RFS (Receive Flow Steering)
RFS(Receive flow steering)和 RPS 配合使用。RPS 试图在 CPU 之间平衡收包,但是没考虑 数据的本地性问题,如何最大化 CPU 缓存的命中率。RFS 将属于相同 flow 的包送到相同的 CPU 进行处理,可以提高缓存命中率。
调优:打开 RFS
RPS 记录一个全局的 hash table,包含所有 flow 的信息。这个 hash table 的大小可以在 net.core.rps_sock_flow_entries:
$ sudo sysctl -w net.core.rps_sock_flow_entries=32768
1
其次,你可以设置每个 RX queue 的 flow 数量,对应着 rps_flow_cnt:
例如,eth0 的 RX queue0 的 flow 数量调整到 2048:
$ sudo bash -c 'echo 2048 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt' 1
aRFS (Hardware accelerated RFS,需要硬件支持)
Accelerated RFS,类似英特尔硬件的Flow Director机制,或者是不同的说法
Accelerated RFS 之于 RFS 相当于 RSS 之于 RPS。Accelerated RFS 在硬件上就可以选择正确的队列,随后触发该数据包所属流所在的 CPU 的中断。由此可见,如果想要在硬件上实现队列选择,我们需要一个从流到硬件队列的对应关系。
从上文可知,我们已经有了一个从流到 CPU 的映射关系,记录在 rps_dev_flow 表中。
然后,我们也有 CPU 和硬件队列的关系,通过 /proc/irq/<irq_num>/smp_affinity 进行配置。
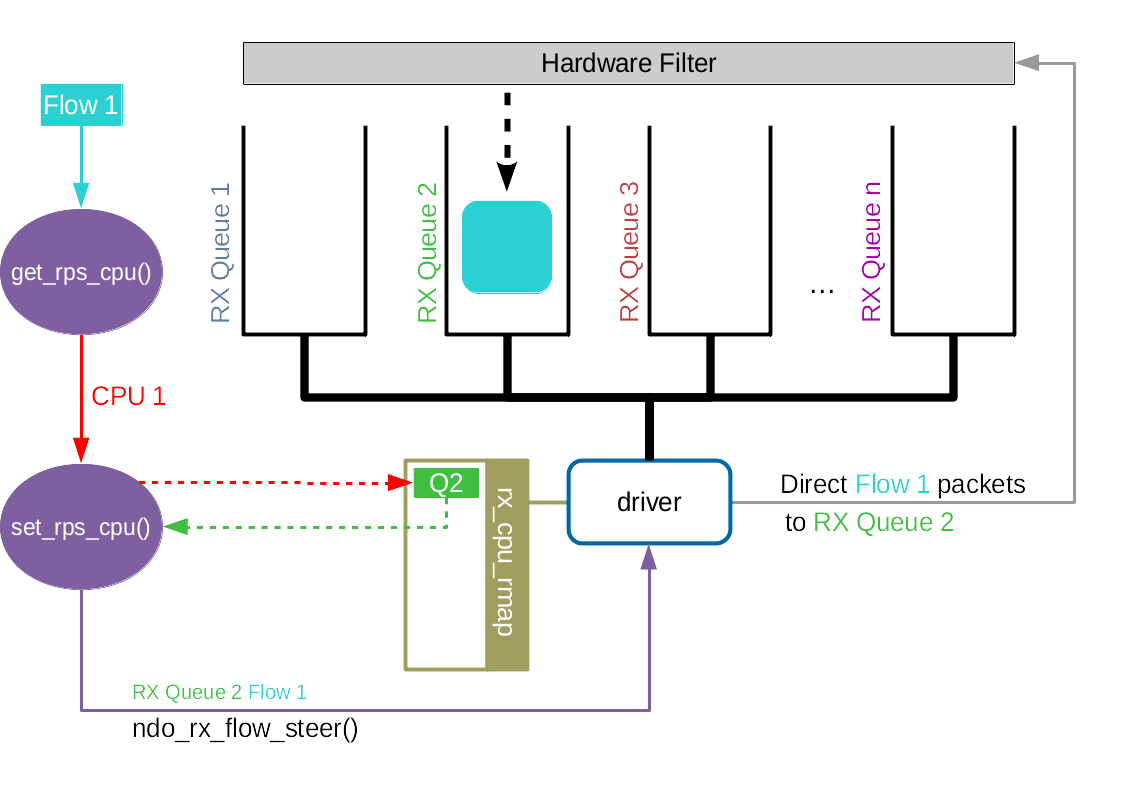
每当 rps_dev_flow 表中的条目被更新,网络协议栈就会调用驱动中的 ndo_rx_flow_steer 函数来更新流到硬件队列的对应关系。
Accelerated RFS 需要在编译阶段使能 CONFIG_RFS_ACCEL,并且需要硬件和驱动的支持。此外,还需要使用 ethtool 设置 ntuple 过滤。其他的就不需要配置了。
Accelerated RFS 机制可以将数据包直接放在最终的 CPU 硬件队列上,所以性能应该是要比 RFS 高。因此,当硬件支持该选项,应该选择此机制。
RFS 可以用硬件加速,网卡和内核协同工作,判断哪个 flow 应该在哪个 CPU 上处理。这需要网卡和网卡驱动的支持。
如果你的网卡驱动里对外提供一个 ndo_rx_flow_steer 函数,那就是支持 RFS。
调优: 启用 aRFS
假如你的网卡支持 aRFS,你可以开启它并做如下配置:
- 打开并配置 RFS 内核中编译期间指定了 CONFIG_RFS_ACCEL 选项。Ubuntu kernel 3.13.0 是有的
- 打开网卡的 ntuple 支持。可以用 ethtool 查看当前的 ntuple 设置 配置 IRQ(硬中断)中每个 RX 和 CPU
的对应关系
以上配置完成后,aRFS 就会自动将 RX queue 数据移动到指定 CPU 的内存,每个 flow 的包都会 到达同一个 CPU,不需要你再通过 ntuple 手动指定每个 flow 的配置了。
作用是最大化数据本地性(data locality),以增加 CPU 处理网络数据时的 缓存命中率。例如,考虑运行在 80 口的 web 服务器:
webserver 进程运行在 80 口,并绑定到 CPU 2
和某个 RX queue 关联的硬中断绑定到 CPU 2
目的端口是80 的 TCP 流量通过 ntuple filtering 绑定到 CPU 2
接下来所有到 80口的流量,从数据包进来到数据到达用户程序的整个过程,都由 CPU 2 处理
仔细监控系统的缓存命中率、网络栈的延迟等信息,以验证以上配置是否生效
远程NIC RPS
如果网卡只支持单个队列,并且有多个 CPU 的的话,在 NUMA 系统中,一般将 RPS CPU 设置为在相同 domain 的 CPU,非 NUMA 系统就无所谓了,因为设置为每一个 CPU 的性能都是一样的。
对于多队列网卡,一般系统不会同时启用 RSS 和 RPS,因为这没什么好处。但也有例外,比如网卡所支持的队列数目少于 CPU 数,也就是每个 CPU 还分不到一个接收队列,那么使用 RPS 可能会使得 CPU 的任务分布更高效。
回顾一下这些机制之间的关系。首先是 RSS/RPS,该机制在接收数据包的时候,通过手动配置,甚至是根据负载情况的自动配置(如 irqbalance),来把数据包的处理负载均匀分配到不同的 CPU 上。RSS/RPS 仅根据负载大小进行判断,但是这可能导致从协议栈处理到上层应用处理之间数据包的转移。
因此 RFS/aRFS 更进一步,在进行 CPU 选择的时候考虑上层应用所处位置,对每一个流都配置一个 Desired CPU。因此,在为数据包选择 CPU 的时候,会优先选择 Desired CPU。
参考:
网络参数 RSS、RPS、RFS、aRFS 学习总结
https://blog.luckyoung.org/2023/23-02-13_network-parameters/#receive-flow-steering-rfs
linux内核网络协议栈–监控和调优
http://t.csdn.cn/39ud0