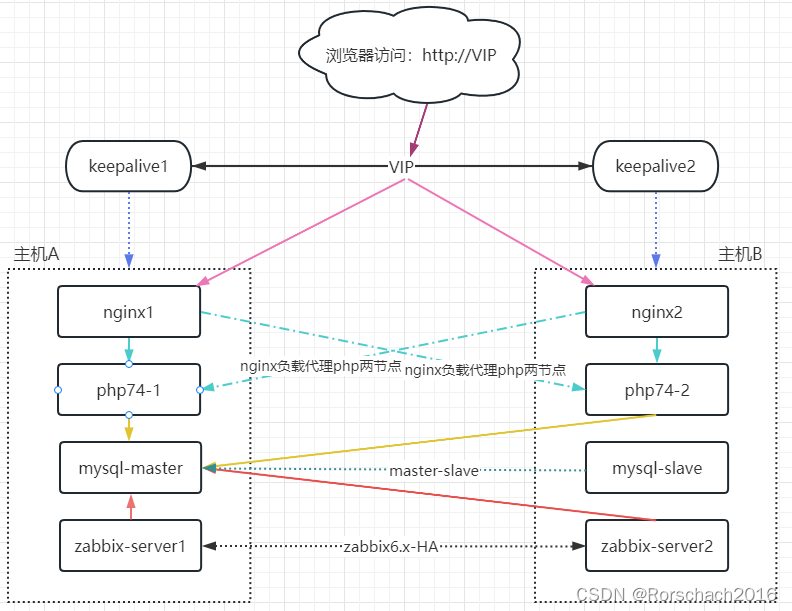
PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋 - 知乎作者:汪诚愚、段忠杰、朱祥茹、黄俊导读近年来,随着海量多模态数据在互联网的爆炸性增长和训练深度学习大模型的算力大幅提升,AI生成内容(AI Generated Content,AIGC)的应用呈现出爆发性增长趋势。其中,文图…![]() https://zhuanlan.zhihu.com/p/590020134这里和sd 1.5保持了一样的架构,训练也是通用的diffusers的train_text_to_image.py,只是加载的权重不一样而已。在这里,其实到没有必要一定使用easynlp中的clip进行训练,实际上可以用transformers中的chineseclip或者就是chinesecllip进行训练得到clip模型,但是大部分情况下clip模型是不需要重新训练,可以基于已有的来训练diffusion模型,已经训练好的clip可以直接替换掉sd中的text_encoder权重接口。其次对于中文diffusion的训练,使用diffusers只需要将tokenizer换成BertTokenizer,还是用clipmodel进行加载即可,也就是说只将clip模块进行替换,即可重新训练中文diffusion模型。
https://zhuanlan.zhihu.com/p/590020134这里和sd 1.5保持了一样的架构,训练也是通用的diffusers的train_text_to_image.py,只是加载的权重不一样而已。在这里,其实到没有必要一定使用easynlp中的clip进行训练,实际上可以用transformers中的chineseclip或者就是chinesecllip进行训练得到clip模型,但是大部分情况下clip模型是不需要重新训练,可以基于已有的来训练diffusion模型,已经训练好的clip可以直接替换掉sd中的text_encoder权重接口。其次对于中文diffusion的训练,使用diffusers只需要将tokenizer换成BertTokenizer,还是用clipmodel进行加载即可,也就是说只将clip模块进行替换,即可重新训练中文diffusion模型。
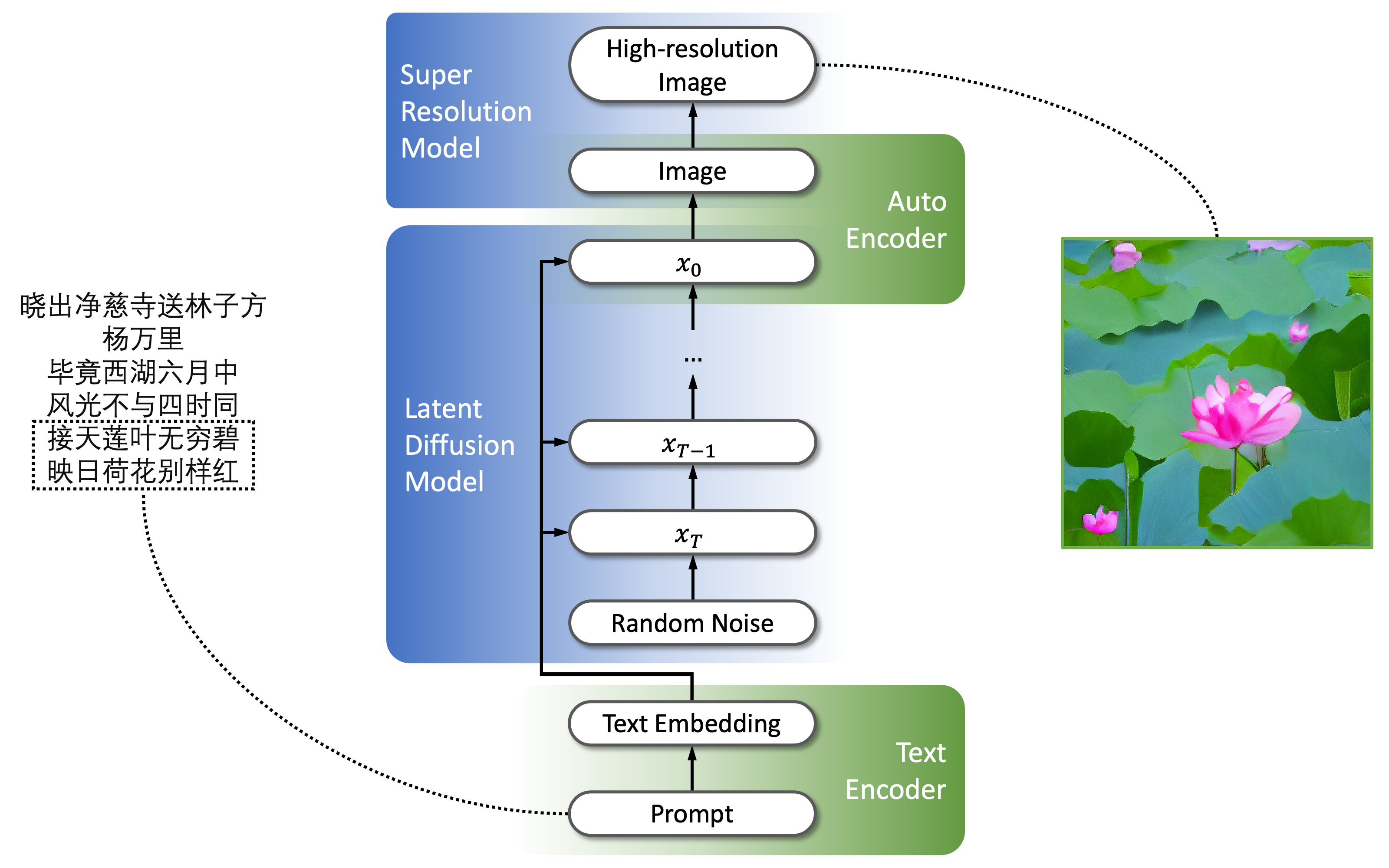
PAI-diffusion使用Wukong数据集中的两千万中文图文数据对上进行了20天的预训练,随后在多个下游数据集中进行了微调。
训练:diffusers -> train_text_to_image_lora.py
diffusers通用
分析一下 pai-diffusion-general-large-zh 权重:
feature_extractor、safety_checker不影响训练和推理,加不加都行
scheduler->scheduler_config.json
{
"_class_name": "DPMSolverMultistepScheduler",
"_diffusers_version": "0.15.0.dev0",
"algorithm_type": "dpmsolver++",
"beta_end": 0.012,
"beta_schedule": "scaled_linear", # beta_scheduler:beta的调度方式,scaled_linear:缩放线性调度方式
"beta_start": 0.00085,
"clip_sample": false,
"dynamic_thresholding_ratio": 0.995,
"lower_order_final": true,
"num_train_timesteps": 1000,
"prediction_type": "epsilon",
"sample_max_value": 1.0,
"set_alpha_to_one": false,
"skip_prk_steps": true,
"solver_order": 2,
"solver_type": "midpoint",
"steps_offset": 1,
"thresholding": false,
"trained_betas": null
}和正常的sd是没什么区别的。
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
diffusers.schedulers.scheduling_utils.SchedulerMixin.from_pretrained()
diffusers.schedulers.scheduling_ddpm.DDPMScheduler->ConfigMixin->load_config
DDPMScheduler.from_config->
model = cls(**init_dict) ->参数完成初始化text_encoder->config.json
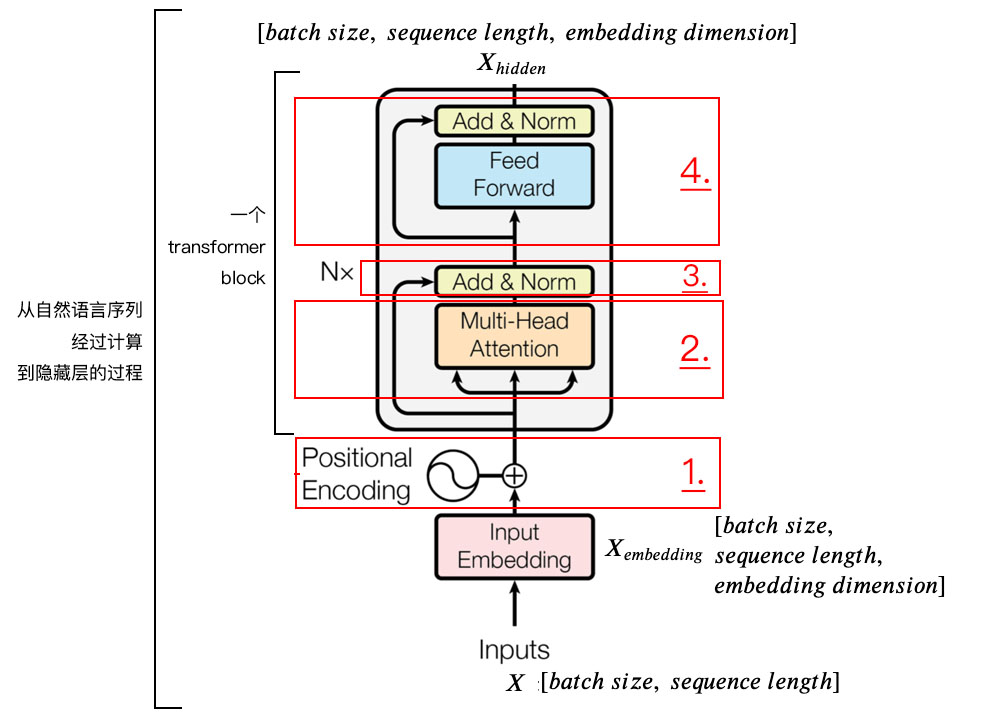
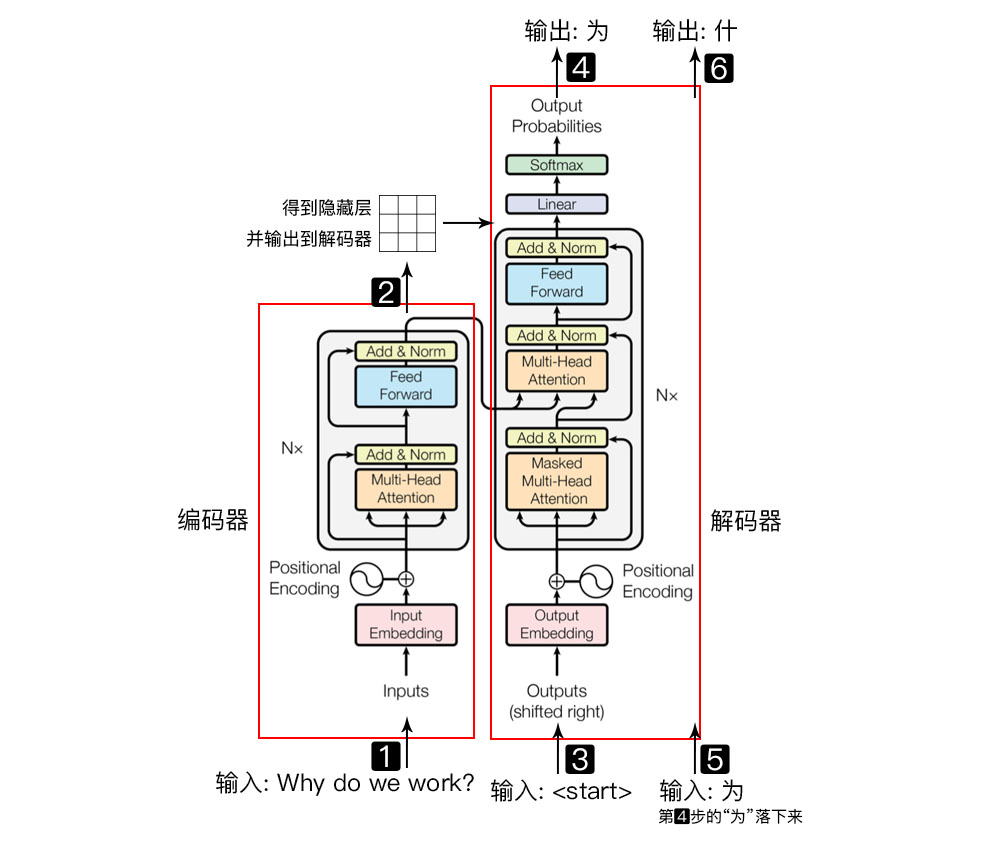
{
"_name_or_path": "models/sdm1.4_with_ChTextEncoder/text_encoder",
"architectures": [
"CLIPTextModel"
],
"attention_dropout": 0.0,
"bos_token_id": 0,
"dropout": 0.0,
"eos_token_id": 2,
"hidden_act": "quick_gelu", # 激活函数
"hidden_size": 768, # encoder layers和pooler layer的维度
"initializer_factor": 1.0,
"initializer_range": 0.02,
"intermediate_size": 3072, # transformer encoder中feed-forward层的维度
"layer_norm_eps": 1e-05,
"max_position_embeddings": 32, # 模型处理的最大序列长度
"model_type": "clip_text_model",
"num_attention_heads": 12, # encoder中并行的transformer layer的个数
"num_hidden_layers": 12, # transformer encoder hidden layers的数量
"pad_token_id": 1,
"projection_dim": 512,
"torch_dtype": "float32",
"transformers_version": "4.25.1",
"vocab_size": 21128 # clip文本模型词汇表大小
}注意到中文的词汇表是21128,如果是英文的词汇表sd 1.5的是49408.
text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder",...)
transformers.modeling_utils.PreTrainedModel.from_pretrained()
transformers.models.clip.configuration_clip.CLIPTextConfig->
transformers.models.clip.modeling_clip.CLIPTextModel.forward->
transformers.models.clip.modeling_clip.CLIPTextTransformer.forward->tokenizer->special_tokens_map.json/tokenizer_config.json/vocab.txt
{
"cls_token": "[CLS]",
"do_basic_tokenize": true,
"do_lower_case": true,
"mask_token": "[MASK]",
"model_max_length": 32,
"name_or_path": "models/release_20230316/512/tokenizer",
"never_split": null,
"pad_token": "[PAD]",
"sep_token": "[SEP]",
"special_tokens_map_file": null,
"strip_accents": null,
"tokenize_chinese_chars": true,
"tokenizer_class": "BertTokenizer",
"unk_token": "[UNK]"
}
tokenizer = BertTokenizer.from_pretrained()->
transformers.tokenization_utils_base.PretrainedTokenizerBase.forward->
transformers.models.bert.tokenization_bert.BertTokenizer
unet->config.json
{
"_class_name": "UNet2DConditionModel",
"_diffusers_version": "0.14.0.dev0",
"_name_or_path": "models/20230321_512_openjourney/checkpoint-30000/unet_ema",
"act_fn": "silu",
"attention_head_dim": 8,
"block_out_channels": [
320,
640,
1280,
1280
],
"center_input_sample": false,
"class_embed_type": null,
"conv_in_kernel": 3,
"conv_out_kernel": 3,
"cross_attention_dim": 768,
"decay": 0.9999,
"down_block_types": [
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"CrossAttnDownBlock2D",
"DownBlock2D"
],
"downsample_padding": 1,
"dual_cross_attention": false,
"flip_sin_to_cos": true,
"freq_shift": 0,
"in_channels": 4,
"inv_gamma": 1.0,
"layers_per_block": 2,
"mid_block_scale_factor": 1,
"mid_block_type": "UNetMidBlock2DCrossAttn",
"min_decay": 0.0,
"norm_eps": 1e-05,
"norm_num_groups": 32,
"num_class_embeds": null,
"only_cross_attention": false,
"optimization_step": 30000,
"out_channels": 4,
"power": 0.6666666666666666,
"projection_class_embeddings_input_dim": null,
"resnet_time_scale_shift": "default",
"sample_size": 64,
"time_cond_proj_dim": null,
"time_embedding_type": "positional",
"timestep_post_act": null,
"up_block_types": [
"UpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D",
"CrossAttnUpBlock2D"
],
"upcast_attention": false,
"update_after_step": 0,
"use_ema_warmup": false,
"use_linear_projection": false
}
vae->config.json
{
"_class_name": "AutoencoderKL",
"_diffusers_version": "0.14.0.dev0",
"_name_or_path": "models/release_20230316/512/vae",
"act_fn": "silu",
"block_out_channels": [
128,
256,
512,
512
],
"down_block_types": [
"DownEncoderBlock2D",
"DownEncoderBlock2D",
"DownEncoderBlock2D",
"DownEncoderBlock2D"
],
"in_channels": 3,
"latent_channels": 4,
"layers_per_block": 2,
"norm_num_groups": 32,
"out_channels": 3,
"sample_size": 512,
"scaling_factor": 0.18215,
"up_block_types": [
"UpDecoderBlock2D",
"UpDecoderBlock2D",
"UpDecoderBlock2D",
"UpDecoderBlock2D"
]
}