前言
对于背压问题不久前就讨论过了,这里就不过多介绍了,总之它是一个非常复杂的话题,本文的主要目的是分析我们如何从Rxjava迁移到Flow并且使用其背压方案,由于本身技术的限制以及协程内部的复杂性,不会做过多的深入讨论,只是通过类似黑盒测试的方式,给出一些示例比较它们之前存在的差异以及如何去使用不同的背压解决方案。鉴于 RxJava 和协程的实现差异,每个示例的实际输出基本都不会相同,这些示例的目的是说明它们之间处理背压的不同策略。
本文会侧重于从
Rxjava的角度出发去对比Flow背压的差异和相关背压策略的使用方案,关于Flow解决背压的简单使用,之前有专门分享过一篇文章,感兴趣的小伙伴可以移步 -----> Flow是如何解决背压问题的
关于Rxjava的背压
首先不得不提到Rxjava中最常用的Observable,有一个我们称之为无限缓冲区,由于Observable 没有提供优雅的方式来处理背压,所有发送/接收的数据都存储在内存中并确保订阅者接收到它。如果发送的数据量非常非常大,那么最终可能会导致 OOM内存溢出,程序会发生crash。
在Rxjava中只有Flowable流类型才有对背压进行处理,它默认具有128大小的缓冲区,是通过Subscriber接口支持的,我们看下它的内部代码结构
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t)
public void onComplete();
}
而提供背压管理内容的功能正是其内部的Subscripion接口
public interface Subscription {
public void request(long n);
public void cancel();
}
特别request方法,每当下游能够使用更多事件时,它都会向上游发送请求,提供它能够使用的事件数量。
因此,基本通信如下:
-
在订阅下游请求一些事件(比如 1)
-
上游收到该请求并产生下一个事件
-
当下游接收到事件时,它可以向上游请求更多事件
这就是支持背压的方式:如果下游没有请求事件,生产者应该停止生产事件。如果应用了某种背压策略并且生产者能够发出新项目而消费者无法消费它,那么生产者可能会丢弃掉一些值(
Drop)或缓冲(Buffer)它们。这可能被视为从链的底部到顶部的通信(简称链式通信),以告诉上游是否发出值,并且(基于背压策略)对尚未准备好发送给消费者的值应用一些规则。
关于Flow背压
在Flow中一切都会更加复杂,由于本文不深入研究,所以也不做过多探讨,只需要知道它没有像Rxjava那样从下游到上游的直接链式通信,一切的一切都是基于suspend,当流的收集器不堪重负时,它可以简单地暂停发射器,然后在准备好接受更多元素时恢复它;当下游暂停(或做一些其他工作)时,上游可能会识别并且不发射元素。
Flow&Rxjava的简单比较
简单来说,为了比较Rxjava与Flow背压策略的不同,我们通过一些测试用例进行说明,例如模拟从网络中拿取一些数据等,这里也不用那些看起来就非常复杂的官方术语解释了,总之就一句话,Rxjava会将它进行阻塞,而Flow则将它挂起/暂停
话不多说,接下来我们将创建一些上游,然后定义一些延迟事件,一起来看下下面这个例子吧
对于Rxjava,我们可以这么定义:
private fun flowable(delay: Long, mode: BackpressureStrategy, limit: Int): Flowable<Int> =
Flowable.create<Int>({ emitter ->
for (i in 1..limit) {
Thread.sleep(delay)
emitter.onNext(i)
}
}, mode)
对于Flow,我们等效策略代码如下:
private fun flow(timeout: Long, limit: Int): Flow<Int> = flow {
for (i in 1..limit) {
delay(timeout)
emit(i)
}
}
简单来说,以上就是实现在每个事件之间延迟timeout时长,发出limit + 1项目的流
接下来再详细验证下,所以我补充了一些代码,如下所示,将让我们的上游每 100毫秒生产一次项目,并依次用 200 毫秒和 300 毫秒处理它们。通过这样的设置,预计(对于消费者来说,它需要大约 500 毫秒来处理结果)并不是所有的事件都会被消费。
//by Rxjava
fun testFlowable(mode: BackpressureStrategy, limit: Int = 10) {
val latch = CountDownLatch(1)
val stringBuffer = StringBuffer()
val time = System.currentTimeMillis()
flowable(delay = 100, mode = mode, limit = limit)
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.computation(), false, 1)
.map { doWorkBlocking(i = it, delay = 200) }
.map { doWorkBlocking(i = it, delay = 300) }
.doOnComplete {
latch.countDown()
}
.subscribe {
stringBuffer.append("$it")
}
latch.await()
println(System.currentTimeMillis() - time)
println(stringBuffer.toString())
}
//by flow
fun testFlow(limit: Int = 10, onBackpressure: Flow<Int>.() -> Flow<Int>) {
val latch = CountDownLatch(1)
val time = System.currentTimeMillis()
val stringBuffer = StringBuffer()
CoroutineScope(Job() + Dispatchers.Default).launch {
flow(timeout = 100, limit = limit)
.flowOn(Dispatchers.IO)
.onBackpressure()
.map { doWorkDelay(i = it, timeout = 200) }
.map { doWorkDelay(i = it, timeout = 300) }
.onCompletion { latch.countDown() }
.collect {
stringBuffer.append("$it")
}
}
latch.await()
println((System.currentTimeMillis() - time))
println(stringBuffer.toString())
}
Rxjava的背压策略
Rxjava Flowable提供了一些背压策略
- Drop:如果超出缓冲区大小,则丢弃未请求的项目
- Buffer:缓冲生产者的所有项目,注意
OOM内存泄漏 - Latest:只保留最新的项目
缓冲Observable的过度生成
一般情况下,当数据生成速度快于数据消耗速度时,就会出现背压,这时候缓冲Observable会过度生成,以至于消费者来不及处理;所以我们来讨论下Rxjava最初处理背压的方式,处理过度生成Observable的最初的方式是为 Observer无法处理的元素定义某种缓冲区。
我们可以通过调用_buffer()_ 方法来做到这一点:
val source = PublishSubject.create<Int>()
source.buffer(1024)
.observeOn(Schedulers.computation())
.subscribe(ComputeFunction::compute, Throwable::printStackTrace);
定义一个大小为 1024 的缓冲区会给_观察者_一些时间来赶上生产过剩的来源,缓冲区将存储尚未处理的元素。我们可以增加缓冲区大小,以便为生成的值留出足够的空间,这个其实和下文将要提到的BackpressureBuffer()处理策略的性质大致相同,可以说是它的初级版本,下文会对该策略方案进行实践补充。
请注意,一般来说,这可能只是一个临时修复,因为如果生产者过度生成元素超出了预测的缓冲区大小,溢出仍然可能发生。
这样说可能会有点抽象,我们做一个类比,想像一下,有一个这样的漏斗,我们不断地去灌某种液体去填充这个漏斗,如果它产生的速度快于它流出的速度,锥体部分将作为缓冲器工作一段时间,如果它装满就会溢出

为了让它不要溢出来,对此我们用不同的方法去对待:
- 如果液体是那种贵金属的话,可以使用锥形部分更大的漏斗来增加缓冲液(
BUFFER) - 不介意液体浪费的话,就让它倒出来吧 (
DROP和LATEST) - 如果可能的话,调整发射器以更慢地产生
接下来我们对这些背压策略分别进行实践说明
.onBackpressureBuffer()
对于这种情况,我们只能画出相似之处并为我们的用例实现等效解决方案。也就是说——我们希望接收发出的事件,即使消费者跟不上。看下官方的示例图:

RxJava 和Flow将以不同的方式解决这个问题。
RxJava 可以缓冲项目,直到消费者准备好处理它们(这可能导致OutOfMemoryException),而Flow可以暂停发射器。使用上文的测试代码,我们分别传入对应的参数进行测试
//buffer
BackpressureTest.testFlowable(BackpressureStrategy.BUFFER)
BackpressureTest.testFlow { buffer() }
结果大致如下所示
5114
1 2 3 4 5 6 7 8 9 10
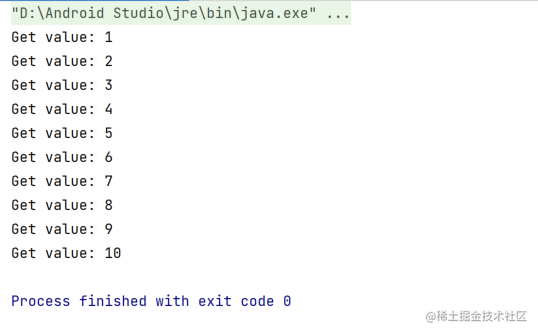
好的,下面再写个示例进行测试,发射10个数据进行模拟,并且使用onBackPressureBuffer这种背压策略,RxJava中的示例如下所示:
fun rxBuffer() {
Flowable.range(1, 10)
.onBackpressureBuffer()
.observeOn(Schedulers.single())
.subscribe { value ->
Thread.sleep(100)
println("Get value: $value")
}
Thread.sleep(1000)
}
它会将所有结果进行输出,如下图所示
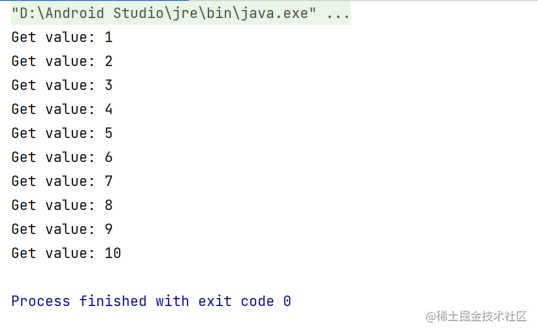
然后我们看下Flow中对应的等效策略是如何解决的
fun main() = runBlocking {
(1..1_000_000).asFlow()
.buffer(capacity = 0, onBufferOverflow = BufferOverflow.SUSPEND)
.collect { value ->
delay(100)
println("Got value: $value")
}
}
它的输出结果和上图是一样的
你可能会问,这个例子是不是和没有任何缓冲区一样的,因为Flow默认情况下会暂停发射器。这是一个很好的观察结果,但请记住,当发射器和收集器在单独的协程中运行时,如果它们都需要一些时间才能完成的时候,它们可以并发执行,这样速度会更快。
在这个例子中,我们已经简单研究了其中一种策略,现在让我们快速看一下其他策略。
.onBackpressureDrop()
如果消费者无法跟上并且缓冲区已满,此策略将丢弃所有发出的项目。在这种情况下(类似于 Latest)生产者将丢弃消费者无法消费的所有项数据,但不会保留最新数据,看下官方的示例图:

好的,举个栗子,还是延用之前的示例,我们依旧发射10个数据进行模拟,这里我们使用onBackpressureDrop背压策略,这是来自 RxJava 的示例:
fun rxDrop() {
Flowable.range(1, 10)
.onBackpressureDrop()
//将默认的缓冲区size改为1
.observeOn(Schedulers.single(), false)
.subscribe { value ->
Thread.sleep(100)
println("Get Value: $value")
}
Thread.sleep(1000)
}
可以看到它的输出结果只拿到了一个1,之后的所有值都被丢弃了,因为消费者无法处理它们。

这里有几件事要注意下:
- 首先,如果我们没有更改
Scheduler调度器,我们将获得所有项目,因为这段代码将同步运行,并且消费者会阻塞生产者。类似地,默认情况下Flow的话,如果在同一个协程中,它会依次在发射和收集之间交替,直到Flow完成。 - 另外,请记住,
observeOn()中使用默认的缓冲区大小是128,这里我们指定了size为1。如果使用默认缓冲区大小,只要我们的运行时间足够长,就会和之前一样获得所有发射出来的元素
使用的等效策略Flow如下所示:
fun flowDrop() = runBlocking {
(1..10).asFlow()
.buffer(capacity = 1, onBufferOverflow = BufferOverflow.DROP_LATEST)
.collect { value ->
delay(100)
println("Get value: $value")
}
}
与Rxjava不一样的是,鉴于协程的性质,收集器处理前两个元素,但想法是相同的——所有未处理的元素都被丢弃。之前文章已经讨论过了,当Flow调用.collect() 的时候,默认情况下,发射和收集将在同一个协程中顺序运行。换句话说,收集器将暂停发射器,直到它准备好接收更多数据。
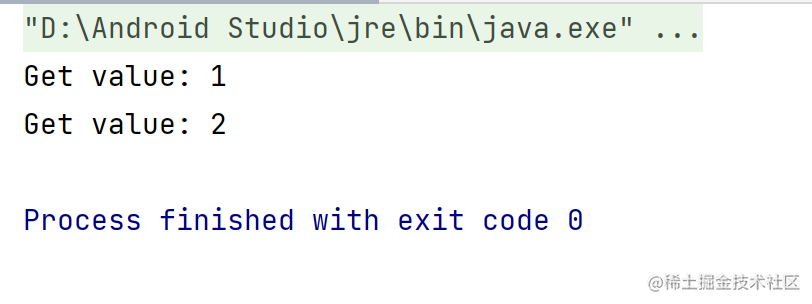
那么这里发生了什么呢?为了使缓冲和背压处理正常工作,我们需要在单独的协程中运行收集器。这就是.buffer()操作员进来的地方。它将_所有发出的项目通过 Flow 发送Channel到在单独的协程中运行的收集器_。
它还为我们提供了缓冲功能:
public fun <T> Flow<T>.buffer(
capacity: Int = BUFFERED,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): Flow<T>
我们可以指定我们的缓冲区capacity和处理策略onBufferOverflow。
在这个例子中,我们已经简单研究了其中一种策略,接下来让我们快速看一下本文讲述的最后一种背压策略。
.onBackpressureLatest()
这个策略的想法是在背压的情况下只发出最新的项目。然而解决方案在 Rxjava 和协程Flow中的工作方式又有所不同。下面是官方给出的图示:

我们可以看到,这种策略它在消费者来不及接收消息的时候,丢弃掉之前的数据,只保留生产者给的最新的数据
进入正题,还是通过一个栗子来进行说明,依旧是和之前一样发射10个数据进行模拟
首先,让我们看一下 Rxjava 示例:
fun rxLatest() {
Flowable.range(1, 10)
.onBackpressureLatest()
.observeOn(Schedulers.single(), false, 2)
.subscribe { value ->
Thread.sleep(100)
println("Get value:$value ")
}
Thread.sleep(1000L)
}
为了说明一个重点,我们将缓冲区大小增加到2。可以看下输出结果,在这种情况下,缓冲区_将填充最旧的值_,并删除所有后续值,最后一个值除外。

然而在Flow中,等效解决方案如下所示,buffer中已经提供了这样的策略DROP_OLDEST
fun flowLatest() = runBlocking {
(1..10).asFlow()
.buffer(capacity = 2, onBufferOverflow = BufferOverflow.DROP_OLDEST)
.collect { value ->
delay(100)
println("Get Value: $value")
}
}
这种策略它的新数据会直接覆盖掉旧数据,不设缓冲区,也就是缓冲区大小为 0,丢弃旧数据,Flow中对此也提供了相应的操作符conflate, 看下输出结果

关于缓冲和背压的最终想法
RxJava 库还有更多处理背压的功能,笔者就不再分享了。它在灵活性和选择方面可能很好,但在学习曲线方面也很糟糕,正确使用这些操作对大多数开发人员来说并不是一项微不足道的任务,需要花上不小的精力,达到使用精通的门槛相对较高。
总的来说,RxJava Flowable 和 Kotlin Flow 都支持背压,但仍然存在差异。这些差异主要是基于 RxJava 内置的背压支持,它从下到上工作(下游能够在需要更多值时告诉上游),而 Kotlin Flow背压主要基于suspend挂起函数,当我们从 RxJava 迁移到 Kotlin Flow 时,请特别注意使用 Flowable 和使用到背压策略的地方,所以在我看来,Kotlin Flow初学者更友好且易于使用,同时为您可能遇到的大多数问题提供了解决方案。
好咯,关于背压的相关探讨就到此划上句号吧,还有很多地方值得继续深入学习,因为背压是一个非常复杂的问题,我只是简单的分析下Rxjava&Flow之间背压策略的区别以及实现方式,还有很多东西要学,共勉!!!!!
本文转自 [https://juejin.cn/post/7177935139853303865],如有侵权,请联系删除。