hello,大家好,这里是【玩数据的诡途】
接上回 <我的影刀故事>
今天给大家介绍一下整个采集的底层逻辑,包括业务流程自动化也是基于这一套基础逻辑进行展开的,顺便带大家熟悉一下影刀,既然叫影刀系列了,那后续一些分享也理所当然的基于影刀来进行
一、 影刀安装
工欲善其事必先利其器,首先需要安装一下影刀工具,直接 影刀官网 下载安装即可,和你电脑里的其他软件安装一样。官网也有一些介绍可以了解下
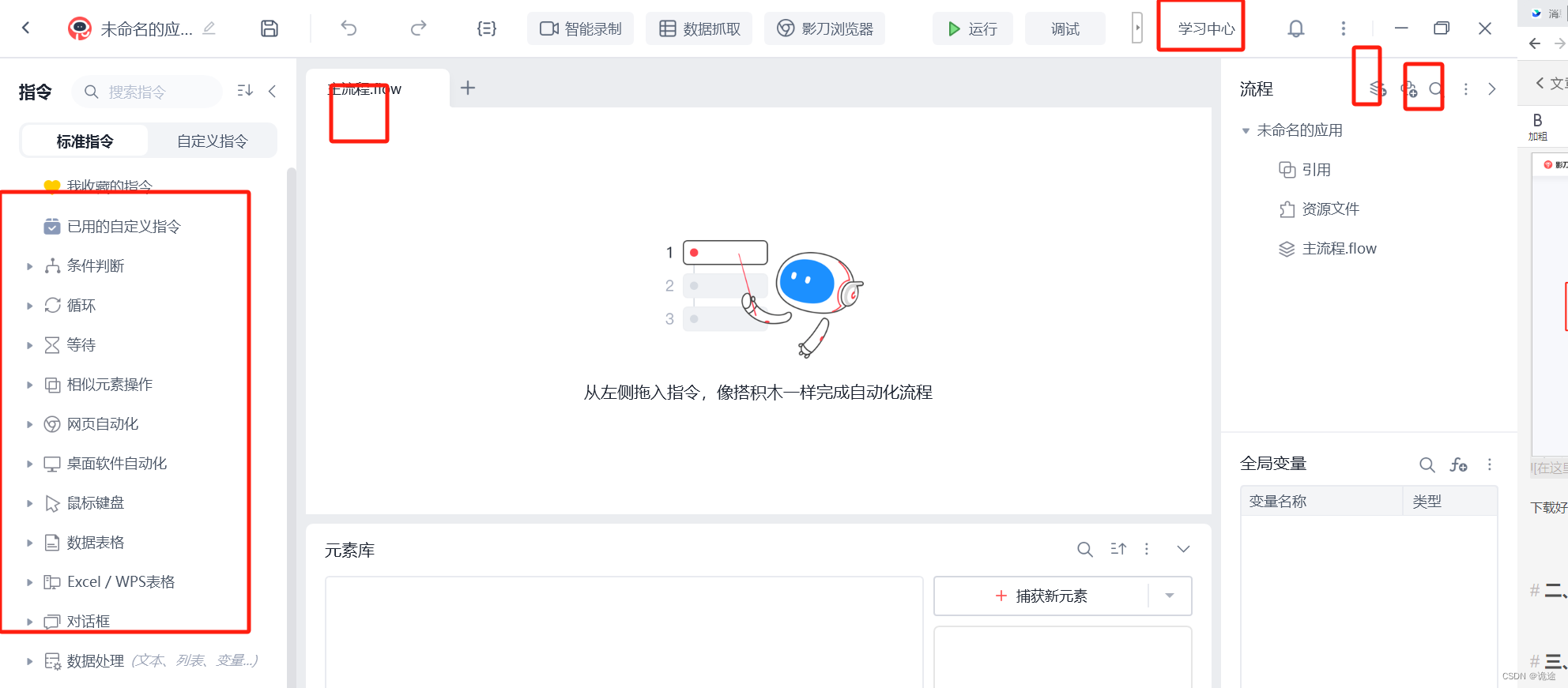
下载好的软件,打开注册登录,这里可以看到有一些教程,可以跟着学习操作练习,新建一个程序, 进入到如下开发面板,整体可以分两个部分,右上方这两个圈出来的地方,一个是【新建流程】,一个是【新建模块】流程就是可视化的低代码开发,模块就是Python模块,可以直接写python代码,每个指令都有简要说明,可以了解一下,学习中心是所有指令的集合,方便根据功能搜索
二、主流程介绍
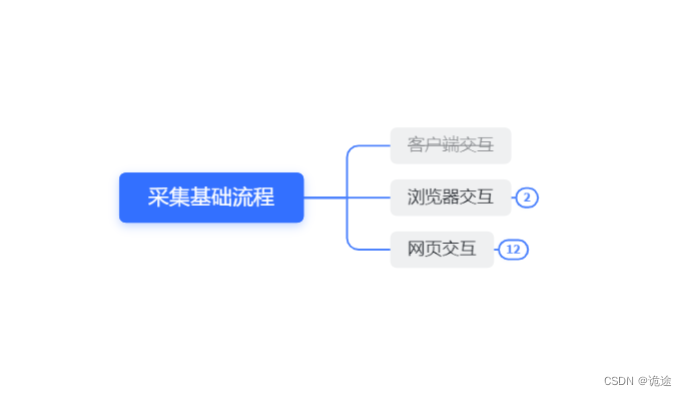
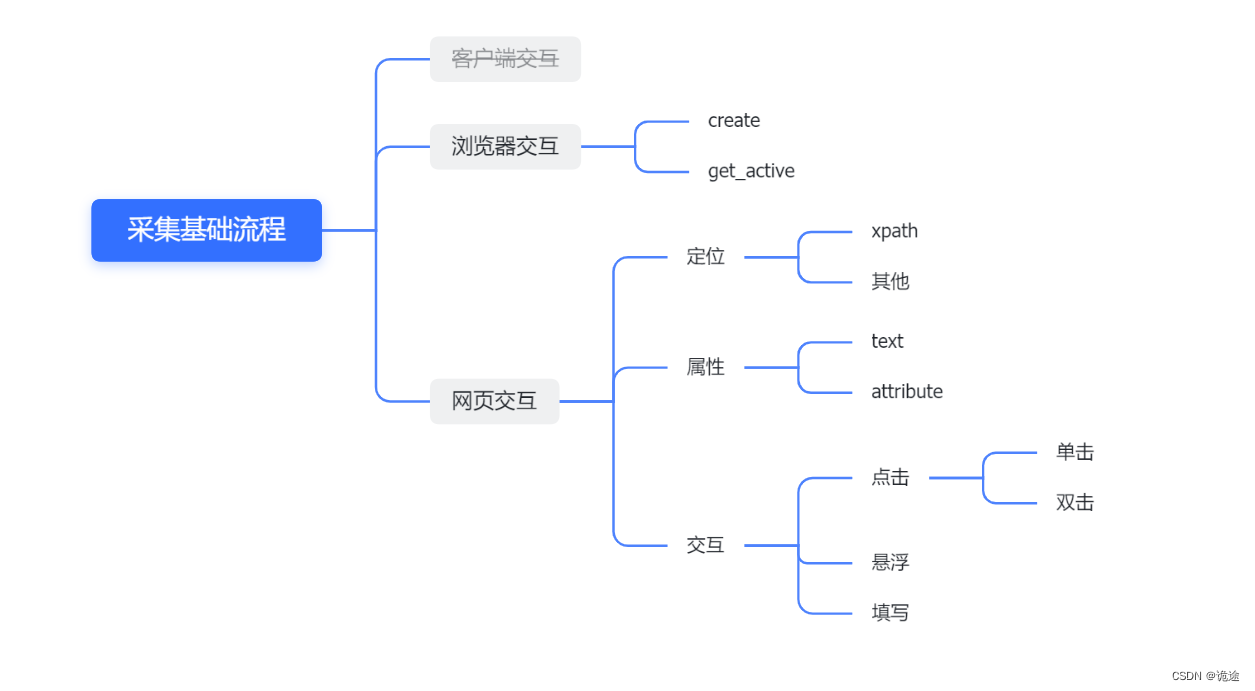
开发的主要流程,一般工作内容是采集/操作浏览器网页,也会有一些客户端交互案例,比如千牛客服,钉钉消息批处理等。更多的工作场景还是基于网页进行的,所以我们还是以网页交互为主。
在采集的过程中主要逻辑是先跟浏览器建立联系,
在影刀中主要使用create
后续所有操作都是对网页交互
所以我们后续频繁使用的功能将是web下面的指令,可以重点了解
三、网页交互
想要进行网页交互,先要和浏览器建立连接,主要使用create、get_active这两个函数进行连接
create(url, mode='cef', *, load_timeout=20, stop_if_timeout=False, silent_running=False, executable_path=None, arguments=None) -> xbot.web.browser.WebBrowser
打开网页
● @param url, 目标网址
● @param mode, 浏览器类型
● 'cef' 影刀浏览器,
● 'chrome' Google Chrome浏览器
● 'edge' Microsoft Edge浏览器
● 'ie' Internet Explorer浏览器
● '360se' 360安全浏览器
● 'firefox' Firefox浏览器
● @param load_timeout, 等待加载超时时间, 默认超时时间20s, 如果网页超时未加载完成则抛出 UIAError 异常
● >0, 等待时间
● 0, 不等待页面加载完成,立即返回
● -1, 无限等待,直到页面加载完成
● @param stop_if_timeout, 网页加载超时时是否停止加载网页, 默认是 False 不停止加载
● @param silent_running, 是否启用静默运行, 默认是 False
● @param arguments, 命令行参数, 必须是目标浏览器支持的命令行, 可为空
● @return WebBrowser , 返回打开的网页对象
===
get_active(mode='cef', *, load_timeout=20, stop_if_timeout=False, silent_running=False) -> xbot.web.browser.WebBrowser
获取当前选中或激活的网页
● @param mode, 浏览器类型
● 'cef' 影刀浏览器,
● 'chrome' Google Chrome浏览器
● 'edge' Microsoft Edge浏览器
● 'ie' Internet Explorer浏览器
● 'firefox' FIrefox浏览器
● @param load_timeout, 等待加载超时时间, 默认超时时间20s, 如果网页超时未加载完成则抛出 UIAError 异常
● @param stop_if_timeout, 网页加载超时时是否停止加载网页, 默认是 False 不停止加载
● @param silent_running, 是否启用静默运行, 默认是 None 沿用之前的设定
● @return WebBrowser , 返回获取到的网页对象


建立连接之后,后面的就是跟网页交互,从而获取自己想要的数据或者自动化执行的内容,总结抽象出了三个主逻辑,所有的功能都是以【元素定位】、【目标元素的属性】,【与定位到的目标元素进行交互】这三个主逻辑循环嵌套来实现的。具体怎么使用,将在下一期具体案例,带大家代码实操,一步步拆解每个模块功能。
写在最后
视频版同步详见
新鲜出炉的UP主,来当未来百大的老粉吧
感谢大家关注,欢迎一键三连,求粉求关注