并重启即可(如果丢失的数据确实无法修复,在业务确认后,可能不得不通过命令 “hdfs fsck / -delete” 删除损坏的 block对应的上层hdfs文件;)
- 对于没有发生 hdfs block 块丢失,而仅仅是由于hdfs客户端无法通过特定的IP或HOSTNAME创建到 datanode 的 TCP 连接进而读取 hdfs 块数据的情形:可能需要检查并修复客户端和 datanode之间的端口级别的网络连通性(ping datanode-ip, telnet datanode-ip datanode-port),也可能需要配置客户端参数 dfs.client.use.datanode.hostname=true;
3 参数 dfs.client.use.datanode.hostname 的技术背景
- 根据 hdfs 读写文件的内部机制: hdfs 客户端读写 hdfs 文件时,客户端首先需要创建到 namenode 的 TCP 连接,然后由 namenode 告知客户端该文件特定 block 对应的 datanode 信息,此后客户端才会去创建到特定 datanode 的 TCP 连接进而读写特定 block数据(其实这里还有个细节:namenode 会告知客户端特定 block 对应的多个 datanode,而客户端只需要创建到其中某一个 datanode 的 TCP 连接就可以读写数据了);
- 默认情况下,上述读写流程中,namenode 告知客户端该文件特定 block 对应的 “datanode 信息",该 “datanode 信息" 就是 datanode 节点的IP地址,可能是内网IP,也可能是外网IP,如果是内网IP,外部的客户端读写block数据时,就会因无法访问指定的内网IP而报错 BlockMissingException;
- 当配置参数 dfs.client.use.datanode.hostname=true时,上述读写流程中,namenode 告知客户端该文件特定 block 对应的 “datanode 信息",该 “datanode 信息" 返回的就是 datanode节点的 hostname了,如果客户端正确地配置了/etc/hosts文件或ndns服务,就可以解析该 hostname 为可访问的公网IP,就能够正常创建连接读写 block 数据了;
- 可以通过如下命令,查询相关参数的配置值:
- hdfs getconf -confKey dfs.client.use.datanode.hostname
- hdfs getconf -confKey dfs.datanode.use.datanode.hostname
- 所以概括起来,在复杂的网络环境中搭建 hadoop 集群时,比如公有云 aws EC2或阿里云 ecs,为确保不会出现上述 BlockMissingException问题:
- hadoop 服务端配置namenode/datanode 监听 wildcard 通配符地址:绑定到通配符地址"0.0.0.0" 后,私网IP和公网IP都会被监听;(set the value of dfs.namenode.rpc-bind-host to 0.0.0.0 and Hadoop will listen on both the private and public network interfaces allowing remote access and datanode access; The wildcard is a special local IP address, It usually means “any” and can only be used for bind operations.)
- (可选)hadoop 服务端配置dfs.datanode.use.datanode.hostname=ture:表示datanode之间的通信也通过域名方式,这样能够使得更换内网IP变得十分简单、方便,而且可以让特定datanode间的数据交换变得更容易,但与此同时也存在一个副作用,当DNS解析失败时会导致整个Hadoop不能正常工作,所以要保证DNS的可靠;
- 客户端配置 dfs.client.use.datanode.hostname=true;
- 客户端配置/etc/hosts文件或dns服务,将主机名与DataNode服务器的公网ip进行映射;

其实关于 Namenode 返回 datanode 信息给客户端时,到底应该用 hostname 还是 IP 来标识 datanode,不同时期 hadoop 有不同考量:
- 早期 nn 使用 hostName 来标志 dn,但为了减轻 dns 解析带来的性能下降,hadoop 通过 HADOOP-985 提供了通过IP 标识 dn 的功能;
- 后期在面对云原生和容器化带来的复杂的网络环境时,hadoop 又通过 HDFS-3150 添加了通过 hostname 标识 dn 的功能,并提供了可配置参数 dfs.client.use.datanode.hostname/dfs.datanode.use.datanode.hostname
- 其它相关jira:Using socket address for datanode registry breaks multihoming:https://issues.apache.org/jira/browse/HADOOP-6867
- Namenode should identify DataNodes as ip:port instead of hostname:port:https://issues.apache.org/jira/browse/HADOOP-985
- Add option for clients to contact DNs via hostname:https://issues.apache.org/jira/browse/HDFS-3150
- dfs.client.use.datanode.hostname: whether clients should use datanode hostnames when connecting to datanodes. default false. (clients outside cluster may not be able to route the IP)
- dfs.datanode.use.datanode.hostname:Whether datanodes should use datanode hostnames when connecting to other datanodes for data transfer.default false.
- Using socket address for datanode registry breaks multihoming:https://issues.apache.org/jira/browse/HADOOP-6867


4 相关源码与参考链接
##参考连接:
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsMultihoming.html
- https://stackoverflow.com/questions/25135183/hadoop-binding-multiple-ip-addresses-to-a-cluster-namenode
- https://rainerpeter.wordpress.com/2014/02/12/connect-to-hdfs-running-in-ec2-using-public-ip-addresses/
##相关源码:
org.apache.hadoop.hdfs.DFSInputStream#getBestNodeDNAddrPair
org.apache.hadoop.hdfs.DFSInputStream#readBlockLength
org.apache.hadoop.hdfs.DFSInputStream#allBlocksLocal
org.apache.hadoop.hdfs.DFSClient#connectToDN
org.apache.hadoop.hdfs.DFSUtilClient#connectToDN
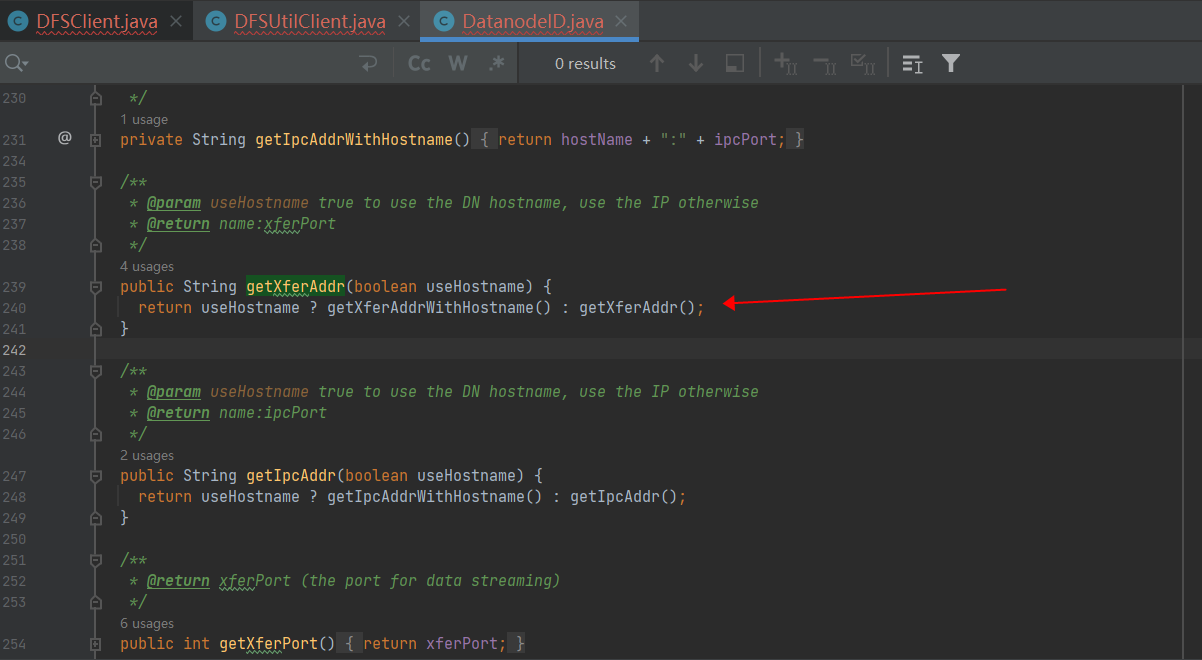
org.apache.hadoop.hdfs.protocol.DatanodeID#getXferAddr(boolean)
org.apache.hadoop.hdfs.DataStreamer#createSocketForPipeline
org.apache.hadoop.hdfs.client.impl.BlockReaderLocalLegacy#getBlockPathInfo
org.apache.hadoop.hdfs.client.impl.DfsClientConf#isConnectToDnViaHostname
org.apache.hadoop.hdfs.protocolPB.ClientDatanodeProtocolTranslatorPB#ClientDatanodeProtocolTranslatorPB(org.apache.hadoop.hdfs.protocol.DatanodeID, Configuration, int, boolean)