案例中将展示机场官网中航班信息(如机场航班的离港与进港信息)的爬取过程。有兴趣的读者可以在本案例的基础上对数据进一步分析,或是对爬虫做进一步的开发,增加更多功能。
请求、解析、处理数据是通用爬虫的三个步骤,在本案例中,利用机场官网的详细信息,在网页上定位各类数据的路径,通过Scrapy爬取得到对应的数据,最后将多个数据统筹整合进一个JSON文件,最终得到机场航班的相关信息。
01、分析网页
打开机场官网(详见前言中的二维码),以进港航班信息为例,存储航班信息的详细页面如图1所示。
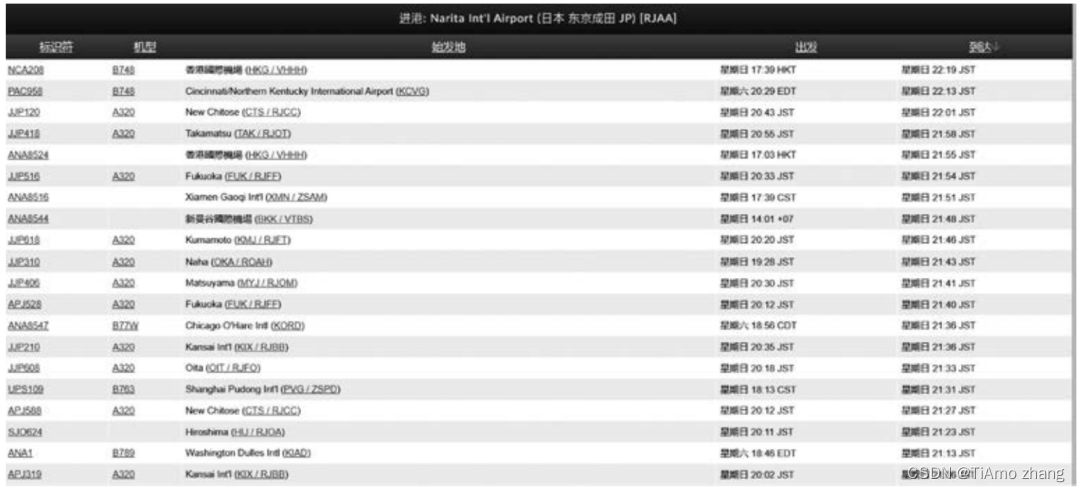
■ 图1 机场进港航班数据列表
按F12键打开浏览器的调试模式,可以通过Elements来定位当前页面中数据的存放位置,样例如图2所示。Elements中的元素比较复杂,所以本次爬虫决定使用Scrapy框架直接获取网页的页面内容,通过element的XPath来精准定位需要爬取的数据。

■ 图2 数据存放位置的样例图
02、编写爬虫
该爬虫使用了Scrapy框架,读者需预先安装Python发行版,并在终端中输入pip install scrapy指令来安装Scrapy框架。
Scrapy框架的目录层次如图3所示。

■ 图3 Scrapy框架的目录层次
比较重要的是items.py、settings.py、pipelines.py、middlewares.py以及spiders文件夹中放置的爬虫主程序。在settings.py文件中,可以对框架进行一些设置。例如,是否使用中间件、是否使用管道等。items.py文件是一个对象文件,用于指示本次爬虫爬取对象的结构,以存放爬取到的数据,下面以TrafficItems.py文件为例,来看一看该内容需要如何实现。
【例1】指示爬取对象的结构,将爬取到的数据保存至TrafficItems.py文件。
import scrapy
class TrafficItems(scrapy.Item):
sysmbol = scrapy.Field() #标识符
model = scrapy.Field()
leavePlace = scrapy.Field() #始发地
leaveAirport = scrapy.Field() #出发机场
destssination = scrapy.Field() #目的地
destssinationAirport = scrapy.Field() #到达机场
flightTime = scrapy.Field() #起飞时间
flightTimeEx = scrapy.Field() #起飞时区
arrivedTime = scrapy.Field() #到达时间
arrivedTimeEx = scrapy.Field() #到达时区
pass构造对象的过程利用了Python面向对象写法,在这里需要引用Scrapy库,使用Field是为了以下两点。
(1) Field对象指明了每个字段的元数据(任何元数据),Field对象接收的值没有任何限制。
(2) 设置Field对象的主要目的就是在一个地方定义好所有的元数据。
MySpiders.py文件位于文件Spiders下,该文件中存放了提取数据的Spider,它用于定义初始URL根网址、请求初始URL之后的逻辑,以及从页面中爬取数据的规则(即写正则或xpath等)。
【例2】执行Spider,爬虫获取数据MySpider.py主文件。
import scrapy
from yryProject.TrafficItems
import TrafficItems
class MySpider(scrapy.Spider):
name ="MySpider"allowed domains =['flightaware.com']start_urls =['https://zh, flightaware. com/live/airport/RJAA/arrivals?;offset = 0; sort =ASC;order =actualarrivaltime']
def parse(self,response):
items =targe
tFile = open("target.html",w',encoding = "utf - 8")targetFile.write(str(response.body))for box in response.xpath( "//*[@ d ='slide0utPanel']/div[1]/table[2]/tbody/trtdl11/table/tbody/tr") :
item = TrafficItems()
Symbol = box.xpath("./td[1]/span/a/text()").extract()
model = box.xpath("./td[ 2]/span/a/text()").extract()
leavePlace = box.xpath("./td[3]/span[1]/span/text()").extract()
landPlace = box.xpath("./td[3]/span[1]/span/text()").extract()leaveAirport = b ox.xpath("./td[3]/span[2]/a/text()").extract()#landAirport = box.xpath("./td[3]/span[2]/a/text()").extract()
flyTime = box.xpath("./td[ 4]/text()").extract()
flyTimeEx = box.xpath("./td[4]/span/text()").extract()
arriveTime = box.xpath("./td[ 5]/text()").extract()
arriveTimeEX = box.xpath("./td[5]/span/text()").extract()
if (Symbol !=[]):
item['Symbol =Symbol[ 0]
else:
item['Symbol'] = unknown'
if (model !=[]):
item['model'] = model[0]
else:
item['model'] =unknown'if (leavePlace != []):item['leavePlace'] = leavePlace[0]
else:
item['leavePlace'] = unknown'
if (leaveAirport !=[]):
item[leaveAirport'] = eaveAirport[0]else:
item[leaveAirport'] = unknownif (flyTime != []):
item['flightTime'] = flyTime[0]else:
item['flightTime'] = unknownif (flyTimeEx != []):
item['flightTimeEx'] = flyTimeEx[0]else:
item['flightTimeEx'] = unknown'if (arriveTime !=[]):
item['arrivedTime'] = arriveTime[0]else:
item['arrivedTime']"'unknownif (arriveTimeEX != []):
item[arrivedTimeEx'] = arriveTimeEX[0]
else:
itemarrivedTimeEx'] = unknown!yield item
response. xpath( "/html/body/div[1]/div[1]/table[ 2]/tbody/tr/td[1].next url =
span[2]/a[1]/@href").extract first()print(next url)yield scrapy.Request(next url,callback = self.parse)
#return items
在Spider文件中,需要定义一个爬虫名与爬取的网址的域名(allowed_domains),首先需要给出一个起始地址(start_urls),然后Scrapy框架就可以根据这个起始地址获取网页源代码,通过源代码获取所需值。下面通过XPath定位对应数据所在的HTML位置,再存放至item中构造好的对应字段中。这样就完成了一次爬取。
此处,一次性爬取一个页面的完整内容后,对于后续页面,可以通过next_url存放下一页面的网址。在爬取完后通过yield scrapy.Request(next_url,callback=self.parse)定位下一页,从而实现模拟翻页。
Mypipeline.py文件是一个管道文件,它约定了爬虫爬取后的内容流向哪里,由于需要存储这些爬取后的文件,所以在管道中将其写入了一个JSON文件。Item在Spider中被收集之后,它将会被传递到Item Pipeline,Pipeline接收到Item并通过它执行一些行为,同时也决定此Item是否能继续通过Pipeline,或是被丢弃。例3为Mypipeline.py的详细代码。
【例3】约定爬取到的内容如何处理。
#Mypipeline.py
#引入文件
from scrapy.exceptions import DropItem
import json
class MyPipeline(object):
def init (self):
# 打开文件
self.file = open('data.json','w',encoding ='utf - 8')
# 该方法用于处理数据
def process item(self,item,spider):
#读取 item 中的数据
line = json.dumps(dict(item),ensure ascii= Ealse)
#写入文件
self.file.write(line)
#返回 item
return item
#该方法在 spider 被开启时被调用def open spider(self,spider):
pass
#该方法在 spider 被关闭时被调用def close spider(self,spider):
pass由于案例中爬取数据所用的浏览器为Chrome,本爬虫使用了ChromeDriver。当编写此爬虫时, Chrome版本为85.0.4183.83,所使用的ChromeDriver需要和Chrome版本相匹配,则需要在chromeMiddleware.py中将driver初始化的指向路径改为本机中存放ChromeDriver的绝对路径。
【例4】设置ChromeDriver启动参数的中间件配置文件。
# chromeMiddleware.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from scrapy.http import HtmlResponse
import time
class chromeMiddleware(object):
def process request(self,request,spider):if spider.name == "MySpider":chrome options = Options()chrome options.add argument('--headless
chrome options.add argument('--disable -gpu')
chrome options.add argument('-- no -sandbox')
chrome options.add argument('-- ignore- certificate-errors')
chrome options.add argument('-- ignore - ssl - errors')
driver = webdriver.Chrome( "E: scrapy_work yryProject\yryProject chromedriverexe",chrome options = chrome options)driver.get(request.url)body = driver.page source#print("访问”+ request.url)return HtmlResponse(driver.current url, body= body, encoding = UTF - 8,request:
request
else:
return None在爬虫运行的过程中,需要对一些细节进行设定,如设定爬虫运行的持续时间、限制爬取内容的数量,或是对爬虫延迟做出调整,这些需要调整的变量都存放于settings.py中,代码如例5所示。
【例5】设置爬虫通用属性的文件。
# settings.py
import uagent
BOT NAME =yryProject'
SPIDER MODULES =['yryProject.spiders']NEWSPIDER MODULE = yryProject.spidersCLOSESPIDER PAGECOUNT = 4
FEED EXPORT ENCODING =UTF - 8
ROBOTSTXT OBEY = False
USER AGENT = uagent.randomUserAgent()
DEFAULT REOUEST HEADERS =
Accept':'text/html,application/xhtml + xml,application/xml;q= 0.9,*/*;q= 0.8''Accept - Language':'en'
DOWNLOADER MIDDLEWARES = yryProject.chromeMiddleware.chromeMiddleware': 543
ITEM PIPELINES = (
yryProject.MyPipeline.MyPipeline': 1
}03、爬虫的使用说明
修改完地址后,进入\yryProject目录,执行scrapy crawl MySpider即可运行爬虫。
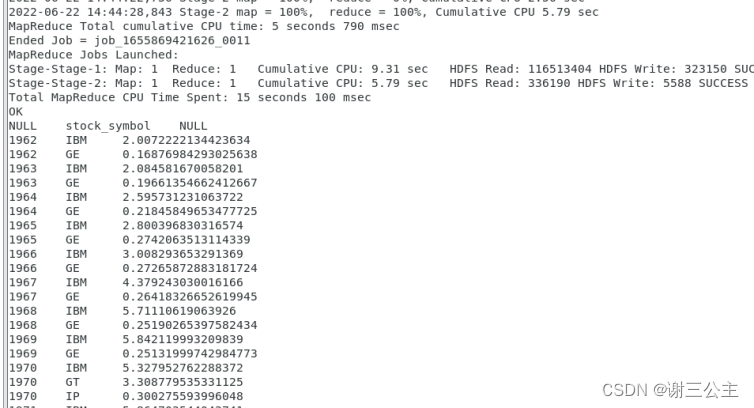
爬取的结果保存在data.json文件中,其截图如图4所示。

■ 图4 爬取结果展示