select/poll
- 五种IO模型
- 对IO的正确理解
- 何为高效的IO
- 阻塞IO
- 非阻塞IO
- 设置文件描述符为非阻塞模式
- 非阻塞IO例子
- 信号驱动IO
- 异步IO
- 多路转接
- selct
- 认识接口
- select返回值
- 基本使用
- select使用特点
- 缺点
- poll
- 认识接口
- 对select的改善
- 缺点
五种IO模型
对IO的正确理解
🚀IO不仅仅是数据的拷贝过程,而IO更准确的定义是:IO = 等待条件就绪 + 拷贝,就像在网络通信中客户端连接上服务器后但是一直不给服务器发送请求,这时对于服务器而言就无法读取,而是一直等待读取事件就绪。
何为高效的IO
🚀所谓高效的IO就是单位事件内,等待事件就绪的时间所占整个IO时间的比例越低,说明IO的效率越高。
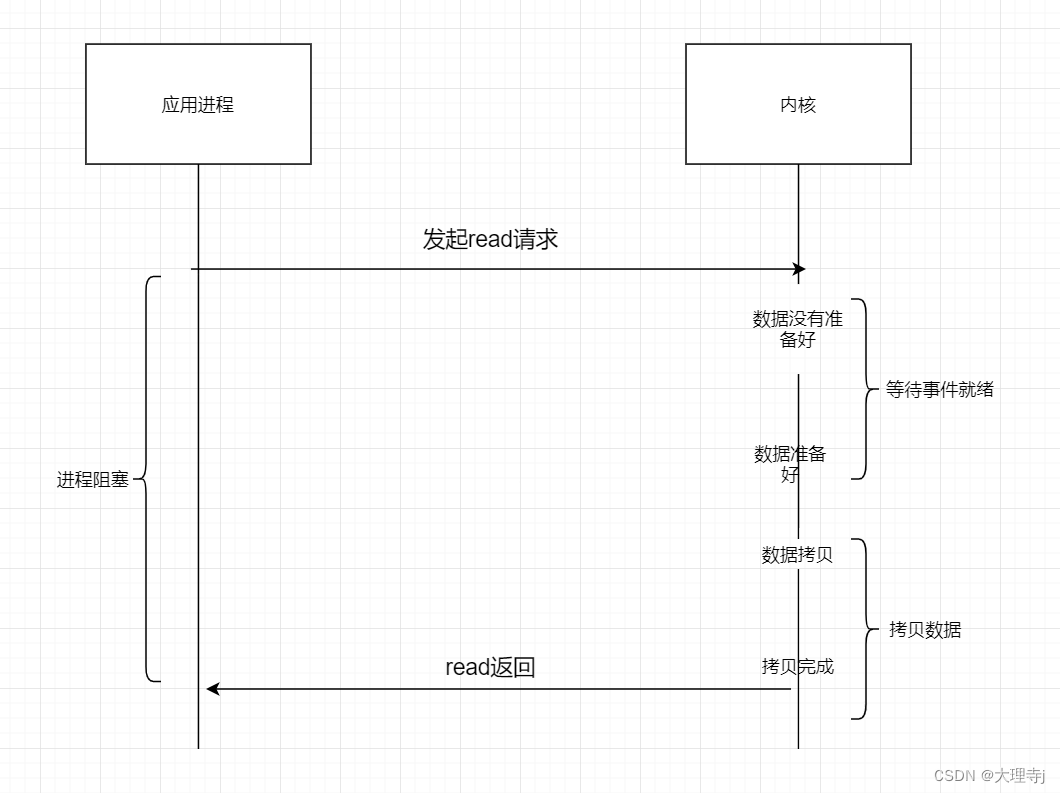
阻塞IO
🚀阻塞IO是最常见的IO模型,所有文件默认都是阻塞IO。在资源就绪之前进程会一直处于等待状态,等待资源就绪后会对数据进行拷贝,然后返回。
非阻塞IO
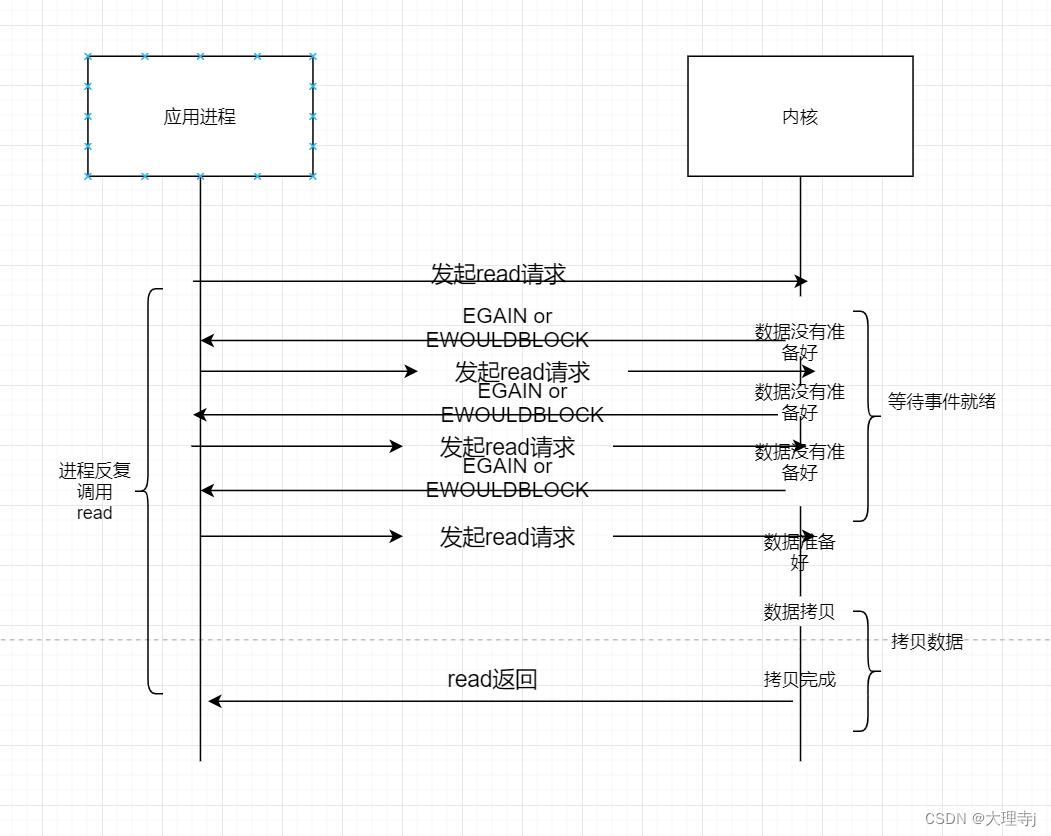
🚀非阻塞IO,当进行IO时发现事件还未就绪就会直接返回,并且错误码被置为EGAIN 或者 EWOULDBLOCK。非阻塞IO是实现轮询的基础,通常程序员利用非阻塞IO来进行轮询,反复的尝试读写某个文件描述符,但是对CPU来说是较大的浪费,一般在特殊情况下使用。

设置文件描述符为非阻塞模式
void SetNonBlock(int fd) {
int fl = fcntl(fd,F_GETFL);
if(fl < 0) {
std::cerr << "getfl faliled\n";
return -1;
}
fcntl(0,F_SETFL,fl | O_NONBLOCK);
}
非阻塞IO例子
#include <iostream>
#include <fcntl.h>
#include <unistd.h>
#include <cerrno>
#include <vector>
#include <functional>
using func_t = std::function<void (void)>;
std::vector<func_t> task_array;
void Log() {
std::cout << "这是一个日志任务\n";
}
void Mysql() {
std::cout << "这是一个数据库任务\n";
}
void Net() {
std::cout << "这是一个网络任务\n";
}
void InitTaskArray() {
task_array.push_back(Log);
task_array.push_back(Mysql);
task_array.push_back(Net);
}
void HandlerAllTask() {
for(auto& func : task_array) {
func();
}
}
int main() {
InitTaskArray();
//1.设置对标准输入的非阻塞IO
int fl = fcntl(0,F_GETFL);
if(fl < 0) {
std::cerr << "getfl faliled\n";
return -1;
}
fcntl(0,F_SETFL,fl | O_NONBLOCK);
//2.从标准输入读取数据 ---- ctl d 文件结尾
while(true) {
std::cout << ">>>";
fflush(stdout);
char buffer[256] {0};
ssize_t n = read(0,buffer,sizeof(buffer) - 1);
if(n > 0) {
buffer[n - 1] = 0;
std::cout << "读取到的内容: " <<buffer << std::endl;
} else if(n == 0) {
std::cout << "读到了文件结尾\n";
break;
} else if(n < 0) {
//非阻塞IO时,读写条件没就绪也会出错返回但是错误码被设置成EAGAIN
if(errno & EAGAIN) {
//std::cout << "数据没有准备好\n";
//数据没准备好
sleep(1);
HandlerAllTask();
continue;
} else if(errno & EINTR) { //可能读取被信号打断
continue;
}
} else {
std::cerr << "读数据出错\n";
return -1;
}
}
return 0;
}
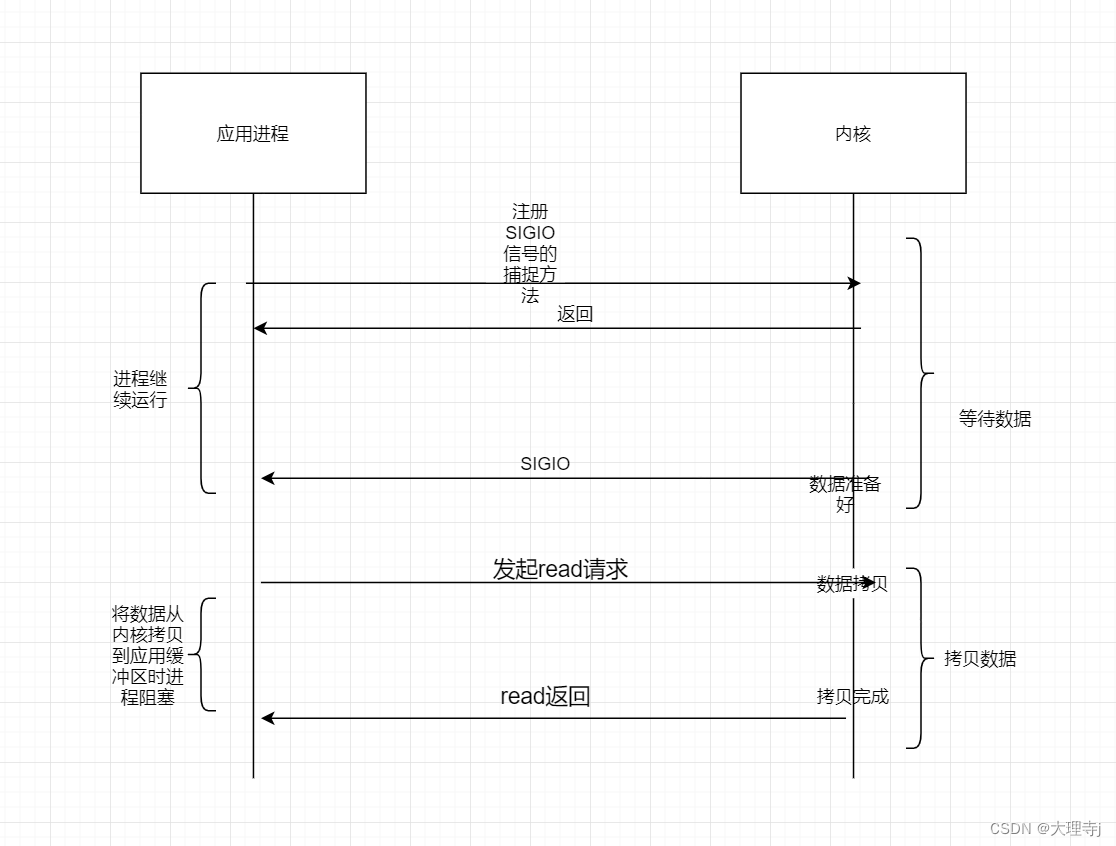
信号驱动IO
🚀信号驱动IO:就是内核将数据准备好的时候给应用进程发送SIGIO信号,通知进程进行IO操作,所以进程要对SIGIO信号进行捕捉。
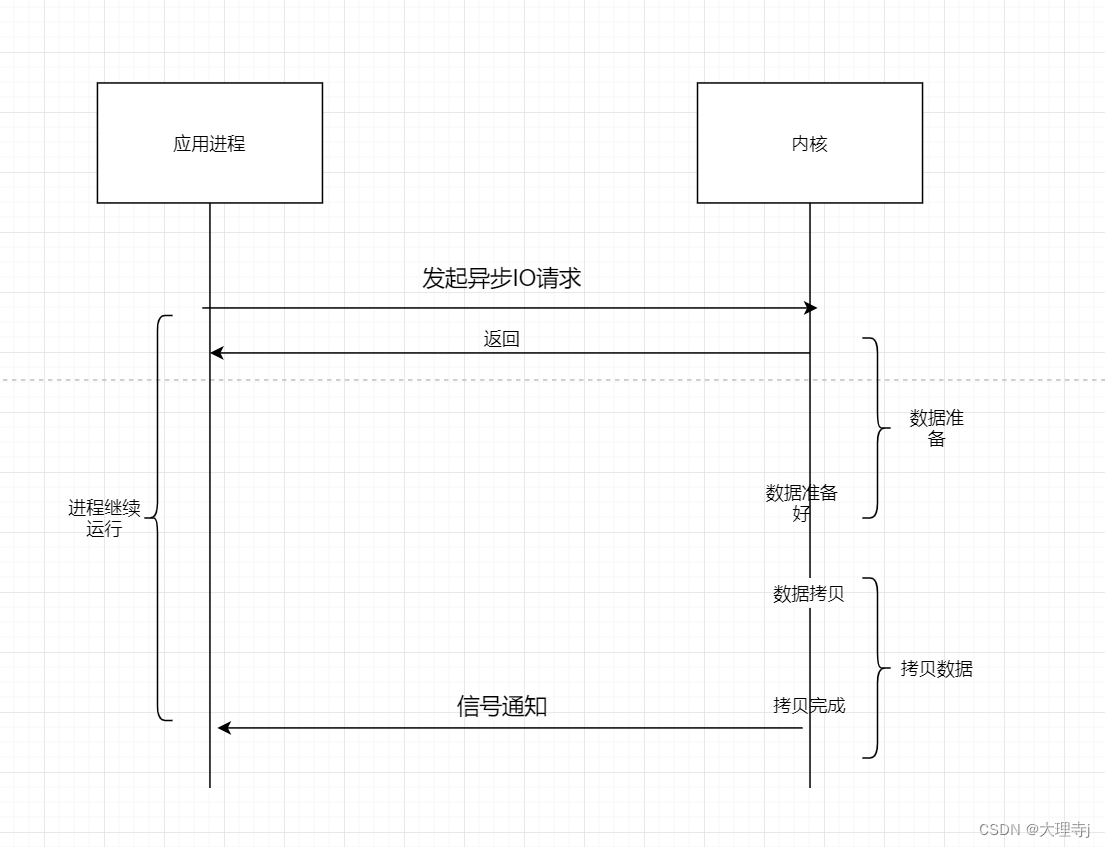
异步IO
🚀异步IO与信号驱动IO很像,区别就是进程指发起IO事件,但真正的IO过程由内核完成,将数据拷贝成功后回像进程发送信号,通知进程。与信号驱动IO区别就是进程收到信号后不用自己调用read读取,而是收到信号时表明数据拷贝已经完成。
多路转接
🚀IO = 等待 + 数据拷贝,多路转接是将两个部分分开来做,由专门的系统调用来进行IO事件就绪的等待工作并且一个可以等待多个文件描述符,当事件就绪时会返回给应用进程,这时应用进程在去进行read/write进行数据拷贝,由于多路转接方案,一次可以等待多个文件描述符,所以在任意时刻事件准备就绪的概率更大,所以IO效率更高。
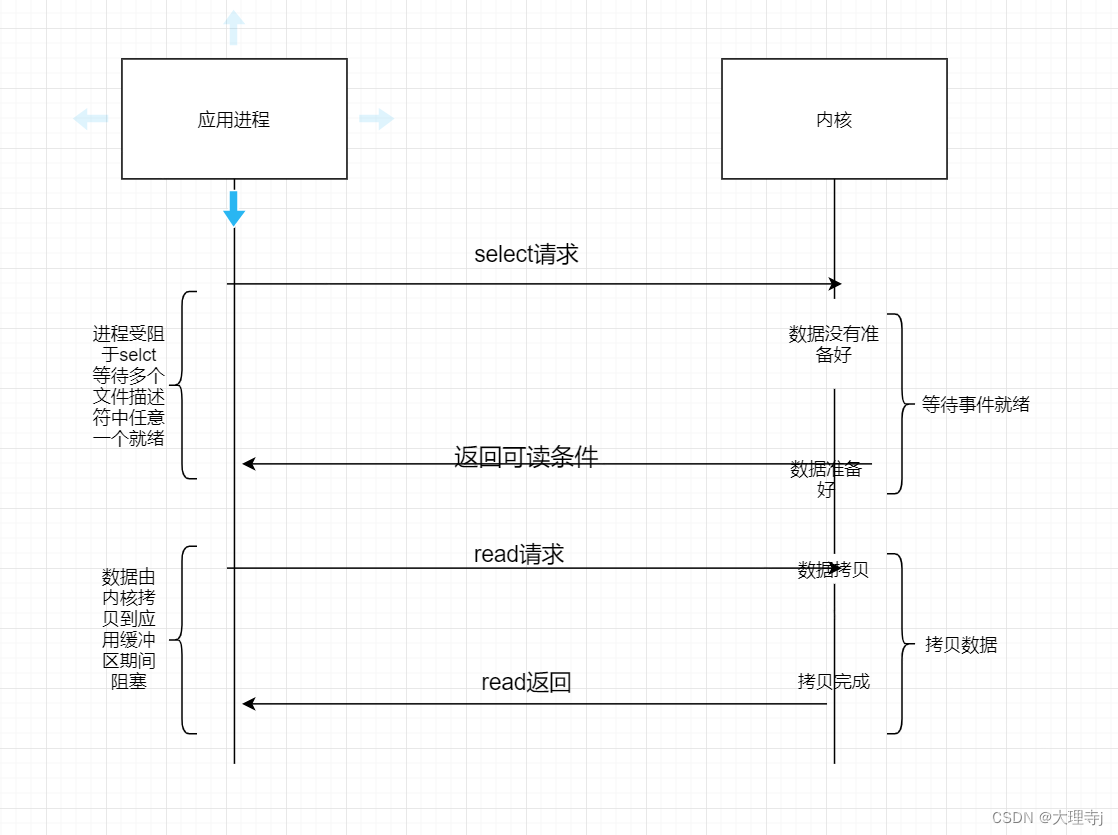
selct
🚀selct是Linux下实现多路转接的一个函数模型。
认识接口
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
-
nfds:值为等待的多个文件描述符中最大的那个值加一。
-
readfds:关心读事件的文件描述符集合
🚀fd_set:是一个位图结构,其每个比特位的位置就表示是哪个文件描述符,内容设置为1,就表示关心这个文件描述符的读/写/异常事件。
-
writefds:关心写事件的文件描述符集合
-
exceptfds:关心异常事件的文件描述符集合
-
timeout:设置select多长事件轮询一次

🚀如果timeval中两个字段设置为0,表示非阻塞轮询方式。如果设定了某个事件,表示以设置的时间间隔进行轮询。将该字段设为nullptr表示阻塞式等待。
🚀FD_CLR:不再关心fd的事件
🚀FD_ISSET:判断位图中是否包含fd
🚀FD_SET:将fd设置进位图,让select关心其事件
🚀FD_ZERO:清空整个位图
注意:select的后四个参数都是输入输出型参数,对于三个位图结构:调用select时表明用户告诉内核想让内核关心哪些文件描述的哪些事件,select返回时,表明让内核关心的哪些文件描述符的哪些事件已经就绪。也就是说在每次返回时都会对我们调用前设置的位图结构更改,所以每次调用前都要重新设置位图结构,从而也就导致第一个参数也要跟着改变。
struct timeval* timeout:当被设置为某个时间间隔后,当事件就绪select返回时,其值会被设置为剩余时间。
select返回值
🚀1.大于0,返回的是包含在三个就绪事件中的文件描述符的数量。
🚀2.等于0,timeout字段被设置,表示经过timeout时间没有事件就绪,返回一次。
🚀3.小于0,select出错
基本使用
🚀下面的代码中由于没有指定应用层协议,所以数据读取和发送是不正确的,在后面分享的epoll中,会制定应用层协议,进行正确的读取和发送。
代码仓库: select
select使用特点
🚀可监控的文件描述符数量取决于sizeof(fd_set),不同的系统可能不同,fd_set作为一个数据类型那么其大小就是确定的,sizeof(fd_set)*8表示select能监控的最多文件描述符数量。
🚀将fd加入到select的监控集合后,还有另开辟一个数组来保存设置进select监控集中的fd。
🚀另开辟数组保存fd的原因:1.select返回后,array作为源数据进行FD_ISSET判断,判断某个fd是否在返回的fd_set集合中。2.select返回后会把以前加入的但并无事件发生的fd清空,则每次开始select前都要重新从array取得fd逐一加入(FD_ZERO最先),扫描array的同时取得fd最大值maxfd,用于select的第一个参数。
缺点
🚀每次调用select, 都需要手动设置fd集合, 从接口使用角度来说也非常不便
🚀每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时比较大
🚀同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也比较大
🚀在应用层当select返回时,也要一次遍历array中的所有fd,判断fd相关事件是否就绪
🚀select支持的文件描述符数量太小,相比于一个进程能够管理的文件描述符数量。
poll
认识接口
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
🚀第一个参数是要用户传递一个数组进去,数组的每个元素为struct pollfd结构体,内容包括fd,告诉内核要关心的事件events,内核告诉用户哪些事件已经就绪revents。
events的常用选项:
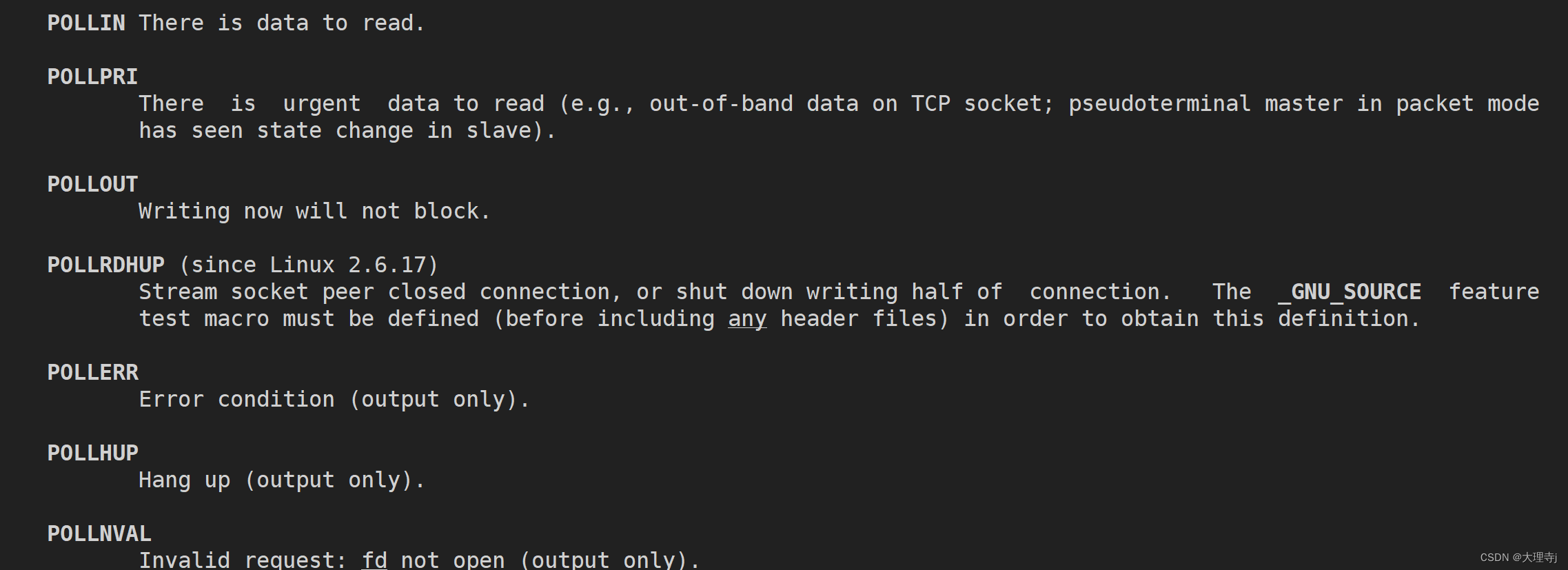
🚀第二个参数为数组中有效元素的个数。
🚀第三个参数是超时时间:
大于0:经过timeout时间的等待没有时间就绪,就返回。
等于0:没有时间就绪直接返回。
-1:阻塞方式等待。
对select的改善
🚀1.相对于select而言,poll可以关心的文件描述符数量没有上限。
🚀2.poll的pollfd参数做到了输入输出参数分离,意味着不用用户在每次调用poll函数之前都要重新设置要让内核关心哪些fd上的哪些事件。
缺点
🚀1.和select一样,每次都需要将pollfd结构由用户态拷贝到内核态,当数量较多时开销比较大。
🚀2.每次调用poll时,在内核中都要对传递进来的fd进行遍历,在fd很多时开销较大。
🚀3.每次poll返回时,用户也要对pollfd数组进行遍历,fd数量很多时,开销比较大。
🚀4.同时连接的大量客户端在任意时刻可能只有很少的处于就绪状态,因此随着监视的文件描述符数量的增多,其效率会有所下降。