《学术小白学习之路》基于Python实现中文文本的DTM主题动态模型构建
- 一、数据选择
- 二、数据预处理
- 三、输入数据ID映射词典构建
- 四、文档加载成构造语料库
- 五、DTM模型构建与结果分析
- 六、结果进行保存
- 七、保存模型
一、数据选择
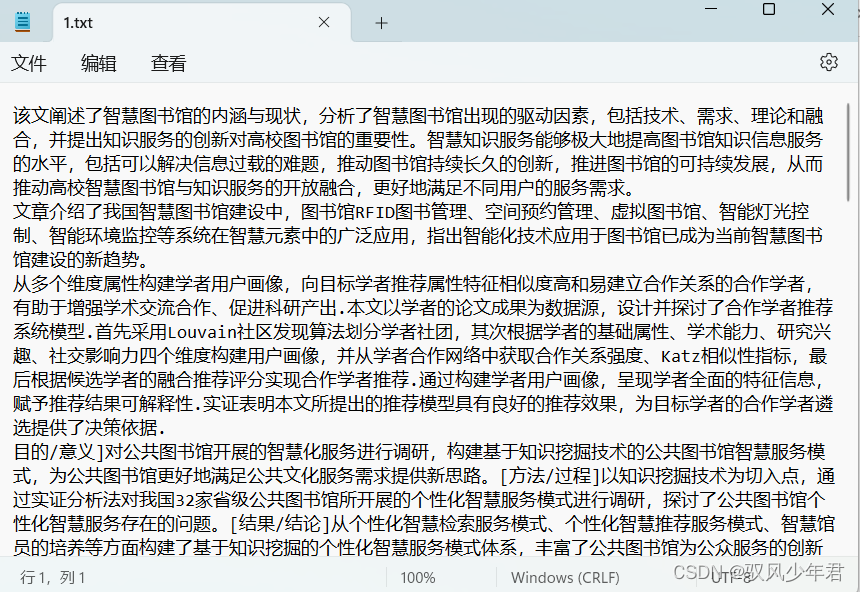
所选取的数据集是论文摘要,作为实验数据集,共计12条数据信息。每一条代表一条数据信息
主要注意的是本文用的是txt的数据集,而且每一个文档用换行的符号进行划分。
获取的数据主要为中文的数据所以需要进行清洗处理
二、数据预处理
导入相应的库
#encoding=utf-8
from __future__ import unicode_literals
import sys
sys.path.append("../")
import re
import jieba
import jieba.posseg
import jieba.analyse
import re
首先需要将数据集中进行分词,同时过滤掉一些标点符号
数据保存在本地的一个1.txt文件就可以
同时,将生成的分词文件命名为1.data.txt文件
f = open('1.txt', 'r', encoding='utf-8')
new_f = open("1.data.txt", "w", encoding="utf-8")
lines = f.readlines()
遍历每个行的数据,用正则清洗掉数据中的标点符号
r = ‘[’,。!"#$%&’()*+,-./:;<=>?@[\]^_`{|}~]+'——表示[]中的符号用re.sub(r, ‘’,line)替换成空,可以自己添加
同时将清洗后的数据进行分词为,并将每个词用“ ”空格隔开
将分词后的数据写入1.data.txt文件
# 代码缺少中文标点符号逗号之类的,不全,分词结果会存在标点符号
r = '[’,。!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~]+'
n = 0
for line in lines:
print(line)
n += 1
line = re.sub(r, '',line)
line = ' '.join(jieba.cut(line))
new_f.write(line)
print(line)
print('一共有{}篇文档'.format(n))
分词后的数据格式如下

三、输入数据ID映射词典构建
其中logging用于查看执行日志,导入的gensim版本是gensim-3.8.3,根据自己系统要求以及pyhton版本选择合适的版本,强调一下最好使用3.8.3版本,不然会报错。
#coding:utf-8
# 1.首先导入相关模块:
import logging
import sys
from gensim import corpora
from six import iteritems