Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2.相关工作
2.1. 图像生成
2.2. 图像标记化(tokenization)
2.3. 图像到图像生成
2.4. 文本到图像生成
3. 方法
3.1. 场景表示和标记化
3.2. 在标记空间中贴合人类强调
3.3. 面部感知矢量量化(VQ)
3.4. 场景空间中的人脸强调
3.5. 目标感知矢量量化
3.6. 基于场景的 transformer
3.7. 无分类器指导 transformer
4. 实验
4.1. 数据集
4.2. 指标
4.3. 与之前的工作比较
4.4. 基线
4.5. 人工评估结果
4.6. FID比较
4.7. 分布外生成
4.8. 场景可控性
4.9. 场景编辑和锚定
4.10. 通过可控性讲故事
4.11. 消融研究
5. 结论
参考
S. 总结
S.1 主要思想
S.2 方法
S.3 应用
0. 摘要
最近的文本到图像生成方法提供了文本和图像域之间简单但令人兴奋的转换功能。 虽然这些方法逐渐提高了生成的图像保真度和文本相关性,但几个关键差距(限制了应用和质量)仍未得到解决。 我们提出了一种新颖的文本到图像方法,通过以下方式解决这些差距:(i)启用与场景形式的文本互补的简单控制机制,(ii)引入通过在关键图像区域(面部和显着物体)上采用特定领域知识来显着改善标记化过程的元素 ,以及(iii)把无分类器指导调整为 transformer 用例。 我们的模型实现了最先进的 FID 和人类评估结果,解锁了生成分辨率为 512*512 像素的高保真图像的能力,显着提高了视觉质量。 通过场景可控性,我们引入了几种新功能:(i)场景编辑,(ii)锚定场景文本编辑,(iii)克服分布外文本提示,以及(iv)故事插图生成 。
1. 简介
“诗人在能够用语言描述画家瞬间描绘的事物之前,会被睡眠和饥饿所征服。”
与达芬奇的这句话类似 [27],“一图胜千言” 的表达方式在不同的语言和时代中得到了重复[14,1,25],暗示从人的角度,图像比文本具有更强的表现力。 毫不奇怪,随着最近通过大型模型和数据集进行文本到图像建模的成功,文本到图像生成的任务越来越受到关注。 这种在文本和图像领域之间轻松架起桥梁的新功能使公众能够接触到新形式的创造力。
虽然当前的方法提供了文本和图像域之间的简单但令人兴奋的转换,但它们仍然缺乏几个关键方面:
- 可控性。 大多数模型接受的唯一输入是文本,限制任何输出仅由文本描述控制。 虽然某些视角可以用文本控制,例如样式或颜色,但其他视角例如结构、形式或排列最多只能进行松散的描述[46]。 这些缺乏控制的视角传达了随机性和用户对图像内容和上下文影响较弱的概念 [34]。 [69] 建议控制文本之外的元素,但它们的使用仅限于受限制的数据集,例如时尚单品或面孔。 [23] 的早期工作建议以边界框的形式进行粗略控制,从而产生低分辨率图像。
- 人类的感知。 虽然生成图像是为了匹配人类的感知和注意力,但生成过程不包含任何相关的先验知识,导致生成和人类注意力之间几乎没有相关性。 这种差距的一个明显例子可以在人和面部生成中观察到,其中从人类角度来看面部像素的重要性与应用于整个图像的损失之间存在不一致 [28, 66]。 这种差距也与动物和显着物体有关。
- 质量和分辨率。 尽管连续提出的方法的质量逐渐提高,但以前最先进的方法仍然仅限于 256*256 像素的输出图像分辨率 [45, 41]。 替代方法提出了一个超分辨率网络,但其结果是不太令人满意的视觉和定量结果 [12]。 质量和分辨率密切相关,因为扩展到 512*512 的分辨率需要比 256*256 更高的质量和更少的伪影。
在这项工作中,我们引入了一种新颖的方法,它成功地解决了这些关键差距,同时在文本到图像生成的任务中获得了最先进的结果。 我们的方法提供了一种与文本互补的新型控制,实现新一代功能,同时提高结构一致性和质量。 此外,我们提出与人类偏好相关的显式损失,显着提高图像质量,打破常见的分辨率障碍,从而产生分辨率为 512*512 像素的结果。
我们的方法由自回归 transformer 组成,除了传统使用文本和图像标记之外,我们还对从分割图派生的可选控制场景标记引入隐式条件。 在推理过程中,分割标记要么由 transformer 独立生成,要么从输入图像中提取,从而提供对生成图像施加额外约束的自由。 与许多基于 GAN 的方法 [24,62,42] 中采用的使用分割作为显式条件的常见做法相反,我们的分割标记提供了隐式条件,即生成的图像和图像标记不限于使用分割信息,因为将它们联系在一起没有损失。 在实践中,这有助于模型生成各种样本,从而产生受输入分割限制的不同结果。 我们展示了该方法除了可控性之外还提供的新功能,例如(i)复杂场景生成(图 1),(ii)分布外生成(图 3),(iii)场景编辑(图 4)和 (iv) 使用锚定场景进行文本编辑(图 5)。
虽然大多数方法依赖于与人类感知无关的损失,但这种方法在这方面有所不同。 我们使用两个改进的矢量量化变分自动编码器(Vector-Quantized Variational Autoencoders,VQ-VAE)对图像和场景标记进行编码和解码,并计算针对与人类感知和注意力相关的特定图像区域(例如面部和显着物体)的显式损失。 这些损失通过强调特定的感兴趣区域并以网络特征匹配的形式整合特定领域的感知知识来促进生成过程。
虽然一些方法依赖于图像重新排序来进行生成后图像过滤(例如利用 CLIP [44]),但我们将 [22, 41] 所建议的用于扩散模型 [53, 20] 的无分类器指导的使用扩展到 transformer, 消除了在生成后进行过滤的需要,从而产生更快、更高质量的生成结果,更好地遵循输入文本提示。
我们提供了大量的实验来确定我们的贡献的视觉和数字有效性。
2.相关工作
2.1. 图像生成
深度生成模型的最新进展使算法能够生成高质量且自然的图像。
- 生成对抗网络(GAN)[17] 通过同时训练生成器网络 G 和鉴别器网络 D,促进在多个领域生成高保真度图像 [29,3,30,56],其中 G 被训练来欺骗 D,而 D 被训练来判断给定图像是真还是假。
- 与 GAN 同时,变分自动编码器 (VAE) [32, 57] 引入了一种基于似然的图像生成方法。
- 其他基于可能性的模型包括自回归模型 [58,43,13,8] 和扩散模型 [11,21,20]。 前者将图像像素建模为每个像素之间具有自回归依赖性的序列,而后者则通过渐进的去噪过程来合成图像。 具体来说,采样从噪声图像开始,该图像被迭代去噪,直到执行所有去噪步骤。 将这两种方法直接应用于图像像素空间可能具有挑战性。 因此,最近的方法要么通过矢量量化 (VQ) VAE [59] 将图像压缩为离散表示 [13, 59],要么对图像分辨率进行下采样 [11, 21]。
- 我们的方法基于离散图像表示的自回归建模。
2.2. 图像标记化(tokenization)
基于离散表示的图像生成模型 [59,45,47,12,13] 遵循两阶段训练方案。 首先,训练图像标记器来提取离散图像表示。 在第二阶段,生成模型在离散潜在空间中生成图像。
- 受矢量量化(Vector Quantization,VQ)技术的启发,VQ-VAE [59] 学习通过执行在线聚类来提取离散的潜在表示。
- VQ-VAE-2 [47] 提出了一种由在多个尺度上运行的 VQ-VAE 模型组成的分层架构,与像素空间生成相比,能够实现更快的生成。
- DALL-E [45] 文本到图像模型使用 dVAE,dVAE 使用gumbel-softmax [26, 39],放松了 VQ-VAE 的在线聚类。
- 最近,VQGAN [13] 在 VQ-VAE 重建任务的基础上添加了对抗性和感知损失 [68],产生了更高质量的重建图像。
- 在我们的工作中,我们通过向特定图像区域(例如面部和显着物体)添加感知损失来修改 VQGAN 框架,这进一步提高了生成图像的保真度。
2.3. 图像到图像生成
从分割图或场景生成图像可以被视为条件图像合成任务 [71,38,24,61,62,42]。 具体来说,这种形式的图像合成可以更好地控制所需的输出。
- CycleGAN [71] 训练了从一个域到另一个域的映射函数。UNIT [38] 将两个不同的域投影到共享的潜在空间中,并使用每个域的解码器来重新合成所需域中的图像。 两种方法都不需要域之间的监督。
- pix2pix [24] 使用条件 GAN 和监督重建损失。 pix2pixHD [62] 通过改进网络架构提高输出图像分辨率来改进后者。
- SPADE [42]引入了空间自适应归一化层,它提高了归一化层中丢失的信息。 [15] 通过受人脸生成方法 [16] 启发的预训练人脸嵌入网络,将人脸细化引入 SPADE。
- 与前面提到的不同,我们的工作以文本和分割的联合作为条件,从而实现双域可控性。
2.4. 文本到图像生成
文本到图像生成 [64,72,54,65,67,45,12,41,70] 专注于从独立的文本描述生成图像。
- 初步的文本到图像方法将基于 RNN 的 DRAW [18] 限制在文本 [40] 上。
- 文本条件 GAN 提供了额外的改进 [48]。
- AttnGAN [64] 引入了一个注意力组件,允许生成器网络关注文本中的相关单词。
- DM-GAN [72] 引入了动态记忆组件,而 DF-GAN [54] 采用了融合块,将文本信息融合到图像特征中。
- 对比学习进一步改善了 DM-GAN [65] 的结果,而 XMCGAN [67] 使用对比学习来最大化图像和文本之间的互信息。
- DALL-E [45] 和 CogView [12] 在文本和图像标记上训练了自回归 transformer [60],在 MS-COCO 数据集上展示了令人信服的零样本能力。
- GLIDE [41] 使用以图像为条件的扩散模型。 受到高质量无条件图像生成模型的启发,GLIDE 采用带或不带分类器网络的引导推理来生成高保真图像。
- LAFITE [70] 采用预先训练的 CLIP [44] 模型将文本和图像投影到同一潜在空间,在没有文本数据的情况下训练文本到图像模型。
- 与 DALL-E 和 CogView 类似,我们在文本和图像标记上训练自回归 transformer 模型。 我们的主要贡献是以场景的形式引入额外的控制元素,改进标记化过程,并对 transformer 采用无分类器指导。
3. 方法
我们的模型根据文本输入和可选的场景布局(分割图)生成图像。 正如我们的实验所证明的,通过以场景布局为条件,我们的方法提供了一种新形式的隐式可控性,提高了结构一致性和质量,并遵循人类偏好(根据我们的人类评估研究评估)。 除了基于场景的方法之外,我们还通过更好地表示标记空间来扩展我们提高总体质量和感知质量的愿望。 我们对标记化过程进行了一些修改,强调对人类视角中越来越重要的方面的认识,例如面部和显着物体。 为了避免生成后过滤,并进一步提高生成质量和文本对齐,我们采用无分类器指导。
接下来,我们详细概述所提出的方法,包括(i)场景表示和标记化,(ii)在具有显式损失的标记空间中关注人类偏好,(iii)基于场景的 transformer ,以及(iv)无分类器指导 transformer。 下面不对在此方法之前常用的方面进行详细说明,而所有元素的具体设置可以在附录中找到。
3.1. 场景表示和标记化
该场景由三个互补的语义分割组(全景、人类和面部)的联合组成。 通过组合三个提取的语义分割组,网络学习生成语义布局,并以此为条件生成最终图像。 因为场景组内类别的选择以及组本身的选择是人类偏好和感知的先验,所以语义布局以与人类偏好相关的隐式形式提供了额外的全局上下。 我们认为这种形式的调节是隐式的,因为网络可能会忽略任何场景信息,并生成仅以文本为条件的图像。 我们的实验表明文本和场景都牢牢地控制着图像。
为了创建场景标记空间,我们采用 VQ-SEG:一种用于语义分割的改进型 VQ-VAE,它建立在 [13]中用于语义分割的 VQ-VAE 的基础上。 在我们的实现中,VQ-SEG 的输入和输出是 m 个通道,表示所有语义分割组的类别数 m = m_p + m_h + m_f + 1,其中 m_p、m_h、m_f 分别是全景分割 [63]、人类分割 [35] 和用 [5] 提取的人脸分割的类别数。 附加通道是分隔不同类和实例的边缘图。 边缘通道为同一类的相邻实例提供分离,并强调具有高重要性的稀缺类,因为边缘(周长)比像素(区域)更不偏向于更大的类别。
3.2. 在标记空间中贴合人类强调
当使用 transformer 生成图像时,我们观察到图像质量的固有上限,源于标记化重建方法。 换句话说,VQ 图像重建方法的质量限制转移为 transformer 生成的图像的质量限制。 为此,我们对分割和图像重建方法进行了一些修改。 这些修改是强调(特定区域感知)和感知知识(特定任务预训练网络上的特征匹配)形式的损失。
3.3. 面部感知矢量量化(VQ)
虽然使用场景作为附加形式的条件为人类偏好提供了隐式先验,但我们以附加损失的形式进行显式强调,显式针对特定图像区域。
我们在预先训练的人脸嵌入网络的激活上采用特征匹配损失,引入对人脸区域的 “感知” 和额外的感知信息,从而激励高质量的人脸重建。
在训练人脸感知 VQ(表示为 VQ-IMG)之前,使用为 VQ-SEG 提取的语义分割信息来定位人脸。 然后在人脸感知 VQ 训练阶段使用人脸位置:对每张来自真实图像和通过人脸嵌入网络重建的图像运行最多 k_f 个人脸。人脸损失可以表述如下:
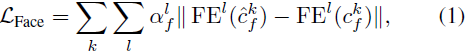
其中索引 l 用于表示人脸嵌入网络 FE [6] 特定层的空间激活的大小,而求和则在大小为 112*112, 56*56, 28*28, 7*7, 1*1 的每个块的最后层上运行 (1*1 是最上面块的大小),
![]()
分别是图像中 k_f 个人脸中的 k 个重建和真实人脸裁剪,
![]()
是每个层归一化超参数,L_Face 是添加到 [13] 定义的 VQGAN 损失中的人脸损失。
3.4. 场景空间中的人脸强调
在训练 VQ-SEG 网络时,我们观察到重建场景中表示面部部位(例如眼睛、鼻子、嘴唇、眉毛)的语义分割频繁减少。 这种效果并不奇怪,因为每个面部部分在场景空间中所占的像素数量相对较少。 一个简单的解决方案是采用更适合类别不平衡的损失,例如焦点损失(focal loss)[36]。 然而,我们并不希望提高稀有且不太重要的类别的重要性,例如水果或牙刷。 相反,我们(1)在分割面部部位类别上采用加权二元交叉熵面部损失,强调面部部位的更高重要性,以及(2)将面部部位边缘作为上述语义分割边缘图的一部分。 加权二元交叉熵损失可以表述如下:
![]()
其中 s 和 ^s 分别是输入和重建的分割图,α_cat 是每类别权重函数,BCE 是二元交叉熵损失,L_WBCE 是由 [13] 定义的添加到条件 VQ-VAE 损失中的加权二元交叉熵损失 。
3.5. 目标感知矢量量化
我们概括并扩展了面部感知 VQ 方法,以提高对全景分割类别中定义为 “事物” 的对象的感知和感知知识。 我们没有使用专门的人脸嵌入网络,而是采用在 ImageNet [33] 上训练的预训练 VGG [52] 网络,并引入代表重建图像和地面实况图像的对象裁剪之间感知差异的特征匹配损失 。 通过对图像裁剪运行特征匹配,我们只需向 VQ-IMG 添加分别添加了额外的下采样和上采样层的编码器和解码器,就可以将输出图像分辨率从 256*256 提高。 与等式 1 类似,损失可以表述为:
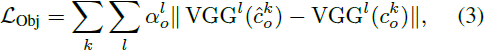
其中,
![]()
分别是重建的和输入的对象裁剪,VGG^l 是预训练 VGG 网络中第 l 层的激活,
![]()
是每层归一化超参数,L_Obj 是等式 1 中定义的添加到 VQ-IMG 损失的对象感知损失。
3.6. 基于场景的 transformer
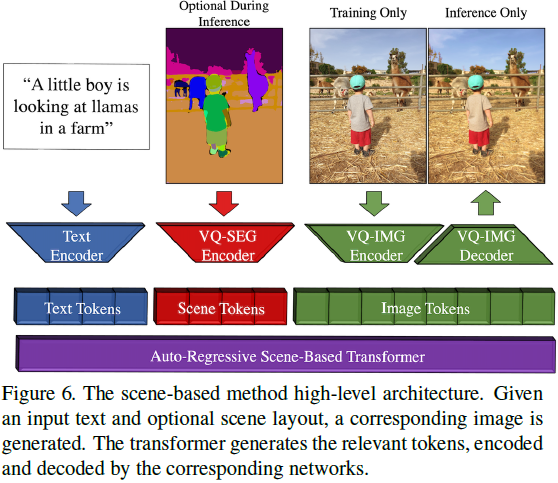
该方法依赖于具有三个独立的连续标记空间(文本、场景和图像)的自回归 transformer,如图 6 所示。标记序列的组成:由 BPE [50] 编码器编码的 n_x 个文本标记组成,由 VQ-SEG编码的 n_y 个场景标记 ,以及由 VQ-IMG 编码或解码的 n_z 个图像标记。
在训练基于场景的转换器之前,使用相应的编码器提取与 [文本、场景、图像] 三元组相对应的每个编码标记序列,生成一个由以下部分组成的序列:
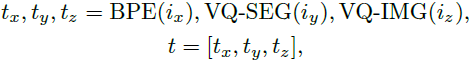
其中 i_x,i_y,i_z 分别为输入文本、场景和图像。
![]()
![]()
d_x 为输入文本序列的长度,h_y,w_y,h_z,w_z 分别是场景和图像输入的高度和宽度,BPE 是字节对编码(Byte Pair Encoding,BPE)编码器,t_x,t_y,t_z 分别是文本、场景和图像输入标记,t 是完整的标记序列。
3.7. 无分类器指导 transformer
受到无条件图像生成模型高保真度的启发,我们采用无分类器指导 [9, 22,44]。 无分类器引导是将无条件样本引导到条件样本方向的过程。 为了支持无条件采样,我们对 transformer 进行微调,同时以概率 p_CF 用填充标记随机替换文本提示。 在推理过程中,我们生成两个并行的标记流:一个以文本为条件的条件标记流,以及一个以用填充标记初始化的空文本流为条件的无条件标记流。 对于 Transformer,我们对 Logit 分数应用无分类器指导:
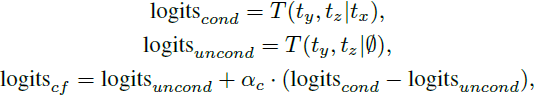
其中,Ø 是空文本流,logits_cond 是条件标记流输出的 logit 分数,logits_uncond 是无条件标记流输出的 logit 分数,α_c 是指导尺度,logits_cf 是用于采样下一个场景或图像标记的指导 logit 分数,T 是一个基于 GPT-3 [4] 架构的自回归 transformer 。 请注意,由于使用自回归 transformer,我们使用 logits_cf 进行一次采样并将相同的标记(图像或场景)提供给条件和无条件流。
4. 实验

我们的模型在基于人类和数值指标的比较中取得了最先进的结果。 图 2 提供了支持定性优势的样本。此外,我们还展示了该方法的新形式的可控性可能带来的新的创造能力。 最后,为了更好地评估每个贡献的效果,提供了一项消融研究。
使用 40 亿个参数 transformer 进行实验,生成 256 个文本标记、256 个场景标记和 1024 个图像标记的序列,然后将其解码为分辨率为 256*256 或 512*512 像素的图像(取决于选择的模型)。
4.1. 数据集
基于场景的 Transformer 在 CC12m [7]、CC [51] 以及 YFCC100m [55] 和 Redcaps [10] 的子集上进行训练,总计 3500 万个文本图像对。 除非另有说明,否则使用 MSCOCO [37]。 VQ-SEG 和 VQ-IMG 在 CC12m、CC 和 MS-COCO 上进行训练。
4.2. 指标
文本到图像生成的目标是从人类的角度生成高质量且文本对齐的图像。 人们提出了不同的指标来模仿人类的观点,其中一些指标被认为比其他指标更可靠。 在评估图像质量和文本对齐时,我们认为人工评估是最高权威,并依靠 FID [19] 来增加评估可信度并处理人工评估不适用的情况。 我们不使用 IS [49],因为它不足以进行模型评估 [2]。
4.3. 与之前的工作比较
文本到图像生成的任务不包含绝对的基本事实,因为特定的文本描述可以应用于多个图像,反之亦然。 这限制评估指标评估图像的分布,而不是特定图像的分布,因此我们采用 FID [19] 作为我们的次要指标。
4.4. 基线
我们在可能的情况下使用 FID 指标和人工评估器 (AMT) 将我们的结果与几种最先进的方法进行比较。
- DALL-E [45] 提供强大的零样本能力,同样采用具有 VQ-VAE 标记器的自回归 transformer。 我们使用 4B 参数训练 DALL-E 的重新实现,以便进行人类评估,并使用相同的 VQ 方法 (VQGAN) 公平地比较两种方法。
- GLIDE [41] 采用基于扩散的 [53] 方法和无分类器指导 [22],展示了比 DALL-E 大大改进的结果。
- 我们还提供了与 CogView [12]、LAFITE [70]、XMC-GAN [67]、DM-GAN(+CL) [65]、DF-GAN [54]、DM-GAN [72]、DFGAN [54] 和 AttnGAN [64] 的 FID 比较。
4.5. 人工评估结果
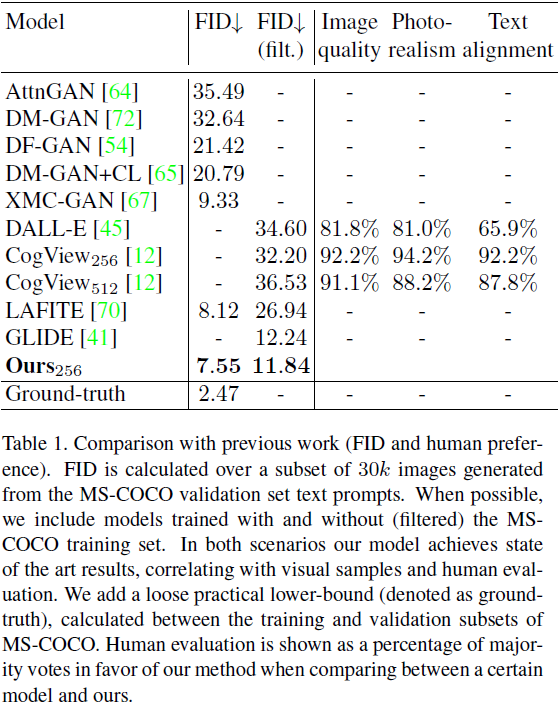
表 1 中提供了使用以前的方法进行的人工评估。
- 在每种情况下,人工评估者都需要在由所比较的两个模型生成的两个图像之间进行选择。
- 这两个模型在三个方面进行比较:(i)图像质量,(ii)真实感(哪个图像看起来更真实),以及(iii)文本对齐(哪个图像与文本最匹配)。
- 每个问题都使用 500 个图像对进行调查,其中 5 个不同的评估者回答每个问题,对于给定的比较,每个问题总计 2500 个实例。
- 我们将 256*256 模型与 DALL-E [45] 和 CogView [12] 的 256*256 模型的重新实现进行比较。
- CogView 的 512*512 模型与我们对应的模型进行了比较。
- 在将某个模型与我们的模型进行比较时,结果以支持我们的方法的多数票的百分比表示。 与这三种方法相比,我们的方法在各方面都获得了明显更高的票数。
4.6. FID比较
FID 是根据 MS-COCO 验证集文本提示生成的 30k 图像子集计算得出的,无需重新排序,并在表 1 中提供。
- 评估的模型分为两组:使用 MS-COCO 训练集训练和不使用 MS-COCO 训练集(表示为过滤后的模型)训练。在这两种情况下,我们的模型都实现了最低的 FID。
- 此外,我们还提供了在 MS-COCO 的训练和验证子集之间计算的松散实际下界(practical lower-bound)(表示为 ground-truth)。
- 由于 FID 结果接近较小的数字,了解可能的实际下界是很有趣的。
4.7. 分布外生成
仅依赖文本输入的方法更局限于在训练分布内生成,如 [41] 所示。
- 生成不寻常的对象和场景可能具有挑战性,因为某些对象与特定结构密切相关,例如四足猫或圆轮汽车。 场景也是如此。
- “老鼠猎杀狮子” 很可能不是在数据集中容易找到的场景。 通过以简单草图形式的场景作为条件,我们能够关注这些不常见的物体和场景,如图 3 所示,尽管事实上某些物体(老鼠、狮子)在我们的场景的类别中并不存在。 我们通过使用在某些方面可能接近的类别(大象而不是老鼠,猫而不是狮子)来解决类别差距。
- 实际上,对于不存在的类别,可以使用多个类别来代替。




4.8. 场景可控性
图 1、3、4、5 和附录中提供了我们的 256*256 和 512*512 模型的样品。 除了仅从文本生成高保真图像之外,我们还演示了场景式图像控制和保持各生成之间一致性的适用性。
4.9. 场景编辑和锚定
我们引入了从现有或编辑的场景生成图像的新功能,而不是如 [45] 所示编辑图像的某些区域。 在图 4 中,考虑了两种情况。 在这两种情况下,语义分割都是从输入图像中提取的,并用于根据输入文本重新生成图像。
- 在顶行中,对场景进行编辑,将 “天空” 和 “树” 类别替换为 “海洋”,将 “草”类别替换为 “沙子”,从而生成符合新场景的图像。
- 一条巨狗的简单草图被添加到底行的场景中,从而生成与新场景相对应的生成图像,而文本没有任何变化。
图 5 展示了对现有图像和场景生成新解释的能力。 从给定图像中提取语义分割后,我们根据输入场景和编辑的文本重新生成图像。
4.10. 通过可控性讲故事
为了演示利用场景控制进行故事插图的适用性,我们编写了一个儿童故事,并使用我们的方法对其进行了插图。 在这种情况下,使用简单草图作为附加输入的主要优点是(i)作者可以将他们的想法转化为绘画或逼真的图像,同时不易受到文本到图像生成的 “随机性” 的影响,以及(ii)提高了各生成之间的一致性。
4.11. 消融研究
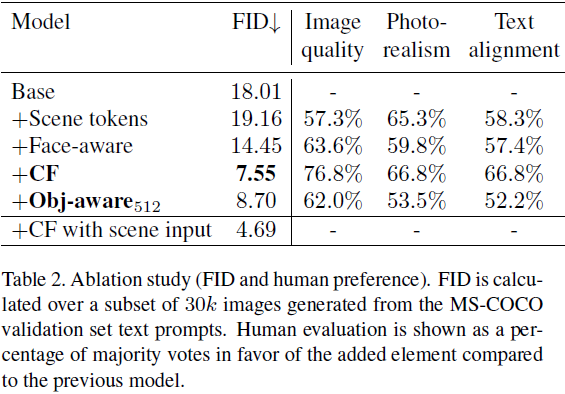
表 2 中提供了人类偏好和 FID 的消融研究, 评估我们不同贡献的有效性。
- 这两项研究的设置与之前的工作(第 4.3 节)进行的比较类似。 每一行对应于使用附加元素训练的模型,与没有根据人类偏好添加特定元素的模型进行比较。
- 我们注意到,虽然 256*256 模型获得了最低的 FID,但人类偏好更倾向于具有对象感知训练的 512*512 模型,尤其是在质量方面。
- 此外,我们重新检查了最佳模型的 FID,其中场景作为附加输入给出,以获得与下限之间的差距的更好概念。
5. 结论
文本到图像领域出现了大量旨在提高生成图像的总体质量和对文本的遵守的新颖方法。 虽然一些方法提出了图像编辑技术,但进展通常不是为了实现新形式的人类创造力和体验。 我们试图将文本到图像的生成发展为更具交互性的体验,人们可以感知到对生成的输出有更多的控制,从而实现讲故事等现实世界的应用。 除了提高总体图像质量之外,我们还专注于改善我们认为对人类感知至关重要的关键图像方面,例如面部和显着物体,从而使我们的方法在人类评估和客观指标方面获得更高的青睐。
参考
Gafni O, Polyak A, Ashual O, et al. Make-a-scene: Scene-based text-to-image generation with human priors[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 89-106.
S. 总结
S.1 主要思想
本文提出了一种新颖的方法,用于解决文本到图像生成的几个问题:
- 可控性。启用与场景形式的文本互补的简单控制机制。本方法由自回归 transformer 组成,除了传统使用文本和图像标记之外,还对从场景布局(分割图)派生的可选控制场景标记引入隐式条件,从而产生受输入分割限制的不同结果。
- 人类感知。使用两个改进的 VQ-VAE 对图像和场景标记进行编码和解码,并计算针对与人类感知和注意力相关的特定图像区域(例如面部和显着物体)的显式损失。 这些损失通过强调特定的感兴趣区域并以网络特征匹配的形式整合特定领域的感知知识来促进生成过程。
- 质量和分辨率。将扩散模型的无分类器指导扩展到 transformer,并结合上述方法,从而生成更高质量和分辨率的图像。
S.2 方法
场景表示和标记化。
- 场景由三个互补的语义分割组(全景、人类和面部)组成。 通过组合三个提取的语义分割组,网络学习生成语义布局,并以此为条件生成最终图像。
- 因为场景组内类别的选择以及组本身的选择是人类偏好和感知的先验,所以语义布局以与人类偏好相关的隐式形式提供了额外的全局上下文。
- 采用 VQ-SEG(用于语义分割的改进的 VQ-VAE)创建场景标记空间。
面部感知矢量量化。在预先训练的人脸嵌入网络的激活上,采用真实人脸和通过人脸嵌入网络重建的人脸的特征匹配损失,引入对人脸区域的 “感知” 和额外的感知信息,从而激励高质量的人脸重建。
场景空间中的人脸强调。采用加权二元交叉熵面部损失,强调面部部位的更高重要性,从而避免重建场景中表示面部部位(例如眼睛、鼻子、嘴唇、眉毛)的语义分割频繁减少。
目标感知矢量量化。 采用预训练 VGG 网络,并引入代表重建图像和真实图像的对象裁剪之间的感知差异的特征匹配损失,以提高对全景分割类别中定义为 “事物” 的对象的感知和感知知识。
基于场景的 transformer。使用具有三个独立的连续标记空间(文本、场景和图像)的自回归 transformer 进行图像生成。
无分类器指导 transformer。
- 受到无条件图像生成模型高保真度的启发,本文采用无分类器指导。
- 无分类器引导是将无条件样本引导到条件样本方向的过程。
- 与先前扩散模型中基于噪声的评分不同,本文使用 transformer 获得分数。
S.3 应用
场景编辑。将 “天空” 和 “树” 类别替换为 “海洋”,将 “草”类别替换为 “沙子”,从而将场景从草地转换为沙滩。
分布外生成。生成现实中不存在的场景(例如,老鼠猎杀狮子)。通过使用在某些方面可能接近的类别(大象而不是老鼠,猫而不是狮子)进行替换来实现。
文本编辑和场景锚定。例如,基于文本引导的域自适应。
故事插图生成。 使用本文方法为故事生成插图。可使用简单草图作为附加输入,从而减少随机性,并提高生成一致性。