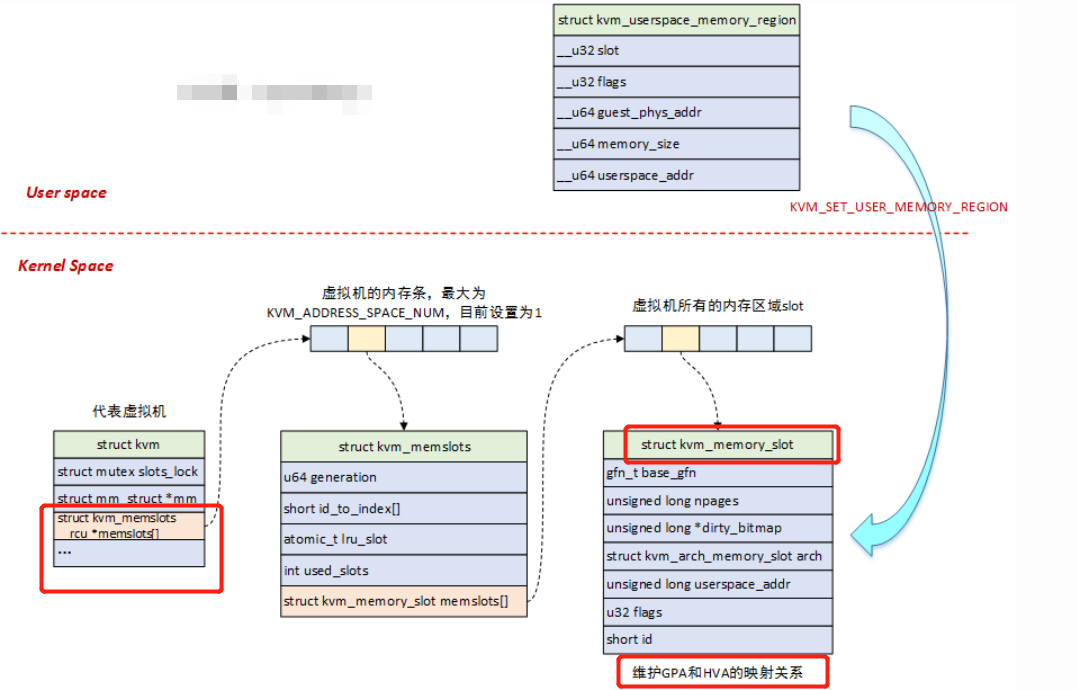
struct kvm_memory_slot
http://tinylab.org/kvm-intro-part1
https://www.cnblogs.com/LoyenWang/p/13943005.html
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !
- 虚拟机使用
slot来组织物理内存,每个slot对应一个struct kvm_memory_slot,一个虚拟机的所有slot构成了它的物理地址空间; - 用户态使用
struct kvm_userspace_memory_region来设置内存slot,在内核中使用struct kvm_memslots结构来将kvm_memory_slot组织起来; struct kvm_userspace_memory_region结构体中,包含了slot的ID号用于查找对应的slot,此外还包含了物理内存起始地址及大小,以及HVA地址,HVA地址是在用户进程地址空间中分配的,也就是Qemu进程地址空间中的一段区域;
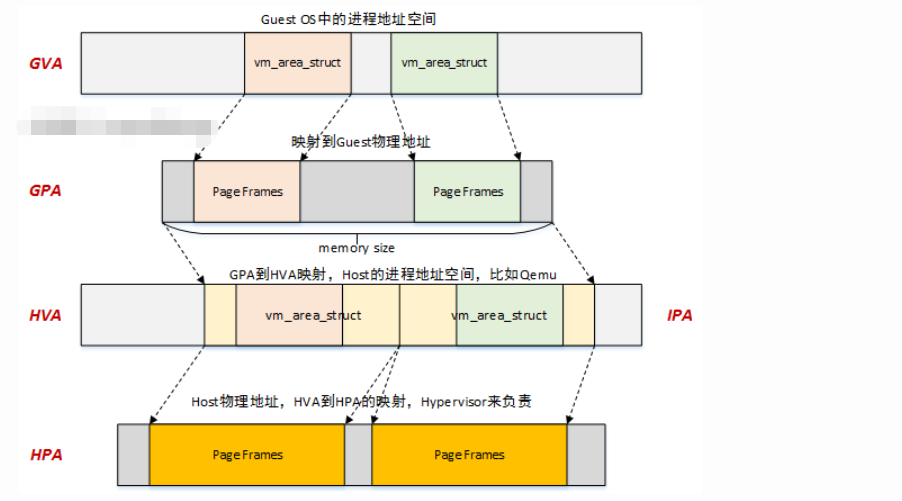
GPA->HVA
KVM-Qemu方案中,GPA->HVA的转换,是通过ioctl中的KVM_SET_USER_MEMORY_REGION命令来实现的,如下图:
HVA->HPA
光有了GPA->HVA,似乎还是跟Hypervisor没有太大关系,到底是怎么去访问物理内存的呢?貌似也没有看到去建立页表映射啊?
跟我走吧,带着问题出发!
之前内存管理相关文章中提到过,用户态程序中分配虚拟地址vma后,实际与物理内存的映射是在page fault时进行的。那么同样的道理,我们可以顺着这个思路去查找是否HVA->HPA的映射也是在异常处理的过程中创建的?答案是显然的。
- 当用户态触发
kvm_arch_vcpu_ioctl_run时,会让Guest OS去跑在Hypervisor上,当Guest OS中出现异常退出到Host时,此时handle_exit将对退出的原因进行处理;
异常处理函数arm_exit_handlers如下,具体调用选择哪个处理函数,是根据ESR_EL2, Exception Syndrome Register(EL2)中的值来确定的。

static exit_handle_fn arm_exit_handlers[] = {
[0 ... ESR_ELx_EC_MAX] = kvm_handle_unknown_ec,
[ESR_ELx_EC_WFx] = kvm_handle_wfx,
[ESR_ELx_EC_CP15_32] = kvm_handle_cp15_32,
[ESR_ELx_EC_CP15_64] = kvm_handle_cp15_64,
[ESR_ELx_EC_CP14_MR] = kvm_handle_cp14_32,
[ESR_ELx_EC_CP14_LS] = kvm_handle_cp14_load_store,
[ESR_ELx_EC_CP14_64] = kvm_handle_cp14_64,
[ESR_ELx_EC_HVC32] = handle_hvc,
[ESR_ELx_EC_SMC32] = handle_smc,
[ESR_ELx_EC_HVC64] = handle_hvc,
[ESR_ELx_EC_SMC64] = handle_smc,
[ESR_ELx_EC_SYS64] = kvm_handle_sys_reg,
[ESR_ELx_EC_SVE] = handle_sve,
[ESR_ELx_EC_IABT_LOW] = kvm_handle_guest_abort,
[ESR_ELx_EC_DABT_LOW] = kvm_handle_guest_abort,
[ESR_ELx_EC_SOFTSTP_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_WATCHPT_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_BREAKPT_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_BKPT32] = kvm_handle_guest_debug,
[ESR_ELx_EC_BRK64] = kvm_handle_guest_debug,
[ESR_ELx_EC_FP_ASIMD] = handle_no_fpsimd,
[ESR_ELx_EC_PAC] = kvm_handle_ptrauth,
};

这个函数表,发现ESR_ELx_EC_DABT_LOW和ESR_ELx_EC_IABT_LOW两个异常,这不就是指令异常和数据异常吗,我们大胆的猜测,HVA->HPA映射的建立就在kvm_handle_guest_abort函数中。
虚拟机内存初始化
https://abelsu7.top/2019/07/07/kvm-memory-virtualization/
qemu中用AddressSpace用来表示CPU/设备看到的内存,两个全局 Address_sapce: address_space_memory、 address_space_io,地址空间之间通过链表连接起来
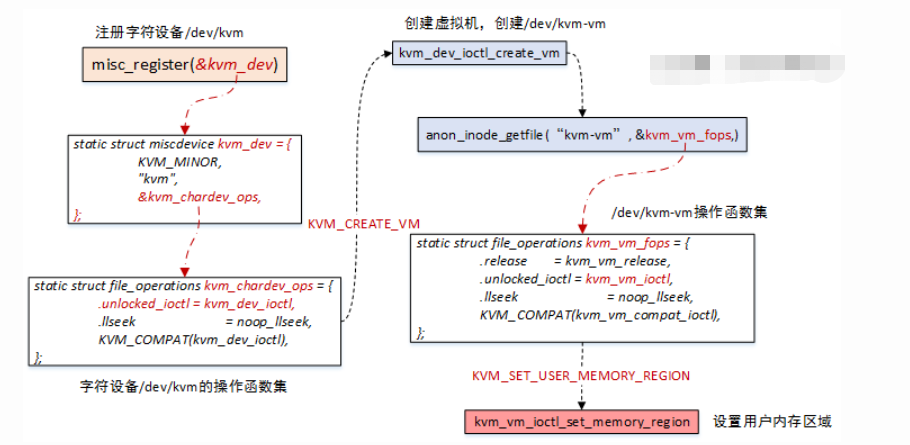
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);来修改Guest的内存空间的
在kvm_init()函数中主要做如下几件事情:
1、s->fd = qemu_open("/dev/kvm", O_RDWR),打开kvm控制的总设备文件/dev/kvm
2、s->vmfd = kvm_ioctl(s, KVM_CREATE_VM, 0),调用创建虚拟机的API,对应Linux kernel中的创建流程,请全文搜索kernel,关键词“KVM_CREATE_VM”
3、kvm_check_extension,检查各种extension,并设置对应的features
4、ret = kvm_arch_init(s),做一些体系结构相关的初始化,如msr、identity map、mmu pages number等等
5、kvm_irqchip_create,调用kvm_vm_ioctl(s, KVM_CREATE_IRQCHIP)在KVM中虚拟IRQ芯片,详细流程请全文搜索
6、memory_listener_register,该函数是初始化内存的主要函数,
memory_listener_register调用了两次,分别注册了 kvm_memory_listener和kvm_io_listener,即通用的内存和MMIO是分开管理的。
以通用的内存注册为例,函数首先在全局的memory_listener链表中添加了kvm_memory_listener,之后调用listener_add_address_space分别将该listener添加到address_space_memory和address_space_io中, address_space_io是虚机的io地址空间(设备的io port就分布在这个地址空间里)
然后调用listener的region_add(即kvm_region_add()),该函数最终调用了kvm_set_user_memory_region(),其中调用kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem),该调用是最终将内存区域注册到kvm中的函数。

int main()
└─ static int configure_accelerator()
└─ int kvm_init() // 初始化 KVM
├─ int kvm_ioctl(KVM_CREATE_VM) // 创建 VM
├─ int kvm_arch_init() // 针对不同的架构进行初始化
└─ void memory_listener_register() // 注册 kvm_memory_listener
└─ static void listener_add_address_space() // 调用 region_add 回调
└─ static void kvm_region_add() // region_add 对应的回调实现
|
└─memory_region_get_ram_ptr
└─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot
└─ static int kvm_set_user_memory_region()
└─ int ioctl(KVM_SET_USER_MEMORY_REGION)


int kvm_init(void)
{
/* ... */
s->vmfd = kvm_ioctl(s, KVM_CREATE_VM, 0); // 创建 VM
/* ... */
ret = kvm_arch_init(s); // 针对不同的架构进行初始化
if (ret < 0) {
goto err;
}
/* ... */
memory_listener_register(&kvm_memory_listener, NULL); // 注册回调函数
/* ... */
}


static void kvm_region_add(MemoryListener *listener,
MemoryRegionSection *section)
{
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
memory_region_ref(section->mr);
kvm_set_phys_mem(kml, section, true);
}
这个函数看似复杂,主要是因为,需要判断变化的各种情况是否与之前的重合,是否是脏页等等情况。我们只看最开始的情况。
static void kvm_set_phys_mem(KVMMemoryListener *kml,
MemoryRegionSection *section, bool add)
{
KVMState *s = kvm_state;
KVMSlot *mem, old;
int err;
MemoryRegion *mr = section->mr;
bool writeable = !mr->readonly && !mr->rom_device;
hwaddr start_addr = section->offset_within_address_space;
ram_addr_t size = int128_get64(section->size);
void *ram = NULL;
unsigned delta;
/* kvm works in page size chunks, but the function may be called
with sub-page size and unaligned start address. Pad the start
address to next and truncate size to previous page boundary. */
delta = qemu_real_host_page_size - (start_addr & ~qemu_real_host_page_mask);
delta &= ~qemu_real_host_page_mask;
if (delta > size) {
return;
}
start_addr += delta;
size -= delta;
size &= qemu_real_host_page_mask;
if (!size || (start_addr & ~qemu_real_host_page_mask)) {
return;
}
if (!memory_region_is_ram(mr)) {
if (writeable || !kvm_readonly_mem_allowed) {
return;
} else if (!mr->romd_mode) {
/* If the memory device is not in romd_mode, then we actually want
* to remove the kvm memory slot so all accesses will trap. */
add = false;
}
}
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + delta;
...
if (!size) {
return;
}
if (!add) {
return;
}
mem = kvm_alloc_slot(kml);
mem->memory_size = size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(mr);
err = kvm_set_user_memory_region(kml, mem);
if (err) {
fprintf(stderr, "%s: error registering slot: %sn", __func__,
strerror(-err));
abort();
}
}
这个函数主要就是得到MemoryRegionSection在address_space中的位置,这个就是虚拟机的物理地址,函数中是start_addr,
然后通过memory_region_get_ram_ptr得到对应其对应的qemu的HVA地址,函数中是ram,当然还有大小的size以及这块内存的flags,这些参数组成了一个KVMSlot,之后传递给kvm_set_user_memory_region。
static int kvm_set_user_memory_region(KVMMemoryListener *kml, KVMSlot *slot)
{
KVMState *s = kvm_state;
struct kvm_userspace_memory_region mem;
mem.slot = slot->slot | (kml->as_id << 16);
mem.guest_phys_addr = slot->start_addr;
mem.userspace_addr = (unsigned long)slot->ram;
mem.flags = slot->flags;
if (slot->memory_size && mem.flags & KVM_MEM_READONLY) {
/* Set the slot size to 0 before setting the slot to the desired
* value. This is needed based on KVM commit 75d61fbc. */
mem.memory_size = 0;
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
mem.memory_size = slot->memory_size;
return kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
通过层层抽象,我们终于完成了GPA->HVA的对应,并且传递到了KVM

KVM_SET_USER_MEMORY_REGION kvm_vm_ioctl_set_memory_region
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem)
┝━kvm_vm_ioctl_set_memory_region()-->kvm_set_memory_region()-->__kvm_set_memory_region()
/*
* kvm ioctl vm指令的入口,传入的fd为KVM_CREATE_VM中返回的fd。
* 主要用于针对VM虚拟机进行控制,如:内存设置、创建VCPU等。
*/
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
if (kvm->mm != current->mm)
return -EIO;
switch (ioctl) {
// 创建VCPU
case KVM_CREATE_VCPU:
r = kvm_vm_ioctl_create_vcpu(kvm, arg);
break;
// 建立guest物理地址空间中的内存区域与qemu-kvm虚拟地址空间中的内存区域的映射
case KVM_SET_USER_MEMORY_REGION: {
// 存放内存区域信息的结构体,该内存区域从qemu-kvm进程的用户地址空间中分配
struct kvm_userspace_memory_region kvm_userspace_mem;
r = -EFAULT;
// 从用户态拷贝相应数据到内核态,入参argp指向用户态地址
if (copy_from_user(&kvm_userspace_mem, argp,
sizeof kvm_userspace_mem))
goto out;
// 进入实际处理流程
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem);
break;
}

数据结构部分已经罗列了大体的关系,那么在KVM_SET_USER_MEMORY_REGION时,围绕的操作就是slots的创建、删除,更新等操作,话不多说,来图了:
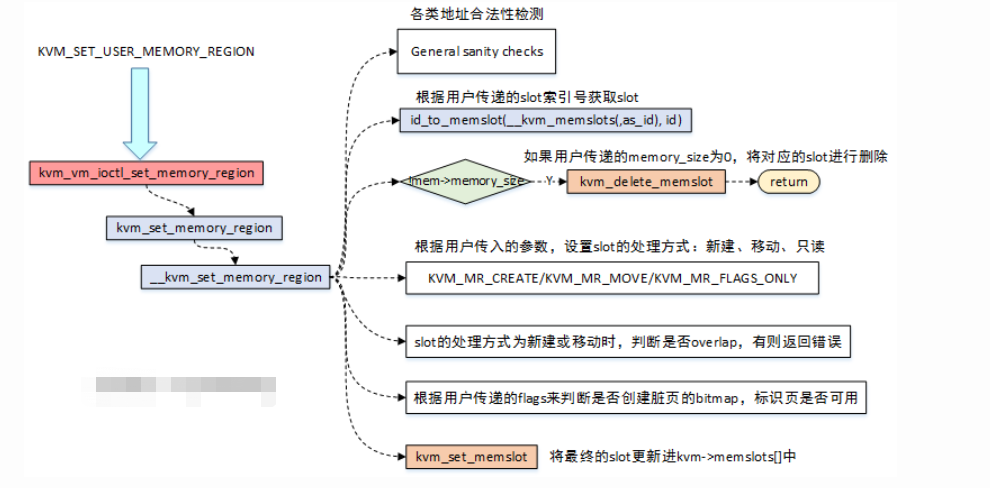
- 当用户要设置内存区域时,最终会调用到
__kvm_set_memory_region函数,在该函数中完成所有的逻辑处理; __kvm_set_memory_region函数,首先会对传入的struct kvm_userspace_memory_region的各个字段进行合法性检测判断,主要是包括了地址的对齐,范围的检测等;- 根据用户传递的
slot索引号,去查找虚拟机中对应的slot,查找的结果只有两种:1)找到一个现有的slot;2)找不到则新建一个slot; - 如果传入的参数中
memory_size为0,那么会将对应slot进行删除操作; - 根据用户传入的参数,设置
slot的处理方式:KVM_MR_CREATE,KVM_MR_MOVE,KVM_MEM_READONLY; - 根据用户传递的参数决定是否需要分配脏页的bitmap,标识页是否可用;
- 最终调用
kvm_set_memslot来设置和更新slot信息;

/*
* 建立guest物理地址空间中的内存区域与qemu-kvm虚拟地址空间中的内存区域的映射
* 相应信息由uerspace_memory_region参数传入,而其源头来自于用户态qemu-kvm。每次
* 调用设置一个内存区间。内存区域可以不连续(实际的物理内存区域也经常不连
* 续,因为有可能有保留内存)
*/
int __kvm_set_memory_region(struct kvm *kvm,
struct kvm_userspace_memory_region *mem)
{
int r;
gfn_t base_gfn;
unsigned long npages;
struct kvm_memory_slot *slot;
struct kvm_memory_slot old, new;
struct kvm_memslots *slots = NULL, *old_memslots;
enum kvm_mr_change change;
// 标记检查
r = check_memory_region_flags(mem);
if (r)
goto out;
r = -EINVAL;
/* General sanity checks */
// 合规检查,防止用户态恶意传参,导致安全漏洞
if (mem->memory_size & (PAGE_SIZE - 1))
goto out;
if (mem->guest_phys_addr & (PAGE_SIZE - 1))
goto out;
/* We can read the guest memory with __xxx_user() later on. */
if ((mem->slot < KVM_USER_MEM_SLOTS) &&
((mem->userspace_addr & (PAGE_SIZE - 1)) ||
!access_ok(VERIFY_WRITE,
(void __user *)(unsigned long)mem->userspace_addr,
mem->memory_size)))
goto out;
if (mem->slot >= KVM_MEM_SLOTS_NUM)
goto out;
if (mem->guest_phys_addr + mem->memory_size < mem->guest_phys_addr)
goto out;
// 将kvm_userspace_memory_region->slot转换为kvm_mem_slot结构,该结构从kvm->memslots获取
slot = id_to_memslot(kvm->memslots, mem->slot);
// 内存区域起始位置在Guest物理地址空间中的页框号
base_gfn = mem->guest_phys_addr >> PAGE_SHIFT;
// 内存区域大小转换为page单位
npages = mem->memory_size >> PAGE_SHIFT;
r = -EINVAL;
if (npages > KVM_MEM_MAX_NR_PAGES)
goto out;
if (!npages)
mem->flags &= ~KVM_MEM_LOG_DIRTY_PAGES;
new = old = *slot;
new.id = mem->slot;
new.base_gfn = base_gfn;
new.npages = npages;
new.flags = mem->flags;
r = -EINVAL;
if (npages) {
// 判断是否需新创建内存区域
if (!old.npages)
change = KVM_MR_CREATE;
// 判断是否修改现有的内存区域
else { /* Modify an existing slot. */
// 修改的区域的HVA不同或者大小不同或者flag中的
// KVM_MEM_READONLY标记不同,直接退出。
if ((mem->userspace_addr != old.userspace_addr) ||
(npages != old.npages) ||
((new.flags ^ old.flags) & KVM_MEM_READONLY))
goto out;
/*
* 走到这,说明被修改的区域HVA和大小都是相同的
* 判断区域起始的GFN是否相同,如果是,则说明需
* 要在Guest物理地址空间中move这段区域,设置KVM_MR_MOVE标记
*/
if (base_gfn != old.base_gfn)
change = KVM_MR_MOVE;
// 如果仅仅是flag不同,则仅修改标记,设置KVM_MR_FLAGS_ONLY标记
else if (new.flags != old.flags)
change = KVM_MR_FLAGS_ONLY;
// 否则,啥也不干
else { /* Nothing to change. */
r = 0;
goto out;
}
}
} else if (old.npages) {/*如果新设置的区域大小为0,而老的区域大小不为0,则表示需要删除原有区域。*/
change = KVM_MR_DELETE;
} else /* Modify a non-existent slot: disallowed. */
goto out;
if ((change == KVM_MR_CREATE) || (change == KVM_MR_MOVE)) {
/* Check for overlaps */
r = -EEXIST;
// 检查现有区域中是否重叠的
kvm_for_each_memslot(slot, kvm->memslots) {
if ((slot->id >= KVM_USER_MEM_SLOTS) ||
(slot->id == mem->slot))
continue;
if (!((base_gfn + npages <= slot->base_gfn) ||
(base_gfn >= slot->base_gfn + slot->npages)))
goto out;
}
}
/* Free page dirty bitmap if unneeded */
if (!(new.flags & KVM_MEM_LOG_DIRTY_PAGES))
new.dirty_bitmap = NULL;
r = -ENOMEM;
// 如果需要创建新区域
if (change == KVM_MR_CREATE) {
new.userspace_addr = mem->userspace_addr;
// 设置新的内存区域架构相关部分
if (kvm_arch_create_memslot(&new, npages))
goto out_free;
}
/* Allocate page dirty bitmap if needed */
if ((new.flags & KVM_MEM_LOG_DIRTY_PAGES) && !new.dirty_bitmap) {
if (kvm_create_dirty_bitmap(&new) < 0)
goto out_free;
}
// 如果删除或move内存区域
if ((change == KVM_MR_DELETE) || (change == KVM_MR_MOVE)) {
r = -ENOMEM;
// 复制kvm->memslots的副本
slots = kmemdup(kvm->memslots, sizeof(struct kvm_memslots),
GFP_KERNEL);
if (!slots)
goto out_free;
slot = id_to_memslot(slots, mem->slot);
slot->flags |= KVM_MEMSLOT_INVALID;
// 安装新memslots,返回旧的memslots
old_memslots = install_new_memslots(kvm, slots, NULL);
/* slot was deleted or moved, clear iommu mapping */
// 原来的slot需要删除,所以需要unmap掉相应的内存区域
kvm_iommu_unmap_pages(kvm, &old);
/* From this point no new shadow pages pointing to a deleted,
* or moved, memslot will be created.
*
* validation of sp->gfn happens in:
* - gfn_to_hva (kvm_read_guest, gfn_to_pfn)
* - kvm_is_visible_gfn (mmu_check_roots)
*/
// flush影子页表中的条目
kvm_arch_flush_shadow_memslot(kvm, slot);
slots = old_memslots;
}
// 处理private memory slots,对其分配用户态地址,即HVA
r = kvm_arch_prepare_memory_region(kvm, &new, mem, change);
if (r)
goto out_slots;
r = -ENOMEM;
/*
* We can re-use the old_memslots from above, the only difference
* from the currently installed memslots is the invalid flag. This
* will get overwritten by update_memslots anyway.
*/
if (!slots) {
slots = kmemdup(kvm->memslots, sizeof(struct kvm_memslots),
GFP_KERNEL);
if (!slots)
goto out_free;
}
/*
* IOMMU mapping: New slots need to be mapped. Old slots need to be
* un-mapped and re-mapped if their base changes. Since base change
* unmapping is handled above with slot deletion, mapping alone is
* needed here. Anything else the iommu might care about for existing
* slots (size changes, userspace addr changes and read-only flag
* changes) is disallowed above, so any other attribute changes getting
* here can be skipped.
*/
if ((change == KVM_MR_CREATE) || (change == KVM_MR_MOVE)) {
r = kvm_iommu_map_pages(kvm, &new);
if (r)
goto out_slots;
}
/* actual memory is freed via old in kvm_free_physmem_slot below */
if (change == KVM_MR_DELETE) {
new.dirty_bitmap = NULL;
memset(&new.arch, 0, sizeof(new.arch));
}
//将new分配的memslot写入kvm->memslots[]数组中
old_memslots = install_new_memslots(kvm, slots, &new);
kvm_arch_commit_memory_region(kvm, mem, &old, change);
// 释放旧内存区域相应的物理内存(HPA)
kvm_free_physmem_slot(&old, &new);
kfree(old_memslots);
return 0;
out_slots:
kfree(slots);
out_free:
kvm_free_physmem_slot(&new, &old);
out:
return r;
}

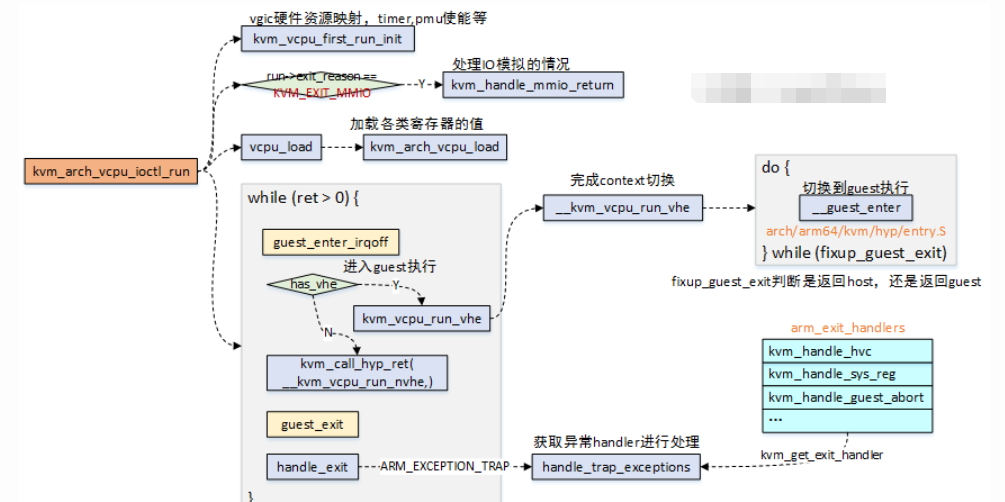
kvm_handle_guest_abort
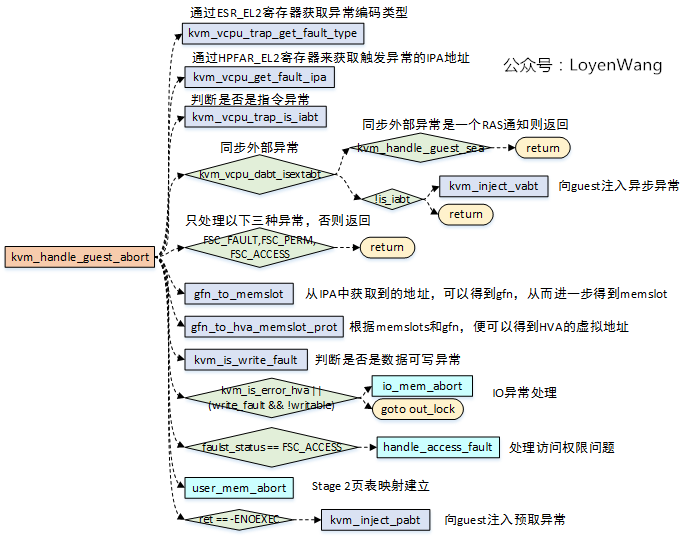
-
kvm_vcpu_trap_get_fault_type用于获取ESR_EL2的数据异常和指令异常的fault status code,也就是ESR_EL2的ISS域;kvm_vcpu_get_fault_ipa用于获取触发异常的IPA地址;kvm_vcpu_trap_is_iabt用于获取异常类,也就是ESR_EL2的EC,并且判断是否为ESR_ELx_IABT_LOW,也就是指令异常类型;kvm_vcpu_dabt_isextabt用于判断是否为同步外部异常,同步外部异常的情况下,如果支持RAS,Host能处理该异常,不需要将异常注入给Guest;- 异常如果不是
FSC_FAULT,FSC_PERM,FSC_ACCESS三种类型的话,直接返回错误; gfn_to_memslot,gfn_to_hva_memslot_prot这两个函数,是根据IPA去获取到对应的memslot和HVA地址,这个地方就对应到了上文中第二章节中地址关系的建立了,由于建立了连接关系,便可以通过IPA去找到对应的HVA;- 如果注册了RAM,能获取到正确的HVA,如果是IO内存访问,那么HVA将会被设置成
KVM_HVA_ERR_BAD。kvm_is_error_hva或者(write_fault && !writable)代表两种错误:1)指令错误,向Guest注入指令异常;2)IO访问错误,IO访问又存在两种情况:2.1)Cache维护指令,则直接跳过该指令;2.2)正常的IO操作指令,调用io_mem_abort进行IO模拟操作; handle_access_fault用于处理访问权限问题,如果内存页无法访问,则对其权限进行更新;user_mem_abort,用于分配更多的内存,实际上就是完成Stage 2页表映射的建立,根据异常的IPA地址,已经对应的HVA,建立映射,细节的地方就不表了。
int kvm_handle_guest_abort(struct kvm_vcpu *vcpu, struct kvm_run *run)
{
unsigned long fault_status;
phys_addr_t fault_ipa;
struct kvm_memory_slot *memslot;
memslot = gfn_to_memslot(vcpu->kvm, gfn);
hva = gfn_to_hva_memslot_prot(memslot, gfn, &writable);
ret = user_mem_abort(vcpu, fault_ipa, memslot, hva, fault_status);
}
kvm_handle_guest_abort() -->
user_mem_abort()--> {
...
0. checks the vma->flags for the VM_PFNMAP.
1. Since VM_PFNMAP flag is not yet set so force_pte _is_ false;
2. gfn_to_pfn_prot() -->
__gfn_to_pfn_memslot() -->
fixup_user_fault() -->
handle_mm_fault()-->
__do_fault() -->
vma_mmio_fault() --> // vendor's mdev fault handler
remap_pfn_range()--> // Here sets the VM_PFNMAP
flag into vma->flags.
3. Now that force_pte is set to false in step-2),
will execute transparent_hugepage_adjust() func and
that lead to Oops [4].
}
内存初始化
memory_listener_register注册了listener,但是addressspace尚未初始化,本节就介绍下其初始化流程。从上节的configure_accelerator()函数往下走,会执行cpu_exec_init_all()函数, 该函数主要初始化了IO地址空间和系统地址空间。memory_map_init()函数初始化系统地址空间,有一个全局的MemoryRegion指针system_memory指向该区域的MemoryRegion结构
cpu_exec_init_all => memory_map_init 创建 system_memory("system") 和 system_io("io") 两个全局 MemoryRegion
=> address_space_init 初始化 address_space_memory("memory") 和 address_space_io("I/O") AddressSpace,并把 system_memory 和 system_io 作为 root
=> memory_region_transaction_commit 提交修改,引起地址空间的变化

static void memory_map_init(void)
{
/*为system_memory分配内存*/
system_memory = g_malloc(sizeof(*system_memory));
assert(ADDR_SPACE_BITS <= 64);
memory_region_init(system_memory, NULL, "system",
ADDR_SPACE_BITS == 64 ?
UINT64_MAX : (0x1ULL << ADDR_SPACE_BITS));
/*初始化全局的address_space_memory*/
address_space_init(&address_space_memory, system_memory, "memory");
system_io = g_malloc(sizeof(*system_io));
memory_region_init_io(system_io, NULL, &unassigned_io_ops, NULL, "io",
65536);
address_space_init(&address_space_io, system_io, "I/O");
memory_listener_register(&core_memory_listener, &address_space_memory);
if (tcg_enabled()) {
memory_listener_register(&tcg_memory_listener, &address_space_memory);
}
}

所以在函数起始,就对system_memory分配了内存,然后调用了memory_region_init函数对其进行初始化,其中size设置为整个地址空间:如果是64位就是2^64.接着调用了address_space_init函数对address_space_memory进行了初始化。
设备内存
MemoryRegionSection
在内存虚拟化中,一个重要的结构是 MemoryRegionSection ,这个结构通过函数 section_from_flat_range 可由 FlatRange 转换过来。

/**
* MemoryRegionSection: describes a fragment of a #MemoryRegion
*
* @mr: the region, or %NULL if empty
* @fv: the flat view of the address space the region is mapped in
* @offset_within_region: the beginning of the section, relative to @mr's start
* @size: the size of the section; will not exceed @mr's boundaries
* @offset_within_address_space: the address of the first byte of the section
* relative to the region's address space
* @readonly: writes to this section are ignored
*/
struct MemoryRegionSection {
MemoryRegion *mr; // 指向所属 MemoryRegion
FlatView *fv;
hwaddr offset_within_region; // 起始地址 (HVA) 在 MemoryRegion 内的偏移量
Int128 size;
hwaddr offset_within_address_space; // 在 AddressSpace 内的偏移量,如果该 AddressSpace 为系统内存,则为 GPA 起始地址
bool readonly;
};


hw/virtio/vhost.c
vhost_dev_init
hdev->memory_listener = (MemoryListener) {
.begin = vhost_begin,
.commit = vhost_commit,
.region_add = vhost_region_addnop,
.region_nop = vhost_region_addnop,
.log_start = vhost_log_start,
.log_stop = vhost_log_stop,
.log_sync = vhost_log_sync,
.log_global_start = vhost_log_global_start,
.log_global_stop = vhost_log_global_stop,
.eventfd_add = vhost_eventfd_add,
.eventfd_del = vhost_eventfd_del,
.priority = 10
vhost_dev_init --> memory_listener_register(&hdev->memory_listener, &address_space_memory);
├─memory_listener_register
└─listener_add_address_space
listener->region_add
└─ vhost_region_addnop
└─vhost_region_add_section

staticvoid listener_add_address_space(MemoryListener *listener, AddressSpace *as)
{
FlatView *view;
FlatRange *fr;
if (listener->begin) {
listener->begin(listener);
}
if (global_dirty_log) {
if (listener->log_global_start) {
listener->log_global_start(listener);
}
}
view = address_space_get_flatview(as);
FOR_EACH_FLAT_RANGE(fr, view) {
MemoryRegionSection section = section_from_flat_range(fr, view);
if (listener->region_add) {
listener->region_add(listener, §ion); //调用listener的region_add
}
if (fr->dirty_log_mask && listener->log_start) {
listener->log_start(listener, §ion, 0, fr->dirty_log_mask);
}
}
if (listener->commit) {
listener->commit(listener);
}
flatview_unref(view);
}


static void vhost_begin(MemoryListener *listener)
{
struct vhost_dev *dev = container_of(listener, struct vhost_dev,
memory_listener);
dev->tmp_sections = NULL;
dev->n_tmp_sections = 0;
}

struct vhost_dev {
MemoryListener memory_listener; /* MemoryListener是物理内存操作的回调函数集合 */
struct vhost_memory *mem;
int n_mem_sections;
MemoryRegionSection *mem_sections;
QEMU下的内存结构体很多了,RAMBlock,MemoryRegion,AddressSpace,MemoryRegionSection,KVMSlot和kvm_userspace_memory_region
vhost_commit

vhost_dev_init
├─vhost_virtqueue_init
| └─vhost_set_vring_call
└─memory_listener_register
└─listener_add_address_space
├─vhost_begin
├─vhost_log_global_start
| └─vhost_migration_log
| └─vhost_dev_set_log
| └─vhost_kernel_set_vring_add
├─vhost_log_start
├─vhost_region_addnop
| └─vhost_region_add_section
└─vhost_commit
└─vhost_kernel_set_mem_table(VHOST_SET_MEM_TABLE)
└─调用到内核vhost_set_memory
└─vhost_new_umem_range

vhost_commit处理

for (i = 0; i < dev->n_mem_sections; i++) {
struct vhost_memory_region *cur_vmr = dev->mem->regions + i;
struct MemoryRegionSection *mrs = dev->mem_sections + i;
cur_vmr->guest_phys_addr = mrs->offset_within_address_space;
cur_vmr->memory_size = int128_get64(mrs->size);
cur_vmr->userspace_addr =
(uintptr_t)memory_region_get_ram_ptr(mrs->mr) +
mrs->offset_within_region;
cur_vmr->flags_padding = 0;
}

linux kernel

vhost_dev_init
├─vhost_virtqueue_init
| └─vhost_set_vring_call
└─memory_listener_register
└─listener_add_address_space
├─vhost_begin
├─vhost_log_global_start
| └─vhost_migration_log
| └─vhost_dev_set_log
| └─vhost_kernel_set_vring_add
├─vhost_log_start
├─vhost_region_addnop
| └─vhost_region_add_section
└─vhost_commit
└─(VHOST_SET_MEM_TABLE) ----同步给内核
└─调用到内核vhost_set_memory
└─vhost_new_umem_range

hw/virtio/vhost-backend.c:99:static int vhost_kernel_set_mem_table(struct vhost_dev *dev,
hw/virtio/vhost-backend.c:304: .vhost_set_mem_table = vhost_kernel_set_mem_table,
hw/virtio/vhost-user.c:2362: .vhost_set_mem_table = vhost_user_set_mem_table, hw/virtio/vhost-vdpa.c:598: .vhost_set_mem_table = vhost_vdpa_set_mem_table, hw/virtio/vhost-backend.c:304: .vhost_set_mem_table = vhost_kernel_set_mem_table
static int vhost_kernel_set_mem_table(struct vhost_dev *dev,
struct vhost_memory *mem)
{
return vhost_kernel_call(dev, VHOST_SET_MEM_TABLE, mem);
}
kernel code

static long vhost_set_memory(struct vhost_dev *d, struct vhost_memory __user *m)
{
struct vhost_memory mem, *newmem, *oldmem;
unsigned long size = offsetof(struct vhost_memory, regions);
if (copy_from_user(&mem, m, size))
return -EFAULT;
if (mem.padding)
return -EOPNOTSUPP;
if (mem.nregions > VHOST_MEMORY_MAX_NREGIONS)
return -E2BIG;
newmem = kmalloc(size + mem.nregions * sizeof *m->regions, GFP_KERNEL);
if (!newmem)
return -ENOMEM;
memcpy(newmem, &mem, size);
if (copy_from_user(newmem->regions, m->regions,
mem.nregions * sizeof *m->regions)) {
kfree(newmem);
return -EFAULT;
}
if (!memory_access_ok(d, newmem,
vhost_has_feature(d, VHOST_F_LOG_ALL))) {
kfree(newmem);
return -EFAULT;
}
oldmem = rcu_dereference_protected(d->memory,
lockdep_is_held(&d->mutex));
rcu_assign_pointer(d->memory, newmem);
synchronize_rcu();
kfree(oldmem);
return 0;
}
long vhost_vring_ioctl(struct vhost_dev *d, int ioctl, void __user *argp)
{
struct file *eventfp, *filep = NULL;
bool pollstart = false, pollstop = false;
struct eventfd_ctx *ctx = NULL;
u32 __user *idxp = argp;
struct vhost_virtqueue *vq;
struct vhost_vring_state s;
struct vhost_vring_file f;
struct vhost_vring_addr a;
u32 idx;
long r;
r = get_user(idx, idxp);
if (r < 0)
return r;
if (idx >= d->nvqs)
return -ENOBUFS;
vq = d->vqs + idx;
mutex_lock(&vq->mutex);
switch (ioctl) {
case VHOST_SET_VRING_NUM:
/* Resizing ring with an active backend?
* You don't want to do that. */
if (vq->private_data) {
r = -EBUSY;
break;
}
if (copy_from_user(&s, argp, sizeof s)) {
r = -EFAULT;
break;
}
if (!s.num || s.num > 0xffff || (s.num & (s.num - 1))) {
r = -EINVAL;
break;
}
vq->num = s.num;
break;
case VHOST_SET_VRING_BASE:
/* Moving base with an active backend?
* You don't want to do that. */
if (vq->private_data) {
r = -EBUSY;
break;
}
if (copy_from_user(&s, argp, sizeof s)) {
r = -EFAULT;
break;
}
if (s.num > 0xffff) {
r = -EINVAL;
break;
}
vq->last_avail_idx = s.num;
/* Forget the cached index value. */
vq->avail_idx = vq->last_avail_idx;
break;
case VHOST_GET_VRING_BASE:
s.index = idx;
s.num = vq->last_avail_idx;
if (copy_to_user(argp, &s, sizeof s))
r = -EFAULT;
break;
case VHOST_SET_VRING_ADDR:
if (copy_from_user(&a, argp, sizeof a)) {
r = -EFAULT;
break;
}
if (a.flags & ~(0x1 << VHOST_VRING_F_LOG)) {
r = -EOPNOTSUPP;
break;
}
/* For 32bit, verify that the top 32bits of the user
data are set to zero. */
if ((u64)(unsigned long)a.desc_user_addr != a.desc_user_addr ||
(u64)(unsigned long)a.used_user_addr != a.used_user_addr ||
(u64)(unsigned long)a.avail_user_addr != a.avail_user_addr) {
r = -EFAULT;
break;
}
if ((a.avail_user_addr & (sizeof *vq->avail->ring - 1)) ||
(a.used_user_addr & (sizeof *vq->used->ring - 1)) ||
(a.log_guest_addr & (sizeof *vq->used->ring - 1))) {
r = -EINVAL;
break;
}
/* We only verify access here if backend is configured.
* If it is not, we don't as size might not have been setup.
* We will verify when backend is configured. */
if (vq->private_data) {
if (!vq_access_ok(d, vq->num,
(void __user *)(unsigned long)a.desc_user_addr,
(void __user *)(unsigned long)a.avail_user_addr,
(void __user *)(unsigned long)a.used_user_addr)) {
r = -EINVAL;
break;
}
/* Also validate log access for used ring if enabled. */
if ((a.flags & (0x1 << VHOST_VRING_F_LOG)) &&
!log_access_ok(vq->log_base, a.log_guest_addr,
sizeof *vq->used +
vq->num * sizeof *vq->used->ring)) {
r = -EINVAL;
break;
}
}
vq->log_used = !!(a.flags & (0x1 << VHOST_VRING_F_LOG));
vq->desc = (void __user *)(unsigned long)a.desc_user_addr;
vq->avail = (void __user *)(unsigned long)a.avail_user_addr;
vq->log_addr = a.log_guest_addr;
vq->used = (void __user *)(unsigned long)a.used_user_addr;
break;
case VHOST_SET_VRING_KICK:
if (copy_from_user(&f, argp, sizeof f)) {
r = -EFAULT;
break;
}
eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd);
if (IS_ERR(eventfp)) {
r = PTR_ERR(eventfp);
break;
}
if (eventfp != vq->kick) {
pollstop = (filep = vq->kick) != NULL;
pollstart = (vq->kick = eventfp) != NULL;
} else
filep = eventfp;
break;
case VHOST_SET_VRING_CALL:
if (copy_from_user(&f, argp, sizeof f)) {
r = -EFAULT;
break;
}
eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd);
if (IS_ERR(eventfp)) {
r = PTR_ERR(eventfp);
break;
}
if (eventfp != vq->call) {
filep = vq->call;
ctx = vq->call_ctx;
vq->call = eventfp;
vq->call_ctx = eventfp ?
eventfd_ctx_fileget(eventfp) : NULL;
} else
filep = eventfp;
break;
case VHOST_SET_VRING_ERR:
if (copy_from_user(&f, argp, sizeof f)) {
r = -EFAULT;
break;
}
eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd);
if (IS_ERR(eventfp)) {
r = PTR_ERR(eventfp);
break;
}
if (eventfp != vq->error) {
filep = vq->error;
vq->error = eventfp;
ctx = vq->error_ctx;
vq->error_ctx = eventfp ?
eventfd_ctx_fileget(eventfp) : NULL;
} else
filep = eventfp;
break;
default:
r = -ENOIOCTLCMD;
}
if (pollstop && vq->handle_kick)
vhost_poll_stop(&vq->poll);
if (ctx)
eventfd_ctx_put(ctx);
if (filep)
fput(filep);
if (pollstart && vq->handle_kick)
r = vhost_poll_start(&vq->poll, vq->kick);
mutex_unlock(&vq->mutex);
if (pollstop && vq->handle_kick)
vhost_poll_flush(&vq->poll);
return r;
}

vring
Guest、Host之间通过通过共享vring buffer的方式完成数据报文传递,相关数据结构如下,其中vring_virtqueue为Guest侧数据结构,vhost_virtqueue为Host侧数据结构;

struct vring_virtqueue
{
struct virtqueue vq;
/* Actual memory layout for this queue */
/*
包含desc、avail、used三个vring,其中desc用于存放描述符信息,avail用于表示当前可用的desc 的
head id,used用于描述当前已经使用的desc的head id
*/
struct vring vring;
};
struct vhost_virtqueue {
struct vhost_dev *dev;
/* The actual ring of buffers. */
struct mutex mutex;
unsigned int num;
/*
Qemu通过VHOST_SET_VRING_ADDR将Guest的三个vring地址通知给vhost,vhost填充到
vhost_virtqueue对应字段
*/
struct vring_desc __user *desc;
struct vring_avail __user *avail;
struct vring_used __user *used;
};


struct vring {
/* VRing的队列深度,表示一个VRing有多少个buffer */
unsigned int num;
/* 指向Descriptor Table */
struct vring_desc *desc;
/* 指向Avail Ring */
struct vring_avail *avail;
/* 指向Used Ring */
struct vring_used *used;
};

struct virtqueue {
struct list_head list;
void (*callback)(struct virtqueue *vq);
const char *name;
struct virtio_device *vdev;
unsigned int index;
unsigned int num_free;
void *priv;
};

qemu侧vring地址初始化
https://www.cnblogs.com/kvm-qemu/articles/8496594.html

guest把分配的vring地址传递给qemu
virtio_pci_common_write
└─virtio_queue_set_rings
└─virtio_init_region_cache
└─address_space_cache_init//这个函数等qemu内存虚拟化时一块分析

virtio_queue_set_rings 和virtio_queue_set_addr
static void virtio_pci_common_write(void *opaque, hwaddr addr,
uint64_t val, unsigned size)
case VIRTIO_PCI_COMMON_Q_ENABLE:
if (val == 1) {
virtio_queue_set_num(vdev, vdev->queue_sel,
proxy->vqs[vdev->queue_sel].num);
virtio_queue_set_rings(vdev, vdev->queue_sel,
((uint64_t)proxy->vqs[vdev->queue_sel].desc[1]) << 32 |
proxy->vqs[vdev->queue_sel].desc[0],
((uint64_t)proxy->vqs[vdev->queue_sel].avail[1]) << 32 |
proxy->vqs[vdev->queue_sel].avail[0],
((uint64_t)proxy->vqs[vdev->queue_sel].used[1]) << 32 |
proxy->vqs[vdev->queue_sel].used[0]);
proxy->vqs[vdev->queue_sel].enabled = 1;
}

QEMU-GUEST交互所有设备的i/o操作都经由virtio_ioport_write处理

QEMU-GUEST交互
所有设备的i/o操作都经由qemu virtio_ioport_write处理
static void virtio_ioport_write(void *opaque, uint32_t addr, uint32_t val){
.....
switch (addr) {
case VIRTIO_PCI_GUEST_FEATURES:
/* Guest does not negotiate properly? We have to assume nothing. */
if (val & (1 << VIRTIO_F_BAD_FEATURE)) {
val = virtio_bus_get_vdev_bad_features(&proxy->bus);
}
virtio_set_features(vdev, val);
break;
....
case VIRTIO_PCI_QUEUE_PFN: // addr = 8
pa = (hwaddr)val << VIRTIO_PCI_QUEUE_ADDR_SHIFT; // 描述符表物理地址
if (pa == 0) {
virtio_pci_reset(DEVICE(proxy));
}
else
virtio_queue_set_addr(vdev, vdev->queue_sel, pa); // 写入描述符表物理地址
break;
case VIRTIO_PCI_QUEUE_SEL: // addr = 14
if (val < VIRTIO_QUEUE_MAX)
vdev->queue_sel = val; // 更新Virtqueue handle_output 序号
break;
case VIRTIO_PCI_QUEUE_NOTIFY: // addr = 16
if (val < VIRTIO_QUEUE_MAX) {
virtio_queue_notify(vdev, val); //根据val序号 触发Virtqueue的描述符表
}
break;
}
}




void virtio_queue_set_rings(VirtIODevice *vdev, int n, hwaddr desc,
hwaddr avail, hwaddr used)
{
if (!vdev->vq[n].vring.num) {
return;
}
vdev->vq[n].vring.desc = desc;
vdev->vq[n].vring.avail = avail;
vdev->vq[n].vring.used = used;
virtio_init_region_cache(vdev, n);
}

hwaddr virtio_queue_get_desc_addr(VirtIODevice *vdev, int n)
{
return vdev->vq[n].vring.desc;
}

static void *vhost_memory_map(struct vhost_dev *dev, hwaddr addr,
hwaddr *plen, bool is_write)
{
if (!vhost_dev_has_iommu(dev)) {
return cpu_physical_memory_map(addr, plen, is_write);
} else {
return (void *)(uintptr_t)addr;
}
}
cpu_physical_memory_map() ->address_space_map() -> address_space_translate-> address_space_translate_internal函数完成gpa到hva的转换
Virtio-net数据结构
先了解一下普通的环形队列,它经常用于生产者/消费者的模型。比如virtio-net网卡recv流程中,网卡设备只管往ring中添加报文,而网卡驱动只需要从ring里不断的读取报文。如下图所示,通常来说我们只需要两个指针便能知道环形队列中的有效数据位置。

再来了解一下virtio网卡驱动的数据结构(virtio-net前端,在内核驱动代码中,数据结构如下图所示,注意,这是内核中的数据结构)。为了简单起见,我们不讨论它的原理,只说明用途。
VirtQueue是虚拟队列,用于描述队列的使用情况。Virtio网卡有一个读队列和一个写队列。
Vring是环形队列结构体:他用于记录缓冲区描述符、可用缓冲区描述符、已用缓冲区描述符的情况。
Vring->desc是一个结构体数组的首地址,其中每一个数组元素是一个描述缓冲区的结构体,也称为描述符数组。每个元素中都有一个next变量执行下一个元素。 其实desc是一个数组方式实现的环形队列的首地址。
Vring->avail成员变量是一个用于描述 desc中可用的描述符的结构。 Vring->used是描述已经使用的描述符。 (其实很多驱动中avail和used都简单的设计成两个指针,用于指向当前可用的描述符起始位置和已用的描述符起始位置。而virtio中他们被设计成了指针数组,这使得整个流程看起来很复杂。 指针数组这样的实现可以避免因为其中某一个描述符的处理阻塞而导致整个生产线阻塞的情况)

从上图看出如果要获取网卡队列缓冲区的地址,我们只需要知道虚拟机内核中的Vring结构体中的desc、avail这些值即可。在Qemu中也有VRing结构体,他们与内核中的Vring对应,实际上它是从内核中获取的。
通过sourceinsight references可以知道有两个函数可以设置QEMU中vring的desc、avail、used成员变量,分别是virtio_queue_set_rings和virtio_queue_set_addr。
virtio_queue_set_rings被virtio_pci_common_write调用,而virtio_pci_common_write是virtio_pci_modern_regions_init注册的IO内存区域的回调,它会在MMIO的处理流程address_space_rw中被调用到(MMIO简单说明:在CPU看来,所有的设备和内存都一样,都是一段地址空间。X86的物理地址空间和PCI地址空间是重叠的,他们通过PCI控制器隔离开来。CPU可以通过PIO和MMIO这两种方式来访问这些设备的寄存器。PIO是用IN、OUT这样的IO指令来访问这些寄存器;而MMIO则把PCI设备的寄存器地址DMA映射到一段物理内存中,这么一来CPU访问PCI寄存器就跟访问内存一样,而不需要IN、OUT这样的指令。PIO是使用IO、OUT这样的敏感指令,所以会从guest模式退出到root模式并被KVM模拟;但是MMIO是普通的内存访问指令,普通的内存存取是不会退出到root模式的。为了捕获并模拟MMIO,KVM不会为MMIO映射的内存建立页表,这样在MMIO的时候就会出现缺页异常而退出到KVM并被模拟)。
传给virtio_queue_set_rings的desc是proxy结构中的成员变量,他们是在virtio_pci_common_write函数中的VIRTIO_PCI_COMMON_Q_DESCLO、VIRTIO_PCI_COMMON_Q_DESCHI中被赋值的, 很显然他们也都是虚拟机中MMIO的时候被KVM截获到的。查看内核virtio-net驱动代码便明白了,desc是在virtio_pci_modern.c的setup_vq函数中写入的:
vp_iowrite64_twopart(virt_to_phys(info->queue), &cfg->queue_desc_lo, &cfg->queue_desc_hi);
setup_vq函数往queue_desc_lo和queue_desc_hi这两个寄存器映射的内存中写入了网卡缓冲区描述符结构体数组的地址info->queue,setup_vq函数中还用同样的方式写入了avail和used这两个寄存器(modern模式)。
简单的说就是虚拟机驱动中往virtio网卡的寄存器中写入了网卡缓冲区描述符的首地址,然后这个写入动作被KVM捕获并传给QEMU,这样QEMU就可以找到网卡缓冲区的地址(这个地址是虚拟机的物理地址,QEMU中使用它之前还需要进行转换)
struct vring {
/* VRing的队列深度,表示一个VRing有多少个buffer */
unsigned int num;
/* 指向Descriptor Table */
struct vring_desc *desc;
/* 指向Avail Ring */
struct vring_avail *avail;
/* 指向Used Ring */
struct vring_used *used;
};

guest 中设置vring的desc、avail、used成员变量,分别是 virtqueue_add_split
vm_find_vqs --> vm_setup_vq
|
| --> vring_create_virtqueue
|--> vring_init
|--> __vring_new_virtqueue
virtqueue_add_split
| --> dma_addr_t addr = vring_map_one_sg(vq, sg, DMA_TO_DEVICE)
| --> vq->split.vring.desc vq->split.vring.avail

将vring的地址传递给dpdk
a=virtio_queue_get_desc_addr(vdev, idx)获取desc的地址 vq->desc = vhost_memory_map(dev, a, &l, false);
vq->avail_phys = a = virtio_queue_get_avail_addr(vdev, idx);
vq->avail = vhost_memory_map(dev, a, &l, false);
vq->used_phys = a = virtio_queue_get_used_addr(vdev, idx);
vq->used = vhost_memory_map(dev, a, &l, true);
把vhost_virtqueue_set_addr(dev, vq, vhost_vq_index, dev->log_enabled)
vq->desc;
vq->avail;
vq->used;
地址告诉dpdk
dpdk收到消息后会对地址进行translate

VHOST_USER_SET_VRING_ADDR 消息
vhost_virtqueue_start
┣━━━ vhost_virtqueue_set_addr
┣━━━ dev->vhost_ops->vhost_set_vring_addr(vhost_user_set_vring_addr)
┣━━━vhost_user_write 发送VHOST_USER_SET_VRING_ADDR 消息
dpdk 处理 VHOST_USER_SET_VRING_ADDR 消息
vhost_user_set_vring_addr
┣━━━ translate_ring_addresses

static int vhost_virtqueue_start(struct vhost_dev *dev,
struct VirtIODevice *vdev,
struct vhost_virtqueue *vq,
unsigned idx)
{
hwaddr s, l, a;
int r;
int vhost_vq_index = dev->vhost_ops->vhost_get_vq_index(dev, idx);
struct vhost_vring_file file = {
.index = vhost_vq_index
};
struct vhost_vring_state state = {
.index = vhost_vq_index
};
struct VirtQueue *vvq = virtio_get_queue(vdev, idx);
a = virtio_queue_get_desc_addr(vdev, idx);
if (a == 0) {
/* Queue might not be ready for start */
return 0;
}
vq->num = state.num = virtio_queue_get_num(vdev, idx);
r = dev->vhost_ops->vhost_set_vring_num(dev, &state);
if (r) {
VHOST_OPS_DEBUG("vhost_set_vring_num failed");
return -errno;
}
state.num = virtio_queue_get_last_avail_idx(vdev, idx);
r = dev->vhost_ops->vhost_set_vring_base(dev, &state);
if (r) {
VHOST_OPS_DEBUG("vhost_set_vring_base failed");
return -errno;
}
if (vhost_needs_vring_endian(vdev)) {
r = vhost_virtqueue_set_vring_endian_legacy(dev,
virtio_is_big_endian(vdev),
vhost_vq_index);
if (r) {
return -errno;
}
}
vq->desc_size = s = l = virtio_queue_get_desc_size(vdev, idx);
vq->desc_phys = a;
vq->desc = vhost_memory_map(dev, a, &l, false);
vq->avail_size = s = l = virtio_queue_get_avail_size(vdev, idx);
vq->avail_phys = a = virtio_queue_get_avail_addr(vdev, idx);
vq->avail = vhost_memory_map(dev, a, &l, false);
vq->used_size = s = l = virtio_queue_get_used_size(vdev, idx);
vq->used_phys = a = virtio_queue_get_used_addr(vdev, idx);
vq->used = vhost_memory_map(dev, a, &l, true);
r = vhost_virtqueue_set_addr(dev, vq, vhost_vq_index, dev->log_enabled);
if (r < 0) {
r = -errno;
goto fail_alloc;
}
file.fd = event_notifier_get_fd(virtio_queue_get_host_notifier(vvq));
r = dev->vhost_ops->vhost_set_vring_kick(dev, &file);
if (r) {
VHOST_OPS_DEBUG("vhost_set_vring_kick failed");
r = -errno;
goto fail_kick;
}
/* Clear and discard previous events if any. */
event_notifier_test_and_clear(&vq->masked_notifier);
/* Init vring in unmasked state, unless guest_notifier_mask
* will do it later.
*/
if (!vdev->use_guest_notifier_mask) {
/* TODO: check and handle errors. */
vhost_virtqueue_mask(dev, vdev, idx, false);
}
if (k->query_guest_notifiers &&
k->query_guest_notifiers(qbus->parent) &&
virtio_queue_vector(vdev, idx) == VIRTIO_NO_VECTOR) {
file.fd = -1;
r = dev->vhost_ops->vhost_set_vring_call(dev, &file);
if (r) {
goto fail_vector;
}
}
return r;
}

vhost_memory_region

vhost的内存布局,也是由一组vhost_memory_region构成,
struct vhost_memory_region {
__u64 guest_phys_addr;
__u64 memory_size; /* bytes */
__u64 userspace_addr;
__u64 flags_padding; /* No flags are currently specified. */
};
/* All region addresses and sizes must be 4K aligned. */
#define VHOST_PAGE_SIZE 0x1000
struct vhost_memory {
__u32 nregions;
__u32 padding;
struct vhost_memory_region regions[0];


qemu侧 vhost_user_set_mem_table

static int vhost_user_set_mem_table(struct vhost_dev *dev,
struct vhost_memory *mem)
{
struct vhost_user *u = dev->opaque;
int fds[VHOST_MEMORY_BASELINE_NREGIONS];
size_t fd_num = 0;
bool do_postcopy = u->postcopy_listen && u->postcopy_fd.handler;
bool reply_supported = virtio_has_feature(dev->protocol_features,
VHOST_USER_PROTOCOL_F_REPLY_ACK);
bool config_mem_slots =
virtio_has_feature(dev->protocol_features,
VHOST_USER_PROTOCOL_F_CONFIGURE_MEM_SLOTS);
if (do_postcopy) {
/*
* Postcopy has enough differences that it's best done in it's own
* version
*/
return vhost_user_set_mem_table_postcopy(dev, mem, reply_supported,
config_mem_slots);
}
VhostUserMsg msg = {
.hdr.flags = VHOST_USER_VERSION,
};
if (reply_supported) {
msg.hdr.flags |= VHOST_USER_NEED_REPLY_MASK;
}
if (config_mem_slots) {
if (vhost_user_add_remove_regions(dev, &msg, reply_supported,
false) < 0) {
return -1;
}
} else {
if (vhost_user_fill_set_mem_table_msg(u, dev, &msg, fds, &fd_num,
false) < 0) {
return -1;
}
if (vhost_user_write(dev, &msg, fds, fd_num) < 0) {
return -1;
}
if (reply_supported) {
return process_message_reply(dev, &msg);
}
}
return 0;
}

static int vhost_user_fill_set_mem_table_msg(struct vhost_user *u,
struct vhost_dev *dev,
VhostUserMsg *msg,
int *fds, size_t *fd_num,
bool track_ramblocks)
{
int i, fd;
ram_addr_t offset;
MemoryRegion *mr;
struct vhost_memory_region *reg;
VhostUserMemoryRegion region_buffer;
msg->hdr.request = VHOST_USER_SET_MEM_TABLE;

static int vhost_user_set_mem_table_postcopy(struct vhost_dev *dev,
struct vhost_memory *mem,
bool reply_supported,
bool config_mem_slots)
{
struct vhost_user *u = dev->opaque;
int fds[VHOST_MEMORY_BASELINE_NREGIONS];
size_t fd_num = 0;
VhostUserMsg msg_reply;
int region_i, msg_i;
VhostUserMsg msg = {
.hdr.flags = VHOST_USER_VERSION,
};
if (u->region_rb_len < dev->mem->nregions) {
u->region_rb = g_renew(RAMBlock*, u->region_rb, dev->mem->nregions);
u->region_rb_offset = g_renew(ram_addr_t, u->region_rb_offset,
dev->mem->nregions);
memset(&(u->region_rb[u->region_rb_len]), '\0',
sizeof(RAMBlock *) * (dev->mem->nregions - u->region_rb_len));
memset(&(u->region_rb_offset[u->region_rb_len]), '\0',
sizeof(ram_addr_t) * (dev->mem->nregions - u->region_rb_len));
u->region_rb_len = dev->mem->nregions;
}
if (config_mem_slots) {
if (vhost_user_add_remove_regions(dev, &msg, reply_supported,
true) < 0) {
return -1;
}
} else {
if (vhost_user_fill_set_mem_table_msg(u, dev, &msg, fds, &fd_num,
true) < 0) {
return -1;
}
if (vhost_user_write(dev, &msg, fds, fd_num) < 0) {
return -1;
}
if (vhost_user_read(dev, &msg_reply) < 0) {
return -1;
}
if (msg_reply.hdr.request != VHOST_USER_SET_MEM_TABLE) {
error_report("%s: Received unexpected msg type."
"Expected %d received %d", __func__,
VHOST_USER_SET_MEM_TABLE, msg_reply.hdr.request);
return -1;
}
/*
* We're using the same structure, just reusing one of the
* fields, so it should be the same size.
*/
if (msg_reply.hdr.size != msg.hdr.size) {
error_report("%s: Unexpected size for postcopy reply "
"%d vs %d", __func__, msg_reply.hdr.size,
msg.hdr.size);
return -1;
}
memset(u->postcopy_client_bases, 0,
sizeof(uint64_t) * VHOST_USER_MAX_RAM_SLOTS);
/*
* They're in the same order as the regions that were sent
* but some of the regions were skipped (above) if they
* didn't have fd's
*/
for (msg_i = 0, region_i = 0;
region_i < dev->mem->nregions;
region_i++) {
if (msg_i < fd_num &&
msg_reply.payload.memory.regions[msg_i].guest_phys_addr ==
dev->mem->regions[region_i].guest_phys_addr) {
u->postcopy_client_bases[region_i] =
msg_reply.payload.memory.regions[msg_i].userspace_addr;
trace_vhost_user_set_mem_table_postcopy(
msg_reply.payload.memory.regions[msg_i].userspace_addr,
msg.payload.memory.regions[msg_i].userspace_addr,
msg_i, region_i);
msg_i++;
}
}
if (msg_i != fd_num) {
error_report("%s: postcopy reply not fully consumed "
"%d vs %zd",
__func__, msg_i, fd_num);
return -1;
}
/*
* Now we've registered this with the postcopy code, we ack to the
* client, because now we're in the position to be able to deal
* with any faults it generates.
*/
/* TODO: Use this for failure cases as well with a bad value. */
msg.hdr.size = sizeof(msg.payload.u64);
msg.payload.u64 = 0; /* OK */
if (vhost_user_write(dev, &msg, NULL, 0) < 0) {
return -1;
}
}
return 0;
}
static int vhost_user_set_mem_table(struct vhost_dev *dev,
struct vhost_memory *mem)
{
struct vhost_user *u = dev->opaque;
int fds[VHOST_MEMORY_BASELINE_NREGIONS];
size_t fd_num = 0;
bool do_postcopy = u->postcopy_listen && u->postcopy_fd.handler;
bool reply_supported = virtio_has_feature(dev->protocol_features,
VHOST_USER_PROTOCOL_F_REPLY_ACK);
bool config_mem_slots =
virtio_has_feature(dev->protocol_features,
VHOST_USER_PROTOCOL_F_CONFIGURE_MEM_SLOTS);
if (do_postcopy) {
/*
* Postcopy has enough differences that it's best done in it's own
* version
*/
return vhost_user_set_mem_table_postcopy(dev, mem, reply_supported,
config_mem_slots);
}
dpdk vhost_user_set_mem_table
设置vhost_memory

2020-12-23T01:58:41.653Z|00029|dpdk|INFO|VHOST_CONFIG: read message VHOST_USER_SET_MEM_TABLE
2020-12-23T01:58:41.654Z|00030|dpdk|INFO|VHOST_CONFIG: guest memory region 0, size: 0x80000000
guest physical addr: 0x40000000
guest virtual addr: 0xffff00000000
host virtual addr: 0x400000000000
mmap addr : 0x400000000000
mmap size : 0x80000000
mmap align: 0x20000000
mmap off : 0x0
https://www.cnblogs.com/yi-mu-xi/p/12510775.html

/*对应qemu端的region结构*/
typedef struct VhostUserMemoryRegion {
uint64_t guest_phys_addr;//GPA of region
uint64_t memory_size; //size
uint64_t userspace_addr;//HVA in qemu process
uint64_t mmap_offset; //offset
} VhostUserMemoryRegion;
typedef struct VhostUserMemory {
uint32_t nregions;//region num
uint32_t padding;
VhostUserMemoryRegion regions[VHOST_MEMORY_MAX_NREGIONS];//All region
} VhostUserMemory;

lib/librte_vhost/vhost_user.h
dpdk

typedef struct VhostUserMemoryRegion {
uint64_t guest_phys_addr;
uint64_t memory_size;
uint64_t userspace_addr;
uint64_t mmap_offset;
} VhostUserMemoryRegion;
typedef struct VhostUserMemory {
uint32_t nregions;
uint32_t padding;
VhostUserMemoryRegion regions[VHOST_MEMORY_MAX_NREGIONS];
} VhostUserMemory;


struct rte_vhost_mem_region {
uint64_t guest_phys_addr;//GPA of region
uint64_t guest_user_addr;//HVA in qemu process
uint64_t host_user_addr;//HVA in vhost-user
uint64_t size;//size
void *mmap_addr;//mmap base Address
uint64_t mmap_size;
int fd;//relative fd of region
};

在virtio_net结构中保存有指向当前连接对应的memory结构rte_vhost_memory
1 struct rte_vhost_memory {
2 uint32_t nregions;
3 struct rte_vhost_mem_region regions[];
4 };
qemu侧

vhost_commit
└─for (i = 0; i < dev->n_mem_sections; i++) {
struct vhost_memory_region *cur_vmr = dev->mem->regions + i;
struct MemoryRegionSection *mrs = dev->mem_sections + i;
cur_vmr->guest_phys_addr = mrs->offset_within_address_space;
cur_vmr->memory_size = int128_get64(mrs->size);
cur_vmr->userspace_addr =
(uintptr_t)memory_region_get_ram_ptr(mrs->mr) +
mrs->offset_within_region;
cur_vmr->flags_padding = 0;
}
└─vhost_user_set_mem_table(VHOST_SET_MEM_TABLE)
dpdk核心部分 :


1 dev->mem = rte_zmalloc("vhost-mem-table", sizeof(struct rte_vhost_memory) +
2 sizeof(struct rte_vhost_mem_region) * memory.nregions, 0);
3 if (dev->mem == NULL) {
4 RTE_LOG(ERR, VHOST_CONFIG,
5 "(%d) failed to allocate memory for dev->mem\n",
6 dev->vid);
7 return -1;
8 }
9 /*region num*/
10 dev->mem->nregions = memory.nregions;
11
12 for (i = 0; i < memory.nregions; i++) {
13 /*fd info*/
14 fd = msg->fds[i];//qemu进程中的文件描述符??
15 reg = &dev->mem->regions[i];
16 /*GPA of specific region*/
17 reg->guest_phys_addr = memory.regions[i].guest_phys_addr;
18 /*HVA in qemu address*/
19 reg->guest_user_addr = memory.regions[i].userspace_addr;//该region在qemu进程中的虚拟地址
20 reg->size = memory.regions[i].memory_size;
21 reg->fd = fd;
22 /*offset in region*/
23 mmap_offset = memory.regions[i].mmap_offset;
24 mmap_size = reg->size + mmap_offset;
25
26 /* mmap() without flag of MAP_ANONYMOUS, should be called
27 * with length argument aligned with hugepagesz at older
28 * longterm version Linux, like 2.6.32 and 3.2.72, or
29 * mmap() will fail with EINVAL.
30 *
31 * to avoid failure, make sure in caller to keep length
32 * aligned.
33 */
34 alignment = get_blk_size(fd);
35 if (alignment == (uint64_t)-1) {
36 RTE_LOG(ERR, VHOST_CONFIG,
37 "couldn't get hugepage size through fstat\n");
38 goto err_mmap;
39 }
40 /*对齐*/
41 mmap_size = RTE_ALIGN_CEIL(mmap_size, alignment);
42 /*执行映射,这里就是本进程的虚拟地址了,为何能映射另一个进程的文件描述符呢?*/
43 mmap_addr = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE,
44 MAP_SHARED | MAP_POPULATE, fd, 0);
45
46 if (mmap_addr == MAP_FAILED) {
47 RTE_LOG(ERR, VHOST_CONFIG,
48 "mmap region %u failed.\n", i);
49 goto err_mmap;
50 }
51
52 reg->mmap_addr = mmap_addr;
53 reg->mmap_size = mmap_size;
54 /*region Address in vhost process*/
55 reg->host_user_addr = (uint64_t)(uintptr_t)mmap_addr +
56 mmap_offset;//该region在vhost进程中的虚拟地址
57
58 if (dev->dequeue_zero_copy)
59 add_guest_pages(dev, reg, alignment);
60
61
62 }

首先就是为dev分配mem空间,由此我们也可以得到该结构的布局

下面一个for循环对每个region先进行对应信息的复制,然后对该region的大小进行对其操作,接着通过mmap的方式对region关联的fd进行映射,这里便得到了region在vhost端的虚拟地址,但是region中GPA对应的虚拟地址还需要在mmap得到的虚拟地址上加上offset,该值也是作为参数传递进来的。到此,设置memory Table的工作基本完成,看下地址翻译过程呢?


1 /* Converts QEMU virtual address to Vhost virtual address. */
2 static uint64_t
3 qva_to_vva(struct virtio_net *dev, uint64_t qva)
4 {
5 struct rte_vhost_mem_region *reg;
6 uint32_t i;
7
8 /* Find the region where the address lives. */
9 for (i = 0; i < dev->mem->nregions; i++) {
10 reg = &dev->mem->regions[i];
11
12 if (qva >= reg->guest_user_addr &&
13 qva < reg->guest_user_addr + reg->size) {
14 return qva - reg->guest_user_addr +
15 reg->host_user_addr;//qva在所属region中的偏移,qva - reg->guest_user_addr
16 }
17 }
18
19 return 0;
20 }

相当简单把,核心思想是先使用QVA确定在哪一个region,然后取地址在region中的偏移,加上该region在vhost-user映射的实际有效地址即reg->host_user_addr字段。这部分还有一个核心思想是fd的使用,vhost_user_set_mem_table直接从MSG中获取到了fd,然后直接把FD进行mmap映射,这点一时间让我难以理解,FD不是仅仅在进程内部有效么?怎么也可以共享了??通过向开源社区请教,感叹自己的知识面实在狭窄,这是Unix下一种通用的传递描述符的方式,怎么说呢?就是进程A的描述符可以通过特定的调用传递给进程B,进程B在自己的描述符表中分配一个位置给该描述符指针,因此实际上进程B使用的并不是A的FD,而是自己描述符表中的FD,但是两个进程的FD却指向同一个描述符表,就像是增加了一个引用而已。后面会专门对该机制进行详解,本文仅仅了解该作用即可。

static int
vhost_user_set_mem_table(struct virtio_net **pdev, struct VhostUserMsg *msg,
int main_fd)
{
struct virtio_net *dev = *pdev;
struct VhostUserMemory *memory = &msg->payload.memory;
struct rte_vhost_mem_region *reg;
void *mmap_addr;
uint64_t mmap_size;
uint64_t mmap_offset;
uint64_t alignment;
uint32_t i;
int populate;
int fd;
if (memory->nregions > VHOST_MEMORY_MAX_NREGIONS) {
RTE_LOG(ERR, VHOST_CONFIG,
"too many memory regions (%u)\n", memory->nregions);
return VH_RESULT_ERR;
}
if (dev->mem && !vhost_memory_changed(memory, dev->mem)) {
RTE_LOG(INFO, VHOST_CONFIG,
"(%d) memory regions not changed\n", dev->vid);
for (i = 0; i < memory->nregions; i++)
close(msg->fds[i]);
return VH_RESULT_OK;
}
if (dev->mem) {
free_mem_region(dev);
rte_free(dev->mem);
dev->mem = NULL;
}
/* Flush IOTLB cache as previous HVAs are now invalid */
if (dev->features & (1ULL << VIRTIO_F_IOMMU_PLATFORM))
for (i = 0; i < dev->nr_vring; i++)
vhost_user_iotlb_flush_all(dev->virtqueue[i]);
dev->nr_guest_pages = 0;
if (!dev->guest_pages) {
dev->max_guest_pages = 8;
dev->guest_pages = malloc(dev->max_guest_pages *
sizeof(struct guest_page));
if (dev->guest_pages == NULL) {
RTE_LOG(ERR, VHOST_CONFIG,
"(%d) failed to allocate memory "
"for dev->guest_pages\n",
dev->vid);
return VH_RESULT_ERR;
}
}
dev->mem = rte_zmalloc("vhost-mem-table", sizeof(struct rte_vhost_memory) +
sizeof(struct rte_vhost_mem_region) * memory->nregions, 0);
if (dev->mem == NULL) {
RTE_LOG(ERR, VHOST_CONFIG,
"(%d) failed to allocate memory for dev->mem\n",
dev->vid);
return VH_RESULT_ERR;
}
dev->mem->nregions = memory->nregions;
for (i = 0; i < memory->nregions; i++) {
fd = msg->fds[i];
reg = &dev->mem->regions[i];
//quest_phys_addr和guest_user_addr 虚拟机确定,host_user_addr由dpdk执行mmap确定
reg->guest_phys_addr = memory->regions[i].guest_phys_addr;
reg->guest_user_addr = memory->regions[i].userspace_addr;
reg->size = memory->regions[i].memory_size;
reg->fd = fd;
mmap_offset = memory->regions[i].mmap_offset;
/* Check for memory_size + mmap_offset overflow */
if (mmap_offset >= -reg->size) {
RTE_LOG(ERR, VHOST_CONFIG,
"mmap_offset (%#"PRIx64") and memory_size "
"(%#"PRIx64") overflow\n",
mmap_offset, reg->size);
goto err_mmap;
}
mmap_size = reg->size + mmap_offset;
/* mmap() without flag of MAP_ANONYMOUS, should be called
* with length argument aligned with hugepagesz at older
* longterm version Linux, like 2.6.32 and 3.2.72, or
* mmap() will fail with EINVAL.
*
* to avoid failure, make sure in caller to keep length
* aligned.
*/
alignment = get_blk_size(fd);
if (alignment == (uint64_t)-1) {
RTE_LOG(ERR, VHOST_CONFIG,
"couldn't get hugepage size through fstat\n");
goto err_mmap;
}
mmap_size = RTE_ALIGN_CEIL(mmap_size, alignment);
populate = (dev->dequeue_zero_copy) ? MAP_POPULATE : 0;
mmap_addr = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE,
MAP_SHARED | populate, fd, 0);
if (mmap_addr == MAP_FAILED) {
RTE_LOG(ERR, VHOST_CONFIG,
"mmap region %u failed.\n", i);
goto err_mmap;
}
reg->mmap_addr = mmap_addr;
reg->mmap_size = mmap_size;
reg->host_user_addr = (uint64_t)(uintptr_t)mmap_addr +
mmap_offset;
if (dev->dequeue_zero_copy)
if (add_guest_pages(dev, reg, alignment) < 0) { // 添加
RTE_LOG(ERR, VHOST_CONFIG,
"adding guest pages to region %u failed.\n",
i);
goto err_mmap;
}
RTE_LOG(INFO, VHOST_CONFIG,
"guest memory region %u, size: 0x%" PRIx64 "\n"
"\t guest physical addr: 0x%" PRIx64 "\n"
"\t guest virtual addr: 0x%" PRIx64 "\n"
"\t host virtual addr: 0x%" PRIx64 "\n"
"\t mmap addr : 0x%" PRIx64 "\n"
"\t mmap size : 0x%" PRIx64 "\n"
"\t mmap align: 0x%" PRIx64 "\n"
"\t mmap off : 0x%" PRIx64 "\n",
i, reg->size,
reg->guest_phys_addr,
reg->guest_user_addr,
reg->host_user_addr,
(uint64_t)(uintptr_t)mmap_addr,
mmap_size,
alignment,
mmap_offset);
if (dev->postcopy_listening) {
/*
* We haven't a better way right now than sharing
* DPDK's virtual address with Qemu, so that Qemu can
* retrieve the region offset when handling userfaults.
*/
memory->regions[i].userspace_addr =
reg->host_user_addr;
}
}
if (dev->postcopy_listening) {
/* Send the addresses back to qemu */
msg->fd_num = 0;
send_vhost_reply(main_fd, msg);
/* Wait for qemu to acknolwedge it's got the addresses
* we've got to wait before we're allowed to generate faults.
*/
VhostUserMsg ack_msg;
if (read_vhost_message(main_fd, &ack_msg) <= 0) {
RTE_LOG(ERR, VHOST_CONFIG,
"Failed to read qemu ack on postcopy set-mem-table\n");
goto err_mmap;
}
if (ack_msg.request.master != VHOST_USER_SET_MEM_TABLE) {
RTE_LOG(ERR, VHOST_CONFIG,
"Bad qemu ack on postcopy set-mem-table (%d)\n",
ack_msg.request.master);
goto err_mmap;
}
/* Now userfault register and we can use the memory */
for (i = 0; i < memory->nregions; i++) {
#ifdef RTE_LIBRTE_VHOST_POSTCOPY
reg = &dev->mem->regions[i];
struct uffdio_register reg_struct;
/*
* Let's register all the mmap'ed area to ensure
* alignment on page boundary.
*/
reg_struct.range.start =
(uint64_t)(uintptr_t)reg->mmap_addr;
reg_struct.range.len = reg->mmap_size;
reg_struct.mode = UFFDIO_REGISTER_MODE_MISSING;
if (ioctl(dev->postcopy_ufd, UFFDIO_REGISTER,
®_struct)) {
RTE_LOG(ERR, VHOST_CONFIG,
"Failed to register ufd for region %d: (ufd = %d) %s\n",
i, dev->postcopy_ufd,
strerror(errno));
goto err_mmap;
}
RTE_LOG(INFO, VHOST_CONFIG,
"\t userfaultfd registered for range : %llx - %llx\n",
reg_struct.range.start,
reg_struct.range.start +
reg_struct.range.len - 1);
#else
goto err_mmap;
#endif
}
}
for (i = 0; i < dev->nr_vring; i++) {
struct vhost_virtqueue *vq = dev->virtqueue[i];
if (vq->desc || vq->avail || vq->used) {
/*
* If the memory table got updated, the ring addresses
* need to be translated again as virtual addresses have
* changed.
*/
vring_invalidate(dev, vq);
dev = translate_ring_addresses(dev, i);
if (!dev) {
dev = *pdev;
goto err_mmap;
}
*pdev = dev;
}
}
dump_guest_pages(dev);
return VH_RESULT_OK;
err_mmap:
free_mem_region(dev);
rte_free(dev->mem);
dev->mem = NULL;
return VH_RESULT_ERR;
}

vhost_memory_region用来tx的时候Convert guest physical address to host physical address
copy_desc_to_mbuf会调用gpa_to_hpa
virtio_dev_tx_split -->copy_desc_to_mbuf-->gpa_to_hpa
virtio_dev_tx_single_packed_zmbuf-->vhost_dequeue_single_packed-->copy_desc_to_mbuf-->gpa_to_hpa
rx的时候
virtio_dev_rx--> virtio_dev_rx_split --> reserve_avail_buf_split --> fill_vec_buf_split -->vhost_iova_to_vva 不要调用gpa_to_hpa

Breakpoint 1, virtio_dev_tx_split (dev=0x423fffba00, vq=0x423ffcf000, mbuf_pool=0x13f9aac00, pkts=0xffffbd40cea0, count=1) at /data1/dpdk-19.11/lib/librte_vhost/virtio_net.c:1795 1795 vhost_vring_call_split(dev, vq); Missing separate debuginfos, use: debuginfo-install libgcc-4.8.5-44.el7.aarch64 (gdb) bt #0 virtio_dev_tx_split (dev=0x423fffba00, vq=0x423ffcf000, mbuf_pool=0x13f9aac00, pkts=0xffffbd40cea0, count=1) at /data1/dpdk-19.11/lib/librte_vhost/virtio_net.c:1795 #1 0x000000000052312c in rte_vhost_dequeue_burst (vid=0, queue_id=1, mbuf_pool=0x13f9aac00, pkts=0xffffbd40cea0, count=32) at /data1/dpdk-19.11/lib/librte_vhost/virtio_net.c:2255 #2 0x00000000004822b0 in learning_switch_main (arg=<optimized out>) at /data1/ovs/LearningSwitch-DPDK/main.c:503 #3 0x0000000000585fb4 in eal_thread_loop (arg=0x0) at /data1/dpdk-19.11/lib/librte_eal/linux/eal/eal_thread.c:153 #4 0x0000ffffbe617d38 in start_thread (arg=0xffffbd40d910) at pthread_create.c:309 #5 0x0000ffffbe55f5f0 in thread_start () at ../sysdeps/unix/sysv/linux/aarch64/clone.S:91


/* Convert guest physical address to host physical address */
static __rte_always_inline rte_iova_t
gpa_to_hpa(struct virtio_net *dev, uint64_t gpa, uint64_t size)
{
uint32_t i;
struct guest_page *page;
for (i = 0; i < dev->nr_guest_pages; i++) {
page = &dev->guest_pages[i];
if (gpa >= page->guest_phys_addr &&
gpa + size < page->guest_phys_addr + page->size) {
return gpa - page->guest_phys_addr +
page->host_phys_addr;
}
}
return 0;
}

地址转换vhost_iova_to_vva
virtio_dev_rx--> virtio_dev_rx_split --> reserve_avail_buf_split --> fill_vec_buf_split -->vhost_iova_to_vva

static __rte_always_inline int
fill_vec_buf_split(struct virtio_net *dev, struct vhost_virtqueue *vq,
uint32_t avail_idx, uint16_t *vec_idx,
struct buf_vector *buf_vec, uint16_t *desc_chain_head,
uint32_t *desc_chain_len, uint8_t perm)
{
uint16_t idx = vq->avail->ring[avail_idx & (vq->size - 1)];
uint16_t vec_id = *vec_idx;
uint32_t len = 0;
uint64_t dlen;
uint32_t nr_descs = vq->size;
uint32_t cnt = 0;
struct vring_desc *descs = vq->desc;
struct vring_desc *idesc = NULL;
if (unlikely(idx >= vq->size)) //
return -1;
*desc_chain_head = idx;
if (vq->desc[idx].flags & VRING_DESC_F_INDIRECT) {
dlen = vq->desc[idx].len;
nr_descs = dlen / sizeof(struct vring_desc);
if (unlikely(nr_descs > vq->size))
return -1;
descs = (struct vring_desc *)(uintptr_t)
vhost_iova_to_vva(dev, vq, vq->desc[idx].addr,
&dlen,
VHOST_ACCESS_RO);
if (unlikely(!descs))
return -1;
if (unlikely(dlen < vq->desc[idx].len)) {
/*
* The indirect desc table is not contiguous
* in process VA space, we have to copy it.
*/
idesc = vhost_alloc_copy_ind_table(dev, vq,
vq->desc[idx].addr, vq->desc[idx].len);
if (unlikely(!idesc))
return -1;
descs = idesc;
}
idx = 0;
}
while (1) {
if (unlikely(idx >= nr_descs || cnt++ >= nr_descs)) {
free_ind_table(idesc);
return -1;
}
len += descs[idx].len;
if (unlikely(map_one_desc(dev, vq, buf_vec, &vec_id,
descs[idx].addr, descs[idx].len,
perm))) {
free_ind_table(idesc);
return -1;
}
if ((descs[idx].flags & VRING_DESC_F_NEXT) == 0)
break;
idx = descs[idx].next;
}
*desc_chain_len = len;
*vec_idx = vec_id;
if (unlikely(!!idesc))
free_ind_table(idesc);
return 0;
}
static __rte_always_inline int
map_one_desc(struct virtio_net *dev, struct vhost_virtqueue *vq,
struct buf_vector *buf_vec, uint16_t *vec_idx,
uint64_t desc_iova, uint64_t desc_len, uint8_t perm)
{
uint16_t vec_id = *vec_idx;
while (desc_len) {
uint64_t desc_addr;
uint64_t desc_chunck_len = desc_len;
if (unlikely(vec_id >= BUF_VECTOR_MAX))
return -1;
desc_addr = vhost_iova_to_vva(dev, vq,
desc_iova,
&desc_chunck_len,
perm);
if (unlikely(!desc_addr))
return -1;
rte_prefetch0((void *)(uintptr_t)desc_addr);
buf_vec[vec_id].buf_iova = desc_iova;
buf_vec[vec_id].buf_addr = desc_addr;
buf_vec[vec_id].buf_len = desc_chunck_len;
desc_len -= desc_chunck_len;
desc_iova += desc_chunck_len;
vec_id++;
}
*vec_idx = vec_id;
return 0;
}

vhost_user_set_vring_num

/*
* The virtio device sends us the size of the descriptor ring.
*/
static int
vhost_user_set_vring_num(struct virtio_net **pdev,
struct VhostUserMsg *msg,
int main_fd __rte_unused)
{
struct virtio_net *dev = *pdev;
struct vhost_virtqueue *vq = dev->virtqueue[msg->payload.state.index];
if (validate_msg_fds(msg, 0) != 0)
return RTE_VHOST_MSG_RESULT_ERR;
vq->size = msg->payload.state.num;

QEMU中需要有函数通过UNIX套接口发送内存地址信息到DPDK中。

static int vhost_virtqueue_set_addr(struct vhost_dev *dev,
struct vhost_virtqueue *vq,
unsigned idx, bool enable_log)
{
struct vhost_vring_addr addr; //addr怎么构造
int r;
memset(&addr, 0, sizeof(struct vhost_vring_addr));
if (dev->vhost_ops->vhost_vq_get_addr) {
r = dev->vhost_ops->vhost_vq_get_addr(dev, &addr, vq);
if (r < 0) {
VHOST_OPS_DEBUG("vhost_vq_get_addr failed");
return -errno;
}
} else {
addr.desc_user_addr = (uint64_t)(unsigned long)vq->desc;
addr.avail_user_addr = (uint64_t)(unsigned long)vq->avail;
addr.used_user_addr = (uint64_t)(unsigned long)vq->used;
}
addr.index = idx;
addr.log_guest_addr = vq->used_phys;
addr.flags = enable_log ? (1 << VHOST_VRING_F_LOG) : 0;
r = dev->vhost_ops->vhost_set_vring_addr(dev, &addr);
if (r < 0) {
VHOST_OPS_DEBUG("vhost_set_vring_addr failed");
return -errno;
}
return 0;
}


static int vhost_user_set_vring_addr(struct vhost_dev *dev,
struct vhost_vring_addr *addr)
{
VhostUserMsg msg = {
.hdr.request = VHOST_USER_SET_VRING_ADDR, //通知dpdk
.hdr.flags = VHOST_USER_VERSION,
.payload.addr = *addr,
.hdr.size = sizeof(msg.payload.addr),
};
if (vhost_user_write(dev, &msg, NULL, 0) < 0) {
return -1;
}
return 0;
}

实际上,QEMU中有一个与DPDK的消息处理函数类型的处理函数。
qemu-3.0.0/contrib/libvhost-user/libvhost-user.c

1218 static bool
1219 vu_process_message(VuDev *dev, VhostUserMsg *vmsg)
1220 {
(...)
1244 switch (vmsg->request) {
(...)
1265 case VHOST_USER_SET_VRING_ADDR:
1266 return vu_set_vring_addr_exec(dev, vmsg);
virtio告知DPDK共享内存的virtio queues内存地址
DPDK使用函数vhost_user_set_vring_addr将virtio的描述符、已用环和可用环地址转化为DPDK自身的地址空间。
/*
* The virtio device sends us the desc, used and avail ring addresses.
* This function then converts these to our address space.
*/
static int
vhost_user_set_vring_addr(struct virtio_net **pdev, struct VhostUserMsg *msg,
int main_fd __rte_unused)
{
struct virtio_net *dev = *pdev;
struct vhost_virtqueue *vq;
struct vhost_vring_addr *addr = &msg->payload.addr;
bool access_ok;
if (validate_msg_fds(msg, 0) != 0)
return RTE_VHOST_MSG_RESULT_ERR;
if (dev->mem == NULL)
return RTE_VHOST_MSG_RESULT_ERR;
/* addr->index refers to the queue index. The txq 1, rxq is 0. */
vq = dev->virtqueue[msg->payload.addr.index];
access_ok = vq->access_ok;
/*
* Rings addresses should not be interpreted as long as the ring is not
* started and enabled
*/
memcpy(&vq->ring_addrs, addr, sizeof(*addr));
vring_invalidate(dev, vq);
if ((vq->enabled && (dev->features &
(1ULL << VHOST_USER_F_PROTOCOL_FEATURES))) ||
access_ok) {
dev = translate_ring_addresses(dev, msg->payload.addr.index);
if (!dev)
return RTE_VHOST_MSG_RESULT_ERR;
*pdev = dev;
}
return RTE_VHOST_MSG_RESULT_OK;
}

translate_ring_addresses &ring_addr_to_vva

translate_ring_addresses(struct virtio_net *dev, int vq_index)
{
struct vhost_virtqueue *vq = dev->virtqueue[vq_index];
struct vhost_vring_addr *addr = &vq->ring_addrs;
uint64_t len;
/* The addresses are converted from QEMU virtual to Vhost virtual. */
if (vq->desc && vq->avail && vq->used)
return dev;
len = sizeof(struct vring_desc) * vq->size;
vq->desc = (struct vring_desc *)(uintptr_t)ring_addr_to_vva(dev,
vq, addr->desc_user_addr, &len);
if (vq->desc == 0 || len != sizeof(struct vring_desc) * vq->size) {
RTE_LOG(DEBUG, VHOST_CONFIG,
"(%d) failed to map desc ring.\n",
dev->vid);
return dev;
}
dev = numa_realloc(dev, vq_index);
vq = dev->virtqueue[vq_index];
addr = &vq->ring_addrs;
len = sizeof(struct vring_avail) + sizeof(uint16_t) * vq->size;
vq->avail = (struct vring_avail *)(uintptr_t)ring_addr_to_vva(dev,
vq, addr->avail_user_addr, &len);
if (vq->avail == 0 ||
len != sizeof(struct vring_avail) +
sizeof(uint16_t) * vq->size) {
RTE_LOG(DEBUG, VHOST_CONFIG,
"(%d) failed to map avail ring.\n",
dev->vid);
return dev;
}
len = sizeof(struct vring_used) +
sizeof(struct vring_used_elem) * vq->size;
vq->used = (struct vring_used *)(uintptr_t)ring_addr_to_vva(dev,
vq, addr->used_user_addr, &len);
return dev;
}

总结
memory_region_get_ram_ptr
kvm_set_phys_mem
kvm_set_phys_mem
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + delta;
kvm_set_user_memory_region(kml, mem);同步给内核
vhost_memory_region

vhost_region_add_section
uint64_t prev_host_start =
(uintptr_t)memory_region_get_ram_ptr(prev_sec->mr) +
prev_sec->offset_within_region;
vhost_dev_init
for (i = 0; i < dev->n_mem_sections; i++) {
struct vhost_memory_region *cur_vmr = dev->mem->regions + i;
struct MemoryRegionSection *mrs = dev->mem_sections + i;
cur_vmr->guest_phys_addr = mrs->offset_within_address_space;
cur_vmr->memory_size = int128_get64(mrs->size);
cur_vmr->userspace_addr =
(uintptr_t)memory_region_get_ram_ptr(mrs->mr) +
mrs->offset_within_region;
cur_vmr->flags_padding = 0;
}
vhost_kernel_set_mem_table 同步给内核

guest notify -->VM-exit
具体通知方式:
前面已经提到前端或者后端完成某个操作需要通知另一端的时候需要某种notify机制。这个notify机制是啥呢?这里分为两个方向
1、guest->host
前面也已经介绍,当前端想通知后端时,会调用virtqueue_kick函数,继而调用virtqueue_notify,对应virtqueue结构中的notify函数,在初始化的时候被初始化成vp_notify(virtio_pci.c中),看下该函数的实现

static void vp_notify(struct virtqueue *vq)
{
struct virtio_pci_device *vp_dev = to_vp_device(vq->vdev);
/* we write the queue's selector into the notification register to
* signal the other end */
iowrite16(vq->index, vp_dev->ioaddr + VIRTIO_PCI_QUEUE_NOTIFY);
}

可以看到这里仅仅是吧vq的index编号写入到设备的IO地址空间中,实际上就是设备对应的PCI配置空间中VIRTIO_PCI_QUEUE_NOTIFY位置。这里执行IO操作会引发VM-exit,继而退出到KVM->qemu中处理。看下后端驱动的处理方式。在qemu代码中virtio-pci.c文件中有函数virtio_ioport_write专门处理前端驱动的IO写操作,看
case VIRTIO_PCI_QUEUE_NOTIFY:
if (val < VIRTIO_PCI_QUEUE_MAX) {
virtio_queue_notify(vdev, val);
}
break;
这里首先判断队列号是否在合法范围内,然后调用virtio_queue_notify函数,而最终会调用到virtio_queue_notify_vq,该函数其实仅仅调用了VirtQueue结构中绑定的处理函数handle_output,该函数根据不同的设备有不同的实现,比如网卡有网卡的实现,而块设备有块设备的实现。以网卡为例看看创建VirtQueue的时候给绑定的是哪个函数。在virtio-net,c中的virtio_net_init,可以看到这里给接收队列绑定的是virtio_net_handle_rx,而给发送队列绑定的是virtio_net_handle_tx_bh或者virtio_net_handle_tx_timer。而对于块设备则对应的是virtio_blk_handle_output函数。
net virtqueue 的notify

vq = vring_create_virtqueue(index, num, VIRTIO_MMIO_VRING_ALIGN, vdev,
true, true, ctx, vm_notify, callback, name);
/* Transport interface */
/* the notify function used when creating a virt queue */
static bool vm_notify(struct virtqueue *vq)
{
struct virtio_mmio_device *vm_dev = to_virtio_mmio_device(vq->vdev);
/* We write the queue's selector into the notification register to
* signal the other end */
writel(vq->index, vm_dev->base + VIRTIO_MMIO_QUEUE_NOTIFY);
return true;
}
void virtio_queue_notify(VirtIODevice *vdev, int n)
{
VirtQueue *vq = &vdev->vq[n];
if (unlikely(!vq->vring.desc || vdev->broken)) {
return;
}
trace_virtio_queue_notify(vdev, vq - vdev->vq, vq);
if (vq->host_notifier_enabled) {
event_notifier_set(&vq->host_notifier);
} else if (vq->handle_output) {
vq->handle_output(vdev, vq);
if (unlikely(vdev->start_on_kick)) {
virtio_set_started(vdev, true);
}
}
}

网卡virtqueue

static inline int virtqueue_add(struct virtqueue *_vq,
struct scatterlist *sgs[],
unsigned int total_sg,
unsigned int out_sgs,
unsigned int in_sgs,
void *data,
void *ctx,
gfp_t gfp)
{
struct vring_virtqueue *vq = to_vvq(_vq);
return vq->packed_ring ? virtqueue_add_packed(_vq, sgs, total_sg,
out_sgs, in_sgs, data, ctx, gfp) :
virtqueue_add_split(_vq, sgs, total_sg,
out_sgs, in_sgs, data, ctx, gfp);
}


vm_find_vqs --> vm_setup_vq
|
| --> vring_create_virtqueue
|--> vring_init, 初始化vring
|--> __vring_new_virtqueue,初始化vring_virtqueue的vq和vring
virtqueue_add
| --> virtqueue_add_split
| --> dma_addr_t addr = vring_map_one_sg(vq, sg, DMA_TO_DEVICE)
| --> 更新 vq->split.vring.desc vq->split.vring.avail


struct vring_virtqueue
{
union {
/* Available for split ring */
struct {
/* Actual memory layout for this queue. */
struct vring vring;
/* Last written value to avail->flags */
u16 avail_flags_shadow;
/*
* Last written value to avail->idx in
* guest byte order.
*/
u16 avail_idx_shadow;
/* Per-descriptor state. */
struct vring_desc_state_split *desc_state;
/* DMA address and size information */
dma_addr_t queue_dma_addr;
size_t queue_size_in_bytes;
} split;
};
io write
linux-5.4.60-89/drivers/virtio# grep writel -rn * | grep VIRTIO_MMIO_QUEUE
virtio_mmio.c:278: writel(vq->index, vm_dev->base + VIRTIO_MMIO_QUEUE_NOTIFY);
virtio_mmio.c:324: writel(index, vm_dev->base + VIRTIO_MMIO_QUEUE_SEL);
virtio_mmio.c:326: writel(0, vm_dev->base + VIRTIO_MMIO_QUEUE_PFN);
virtio_mmio.c:328: writel(0, vm_dev->base + VIRTIO_MMIO_QUEUE_READY);
virtio_mmio.c:363: writel(index, vm_dev->base + VIRTIO_MMIO_QUEUE_SEL);
virtio_mmio.c:394: writel(virtqueue_get_vring_size(vq), vm_dev->base + VIRTIO_MMIO_QUEUE_NUM);
virtio_mmio.c:411: writel(PAGE_SIZE, vm_dev->base + VIRTIO_MMIO_QUEUE_ALIGN);
virtio_mmio.c:412: writel(q_pfn, vm_dev->base + VIRTIO_MMIO_QUEUE_PFN);
virtio_mmio.c:417: writel((u32)addr, vm_dev->base + VIRTIO_MMIO_QUEUE_DESC_LOW);
virtio_mmio.c:422: writel((u32)addr, vm_dev->base + VIRTIO_MMIO_QUEUE_AVAIL_LOW);
virtio_mmio.c:427: writel((u32)addr, vm_dev->base + VIRTIO_MMIO_QUEUE_USED_LOW);
virtio_mmio.c:431: writel(1, vm_dev->base + VIRTIO_MMIO_QUEUE_READY);
virtio_mmio.c:447: writel(0, vm_dev->base + VIRTIO_MMIO_QUEUE_PFN);
virtio_mmio.c:449: writel(0, vm_dev->base + VIRTIO_MMIO_QUEUE_READY);

vm_setup_vq

static struct virtqueue *vm_setup_vq(struct virtio_device *vdev, unsigned index,
void (*callback)(struct virtqueue *vq),
const char *name, bool ctx)
{
struct virtio_mmio_device *vm_dev = to_virtio_mmio_device(vdev);
struct virtio_mmio_vq_info *info;
struct virtqueue *vq;
unsigned long flags;
unsigned int num;
int err;
if (!name)
return NULL;
/* Select the queue we're interested in */
writel(index, vm_dev->base + VIRTIO_MMIO_QUEUE_SEL);
/* Queue shouldn't already be set up. */
if (readl(vm_dev->base + (vm_dev->version == 1 ?
VIRTIO_MMIO_QUEUE_PFN : VIRTIO_MMIO_QUEUE_READY))) {
err = -ENOENT;
goto error_available;
}
/* Allocate and fill out our active queue description */
info = kmalloc(sizeof(*info), GFP_KERNEL);
if (!info) {
err = -ENOMEM;
goto error_kmalloc;
}
num = readl(vm_dev->base + VIRTIO_MMIO_QUEUE_NUM_MAX);
if (num == 0) {
err = -ENOENT;
goto error_new_virtqueue;
}
/* Create the vring */
vq = vring_create_virtqueue(index, num, VIRTIO_MMIO_VRING_ALIGN, vdev,
true, true, ctx, vm_notify, callback, name);
if (!vq) {
err = -ENOMEM;
goto error_new_virtqueue;
}
//接着Guest virtio驱动通知Qemu Queue的vring.num
/* Activate the queue */
writel(virtqueue_get_vring_size(vq), vm_dev->base + VIRTIO_MMIO_QUEUE_NUM);
if (vm_dev->version == 1) {
u64 q_pfn = virtqueue_get_desc_addr(vq) >> PAGE_SHIFT;
/*
* virtio-mmio v1 uses a 32bit QUEUE PFN. If we have something
* that doesn't fit in 32bit, fail the setup rather than
* pretending to be successful.
*/
if (q_pfn >> 32) {
dev_err(&vdev->dev,
"platform bug: legacy virtio-mmio must not be used with RAM above 0x%llxGB\n",
0x1ULL << (32 + PAGE_SHIFT - 30));
err = -E2BIG;
goto error_bad_pfn;
}
writel(PAGE_SIZE, vm_dev->base + VIRTIO_MMIO_QUEUE_ALIGN);
//将guest vring的gpa传递给qemu
writel(q_pfn, vm_dev->base + VIRTIO_MMIO_QUEUE_PFN);
} else {
u64 addr;
addr = virtqueue_get_desc_addr(vq);
writel((u32)addr, vm_dev->base + VIRTIO_MMIO_QUEUE_DESC_LOW);
writel((u32)(addr >> 32),
vm_dev->base + VIRTIO_MMIO_QUEUE_DESC_HIGH);
addr = virtqueue_get_avail_addr(vq);
writel((u32)addr, vm_dev->base + VIRTIO_MMIO_QUEUE_AVAIL_LOW);
writel((u32)(addr >> 32),
vm_dev->base + VIRTIO_MMIO_QUEUE_AVAIL_HIGH);
addr = virtqueue_get_used_addr(vq);
writel((u32)addr, vm_dev->base + VIRTIO_MMIO_QUEUE_USED_LOW);
writel((u32)(addr >> 32),
vm_dev->base + VIRTIO_MMIO_QUEUE_USED_HIGH);
writel(1, vm_dev->base + VIRTIO_MMIO_QUEUE_READY);
}

QEMU-GUEST交互

static void virtio_mmio_write(void *opaque, hwaddr offset, uint64_t value,
unsigned size)
{
VirtIOMMIOProxy *proxy = (VirtIOMMIOProxy *)opaque;
VirtIODevice *vdev = virtio_bus_get_device(&proxy->bus);
trace_virtio_mmio_write_offset(offset, value);
if (!vdev) {
/* If no backend is present, we just make all registers
* write-ignored. This allows us to provide transports with
* no backend plugged in.
*/
return;
}
if (offset >= VIRTIO_MMIO_CONFIG) {
offset -= VIRTIO_MMIO_CONFIG;
switch (size) {
case 1:
virtio_config_writeb(vdev, offset, value);
break;
case 2:
virtio_config_writew(vdev, offset, value);
break;
case 4:
virtio_config_writel(vdev, offset, value);
break;
default:
abort();
}
return;
}
if (size != 4) {
qemu_log_mask(LOG_GUEST_ERROR,
"%s: wrong size access to register!\n",
__func__);
return;
}
switch (offset) {
case VIRTIO_MMIO_DEVICE_FEATURES_SEL:
proxy->host_features_sel = value;
break;
case VIRTIO_MMIO_DRIVER_FEATURES:
if (!proxy->guest_features_sel) {
virtio_set_features(vdev, value);
}
break;
case VIRTIO_MMIO_DRIVER_FEATURES_SEL:
proxy->guest_features_sel = value;
break;
case VIRTIO_MMIO_GUEST_PAGE_SIZE:
proxy->guest_page_shift = ctz32(value);
if (proxy->guest_page_shift > 31) {
proxy->guest_page_shift = 0;
}
trace_virtio_mmio_guest_page(value, proxy->guest_page_shift);
break;
case VIRTIO_MMIO_QUEUE_SEL:
if (value < VIRTIO_QUEUE_MAX) {
vdev->queue_sel = value;
}
break;
case VIRTIO_MMIO_QUEUE_NUM:
//在virtio_queue_update_rings中则分别更新了vring->avail和vring->used的gpa指针
trace_virtio_mmio_queue_write(value, VIRTQUEUE_MAX_SIZE);
virtio_queue_set_num(vdev, vdev->queue_sel, value);
/* Note: only call this function for legacy devices */
virtio_queue_update_rings(vdev, vdev->queue_sel);
break;
case VIRTIO_MMIO_QUEUE_ALIGN:
/* Note: this is only valid for legacy devices */
virtio_queue_set_align(vdev, vdev->queue_sel, value);
break;
case VIRTIO_MMIO_QUEUE_PFN:
if (value == 0) {
virtio_reset(vdev);
} else {
virtio_queue_set_addr(vdev, vdev->queue_sel,
value << proxy->guest_page_shift);
}
break;
case VIRTIO_MMIO_QUEUE_NOTIFY:
if (value < VIRTIO_QUEUE_MAX) {
virtio_queue_notify(vdev, value);
}
break;
case VIRTIO_MMIO_INTERRUPT_ACK:
atomic_and(&vdev->isr, ~value);
virtio_update_irq(vdev);
break;
case VIRTIO_MMIO_STATUS:
if (!(value & VIRTIO_CONFIG_S_DRIVER_OK)) {
virtio_mmio_stop_ioeventfd(proxy);
}
virtio_set_status(vdev, value & 0xff);
if (value & VIRTIO_CONFIG_S_DRIVER_OK) {
virtio_mmio_start_ioeventfd(proxy);
}
if (vdev->status == 0) {
virtio_reset(vdev);
}
break;
case VIRTIO_MMIO_MAGIC_VALUE:
case VIRTIO_MMIO_VERSION:
case VIRTIO_MMIO_DEVICE_ID:
case VIRTIO_MMIO_VENDOR_ID:
case VIRTIO_MMIO_DEVICE_FEATURES:
case VIRTIO_MMIO_QUEUE_NUM_MAX:
case VIRTIO_MMIO_INTERRUPT_STATUS:
qemu_log_mask(LOG_GUEST_ERROR,
"%s: write to readonly register\n",
__func__);
break;
default:
qemu_log_mask(LOG_GUEST_ERROR, "%s: bad register offset\n", __func__);
}
}
static const MemoryRegionOps virtio_mem_ops = {
.read = virtio_mmio_read,
.write = virtio_mmio_write,
.endianness = DEVICE_NATIVE_ENDIAN,
};
所有设备的i/o操作都经由virtio_ioport_write处理
static void virtio_ioport_write(void *opaque, uint32_t addr, uint32_t val){
.....
switch (addr) {
case VIRTIO_PCI_GUEST_FEATURES:
/* Guest does not negotiate properly? We have to assume nothing. */
if (val & (1 << VIRTIO_F_BAD_FEATURE)) {
val = virtio_bus_get_vdev_bad_features(&proxy->bus);
}
virtio_set_features(vdev, val);
break;
....
case VIRTIO_PCI_QUEUE_PFN: // addr = 8
pa = (hwaddr)val << VIRTIO_PCI_QUEUE_ADDR_SHIFT; // 描述符表物理地址
if (pa == 0) {
virtio_pci_reset(DEVICE(proxy));
}
else
virtio_queue_set_addr(vdev, vdev->queue_sel, pa); // 写入描述符表物理地址
break;
case VIRTIO_PCI_QUEUE_SEL: // addr = 14
if (val < VIRTIO_QUEUE_MAX)
vdev->queue_sel = val; // 更新Virtqueue handle_output 序号
break;
case VIRTIO_PCI_QUEUE_NOTIFY: // addr = 16
if (val < VIRTIO_QUEUE_MAX) {
virtio_queue_notify(vdev, val); //根据val序号 触发Virtqueue的描述符表
}
break;
}
}

VIRTIO设备
了解QEMU和KVM交互的知道,客户机的IO操作通过KVM处理后再交由QEMU,反馈也如此。这种纯软件的模拟IO设备,增加了IO的延迟。
而Virtio却为虚拟化的IO提供了另一种解决方案:
Virtio在虚拟机系统内核安装前端驱动,在QEMU中实现后端驱动。前后端驱动通过Virtqueue直接通信,从而绕过了KVM内核模块处理,提高了IO操作性能。
QEMU中VIRTIO实现
启动配置设备
-device virtio-scsi-pci
在虚拟机里查看scsi设备lspci

可以看到Virtio-pci设备的相关信息:IO/PORT: 0xc040 (size=64),MemoryAddress: 0xfebf1000(size=4k)
Virtqueue
Virtio使用Virtqueue实现IO机制,每个Virtqueue就是承载大量数据的queue。vring是Virtqueue实现的具体方式;virtio_ring是virtio传出机制的实现,vring引入ving buffer作为数据的载体。
struct VirtQueue
{
VRing vring;
/* Next head to pop */
uint16_t last_avail_idx;
/* Last avail_idx read from VQ. */
uint16_t shadow_avail_idx;
uint16_t used_idx;
/* Last used index value we have signalled on */
uint16_t signalled_used;
/* Last used index value we have signalled on */
bool signalled_used_valid;
/* Notification enabled? */
bool notification;
uint16_t queue_index;
int inuse;
uint16_t vector;
void (*handle_output)(VirtIODevice *vdev, VirtQueue *vq); // handle output
void (*handle_aio_output)(VirtIODevice *vdev, VirtQueue *vq);
VirtIODevice *vdev;
EventNotifier guest_notifier;
EventNotifier host_notifier;
QLIST_ENTRY(VirtQueue) node;
};
C
COPY
vring
typedef struct VRing
{
unsigned int num; //
unsigned int num_default;
unsigned int align;
hwaddr desc; // 关联描述符数组 (buffer的描述)
hwaddr avail; // 表示客户机可用的描述符
hwaddr used; // 表示宿主机已经使用的描述符
} VRing;
C
COPY
Vring Descriptor
typedef struct VRingDesc
{
uint64_t addr; // 指向guest端的物理地址, 一组buffer列表
uint32_t len; // buffer长度
uint16_t flags; // 包含 3 个值,分别是 VRING_DESC_F_NEXT(1)、
// VRING_DESC_F_WRITE(2)、VRING_DESC_F_INDIRECT(4);
uint16_t next; //指向下一个描述符的index(链表结构)
} VRingDesc;
C
COPY
由一组描述符构成描述符表
Available Vring
typedef struct VRingAvail
{
uint16_t flags;
uint16_t idx; // 指向下一描述符表的入口
uint16_t ring[0]; // 每一个值是一个索引,指向描述符表中的一个可用描述符
} VRingAvail;
C
COPY
VRingUsedElem
typedef struct VRingUsedElem
{
uint32_t id;
uint32_t len;
} VRingUsedElem;
VRingUsed
typedef struct VRingUsed
{
uint16_t flags;
uint16_t idx;
VRingUsedElem ring[0];
} VRingUsed;
Virtqueue初始化(在Qemu端实现)
VirtQueue *virtio_add_queue(VirtIODevice *vdev, int queue_size,
void (*handle_output)(VirtIODevice *, VirtQueue *))
{ //每个Device 维护一组Virtqueue
int i;
for (i = 0; i < VIRTIO_QUEUE_MAX; i++) {
if (vdev->vq[i].vring.num == 0)
break;
}
if (i == VIRTIO_QUEUE_MAX || queue_size > VIRTQUEUE_MAX_SIZE)
abort(); // 每个Device最多1024Virtqueue
// 每个Virtqueue最多1024 vring
vdev->vq[i].vring.num = queue_size; // 初始化vring.num
vdev->vq[i].vring.num_default = queue_size; // 初始化vring.num_default
vdev->vq[i].vring.align = VIRTIO_PCI_VRING_ALIGN; //初始化vring.align
vdev->vq[i].handle_output = handle_output; // 初始化handle_output
vdev->vq[i].handle_aio_output = NULL; // handle_aio_output
return &vdev->vq[i];
}
C
COPY
在Guest端,virtio驱动中vm_setup_vq建立与queue对应的Virtqueue
num = readl(vm_dev->base + VIRTIO_MMIO_QUEUE_NUM_MAX);// 获取vring.num
// vring_create_virtqueue
queue = vring_alloc_queue(vdev, vring_size(num, vring_align),
&dma_addr, GFP_KERNEL|__GFP_ZERO);// 分配Virtqueue空间
//vring_size计算方式
static inline unsigned vring_size(unsigned int num, unsigned long align)
{
return ((sizeof(struct vring_desc) * num + sizeof(__virtio16) * (3 + num)
+ align - 1) & ~(align - 1))
+ sizeof(__virtio16) * 3 + sizeof(struct vring_used_elem) * num;
}
C
COPY
从这里可以看出来vring的内存布局

接着Guest virtio驱动通知Qemu Queue的vring.num
writel(virtqueue_get_vring_size(vq), vm_dev->base + VIRTIO_MMIO_QUEUE_NUM);
unsigned int virtqueue_get_vring_size(struct virtqueue *_vq)
{
struct vring_virtqueue *vq = to_vvq(_vq);
return vq->vring.num;
}
C
COPY
Guest向虚拟设备提供buffer
在virtio驱动virtqueue_add实现
// buffer空间 DMA方式分配
dma_addr_t addr = vring_map_one_sg(vq, sg, DMA_TO_DEVICE);
// 填充desc表 flags addr len
desc[i].flags = cpu_to_virtio16(_vq->vdev, VRING_DESC_F_NEXT);
desc[i].addr = cpu_to_virtio64(_vq->vdev, addr);
desc[i].len = cpu_to_virtio32(_vq->vdev, sg->length);
//更新可用ring头
/* Put entry in available array (but don't update avail->idx until they
* do sync). */
avail = vq->avail_idx_shadow & (vq->vring.num - 1);
vq->vring.avail->ring[avail] = cpu_to_virtio16(_vq->vdev, head);
//更新可用ring index
vq->avail_idx_shadow++;
vq->vring.avail->idx = cpu_to_virtio16(_vq->vdev, vq->avail_idx_shadow);
//当Virtqueue添加次数达到64k时,flush vring内容到QEMU
if (unlikely(vq->num_added == (1 << 16) - 1))
virtqueue_kick(_vq);
bool virtqueue_kick(struct virtqueue *vq)
{
if (virtqueue_kick_prepare(vq))
// 修改 virtqueue notify 寄存器
return virtqueue_notify(vq);
return true;
}
C
COPY
虚拟设备使用Buffer
offset = 0;
while (offset < size) {
//从desc表中寻找available ring中添加的buffers,映射内存
elem = virtqueue_pop(vrng->vq, sizeof(VirtQueueElement));
if (!elem) {
break;
}
// 读取内容
len = iov_from_buf(elem->in_sg, elem->in_num,
0, buf + offset, size - offset);
// 更新读取光标
offset += len;
virtqueue_push(vrng->vq, elem, len);
trace_virtio_rng_pushed(vrng, len);
g_free(elem);
}
void virtqueue_push(VirtQueue *vq, const VirtQueueElement *elem,
unsigned int len)
{ // 取消内存映射,跟新usedVring字段
virtqueue_fill(vq, elem, len, 0);
virtqueue_flush(vq, 1);
}
C
COPY
QEMU-GUEST交互
所有设备的i/o操作都经由virtio_ioport_write处理
原文链接:https://www.cnblogs.com/dream397/p/14367489.html








![[附源码]java毕业设计江苏策腾智能科技公司人事管理系统](https://img-blog.csdnimg.cn/25dc5077ef544cd8943ebbe19a4d7941.png)
