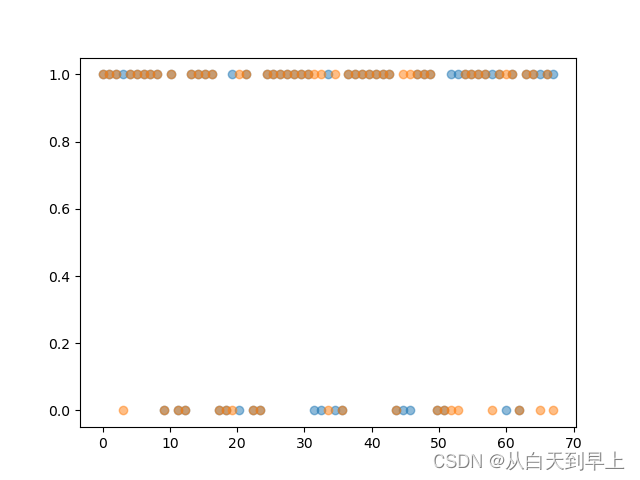
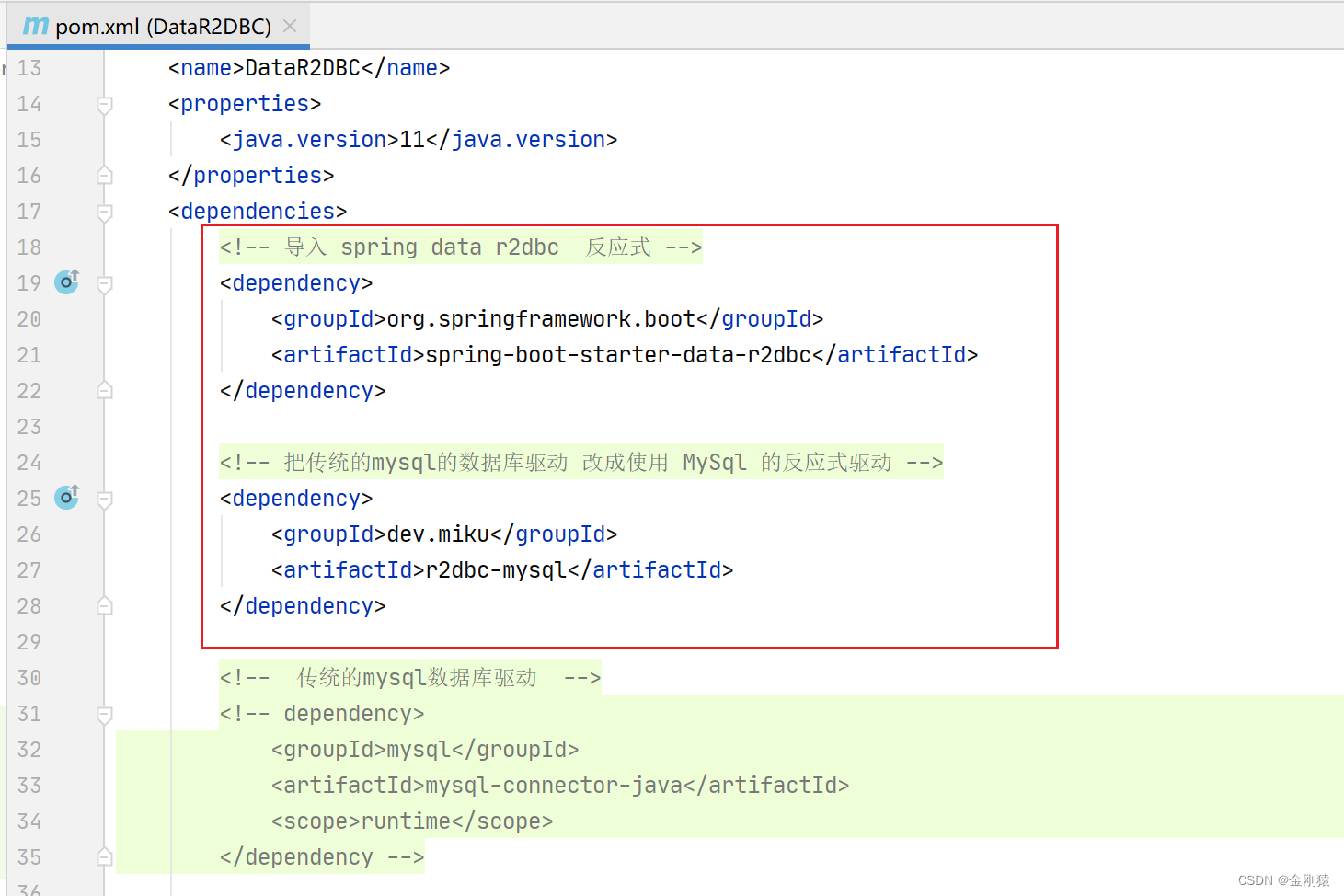
代码:
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
def train():
# 1)读取数据:
df1=pd.read_csv('horseColicTraining.txt',delimiter='\t',header=None)
df2=pd.read_csv('horseColicTest.txt',delimiter='\t',header=None)
last_column = df1.iloc[:, -1] # 获取最后一列数据
x_train1 = df1.iloc[:, :-1] # 第一个DataFrame包含除最后一列以外的所有列
y_train1 = pd.DataFrame(last_column) # 第二个DataFrame只包含最后一列
last_column1 = df2.iloc[:, -1] # 获取最后一列数据
x_test1 = df2.iloc[:, :-1] # 第一个DataFrame包含除最后一列以外的所有列
y_test1 = pd.DataFrame(last_column1) # 第二个DataFrame只包含最后一列
# 2)缺失值处理:
#3)划分数据集:
# 筛选特征值和目标值
# 4)特征工程标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train1)
# print(x_train)
x_test=transfer.transform(x_test1)
# transfer1=StandardScaler()
# y_train=transfer.fit_transform(y_train1)
# y_test=transfer.transform(y_test1)
# 二维数组
two_dimensional_array = np.array(y_train1)
# 使用flatten()函数将二维数组转换为一维数组
y_train = two_dimensional_array.flatten()
# print(y_train)
# 5)逻辑回归的预估器:
estimator=LogisticRegression(C=0.04,max_iter=10000)
estimator.fit(x_train,y_train)
# 回归系数和偏置
print('回归系数为:\n',estimator.coef_)
print('偏置为:',estimator.intercept_)
# 6)分类模型的评估
y_predict=estimator.predict(x_test)
print('测试集的预测值为:\n',y_predict)
error=estimator.score(x_test,y_test1)
print('模型预测准确率为:',error)
# 查看精确率和召回率和F1—score
report=classification_report(y_test1,y_predict,labels=[1,0],target_names=['死亡','没死'])
print(report)#precision:精确率 recall:召回率 f1-score support:数量
return y_predict,y_test1
y1,y2=train()
# print(y)
# plt.plot(np.linspace(0,67,67),y)
fig=plt.figure()
plt.scatter(np.linspace(0,67,67),y1,alpha=0.5)
plt.scatter(np.linspace(0,67,67),y2,alpha=0.5)
plt.show()结果可视化:(随便写的一个)