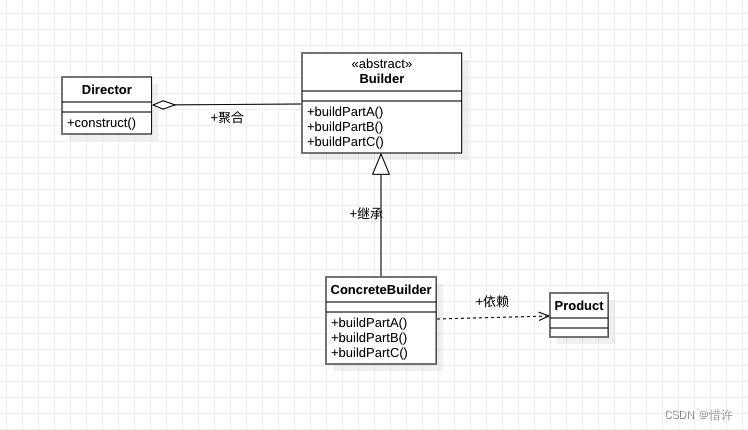
下面以经典的分类任务:MNIST手写数字识别,采用全连接层神经网络
MNIST数据集是一个手写体的数字图片集,它包含有训练集和测试集,由250个人手写的数字构成。训练集包含60000个样本,测试集包含10000个样本。每个样本包括一张图片和一个标签。每张图片由28×28个像素点构成,每个像素点用1个灰度值表示。标签是与图片对应的0到9的数字。

随着训练损失值逐渐降低 精确度上升

部分代码如下
import numpy as np
import tensorflow.keras as ka
import datetime
np.random.seed(0)
(X_train, y_train), (X_val, y_val) = ka.datasets.mnist.load_data("D:\datasets\MNIST_Data\mnist.npz") # 加载数据集,并分成训练集和验证集
num_pixels = X_train.shape[1] * X_train.shape[2] # 每幅图片的像素数为784
# 将二维的数组拉成一维的向量
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32')
X_val = X_val.reshape(X_val.shape[0], num_pixels).astype('float32')
# 归一化
X_train = X_train / 255
X_val = X_val / 255
y_train = ka.utils.to_categorical(y_train) # 转化为独热编码
y_val = ka.utils.to_categorical(y_val)
num_classes = y_val.shape[1] # 10
# 多层全连接神经网络模型
model = ka.Sequential([
ka.layers.Dense(num_pixels, input_shape=(num_pixels,), kernel_initializer='normal', activation='sigmoid'),
ka.layers.Dense(784, kernel_initializer='normal', activation='sigmoid'),
ka.layers.Dense(num_classes, kernel_initializer='normal', activation='sigmoid')
])
model.summary()
#model.compile(loss='mse', optimizer='sgd', metrics=['accuracy'])
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
startdate = datetime.datetime.now() # 获取当前时间
model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=20, batch_size=200, verbose=2)
enddate = datetime.datetime.now()
print("训练用时:" + str(enddate - startdate))下面以上述代码来讨论神经网络中常用的激活函数、损失函数和优化方法
激活函数
常用的激活函数还是ReLU函数 Softplus函数 tanh函数和Softmax函数等等
ReLU函数的定义为:
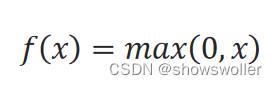
Softplus函数的定义为:

tanh函数的图像类似于Sigmoid函数,作用也类似于Sigmoid函数。它的定义为:
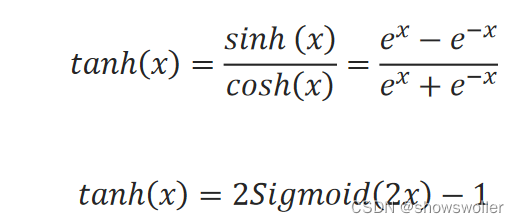
假设有一组实数y_1,y_2,…,y_K(可看作多分类的结果),Softmax函数将它们转化为一组对应的概率值:


假如有一组数1、2、5、3,容易计算出它们的Softmax函数值分别约为0.01、0.04、0.83、0.11,将它们的原数值和Softmax函数值、max函数值等比例画出
修改示例代码,使模型分别采用不同激活函数组合进行比较,其他参数不变,仍为MSE损失函数、SGD优化方法,并训练20轮,运行结果:

采用什么样的激活函数,要根据理论研究、工程经验和试验综合分析。过拟合示例中,如果采用softplus激活函数,训练轮数仍为5000,网络结构仍然是四层(1,5,5,1)结构,分别对样本特征进行归一化处理和不归一化处理时拟合多项式的结果

损失函数
MSE损失函数时基于欧式距离的损失函数,还有KL散度损失函数,交叉熵损失函数等等
交叉熵可以用来衡量两个分布之间的差距
信息熵的定义:H(X)=−∑_i=1^n▒p_ilogp_i。用p_i表示第i个输出的标签值,即真实值,用q_i表示第i个输出值,即预测值。将p_i与q_i之间的对数差在p_i上的期望值称为相对熵:
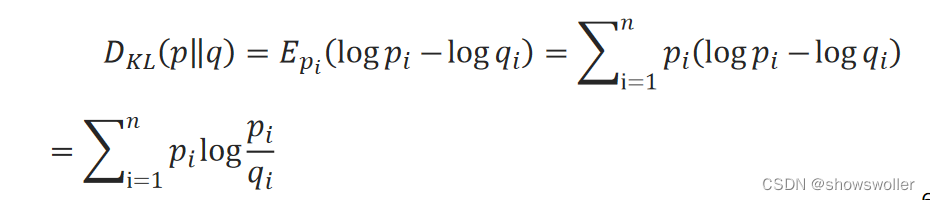
计算a和d两项输出的相对熵:
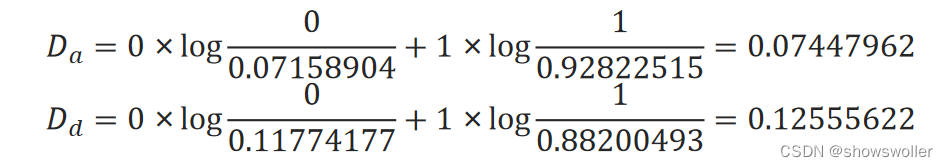
将相对熵的定义式进一步展开:

将相对熵的定义式进一步展开:前一项保持不变,因此一般用后一项作为两个分布之间差异的度量,称为交叉熵:H(p,q)=−∑_i=1^n▒p_ilogq_i
如果只有正负两个分类,记标签为正类的概率为y,记预测为正类的概率为p,那么上式为:

交叉熵损失函数在梯度下降法中可以避免MSE学习速率降低的问题,得到了广泛的应用。
优化算法
下面讨论常用于多层神经网络中的优化算法,它们都是梯度下降法的主要改进方法,主要从增加动量和调整优化步长两方面着手
### MindSpore框架下
class mindspore.nn.SGD(params, learning_rate=0.1, momentum=0.0, dampening=0.0, weight_decay=0.0, nesterov=False, loss_scale=1.0)
### TensorFlow框架下
tf.keras.optimizers.SGD(
learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs
)
为了克服固定步长的弊端,MindSpore深度学习框架和TensorFlow2深度学习框架都提供了动态调整步长的方法。
learning_rate超参数即为梯度下降法中的步长,也称为学习率,它们的默认初始值都是固定的0.1,可以设置成动态的步长。
MindSpore提供了函数和类两种预定义的动态调整步长方法,两种方法的具体功能相近,它们分别按余弦函数、指数函数、与时间成反比、多项式函数等方式衰减步长。
learning_rate = 0.1
decay_rate = 0.9
total_step = 6
step_per_epoch = 2
decay_epoch = 1
output = exponential_decay_lr(learning_rate, decay_rate, total_step, step_per_epoch, decay_epoch)
print(output)
>>> [0.1, 0.1, 0.09000000000000001, 0.09000000000000001, 0.08100000000000002, 0.08100000000000002]
设当前为第i步,其步长的计算方法为:

其中,current_epocℎ=floor(i/step_per_epocℎ),floor为向下取整运算。
在TensorFlow2框架中也提供了类似的动态调整步长方法,它们都在tensorflow.keras.optimezers.schedules模块内。
这些动态调整步长的方法,实际上并没有结合优化的具体进展情况来设定步长,仍然可以看成是一组预先设定的步长,只不过它们的大小按一定方式逐步衰减了。
结合优化具体进展的自适应步长调整方法Adagrad(Adaptive Gradient)算法记录下所有历史梯度的平方和,并用它的平方根来除步长,这样就使得当前的实际步长越来越小。
MindSpore中实现该算法的类为:mindspore.nn.Adagrad。TensorFlow2中实现该算法的类是:tf.keras.optimizers.Adagrad。
在经典力学中,动量(Momentum)表示为物体的质量和速度的乘积,体现为物体运动的惯性。在梯度下降法中,如果使梯度下降的过程具有一定的“动量”,保持原方向运动的一定的 “惯性”,则有可能在下降的过程中“冲过”小的“洼地”,避免陷入极小值点。

在SGD算法中,通过配置momentum 参数,就可以使梯度下降法利用这种“惯性”。momentum 参数设置的是“惯性”的大小
加入动量的梯度下降的迭代关系式还有一种改进方法,称为NAG(Nesterov accelerated gradient)。该方法中,计算梯度的点发生了变化,它可以理解为先按“惯性”前进一小步,再计算梯度。这种方法在每一步都往前多走了一小步,有时可以加快收敛速度。设置SGD的nesterov为True,即可使用该算法。
结合动量和步长进行优化的算法有RMSProp(Root Mean Square Prop)和Adam(Adaptive moment estimation)算法等。
RMSProp(Root Mean Square Prop)算法通过对Adagrad算法逐步增加控制历史信息与当前梯度的比例系数、增加动量因子和中心化操作形成了三个版本。在MindSpore中,实现该算法的类是:mindspore.nn.RMSProp,在TensorFlow2中实现该算法的是:tensorflow.keras.optimizers.RMSprop。
Adam(Adaptive moment estimation)算法是一种结合了AdaGrad算法和RMSProp算法优点的算法。Adam算法综合效果较好,应用广泛。
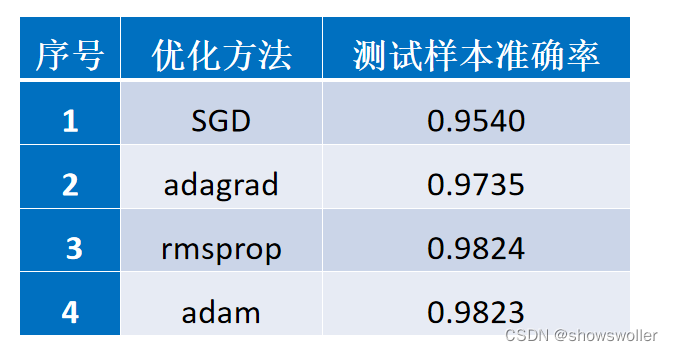
神经网络三隐层分别采用relu、relu和softmax激活函数组合,采用交叉熵损失函数,训练20轮,采用不同的优化方法:
局部收敛与梯度消散
BP神经网络不一定收敛,也就是说,网络的训练不一定成功。误差的平方是非凸函数,BP神经网络是否收敛或者能否收敛到全局最优,与初始值有关。
在校对误差反向传播的过程中,如果偏导数较小,在多次连乘之后,校对误差会趋近于0,导致梯度也趋近于0,前面层的参数无法得到有效更新,称之为梯度消散。相反,如果偏导数较大,则会在反向传播的过程中呈指数级增长,导致溢出,无法计算,网络不稳定,称之为梯度爆炸。
常用的解决方法包括尽量使用合适的激活函数(如Relu函数,它在正数部分导数为1);预训练;合适的网络模型(有些网络模型具有防消散和爆炸能力);梯度截断等等
创作不易 觉得有帮助请点赞关注收藏~~~