文章目录
- 前言背景📜
- 第一步:打开亚马逊商城🛍️
- 第二步:定位搜索框并搜索iphone15🔍
- 第三步:定位具体数据并保存到csv文件💾
- 第三步:多页面数据抓取📄📄📄
- 第四步:动态住宅代理进行数据抓取🌐
- 第五步:分析抓取的数据📊
- 完整代码💻
前言背景📜
在数字化日益盛行的今天,网页抓取已经成为了获取海量信息的必备技能。然而,随着各大网站加强反爬虫策略,传统的数据采集方式逐渐面临挑战。🚫尤其是当我们频繁地从同一IP地址发起请求时,很容易被目标网站识别并封禁。面对这样的困境,我们该如何确保数据采集的稳定与高效呢?一个简单而有效的策略便是利用IP代理。而在众多的IP代理提供商中,亮数据(Bright Data) 以其稳定、高效和专业的服务受到了广大用户的青睐。在接下来的内容中,我们将深入探讨如何结合 亮数据Bright Data 的动态IP代理和Selenium工具,成功抓取亚马逊的数据,从而轻松绕过各种反爬策略,确保数据采集的流畅进行。
相关知识我已经在书籍中有介绍,这里是书籍介绍:《Python网络爬虫入门到实战》
🌟这篇文章将为您揭示如何结合 亮数据Bright Data 的先进技术,成功抓取亚马逊的数据,从而轻松绕过各种反爬策略。
第一步:打开亚马逊商城🛍️
选择一个合适的市场进行数据抓取是成功的第一步。亚马逊,作为全球最大的电商平台,无疑是数据采集的宝藏💎。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import csv
# 初始化浏览器
driver = webdriver.Chrome()
# 打开亚马逊网站
driver.get("https://www.amazon.cn/")
如下所示:
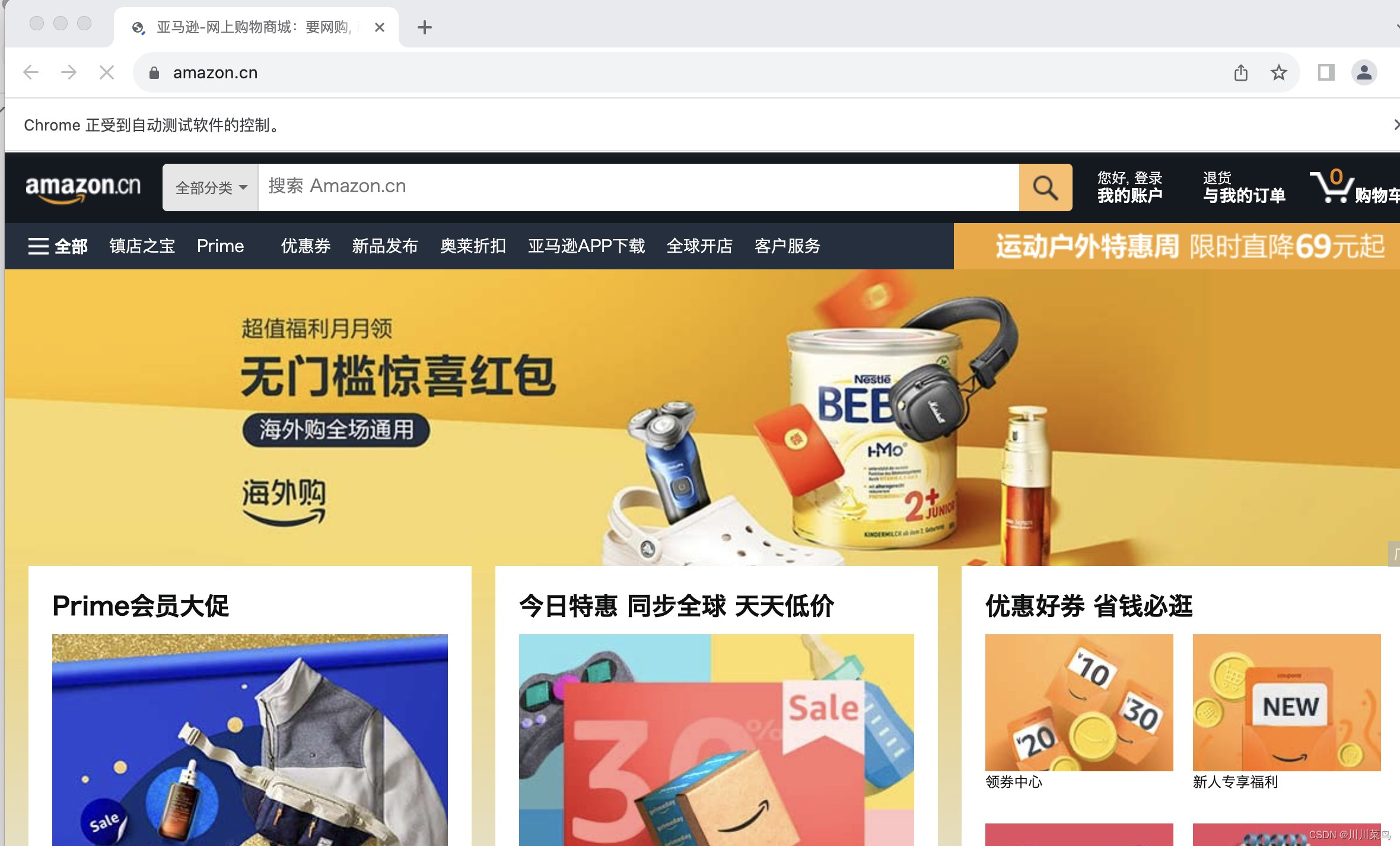
第二步:定位搜索框并搜索iphone15🔍
如图所示进行定位分析:
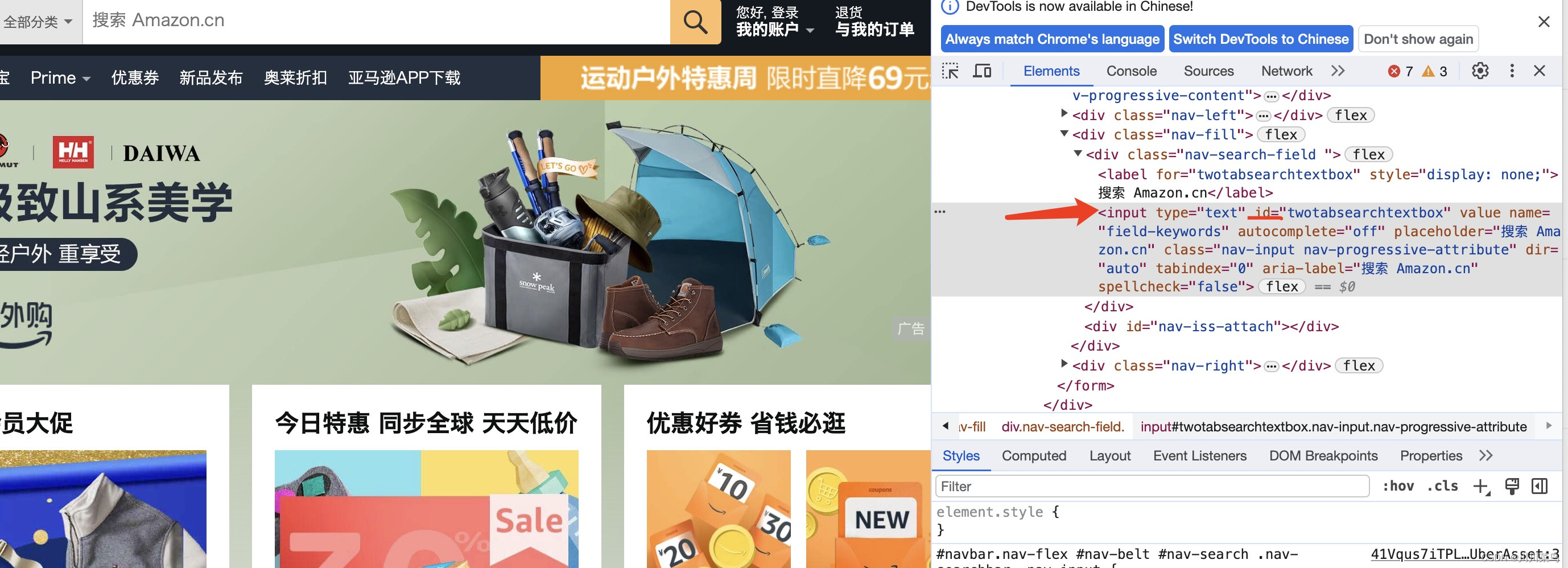
因此进行定位并搜索iphone15相关商品:
# 在搜索框中输入“iPhone 15”
search_box = driver.find_element(By.ID, "twotabsearchtextbox")
search_box.send_keys("iPhone 15")
search_box.send_keys(Keys.RETURN)
运行如下所示:
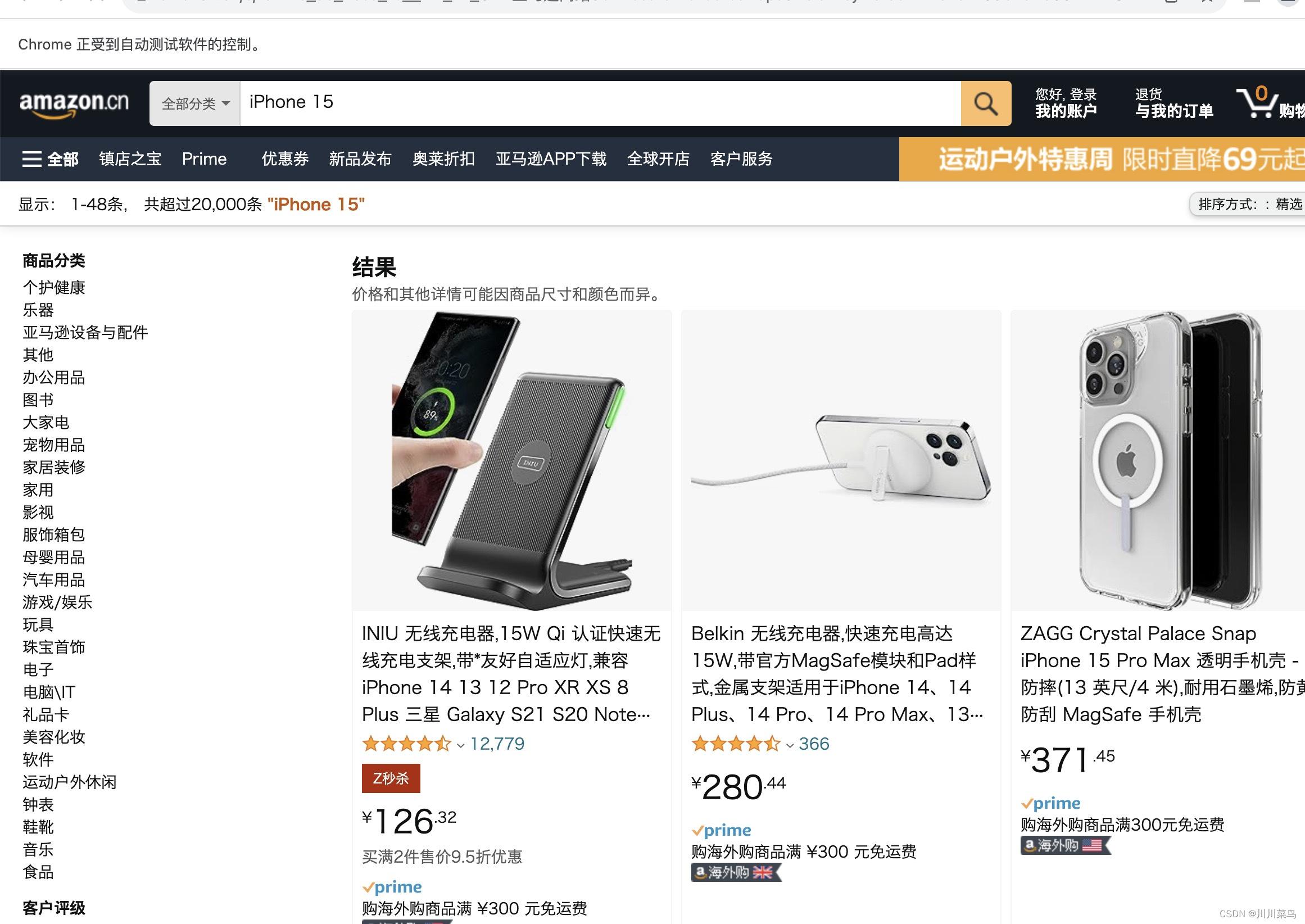
第三步:定位具体数据并保存到csv文件💾
定位页面所有数据:
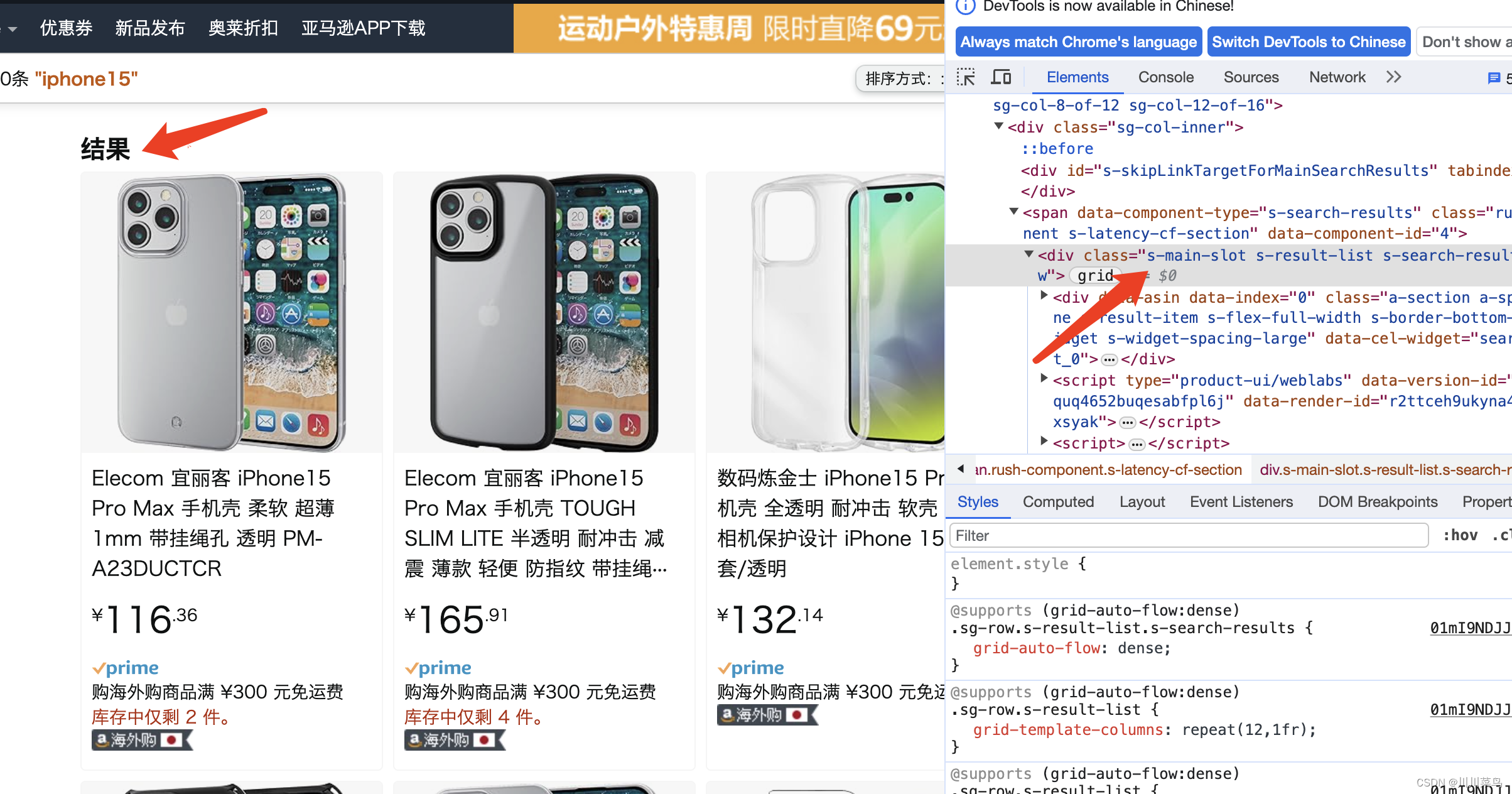
价格定位:
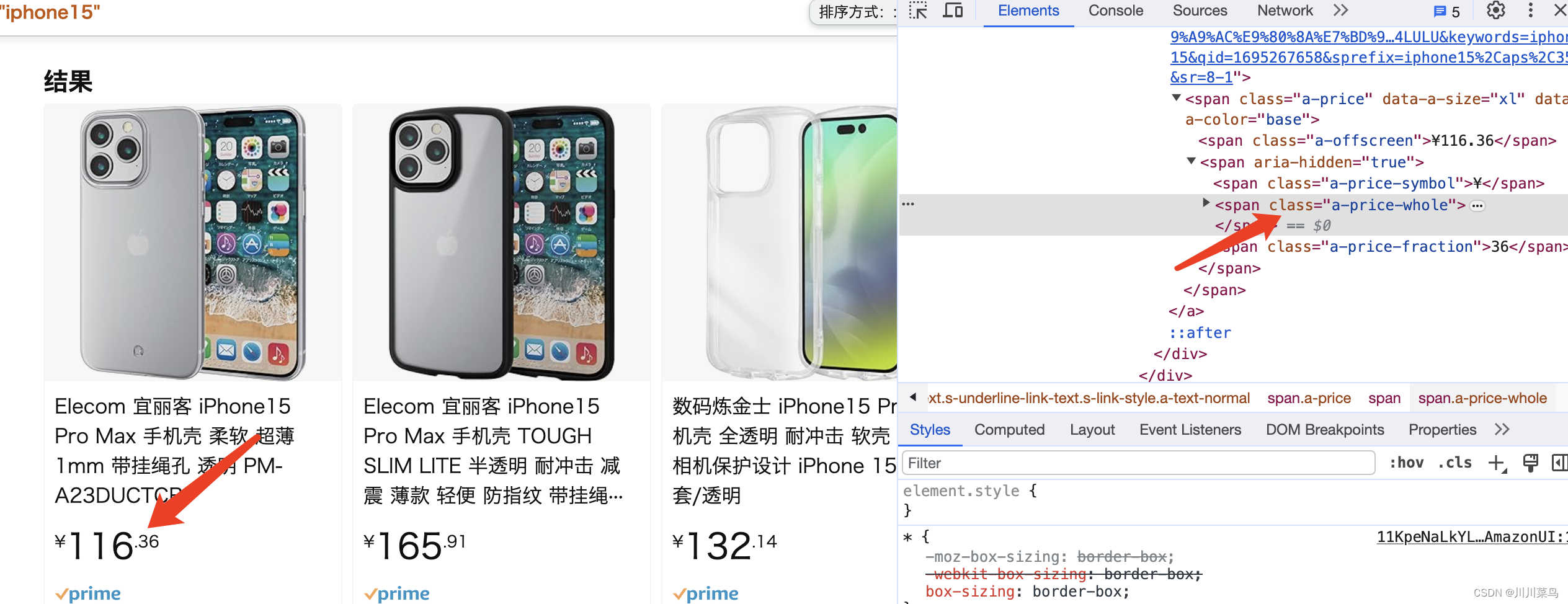
标题定为:
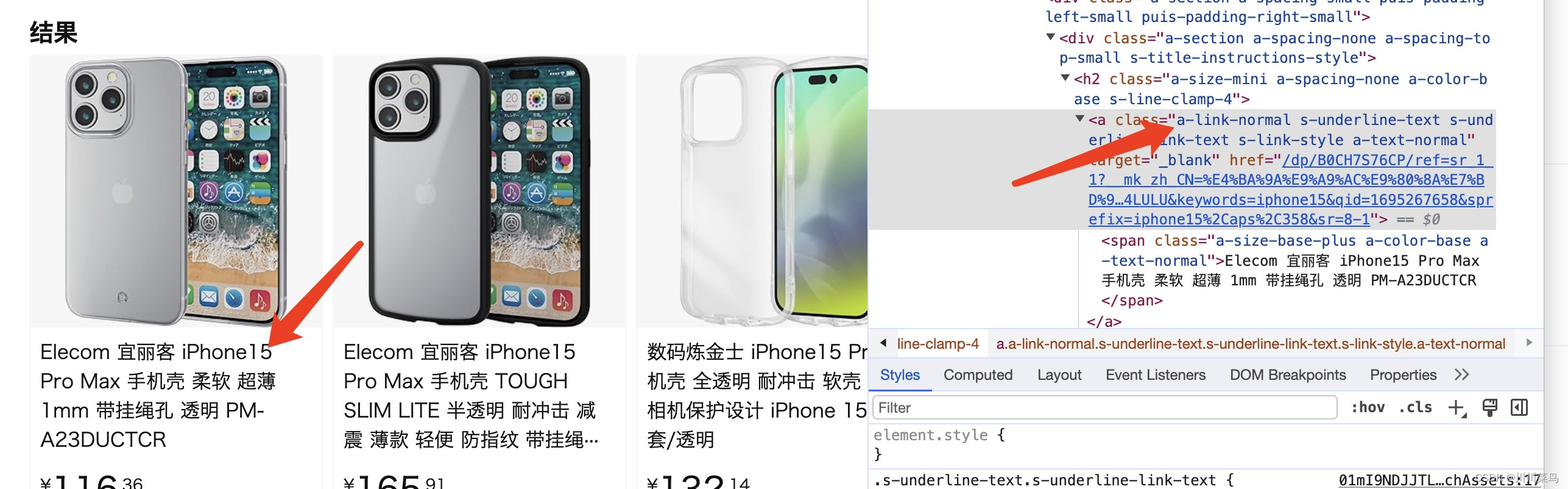
图片定位:
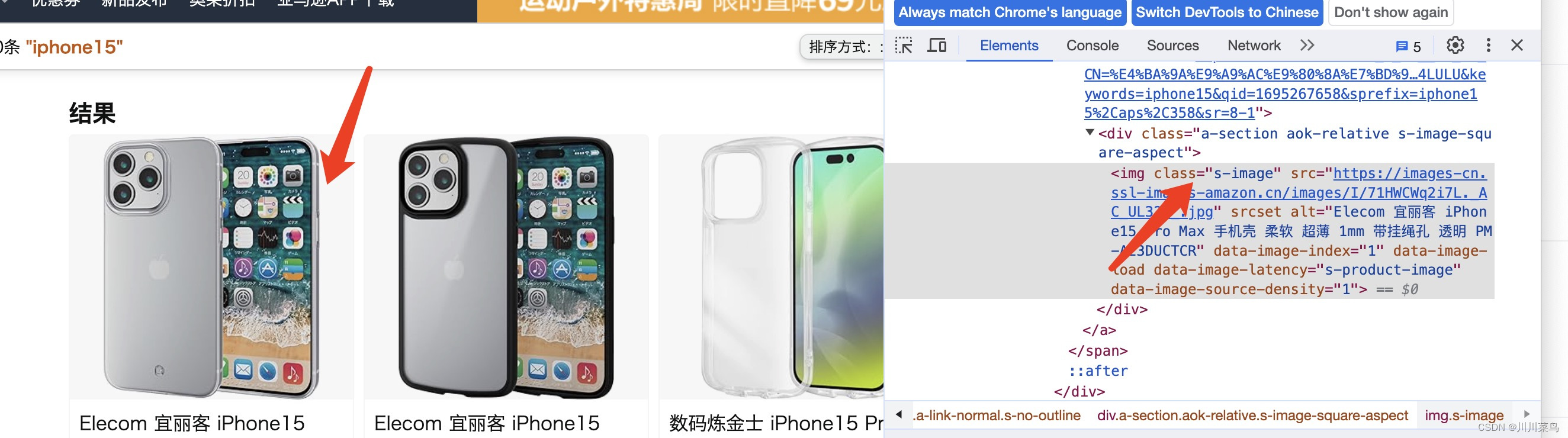
因此代码如下:
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
# 创建CSV文件并写入数据
with open('amazon_products.csv', 'w', newline='', encoding='gbk') as csvfile:
fieldnames = ['Title', 'Price', 'Image URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for index, product in enumerate(product_elements):
try:
title = product.find_element(By.CSS_SELECTOR, ".a-text-normal").text
price = product.find_element(By.CSS_SELECTOR, ".a-price-whole").text
image_url = product.find_element(By.CSS_SELECTOR, "img.s-image").get_attribute("src")
print(f"Product {index + 1}:")
print(f"Title: {title}")
print(f"Price: {price} USD")
print(f"Image URL: {image_url}")
# 写入CSV文件
writer.writerow({'Title': title, 'Price': price, 'Image URL': image_url})
except Exception as e:
print(f"Skipping product {index + 1} due to missing information.")
time.sleep(2)
# 关闭浏览器
driver.quit()
运行并得到抓取到文件如下:
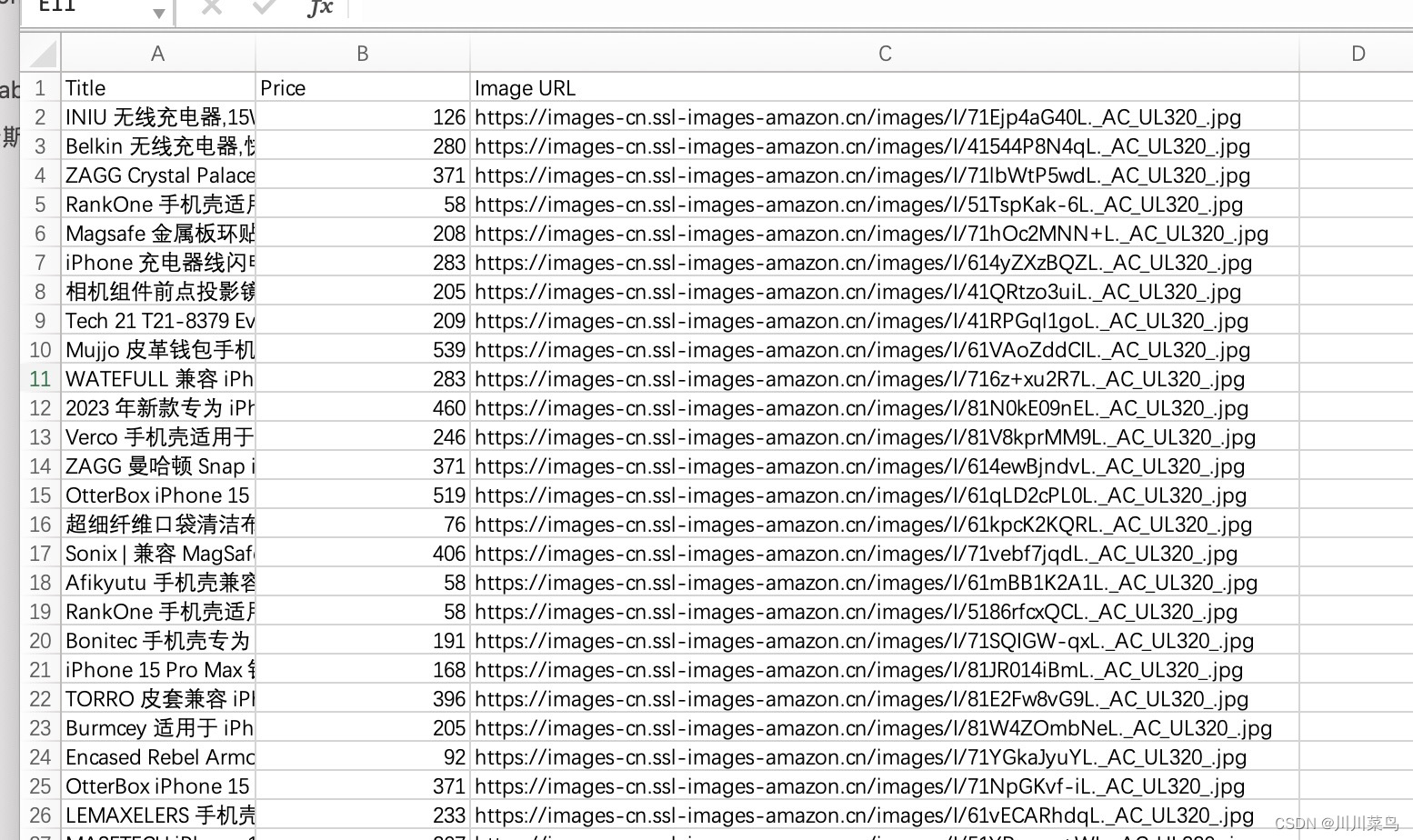
第三步:多页面数据抓取📄📄📄
对于大量的数据,单页面抓取远远不够。如果使用个人的IP进行大量数据抓取又会被封IP,但有了 亮数据Bright Data ,多页面数据抓取变得轻而易举。思路:一个页面抓取完,点击下一页继续抓取即可,定位如下所示:
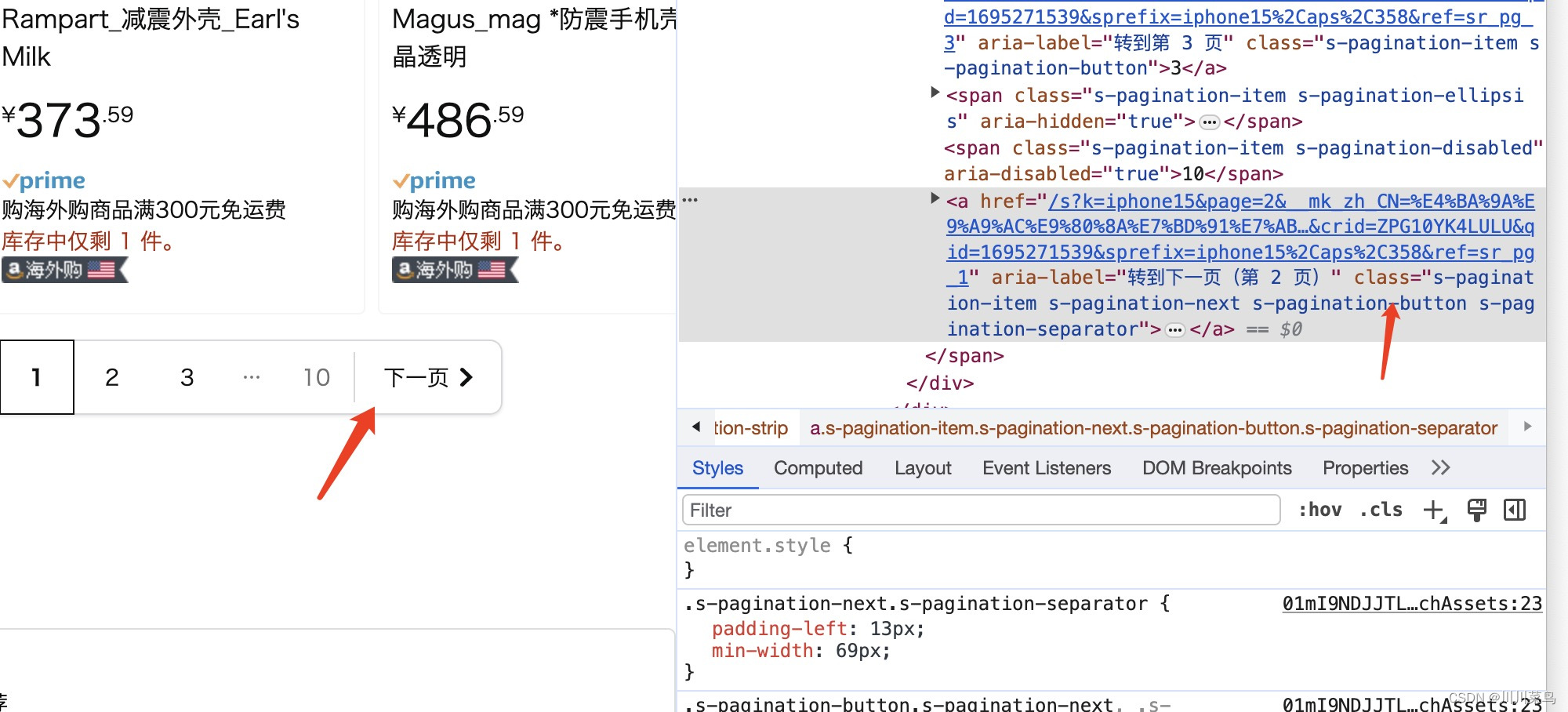
这里为了避免我们的ip被官方查出来,暂时以抓取三个页面数据进行实践,在下一个小节中我将展示如何用代理ip来进行更多大规模抓取:
# 创建CSV文件并写入数据
with open('amazon_products_multiple_pages.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Title', 'Price', 'Image URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 循环遍历多个页面,这里避免被反扒,先暂时用三个页面试试水
for page in range(1, 3):
print(f"Scraping page {page}..")
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
for index, product in enumerate(product_elements):
try:
title = product.find_element(By.CSS_SELECTOR, ".a-text-normal").text
price = product.find_element(By.CSS_SELECTOR, ".a-price-whole").text
image_url = product.find_element(By.CSS_SELECTOR, "img.s-image").get_attribute("src")
print(f"Product {index + 1}:")
print(f"Title: {title}")
print(f"Price: {price} RMB")
print(f"Image URL: {image_url}")
# 写入CSV文件
writer.writerow({'Title': title, 'Price': price, 'Image URL': image_url})
except Exception as e:
print(f"Skipping product {index + 1} due to missing information.")
# 点击“下一页”按钮
try:
next_button = driver.find_element(By.CSS_SELECTOR, ".s-pagination-next")
next_button.click()
time.sleep(3) # 等待下一页加载
except Exception as e:
print("No more pages to scrape.")
break
第四步:动态住宅代理进行数据抓取🌐
Selenium代码中使用上述动态代理的方法:
- 首先,使用代码获取动态IP。
- 然后,配置Chrome WebDriver以使用该代理。
- 最后,使用配置好的WebDriver进行网页抓取。
动态住宅代理IP是真实用户家庭IP,比如你我他家里的IP,这样的IP在被访问网站看来,代表的是真实的个体,真人用户。其高隐匿性,且不断轮动,很难被标注和识别,在采集挖掘反爬技术高超网站的数据信息时,威力很大。但是要找到一个优质且足量的动态住宅IP网络并不容易。
在众多我曾使用的商用代理供应商中,以色列的 “亮数据Bright Data” 无疑是我最为推荐的选择。在撰写爬虫文章系列时,我经历了多家供应商的对比,但每一次,亮数据Bright Data 总能为我带来卓越的满意度。
我们选择了 亮数据Bright Data 的动态住宅代理IP服务,官方网站👉:亮数据 Bright Data。为企业用户提供了一个独特的福利:首次注册的公司用户,有机会免费体验他们的服务。我们都知道,在网络数据抓取领域,动态住宅IP扮演着不可或缺的角色。而 亮数据Bright Data 拥有超过7000万的动态真人IP网络,确保了爬虫的高效、准确抓取。
注册进入官网后开通使用动态住宅代理:
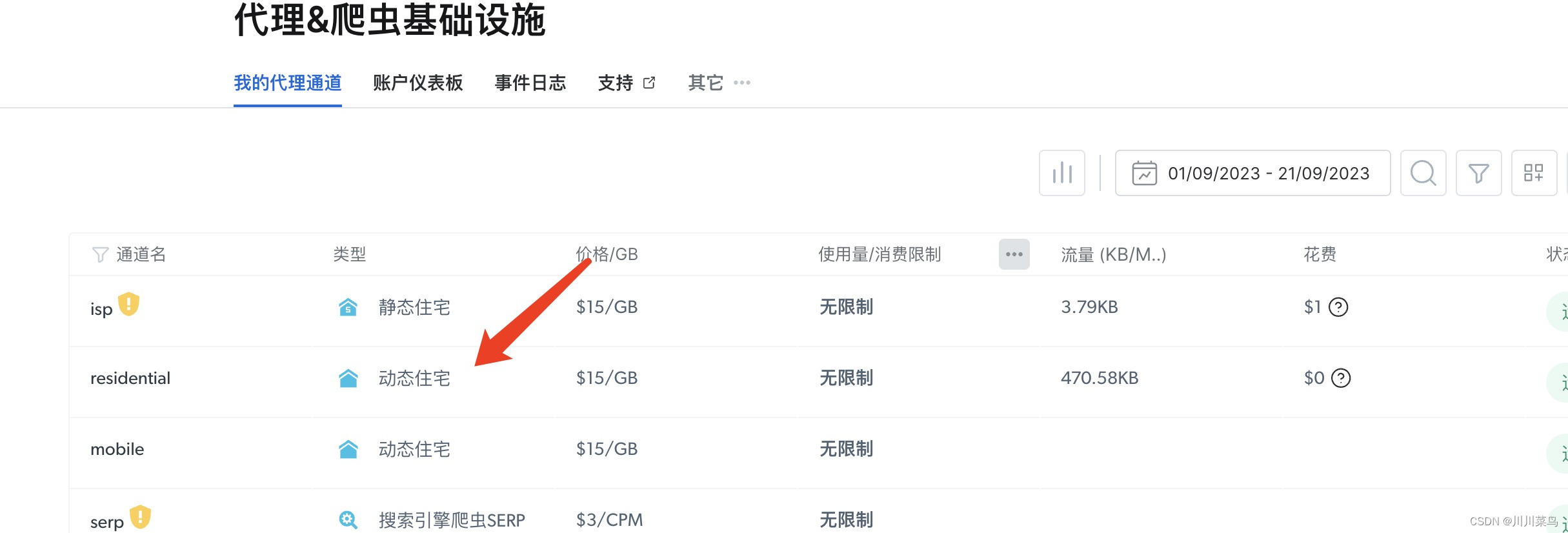
进入后可以查看一些参考代码:
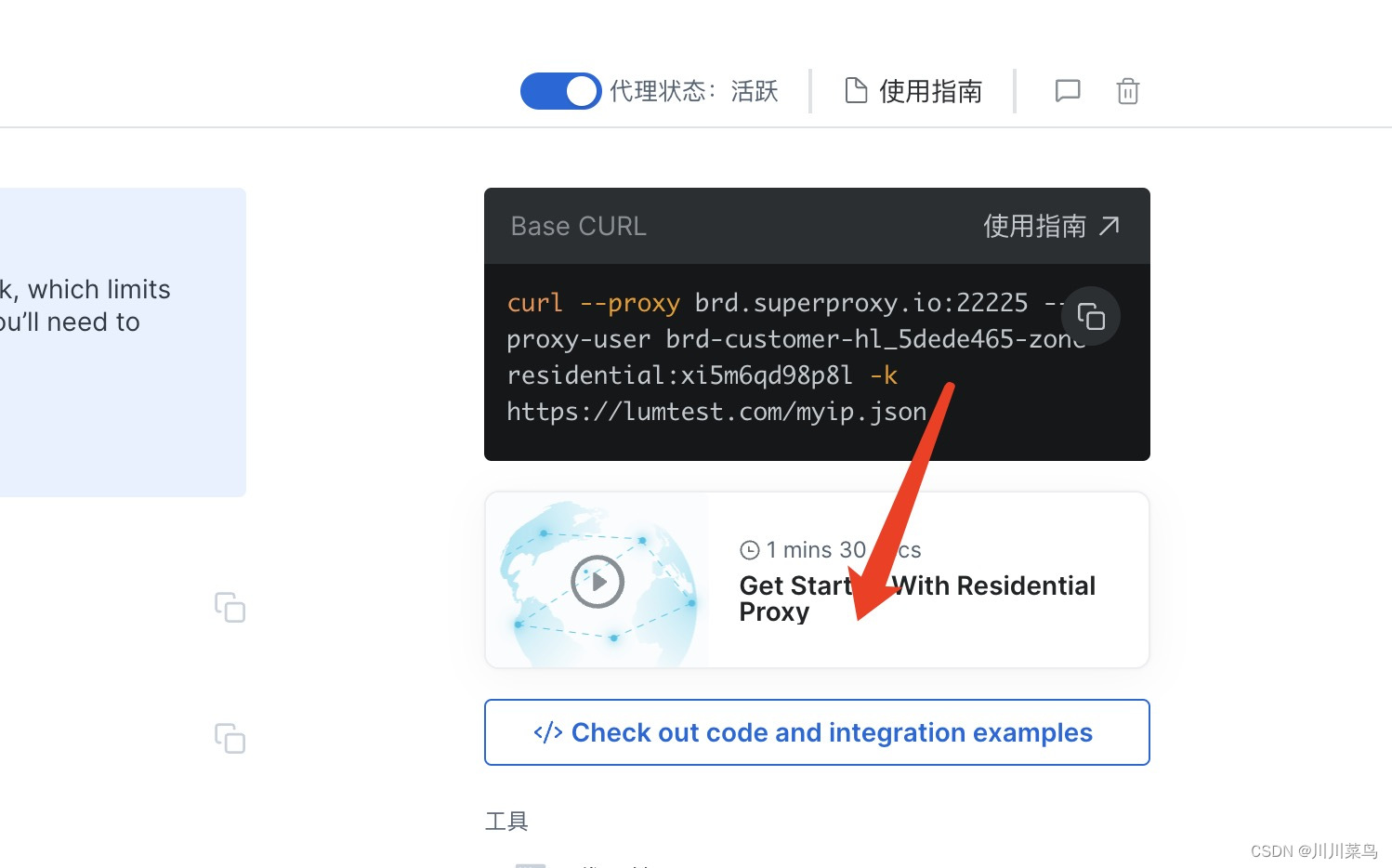
自定义一个国家,由于亚马逊是美国,所以我们选择定位美国的ip:
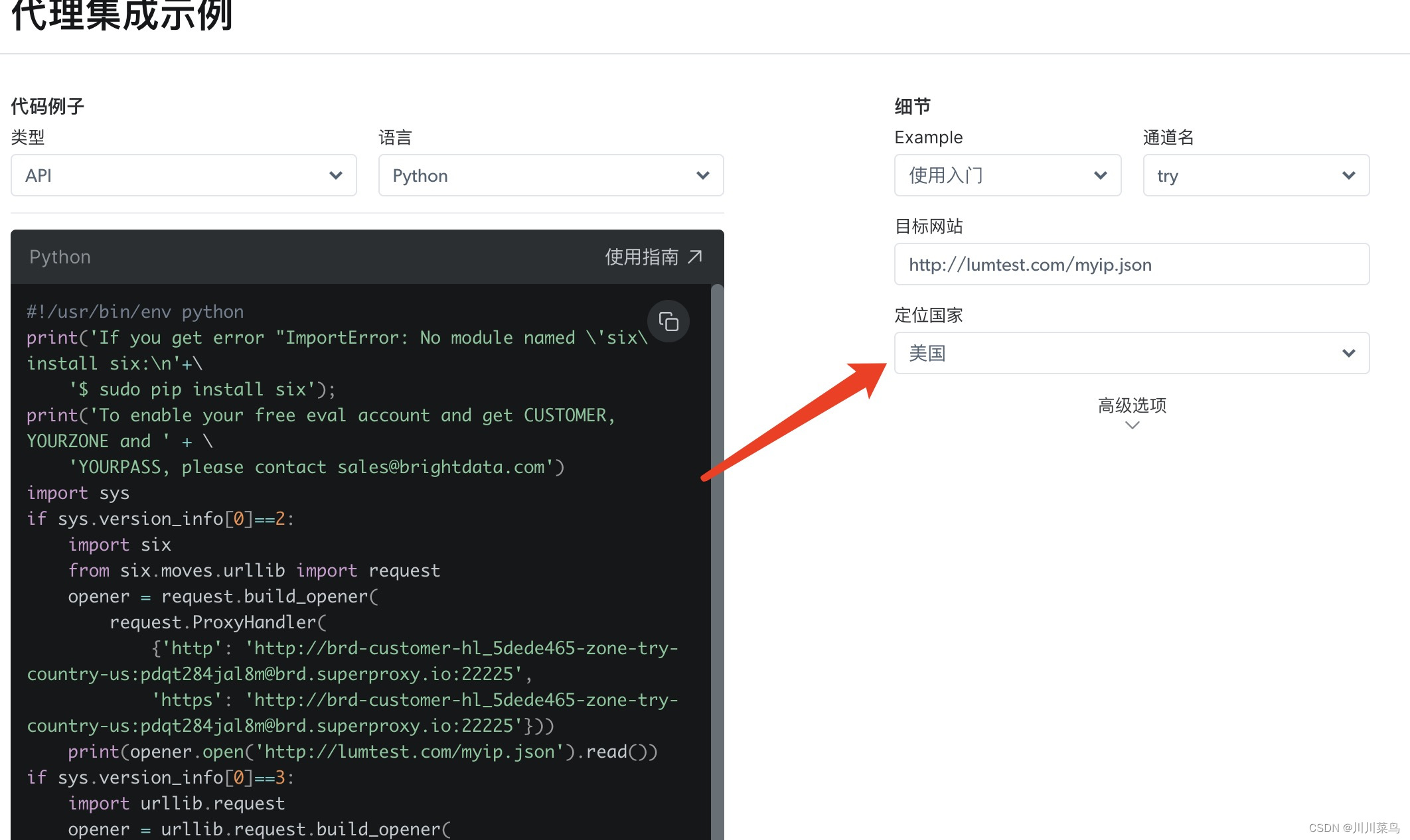
亮数据Bright Data的动态代理技术确保了数据抓取的稳定性和匿名性,大大提高了数据采集的成功率。生成动态ip代码如下(复制上述代码中的ProxyHandler部分,替换下方我的):
import json
import urllib.request
opener = urllib.request.build_opener(
urllib.request.ProxyHandler(
{'http': 'http://brd-customer-hl_5dede465-zone-try-country-us:pdqt284jal8m@brd.superproxy.io:22225',
'https': 'http://brd-customer-hl_5dede465-zone-try-country-us:pdqt284jal8m@brd.superproxy.io:22225'}))
response = opener.open('http://lumtest.com/myip.json').read()
# 将响应转换为字符串
response_str = response.decode('utf-8')
# 使用json库解析字符串
data = json.loads(response_str)['ip']
# 打印IP地址,每一次打印结果是不一样的,输出例子:73.110.170.116
print(data)
给予上述的代码模板,我们可以修改原来的代码:
# 获取动态IP
def get_dynamic_ip():
opener = urllib.request.build_opener(
urllib.request.ProxyHandler(
{'http': 'http://brd-customer-hl_5dede465-zone-try-country-us:pdqt284jal8m@brd.superproxy.io:22225',
'https': 'http://brd-customer-hl_5dede465-zone-try-country-us:pdqt284jal8m@brd.superproxy.io:22225'}))
response = opener.open('http://lumtest.com/myip.json').read()
response_str = response.decode('utf-8')
ip = json.loads(response_str)['ip']
return ip
# 使用动态IP配置WebDriver
def configure_driver_with_proxy(ip):
PROXY = ip
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--proxy-server={PROXY}')
# 初始化浏览器
driver = webdriver.Chrome()
return driver
# 主逻辑
ip = get_dynamic_ip()
print(f"Using IP: {ip}")
driver = configure_driver_with_proxy(ip)
运行查看使用的代理:47.197.239.15
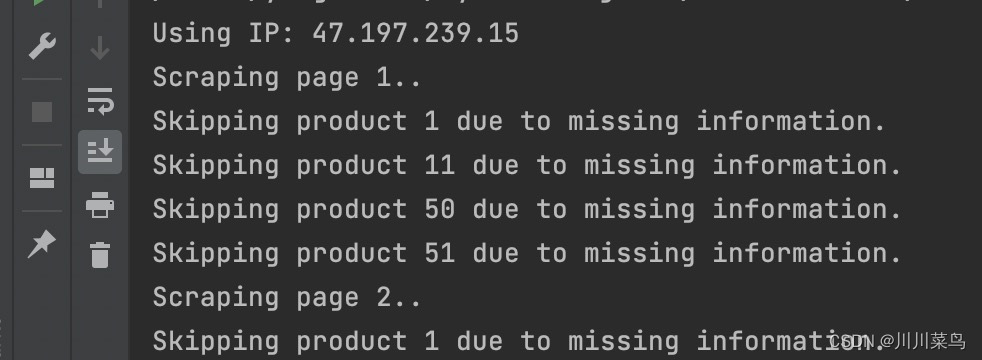
再次运行查看使用的代理:73.129.215.76
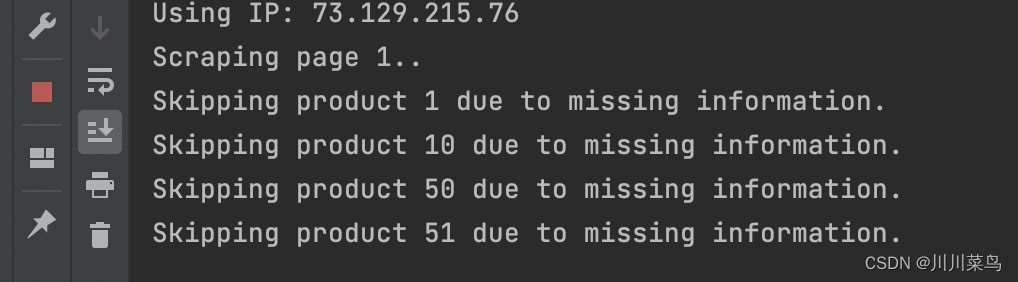
可以看到每次执行都是使用不同的ip,这样就不用担心网站把我自己的ip封了。(其它网站类似操作)
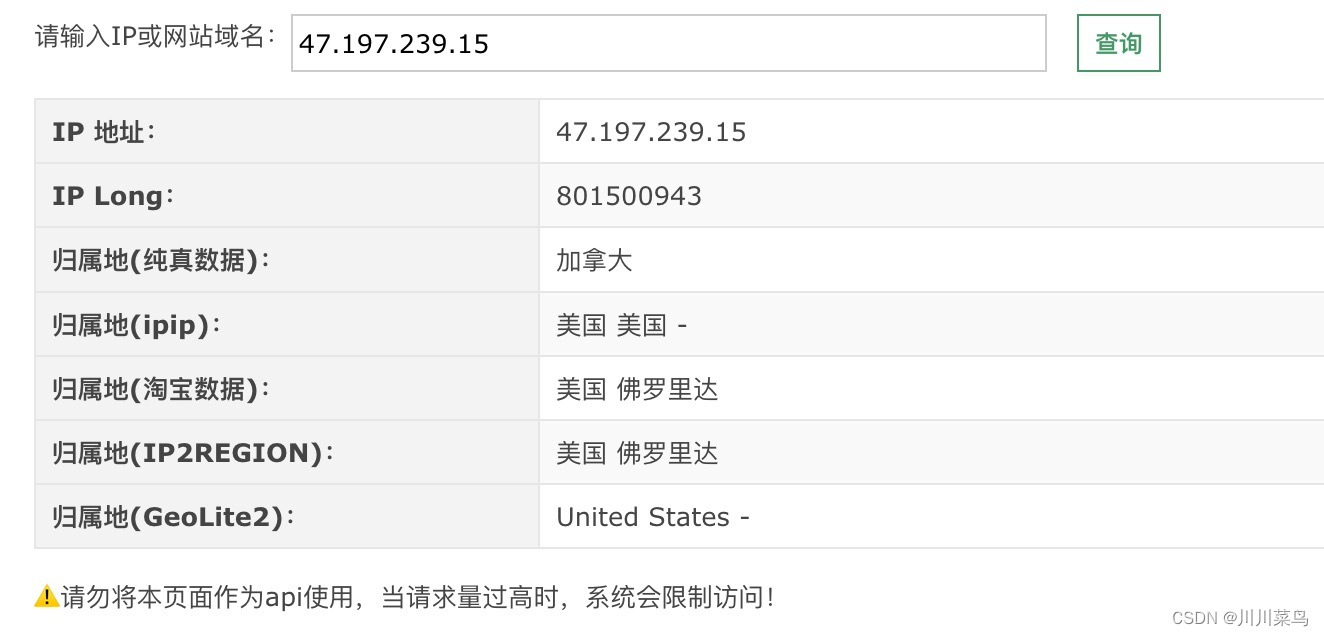
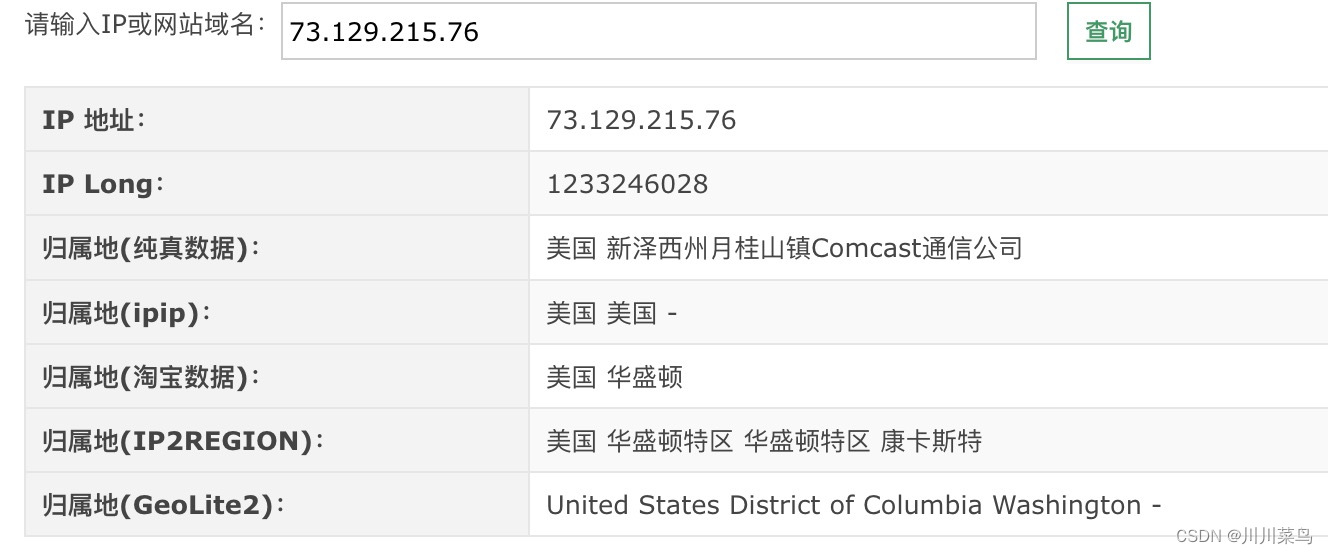
这里来看下我们使用的代理ip位置具体是哪里的?这里我对上述两个ip查询结果如下,可以看到这是纯真的美国ip地址:
第五步:分析抓取的数据📊
这里我们暂时分析这两个方面:
- 价格分布:使用直方图展示价格分布。
- 价格趋势:使用线图展示每个商品的价格趋势。
代码如下所示:
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('amazon_products_multiple_pages.csv')
# 价格分布
plt.figure(figsize=(10, 6))
plt.hist(df['Price'].astype(float), bins=20, color='blue', edgecolor='black')
plt.title('Price Distribution of iPhone 15 Products')
plt.xlabel('Price (RMB)')
plt.ylabel('Number of Products')
plt.grid(True)
plt.show()
# 价格趋势
plt.figure(figsize=(10, 6))
df['Price'].astype(float).plot(kind='line')
plt.title('Price Trend of iPhone 15 Products')
plt.xlabel('Product Index')
plt.ylabel('Price (RMB)')
plt.grid(True)
plt.show()
运行如下:
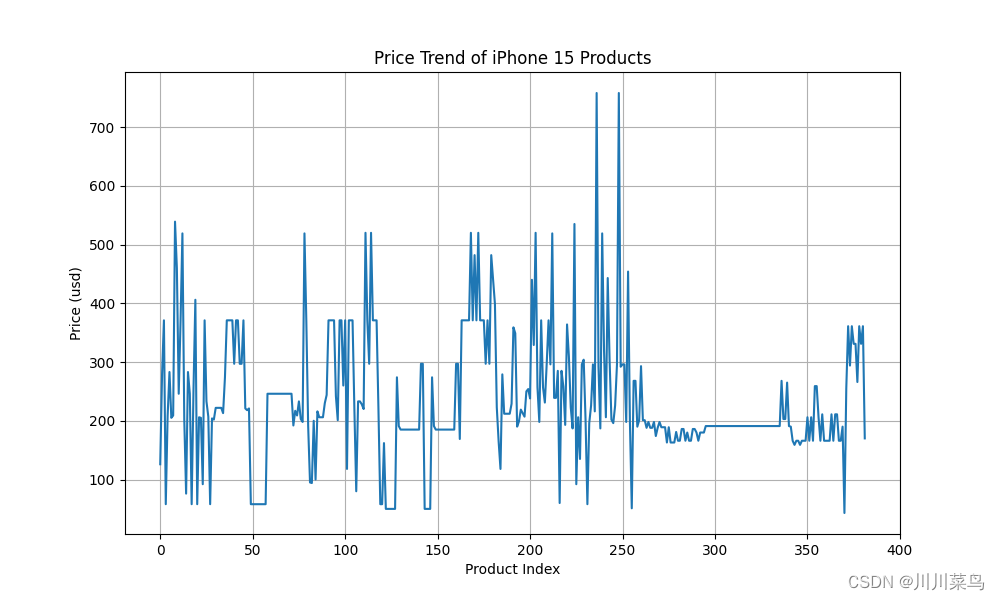
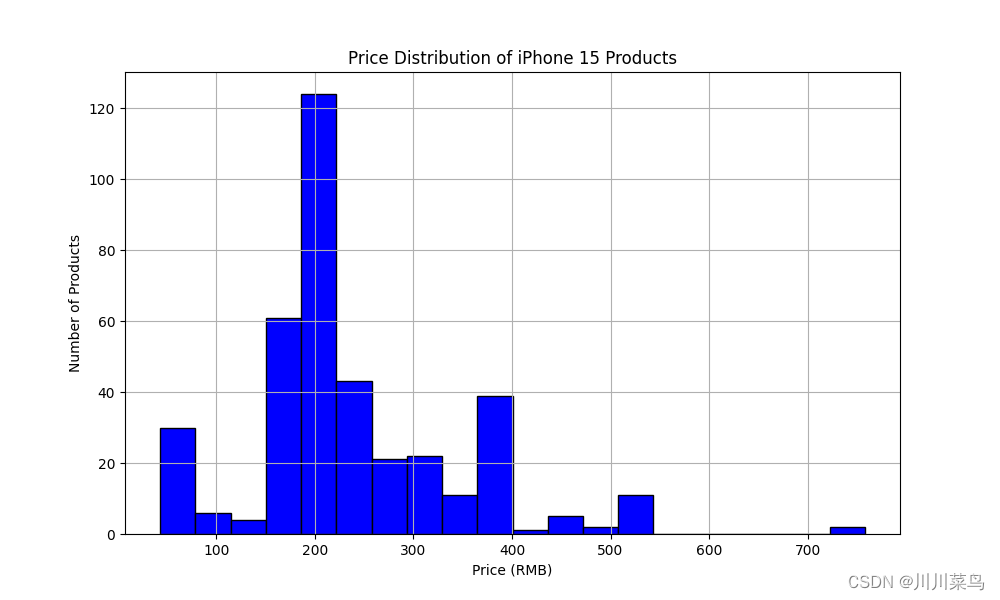
完整代码💻
为了让大家更深入地掌握与应用,我们特意提供了详细的代码示例。在此,我们要特别感谢亮数据Bright Data,他们为我们提供了这样一款强大的工具,让数据抓取变得既简单又安全!
如果你或你的公司正为数据问题苦恼,不妨点击👉:亮数据Bright Data 。扫描下方二维码,直接体验:

数据抓取完整代码如下所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import csv
import json
import urllib.request
# 获取动态IP
def get_dynamic_ip():
opener = urllib.request.build_opener(
urllib.request.ProxyHandler(
{'http': 'http://brd-customer-hl_5dede465-zone-try-country-us:pdqt284jal8m@brd.superproxy.io:22225',
'https': 'http://brd-customer-hl_5dede465-zone-try-country-us:pdqt284jal8m@brd.superproxy.io:22225'}))
response = opener.open('http://lumtest.com/myip.json').read()
response_str = response.decode('utf-8')
ip = json.loads(response_str)['ip']
return ip
# 使用动态IP配置WebDriver
def configure_driver_with_proxy(ip):
PROXY = ip
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--proxy-server={PROXY}')
# 初始化浏览器
driver = webdriver.Chrome()
return driver
# 主逻辑
ip = get_dynamic_ip()
print(f"Using IP: {ip}")
driver = configure_driver_with_proxy(ip)
# 打开亚马逊网站
driver.get("https://www.amazon.cn/")
time.sleep(3)
# 在搜索框中输入“iPhone 15”
search_box = driver.find_element(By.ID, "twotabsearchtextbox")
search_box.send_keys("iPhone 15")
search_box.send_keys(Keys.RETURN)
# 等待页面加载
time.sleep(3)
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
# 创建CSV文件并写入数据
with open('amazon_products_multiple_pages.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Title', 'Price', 'Image URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 循环遍历多个页面,使用代理的ip去爬多页
for page in range(1, 9):
time.sleep(2)
print(f"Scraping page {page}..")
# 获取商品信息
product_elements = driver.find_elements(By.CSS_SELECTOR, ".s-main-slot .s-result-item")
for index, product in enumerate(product_elements):
try:
title = product.find_element(By.CSS_SELECTOR, ".a-text-normal").text
price = product.find_element(By.CSS_SELECTOR, ".a-price-whole").text
image_url = product.find_element(By.CSS_SELECTOR, "img.s-image").get_attribute("src")
# print(f"Product {index + 1}:")
# print(f"Title: {title}")
# print(f"Price: {price} RMB")
# print(f"Image URL: {image_url}")
# 写入CSV文件
writer.writerow({'Title': title, 'Price': price, 'Image URL': image_url})
except Exception as e:
print(f"Skipping product {index + 1} due to missing information.")
# 点击“下一页”按钮
try:
next_button = driver.find_element(By.CSS_SELECTOR, ".s-pagination-next")
next_button.click()
time.sleep(3) # 等待下一页加载
except Exception as e:
print("No more pages to scrape.")
break
time.sleep(10)
# 关闭浏览器
driver.quit()