Clickhouse kafka引擎需要结合kafka使用,需要确保已经安装clickhouse和kafka
实战环境:
Clickhouse-server 版本:22.4.5
Kafka版本:kafka_2.13-3.2.0
Clickhouse数据库执行:
1、使用引擎创建一个kafka消费者
CREATE TABLE log_queue (
logid String,
message String
) ENGINE = Kafka SETTINGS kafka_broker_list = 'localhost:9092',
kafka_topic_list = 'log_topic',
kafka_group_name = 'log_consumer_group',
kafka_format = 'JSONEachRow';必要参数:
kafka_broker_list– 以逗号分隔的 brokers 列表 (localhost:9092)。kafka_topic_list– topic 列表 (my_topic)。kafka_group_name– Kafka 消费组名称 (group1)。如果不希望消息在集群中重复,请在每个分片中使用相同的组名。kafka_format– 消息体格式。使用与 SQL 部分的FORMAT函数相同表示方法,例如JSONEachRow。了解详细信息,请参考Formats部分。
可选参数:
kafka_row_delimiter- 每个消息体(记录)之间的分隔符。kafka_schema– 如果解析格式需要一个 schema 时,此参数必填。例如,普罗托船长 需要 schema 文件路径以及根对象schema.capnp:Message的名字。kafka_num_consumers– 单个表的消费者数量。默认值是:1,如果一个消费者的吞吐量不足,则指定更多的消费者。消费者的总数不应该超过 topic 中分区的数量,因为每个分区只能分配一个消费者。
2、创建数据库结构表
CREATE TABLE test_log (
logid String,
message String
) ENGINE = MergeTree()
order by logid;3、创建物化视图,转换引擎中的数据并转存到数据库结构表中
create materialized view test_log_view to test_log as select * from log_queue;测试:
1、启动zookeeper
#进入kafka bin目录
cd /usr/local/java/kafka_2.13-3.2.0/bin
# 启动zookeeper
./zookeeper-server-start.sh /usr/local/java/kafka_2.13-3.2.0/config/zookeeper.properties &
2、启动kafka
#进入kafka bin目录
cd /usr/local/java/kafka_2.13-3.2.0/bin
#启动kakfa
./kafka-server-start.sh /usr/local/java/kafka_2.13-3.2.0/config/server.properties &3、创建topic
#进入kafka目录
cd /usr/local/java/kafka_2.13-3.2.0
# 创建topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic log_topic4、生产者发送消息
#进入kafka目录
cd /usr/local/java/kafka_2.13-3.2.0
# 生产者控制台连接
bin/kafka-console-producer.sh --topic log_topic --bootstrap-server localhost:9092
# 发送消息,回车键发送
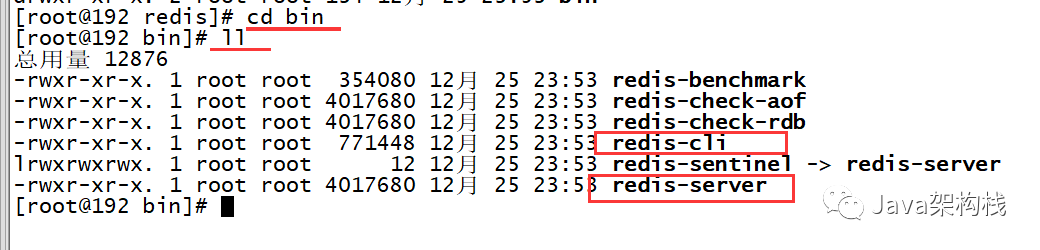
{"logid":"12345789255","message":"test"}5、查看clickhouse数据表,数据是否插入成功

6、如果数据未插入成功,则需要查看clickhouse日志,是否数据格式异常导致。
cd /var/log/clickhouse-server参考文档:
Kafka | ClickHouse Docs
Apache Kafka










![[思维模式-8]:《如何系统思考》-4- 认识篇 - 什么是系统思考?系统思考的特征?系统思考的思维转变。](https://img-blog.csdnimg.cn/img_convert/29d7c2475f0368b5359c843443bbd3f0.jpeg)