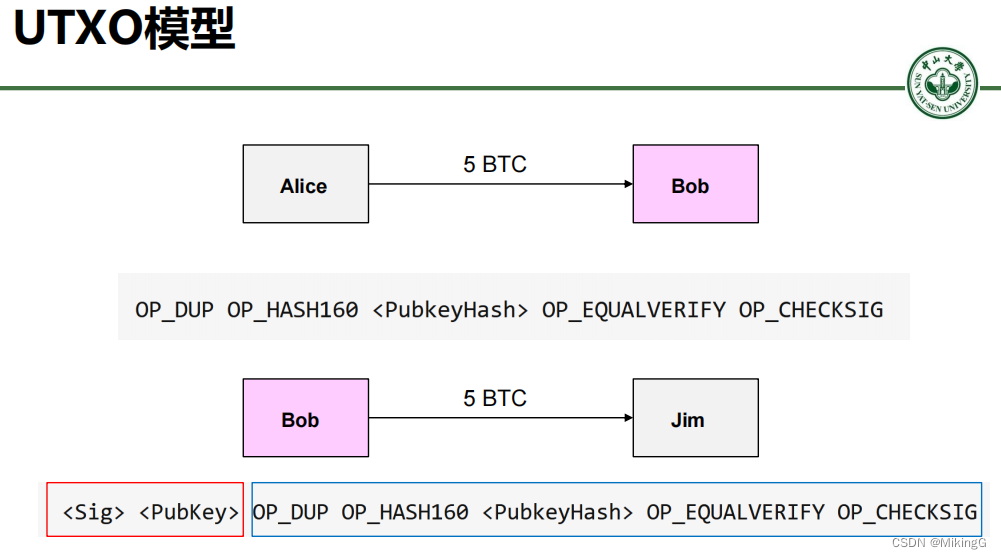
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🔥 上万人涌入抖音国货直播间,朴实「商战」带火国民品牌

谁能想到,李佳琦「华西子事件」意外带火了一众国货品牌的直播间!蜂花、活力28、郁美净、白象、万紫千红、精心……
原来我们印象中的那些品牌还在,而且物美价廉!各品牌疯狂整活联动,直播间由原来的两位数飙升至数千乃至上万人。
围绕这一热点,最先出现的AI作品是品牌形象的拟人化创作——根据品牌的经典配色、产品特点等,创作了系列人物形象,非常可爱。注意!这类作品的数量和类型还比较有限,创作空间挺大的!感兴趣的小伙伴可以上手试试~
🔥 华为秋季全场景新品发布会,遥遥领先的「科技春晚」

9月25日,华为举办了「秋季全场景新品发布会」,带来了包括全新华为MatePad Pro 13.2英寸、华为WATCH ULTIMATE DESIGN非凡大师、华为智慧屏 V5 Pro、华为FreeBuds Pro 3、华为智能眼镜 2、华为WATCH GT 4等在内的多款全场景新品,并公布售价。当然,没提手机和芯片。

这场发布会风格非常独特!中国交响乐团和中国音乐学院青年爱乐乐团,开场便在现场演绎了歌曲「我的梦」,直接将气氛拉满;刘德华现身发布会现场将气氛再推向高潮,身为「华为Mate 60 RS非凡大师品牌大使」,他分享了自己对于「非凡大师」的理解;发布会结尾,华为员工集体登台合唱了一首改编版本的「光辉岁月」,他们举起手机晃动双臂,让人想哭 ⋙ 全程回顾 | 知乎问题讨论

🎯 500+ AI岗位合辑,支持按照岗位/公司/城市/发布日期进行分类检索
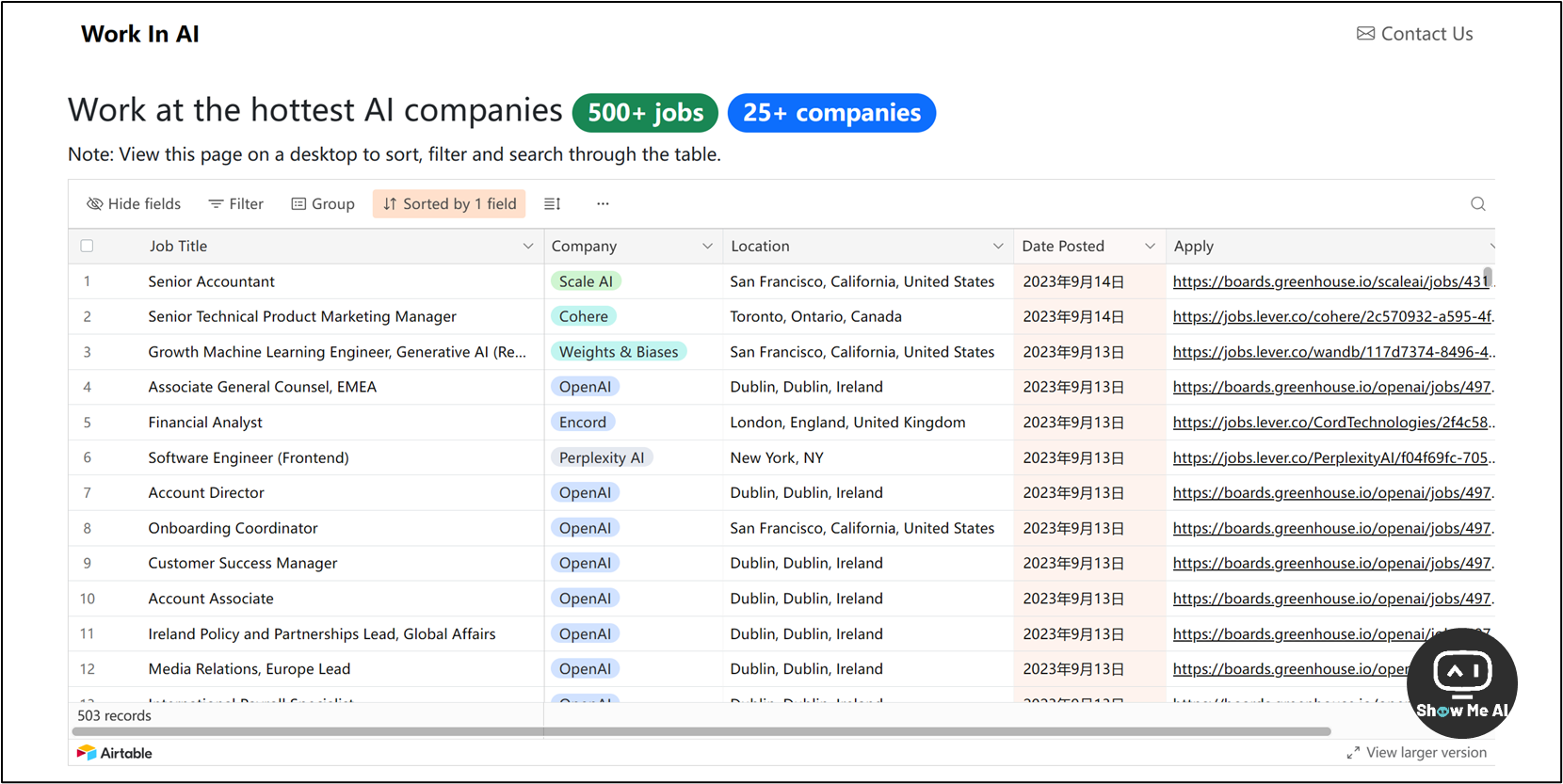
https://workinai.xyz
这是一份AI岗位的合辑,目前包含了500+相关岗位 (目前仅限于美国),支持按照岗位、公司、城市进行检索,实时更新到了9月份,并且附上了完整的岗位JD。
国内似乎还没看到此类招聘信息的合辑,不过可以研究下某类岗位的技能栈,提前学习和准备起来~

🏆 百川智能 x 亚马逊云科技AI黑客松,覆盖医疗健康/游戏娱乐两个赛道

百川智能携手亚马逊云科技、上海AI会客厅,将于10月在上海举办「百川智能×亚马逊云科技AI黑客松」大赛,深入探索大模型在「医疗健康」和「游戏娱乐」领域的前沿应用。
医疗健康赛道:包括但不限于使用百川大模型在中西医医疗领域以及大健康领域的实践落地
游戏娱乐赛道:包括但不限于使用百川大模型在游戏创作、内容生成领域,以及其他泛娱乐应用方面的实践落地
报名截止时间顺延到10月7日23点59分。线下赛的时间正式确定为10月13日至10月15日。每个赛道都设冠军、亚军、季军,亚马逊云科技额外设立了Awesome Star特别奖,食宿差旅报销而且可以获得免费算力微调和使用Baichuan 2大模型 ⋙ 了解更多 | 报名表

👀 AI产品经理视角:如何构建人工智能产品
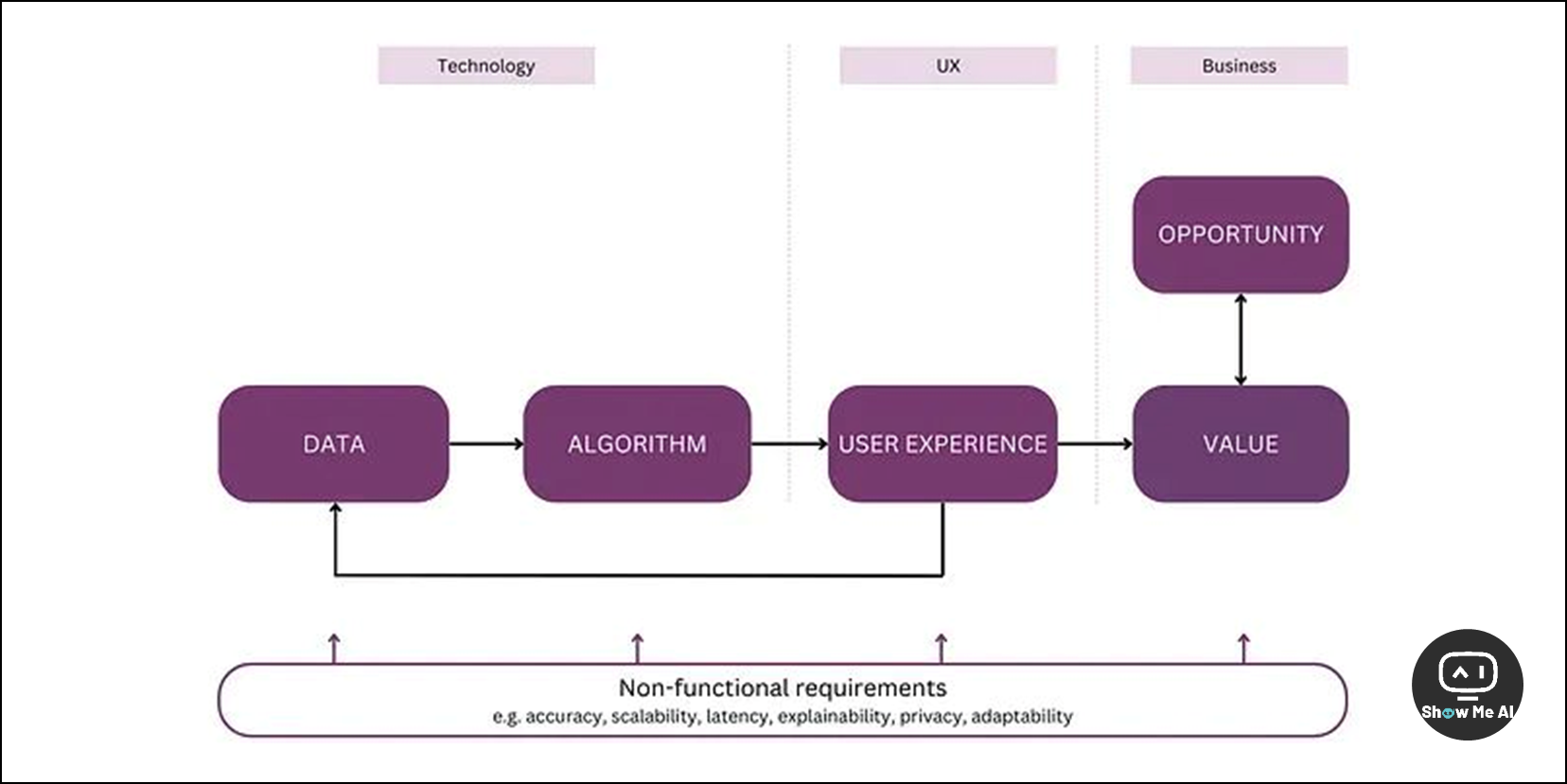
将AI集成到已有产品中,是一件困难重重且效果较差的事情。导致这个现象的原因有很多,比如团队只关注人工智能系统的某一个方面、人工智能的开发需要一个高度协作的团队、低估了产品设计的重要性、受到了市场舆论的压力等等。
这篇文章里,作者就提出了一个包含商业机会、用户价值、数据、算法、用户体验、非功能需求等多个维度的人工智能系统心智模型,强调从商业出发,依据市场机会并综合考量其他各方面的需求,来推动人工智能产品开发。
模型如上图所示,文章对各个维度进行了详细解释,以下是关键内容总结:
以终为始:将人工智能集成到产品中并推向用户,需要一个清晰的路线图,不要仅靠技术就能完成的
市场契合:优先考虑市场机会和客户需求,不要在没有经过市场验证的情况下,通过炒作推动人工智能的实施
用户价值:从效率、个性化、便捷性等价值维度定义、量化和传达AI产品的价值
数据质量:关注数据质量与AI模型有效训练的相关性,尝试使用小型、高质量的数据进行微调,并使用较大的数据集从头开始进行训练
算法/模型选择:为用例选择正确的复杂性和防御性级别,并仔细评估其性能,并随着时间的推移切换到更高级的模型策略
以用户为中心的设计:考虑用户的需求和情感,平衡自动化和用户控制,注意概率人工智能模型的「不可预测性」,并引导用户使用它并从中受益
协作设计:通过强调信任、透明度和用户教育,让用户与人工智能进行协作
非功能性需求:在整个开发过程中,考虑并权衡准确性、延迟、可扩展性和可靠性等因素
协作:促进人工智能专家、设计师、产品经理和其他团队成员之间的密切协作 ⋙ 阅读原文

🚀 企业级AI行业图谱「Market Map」,生态的丰富与拓展

企业在构建AI应用时会面临诸多难题,比如数据质量差、算法过度依赖等。企业AI应用的构建,除了基础大模型之外还需要大量的相关工具,以满足需求并规避法律风险。这些工具共同构成了一个非常丰富的生态,并在快速拓展中。
这篇文章就对这个工具生态进行了分类和整理,并详细解释了板块定位与功能、创始人和投资人的判断、典型公司介绍等:
隐私、安全和合规平台 (Privacy, safety and compliance platforms):保护企业免受集成LLM的法律、合规和隐私风险
数据集成和存储平台 (Data Integration and Storage Platforms):将企业数据源连接到LLM
中间件和应用程序构建器 (Middleware and application builders):构建生产级LLM驱动的内部工具、功能和应用程序
可观测性、监测和评估 (Observability, Monitoring and Evaluation):监测、排除故障和回滚LLM驱动的应用程序和功能
向量数据库 (Vector databases):用向量表示数据以执行ML任务,并对该数据训练模型,并正确地存储它
模型开发、托管和部署 (Model development, hosting and deployment):廉价、高效和安全地开发、部署和托管ML模型 ⋙ 阅读原文(英语) | 中文版(上) | 中文版(下)

👩💻 大语言模型 (LLM) 算法工程师 | 100道面试题与参考答案
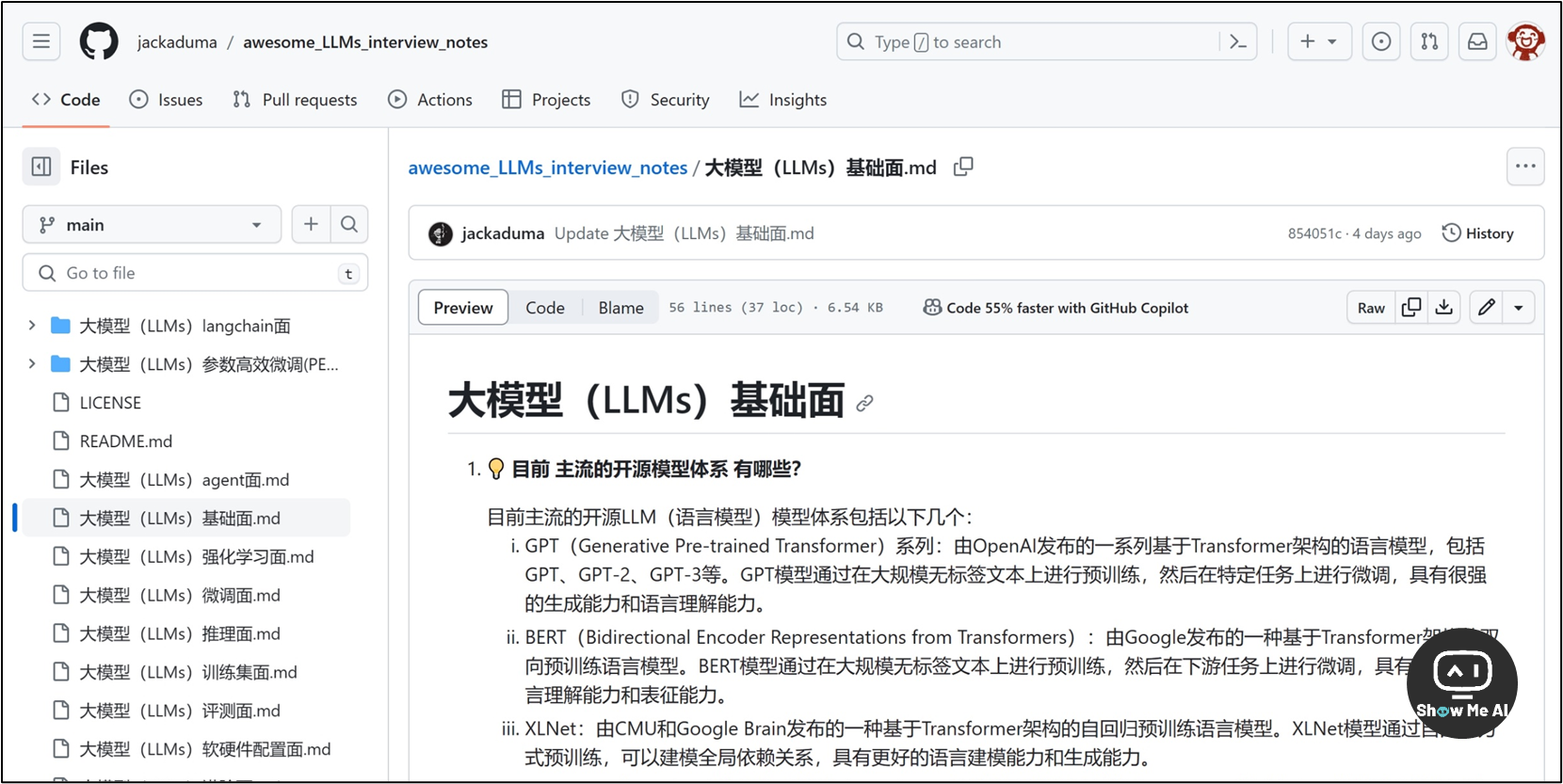
大语言模型岗位的招聘机会越来越多,ShowMeAI社区和日报也在持续分享,有心的同学已经开始进入学习和筹备状态了!
这份资料收集梳理了大语言模型的几大类面试题目,并梳理出了详细的参考答案,推荐收藏啊!也可以前往 GitHub 给作者 ⭐Star 一下~
大模型基础面
大模型进阶面
大模型微调面
大模型 langchain 面
大模型参数高效微调 (PEFT) 面:适配器微调 (Adapter-tuning) 篇、提示学习 (Prompting)、LoRA 系列篇
大模型推理面
大模型评测面
大模型强化学习面
大模型软硬件配置面
大模型训练集面
大模型显存问题面
大模型分布式训练面
大模型 agent 面 ⋙ 查看题目与答案

📚 符尧最新长文:别卷大模型训练了,来卷数据吧!

相信一直在追踪 NLP 领域的伙伴对 符尧 并不陌生。2022年11月底 ChatGPT 发布,两周后符尧的长文「拆解追溯 GPT-3.5 各项能力的起源」刷爆AI圈,非常仔细检查了GPT-3.5系列的能力范围,并追溯了它们所有突现能力的来源。
这是他最新的「Data Engineering (数据工程)」博文,讨论了数据工程应该解决什么问题,以及基本指导原则。在开源社区的研究热点逐渐转向数据工程时,这样的讨论非常有意义,可以帮助我们在正式跑实验前预测每个task最终的performance。
具体来说,博文讨论预训练和 SFT 数据优化的以下目标:
预训练阶段数据优化:找到最优的混合比例+数据格式+数据课程=> 使学习速度最大化
监督微调/指令阶段调整数据优化:寻找最小的 query-response pairs (最小的训练数据) =>使用户偏好分布的覆盖范围最大
博文的关键结论:
解释了可能更好的衡量评估指标 speed of grokking (获取某技能的速度) 是什么,其可能更具有泛化性并且更贴近于特定的skill能力
分析mix ratio (数据混合比例) + data format (数据格式) + data curriculum (数据课程) 以及模型规模对speed of grokking的影响
讨论 LLM 模型最终学习到的是什么,以及可能的一些更好衡量模型效果的metrics ⋙ 阅读原文 | 中文翻译版 | 拆解追溯 GPT-3.5 各项能力的起源
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!