目录
- 1. 一些可用的参考链接
- 2. 开始训练yolov7
- 2.1 --weights
- 2.2 --cfg
- 2.3 --data
- 2.4 --hyp
- 2.5 --epochs
- 2.6 --batch-size
- 2.7 --workers
- 2.8 --name
1. 一些可用的参考链接
- 官方YOLOv7 项目地址:https://github.com/WongKinYiu/yolov7
- 如果想设置早停机制,可以参考这个链接:yolov7自动停止(设置patience)且输出最优模型时的PR图(test best.py)
- 学习
train.py中的参数含义,可参考手把手调参最新 YOLOv7 模型 训练部分 - 最新版本(二) - 学习
detect.py中的参数含义,可参考手把手调参最新 YOLOv7 模型 推理部分 - 最新版本(一)
2. 开始训练yolov7
yolov7-tiny
参数量:6023106
GFLOPs:13.2
- 🍀参考链接:Yolov7训练自己的数据集(超详细)
- 参数详解参考的链接:YOLOV7开源代码讲解–训练参数解释
- 先进入官网下载
yolov7-main代码(直接下载的master根目录代码) - 直接点击下载yolov7-tiny.pt,有12MB
如果是要在AutoDL中训练,则需要再下载Arial.ttf字体后上传到yolov7-main根目录下 - 先跟着以下训练命令中创建或者配置好一些文件,再回来复制这里面的训练命令,粘贴进终端开始训练
先放上我的训练命令,然后讲解设置到的重要参数的含义:
建议:以下参数可以直接通过更改train.py的default值来设置,通过default值来设置的好处是:
1)直接运行train.py即可,不用每次都来重复设置这些值
2)避免以后回顾代码时忘记了自己参数是怎么设置的
3)忘记在哪里看到了,说是在pycharm中直接运行py文件会比在终端设置参数来运行的训练速度快一些;如果是在AutoDL上训练那就没啥影响,因为是必须在终端中用命令来运行的。但是我觉得因为前2点原因还是直接先在py中设置好default值比较方便
python train.py --weights yolov7-tiny.pt --cfg cfg/training/yolov7-tiny.yaml --data data/mydata.yaml --hyp data/hyp.scratch.p5.yaml --epochs 300 --batch-size 32 --workers 16 --name yolov7-tiny
其他的重要参数:
-
--adam:命令行中直接加上--adam则表示使用Adam优化器,否则默认使用SGD(如果是自制数据集,建议使用Adam[其实这个策略也是学到的,忘记从哪儿学到的了,可自行尝试一下]。训练yolov5时我对比了一下,使用SGD时loss值变化比较平缓,相反Adam会比较波动。但是采用Adam训练结束之后,各项指标值比如map0.5、FPS等会高一些) -
--img-size:设置将图像缩放至img-size统一尺寸,再喂入数据网络训练(默认是[640, 640],通常数据集采用这个尺寸就行了。如果是大分辨率图像且采用更大的网络,可适当调大img-size,保持是32的倍数就好。img-size值越大,占用显存就越多,训练速度就更慢,对显卡的要求就越高) -
--rect:命令行中直接加上--rect则表示开启矩形推理(可以试试不开启和开启这个参数,然后对比训练结果。兴许开启之后会效果好一些) -
--resume:命令行中加上--resume True则表示进行断点训练(需要开启这个命令通常是因为【训练突然中断or还想继续训练】,有需要的话可参考我这个博客进行更改👉yolov5ds-断点训练、继续训练、先终止训练并调整最终epoch(yolov5同样适用))
剩下的参数,可以参见我分享出来的训练参数解释链接
2.1 --weights
--weights:用于指明预训练权重文件位置(如果不需要预训练权重,则使default值为空即''即可,或者终端中命令参数写成--weights '')
本篇文章是要使用yolov7-tiny,所以用到了yolov7-tiny.pt预训练权重。点击下载yolov7-tiny.pt
2.2 --cfg
--cfg:用于指明模型的配置文件(这个要指明training文件夹下的yolov7-tiny,注意是training下的yaml,不是deploy下的)
2.3 --data
--data:用来指明自己的配置数据来源,建议将data文件夹下的coco.yaml复制另存为mydata.yaml。命令中写成--data data/mydata.yaml
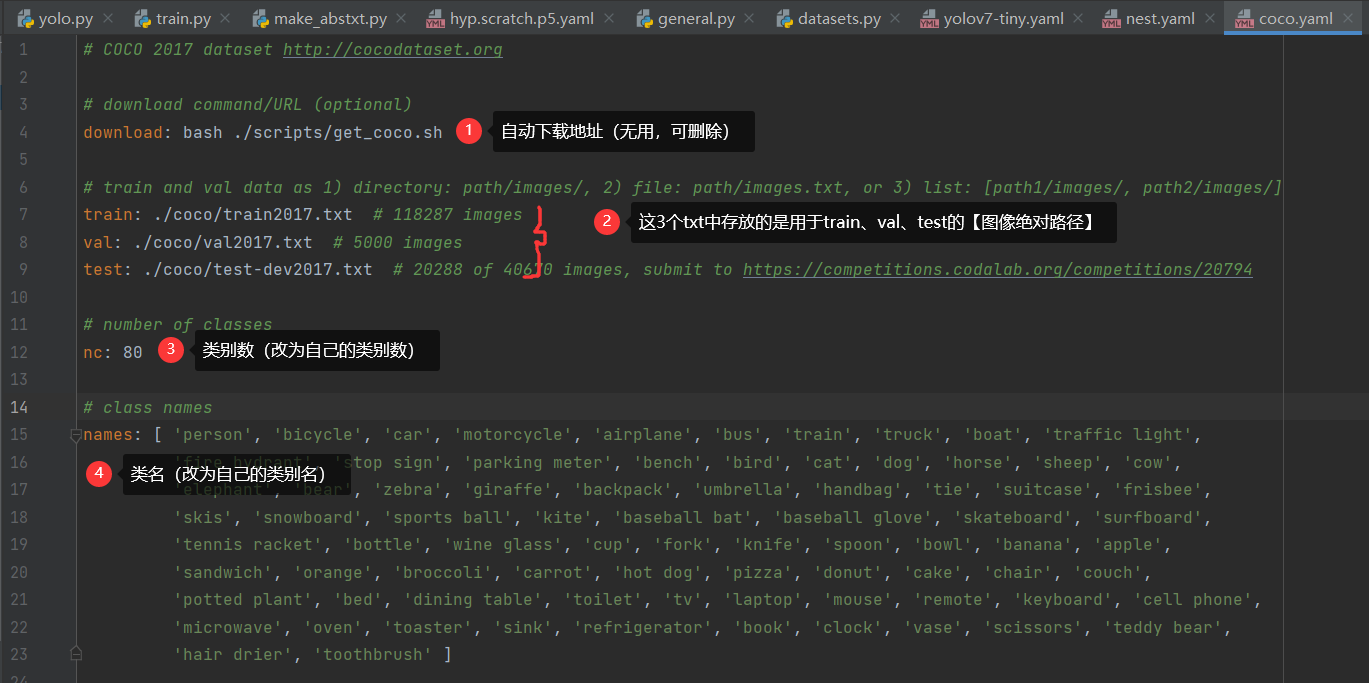
注意:数据集不用必须存放到当前项目中,只要在mydata.yaml文件中的train、val、test指明的txt文件包含了相应任务的图像绝对路径即可。
如果已经存在如下的datasets数据集分布,则可以去我博客【脚本】生成已划分好训练集、验证集、测试集的数据集对应的train.txt、val.txt、test.txt【包含图像的绝对地址】调用代码生成所需txt文件:
datasets
├─images
│ ├─test
│ ├─train
│ └─val
├─labels
├─test
├─train
└─val
2.4 --hyp
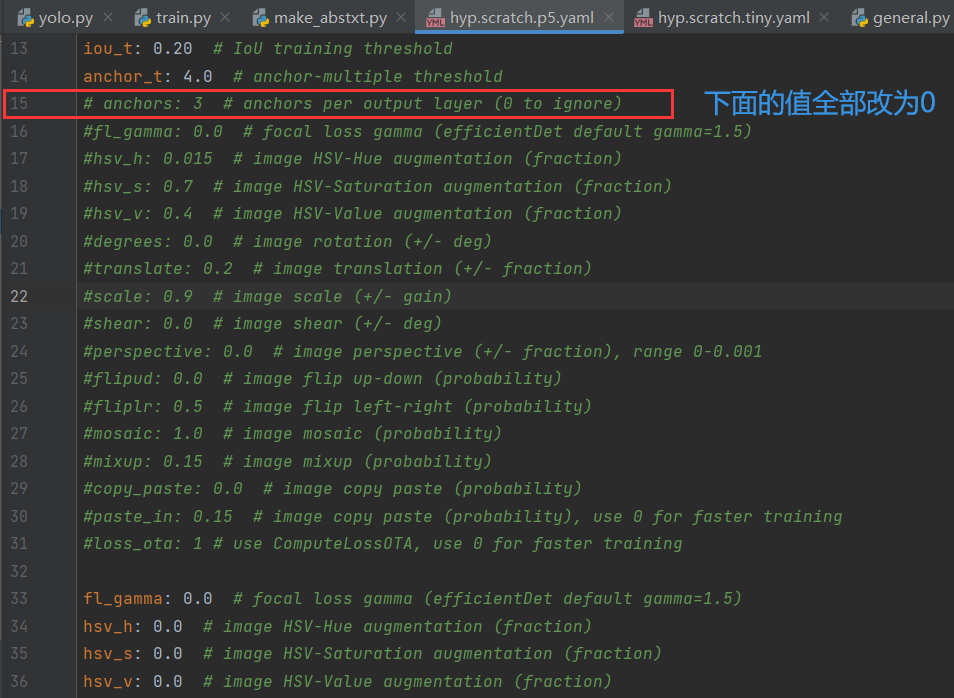
--hyp:超参数配置文件,我使用的是默认的data/hyp.scratch.p5.yaml文件(我将这个里面的数据增强给关掉了,yolov5中的在线数据增强我也关掉了,因为有人说过:自制的数据集本来复杂度就不够,开启在线数据增强的话,很容易训练效果不好,造成过拟合。但是我看还有一个超参数文件是data/hyp.scratch.tiny.yaml,不知道是不是专门用于tiny效果会好点,正在实验中[结果就是,这个tiny.yaml的超参数配置没有p5.yaml的效果好,map0.5降了2个点。还是就是用默认的超参数设置吧])
关闭在线数据增强的方式就是,将15行以下的值全部改为0:
2.5 --epochs
--epochs:训练的轮数,默认为300(如果是自制数据集,类别不多且图像张数不多、复杂度也不是太多的话,设置200~300肯定是够的了)
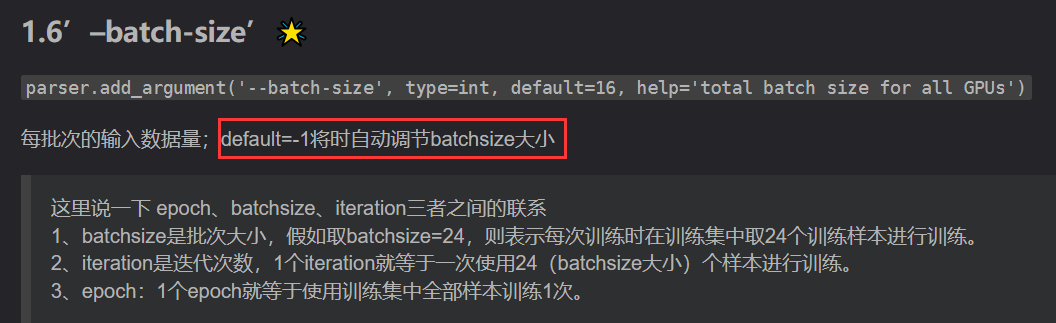
2.6 --batch-size
--batch-size:设置一次性选用多少张图像进行训练(下图引自手把手调参最新 YOLOv7 模型 训练部分 - 最新版本(二))
(通常是8、16、32、64,这取决于自己的GPU内存有多大,大的话就可以设置多点,小的话设置成1、2、4、6、24等,最好是2的倍数。通常论文里面设置成的32、64)
2.7 --workers
--workers :训练时使用的CPU线程数。如果是在windows上训练,一定要设置成0,不然会出错;如果是Linux系统,通常设置成8、16(设置得越大,训练可能会快点)
2.8 --name
--name:设置结果保存文件夹的名称,默认是exp(建议使用这个参数,指明本次实验结果是训练什么模型,以免后续再回顾实验结果时搞不清楚)






![[附源码]java毕业设计江苏策腾智能科技公司人事管理系统](https://img-blog.csdnimg.cn/25dc5077ef544cd8943ebbe19a4d7941.png)




![[旭日X3派] 初识篇 - 01](https://img-blog.csdnimg.cn/e08520ba648e4c9894ca2bfb0c39f8d1.png)