★ 何谓R2DBC
R2DBC 就是 JDBC 的 反应式版本, R2DBC 是 JDBC 的升级版。
R2DBC 是 Reactive Relational Database Connectivity (关系型数据库的响应式连接) 的缩写
反应式的就是类似于消息发布者和订阅者,有消息就进行推送。R2DBC中DAO接口中方法的返回值是 Flux 或 Mono
因此,反应式的 R2DBC ,是不存在 【分页】 这种情况的。
JDBC 或者 R2DBC 都是用来对数据库进行操作的
★ Spring R2DBC
Spring Data 为 JDBC 提供了 Spring Data JDBC 项目,为 R2DBC 则提供了 Spring Data R2DBC 项目。
早期Spring项目并未包含Spring R2DBC模块,而是由Spring Data R2DBC项目来提供Spring R2DBC功能。
从Spring 5.3开始,R2DBC才从Spring Data R2DBC中分离成Spring的Spring R2DBC模块。
从Spring 5.3开始, Spring为支持R2DBC单独提供了Spring R2DBC模块。
▲ 对比
传统: JDBC Spring JDBC(需要自己用JdbcTemplate实现DAO组件的实现类) Spring Data JDBC(只需提供接口)
反应式:R2DBC Spring R2DBC Spring Data R2DBC

★ 两个版本的 DatabaseClient:
- DatabaseClient 是 Spring Data R2DBC 的核心API。
- 早期 DatabaseClient 和它的内部类提供了大量的流式API来拼接SQL(非常像jOOQ),
例如通过select()方法模拟SQL的SELECT子句、通过from()方法模拟SQL的FROM子句
……但这些方法的参数都是String类型,因此这样做的意义并不大,被淘汰了。
- 从Spring Data R2DBC 1.2版本开始,推荐使用 Spring R2DBC 的 DatabaseClient
——新设计的DatabaseClient直接使用sql()方法来接受String类型的SQL语句,这样更加简单、粗暴。
★ Spring Data R2DBC的功能(完全类似于Spring Data JDBC)
SpringBoot 整合 Spring Data JDBC
- DAO接口只需继承 ReactiveCrudRepository 或 ReactiveSortingRepository,
Spring Data R2DBC能为DAO组件提供实现类。
- Spring Data R2DBC 支持方法名关键字查询、类似于 Spring Data JDBC。
- Spring Data R2DBC 支持用 @Query 定义查询语句
- Spring Data R2DBC 同样支持 DAO组件 添加自定义的查询方法。
- 类似 Spring Data JDBC,同样不支持 Example 查询 和 Specification 查询
★ Spring Data R2DBC 的映射(完全类似于Spring Data JDBC)
- 与Spring Data JDBC相同,同样默认使用“约定优于配置”的同名映射策略。同样支持如下注解:
- @Table:映射自定义的表名。
- @Column注解:映射自定义的列名
- @Id注解:修饰标识属性
- @PersistenceConstructor:修饰主构造器
★ Spring Data R2DBC的变化
- 与Spring Data JDBC不同,R2DBC中DAO接口中方法的返回值是 Flux 或 Mono
区别:Spring Data JDBC 的 Dao 接口中的方法的返回值,基本是List集合或者是单个对象。
- 当要实现自定义的查询方法时,不再使用JdbcTemplate,
而是使用DatabaseClient(相当于JdbcTemplate)。
JdbcTemplate或者是DatabaseClient,都是被封装后,用来对数据库进行操作的
【注意点】
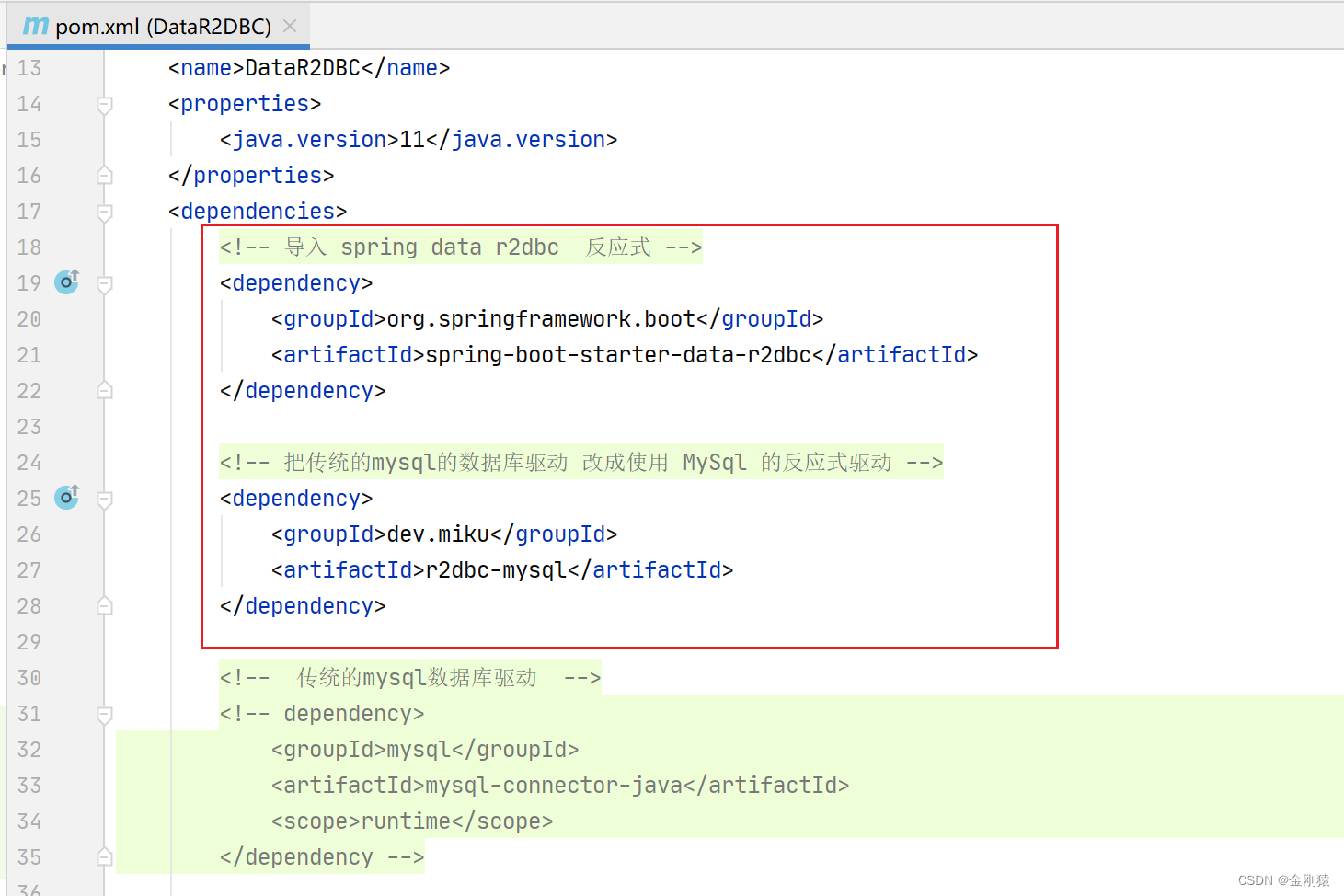
1、 如果你要使用反应式API来访问数据库,请务必使用数据库的反应式驱动,传统驱动是不行的。

把导入的依赖的截图显示下

2、 连接R2DBC的数据库的连接信息也是不同的, URL的协议不再是jdbc,而是r2dbc

3、 如果你要测试反应式DAO组件,请一定要使用block来保证执行完成。
因为:
block 是阻塞线程,一定要等待 Mono 或 flux 发布数据为止,所以这个 block 只能用在测试用例中
block 就相当于在等 消息发布者Mono 发布数据,如果没有发布数据,就一直等,阻塞,相当于把反应式又变成了同步的数据读取方式
如果要测试反应式API,可调用 block 方法来同步获取数据,因为查询可能有数据,也可能查不到数据,所以 block方法有几种:
.block():表示一定要取到值,一定要有数据 ; .blockOptional():如果取不到值,就返回一个null,或者是返回Optional
代码演示:
演示通过 R2DBC(关系型数据库的响应式连接) 反应式的 进行数据库连接查询。
上面,pom.xml 已经添加了对应的 R2DBC 依赖和反应式的数据库驱动,然后配置文件也改成了R2DBC 模式
接下来就是写 DAO 组件了。
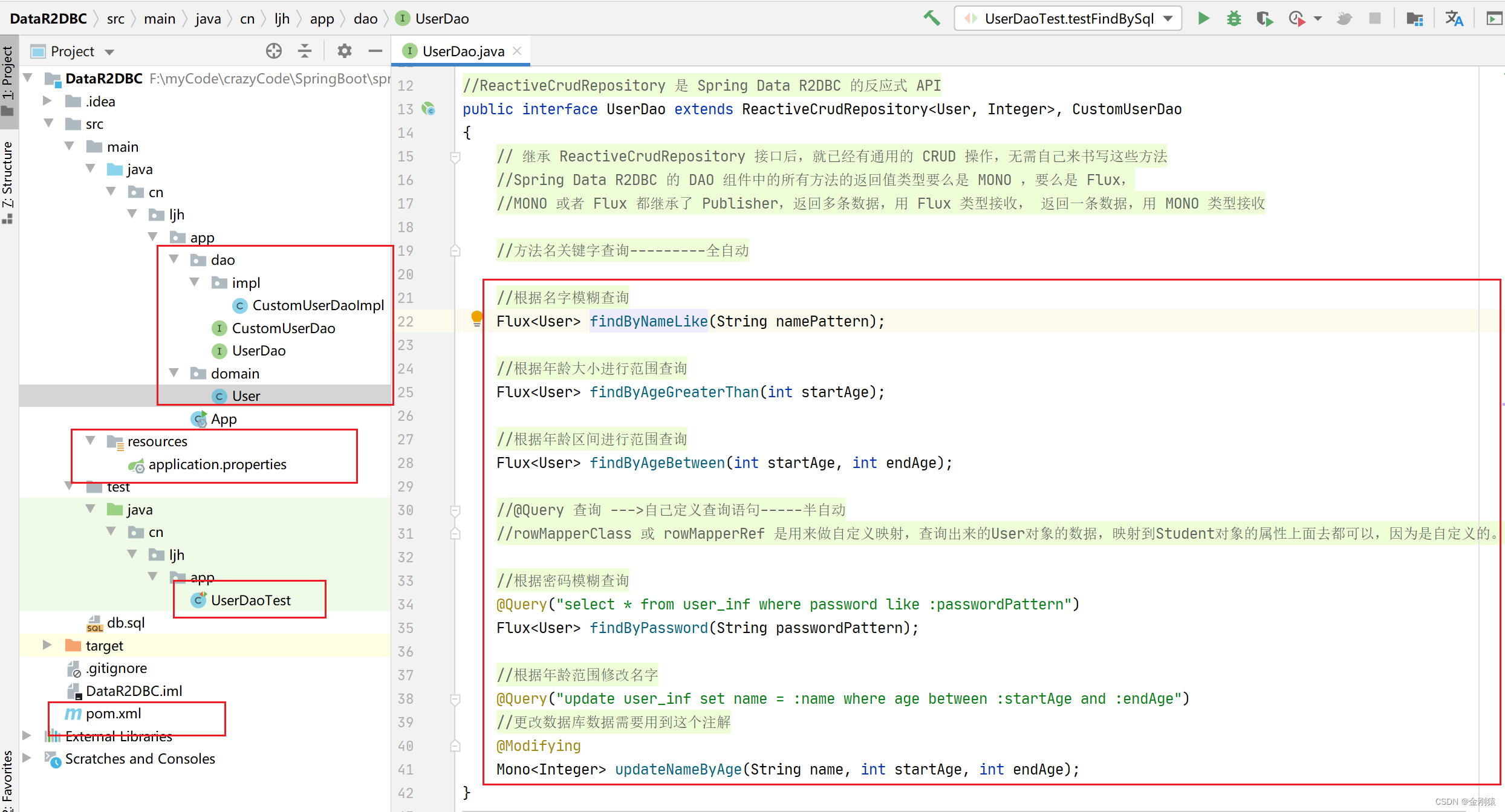
自定义的Dao组件
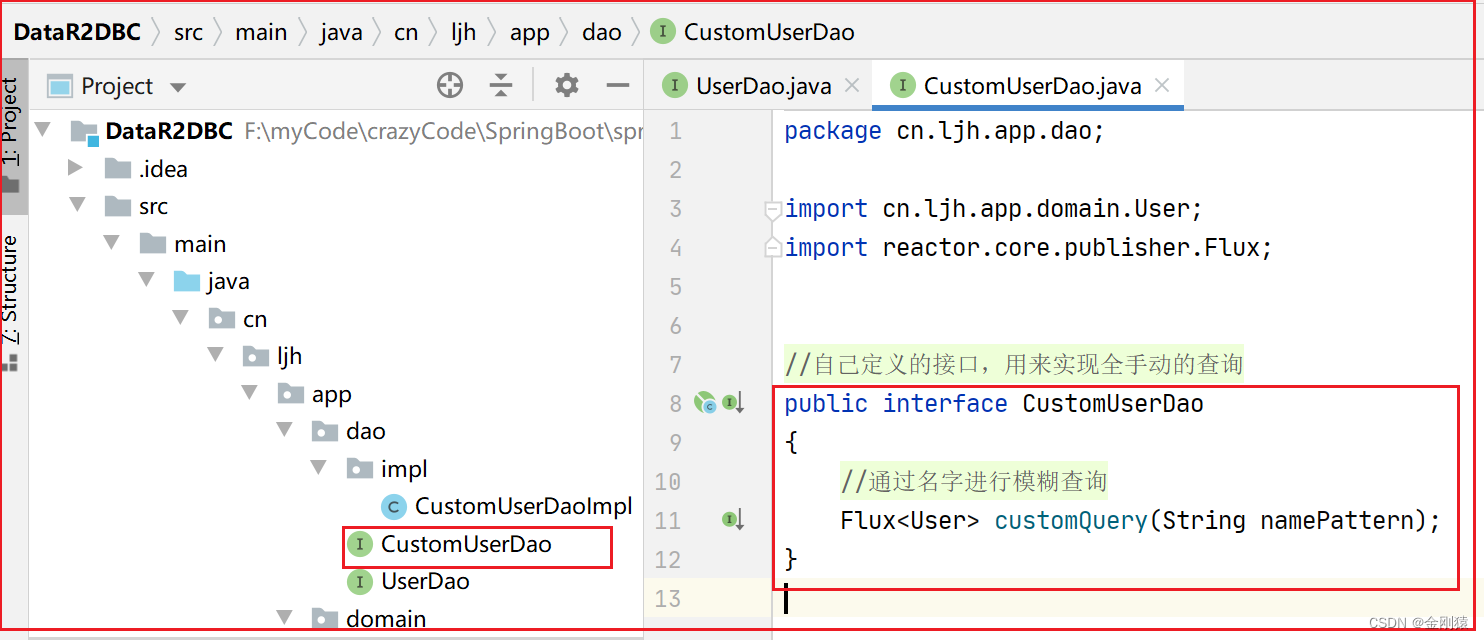
自定义dao组件的接口实现类
当要实现自定义的查询方法时,不再使用JdbcTemplate,而是使用DatabaseClient(相当于JdbcTemplate)
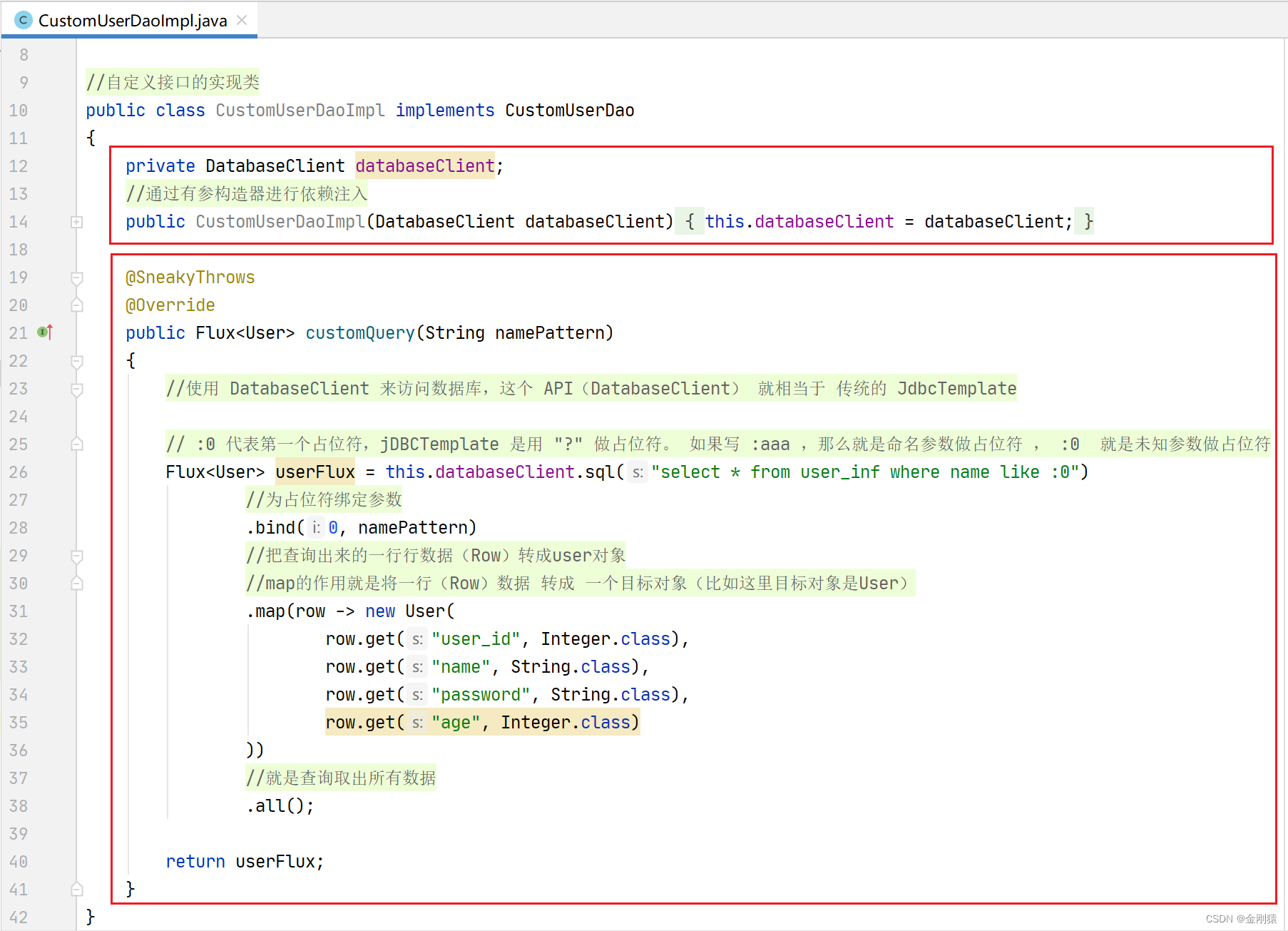
这个是User类
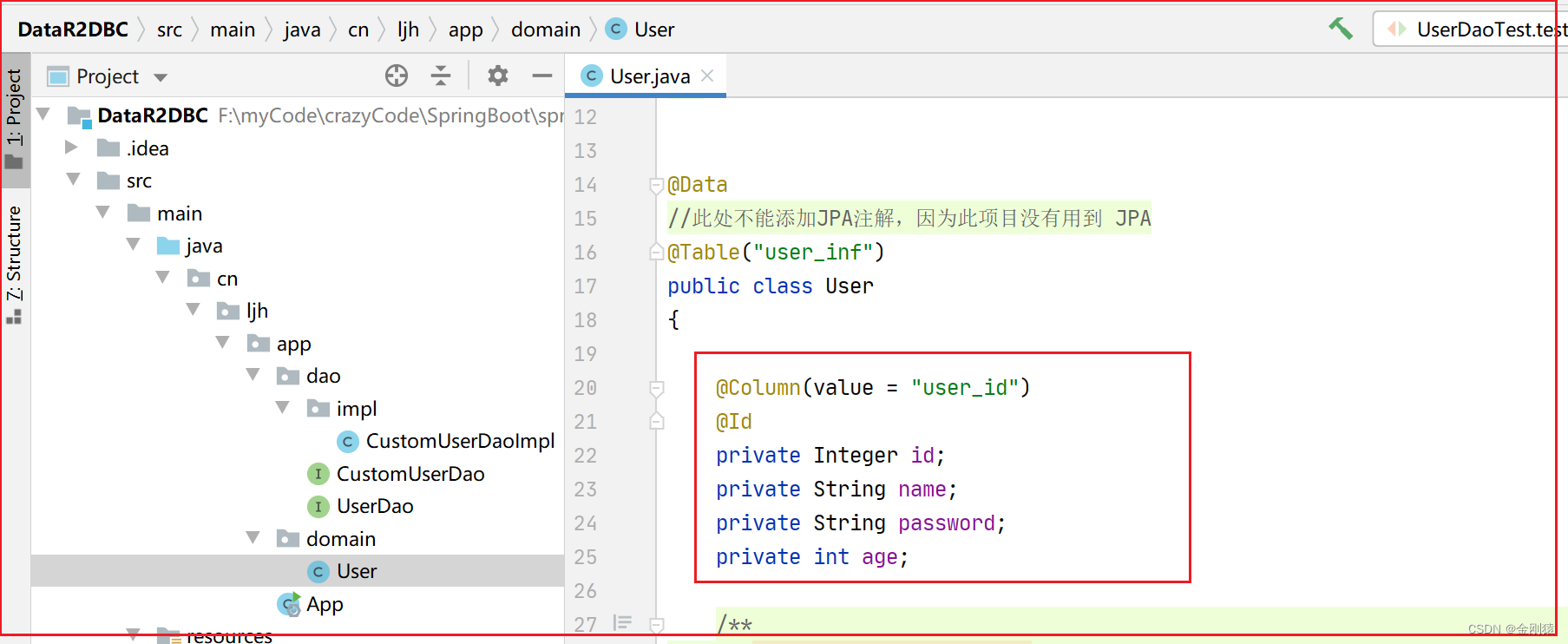
还需要配置数据库的连接
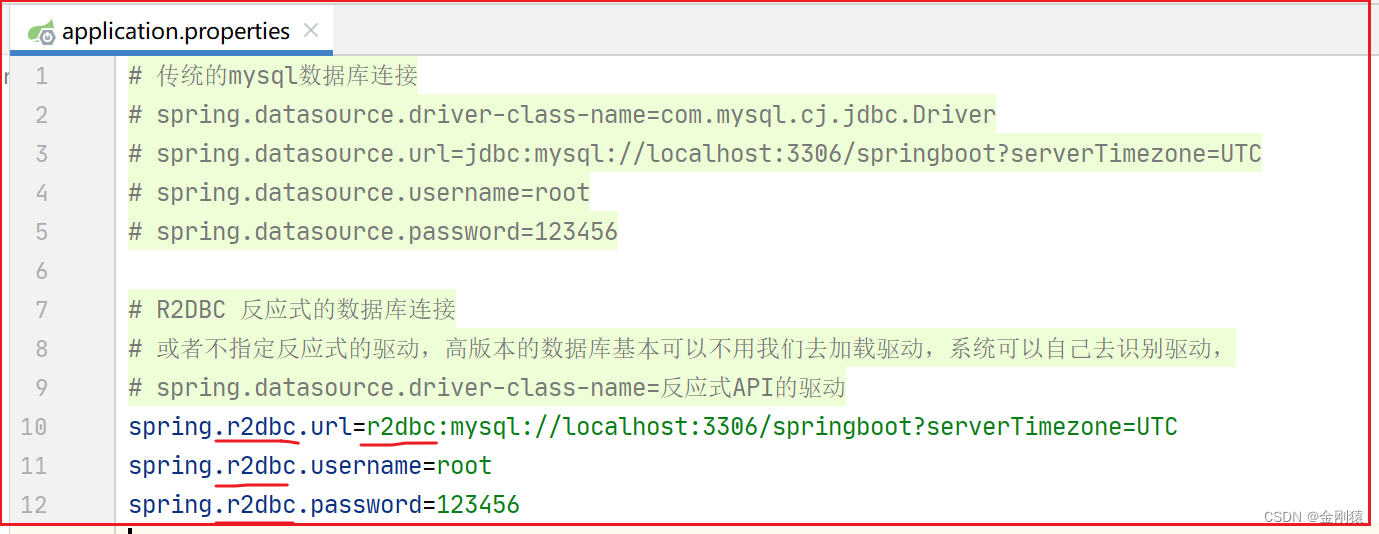
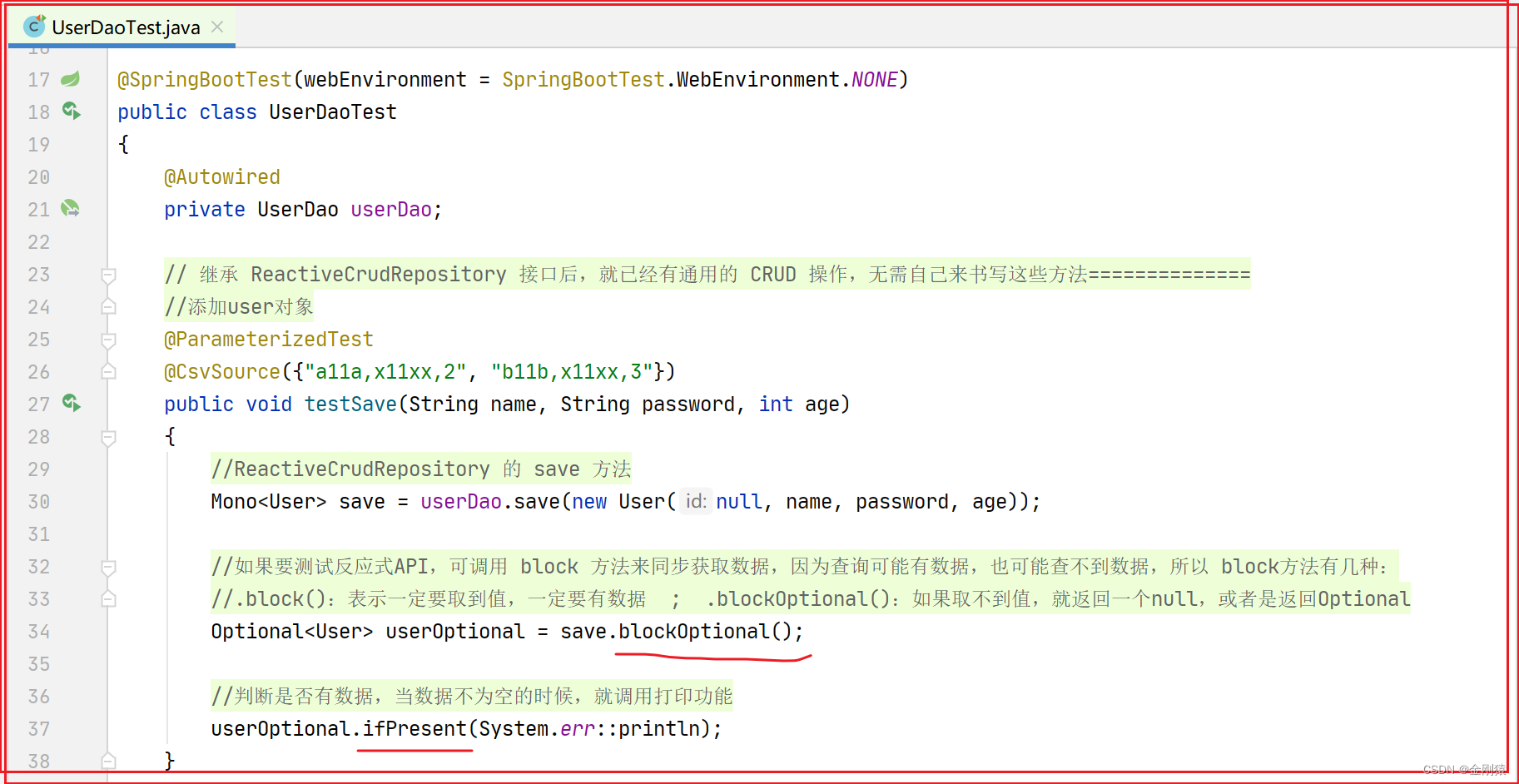
测试:
一些方法的作用:
.block(): block 是阻塞线程,一定要等待 Mono 或 flux 发布数据为止,
表示一定要取到值,一定要有数据
所以这个 block 只能用在测试用例中
block 就相当于在等消息发布者Mono发布数据,如果没有发布数据,就一直等,阻塞,
相当于把反应式又变成了同步的数据读取方式
.blockOptional() :如果取不到值,就返回一个null,或者是返回Optional
.ifPresent(System.err::println):判断是否有数据,当数据不为空的时候,就调用打印功能
.subscribe(System.err::println):消息订阅者subscribe 获取数据
.collectList():将 Flux 中所有数据搜集成 Mono<List>
测试都是通过的,注意的方法都在截图中解释


pom文件
完整代码:
User
package cn.ljh.app.domain;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.PersistenceConstructor;
import org.springframework.data.relational.core.mapping.Column;
import org.springframework.data.relational.core.mapping.Table;
/**
* author JH
*/
@Data
//此处不能添加JPA注解,因为此项目没有用到 JPA
@Table("user_inf")
public class User
{
@Column(value = "user_id")
@Id
private Integer id;
private String name;
private String password;
private int age;
/**
* @PersistenceConstructor
* 修饰主构造器。当你的映射类中有多个构造器时,
* 你希望Spring Data JDBC用哪个构造器来创建对象,就用该注解来修饰该构造器
*/
@PersistenceConstructor
public User()
{
}
public User(Integer id, String name, String password, int age)
{
this.id = id;
this.name = name;
this.password = password;
this.age = age;
}
@Override
public String toString()
{
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", password='" + password + '\'' +
", age=" + age +
'}';
}
}
UserDao
package cn.ljh.app.dao;
import cn.ljh.app.domain.User;
import org.springframework.data.r2dbc.repository.Modifying;
import org.springframework.data.r2dbc.repository.Query;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
//ReactiveCrudRepository 是 Spring Data R2DBC 的反应式 API
public interface UserDao extends ReactiveCrudRepository<User, Integer>, CustomUserDao
{
// 继承 ReactiveCrudRepository 接口后,就已经有通用的 CRUD 操作,无需自己来书写这些方法
//Spring Data R2DBC 的 DAO 组件中的所有方法的返回值类型要么是 MONO ,要么是 Flux,
//MONO 或者 Flux 都继承了 Publisher,返回多条数据,用 Flux 类型接收, 返回一条数据,用 MONO 类型接收
//方法名关键字查询---------全自动
//根据名字模糊查询
Flux<User> findByNameLike(String namePattern);
//根据年龄大小进行范围查询
Flux<User> findByAgeGreaterThan(int startAge);
//根据年龄区间进行范围查询
Flux<User> findByAgeBetween(int startAge, int endAge);
//@Query 查询 --->自己定义查询语句-----半自动
//rowMapperClass 或 rowMapperRef 是用来做自定义映射,查询出来的User对象的数据,映射到Student对象的属性上面去都可以,因为是自定义的。
//根据密码模糊查询
@Query("select * from user_inf where password like :passwordPattern")
Flux<User> findByPassword(String passwordPattern);
//根据年龄范围修改名字
@Query("update user_inf set name = :name where age between :startAge and :endAge")
//更改数据库数据需要用到这个注解
@Modifying
Mono<Integer> updateNameByAge(String name, int startAge, int endAge);
}
CustomUserDao
package cn.ljh.app.dao;
import cn.ljh.app.domain.User;
import reactor.core.publisher.Flux;
//自己定义的接口,用来实现全手动的查询
public interface CustomUserDao
{
//通过名字进行模糊查询
Flux<User> customQuery(String namePattern);
}
CustomUserDaoImpl
package cn.ljh.app.dao.impl;
import cn.ljh.app.dao.CustomUserDao;
import cn.ljh.app.domain.User;
import lombok.SneakyThrows;
import org.springframework.r2dbc.core.DatabaseClient;
import reactor.core.publisher.Flux;
//自定义接口的实现类
public class CustomUserDaoImpl implements CustomUserDao
{
private DatabaseClient databaseClient;
//通过有参构造器进行依赖注入
public CustomUserDaoImpl(DatabaseClient databaseClient)
{
this.databaseClient = databaseClient;
}
@SneakyThrows
@Override
public Flux<User> customQuery(String namePattern)
{
//使用 DatabaseClient 来访问数据库,这个 API(DatabaseClient) 就相当于 传统的 JdbcTemplate
// :0 代表第一个占位符,jDBCTemplate 是用 "?" 做占位符。 如果写 :aaa ,那么就是命名参数做占位符 , :0 就是未知参数做占位符
Flux<User> userFlux = this.databaseClient.sql("select * from user_inf where name like :0")
//为占位符绑定参数
.bind(0, namePattern)
//把查询出来的一行行数据(Row)转成user对象
//map的作用就是将一行(Row)数据 转成 一个目标对象(比如这里目标对象是User)
.map(row -> new User(
row.get("user_id", Integer.class),
row.get("name", String.class),
row.get("password", String.class),
row.get("age", Integer.class)
))
//就是查询取出所有数据
.all();
return userFlux;
}
}
UserDaoTest
package cn.ljh.app;
import cn.ljh.app.dao.UserDao;
import cn.ljh.app.domain.User;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import reactor.core.Disposable;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.util.List;
import java.util.Optional;
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class UserDaoTest
{
@Autowired
private UserDao userDao;
// 继承 ReactiveCrudRepository 接口后,就已经有通用的 CRUD 操作,无需自己来书写这些方法==============
//添加user对象
@ParameterizedTest
@CsvSource({"a11a,x11xx,2", "b11b,x11xx,3"})
public void testSave(String name, String password, int age)
{
//ReactiveCrudRepository 的 save 方法
Mono<User> save = userDao.save(new User(null, name, password, age));
//如果要测试反应式API,可调用 block 方法来同步获取数据,因为查询可能有数据,也可能查不到数据,所以 block方法有几种:
//.block():表示一定要取到值,一定要有数据 ; .blockOptional():如果取不到值,就返回一个null,或者是返回Optional
Optional<User> userOptional = save.blockOptional();
//判断是否有数据,当数据不为空的时候,就调用打印功能
userOptional.ifPresent(System.err::println);
}
//根据id查询对象
@ParameterizedTest
@ValueSource(ints = {1})
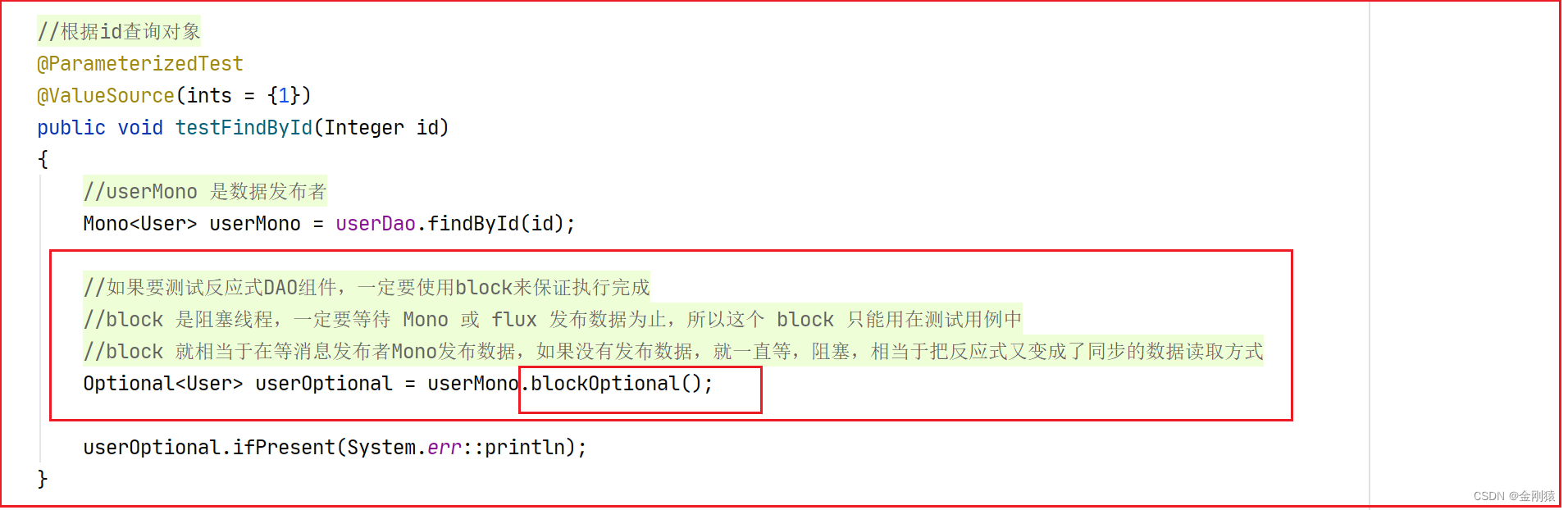
public void testFindById(Integer id)
{
//userMono 是数据发布者
Mono<User> userMono = userDao.findById(id);
//如果要测试反应式DAO组件,一定要使用block来保证执行完成
//block 是阻塞线程,一定要等待 Mono 或 flux 发布数据为止,所以这个 block 只能用在测试用例中
//block 就相当于在等消息发布者Mono发布数据,如果没有发布数据,就一直等,阻塞,相当于把反应式又变成了同步的数据读取方式
Optional<User> userOptional = userMono.blockOptional();
//判断是否有数据,当数据不为空的时候,就调用打印功能
userOptional.ifPresent(System.err::println);
}
//根据id删除用户对象
@ParameterizedTest
@ValueSource(ints = {24})
public void testDelete(Integer id)
{
Mono<Void> mono = userDao.deleteById(id);
//如果要测试反应式DAO组件,一定要使用block来保证执行完成,block的作用就是一定会等待着阻塞着直到拿到数据
Optional<Void> optional = mono.blockOptional();
}
//根据id修改对象 ,有id,save就是修改
@ParameterizedTest
@CsvSource({"13,aaa,xxxx,22"})
public void testUpdate(Integer id, String name, String password, int age)
{
//跟上面添加对象的写法一样
Mono<User> save = userDao.save(new User(id, name, password, age));
Optional<User> userOptional = save.blockOptional();
userOptional.ifPresent(System.err::println);
}
//根据名字模糊查询
@ParameterizedTest
@ValueSource(strings = {"孙%", "%精"})
public void testFindByNameLike(String namePattern) throws InterruptedException
{
//userFlux 数据发布者
Flux<User> userFlux = userDao.findByNameLike(namePattern);
//除了用 block 这种同步的方式获取数据之外,还可以用这个 消息订阅者subscribe 获取数据。
//为 Flux 指定了一个消息订阅者,消息订阅者是一个 Lambda 表达式,只是负责将数据打印出来
//如果只是用 subscribe ,因为反应式API是异步的,意味着有可能数据还没有到来,测试方法就已经执行结束了
userFlux.subscribe(System.err::println);
//让测试方法暂定1秒,等到Flux的数据到来---只适合数据量小的时候
Thread.sleep(1000);
}
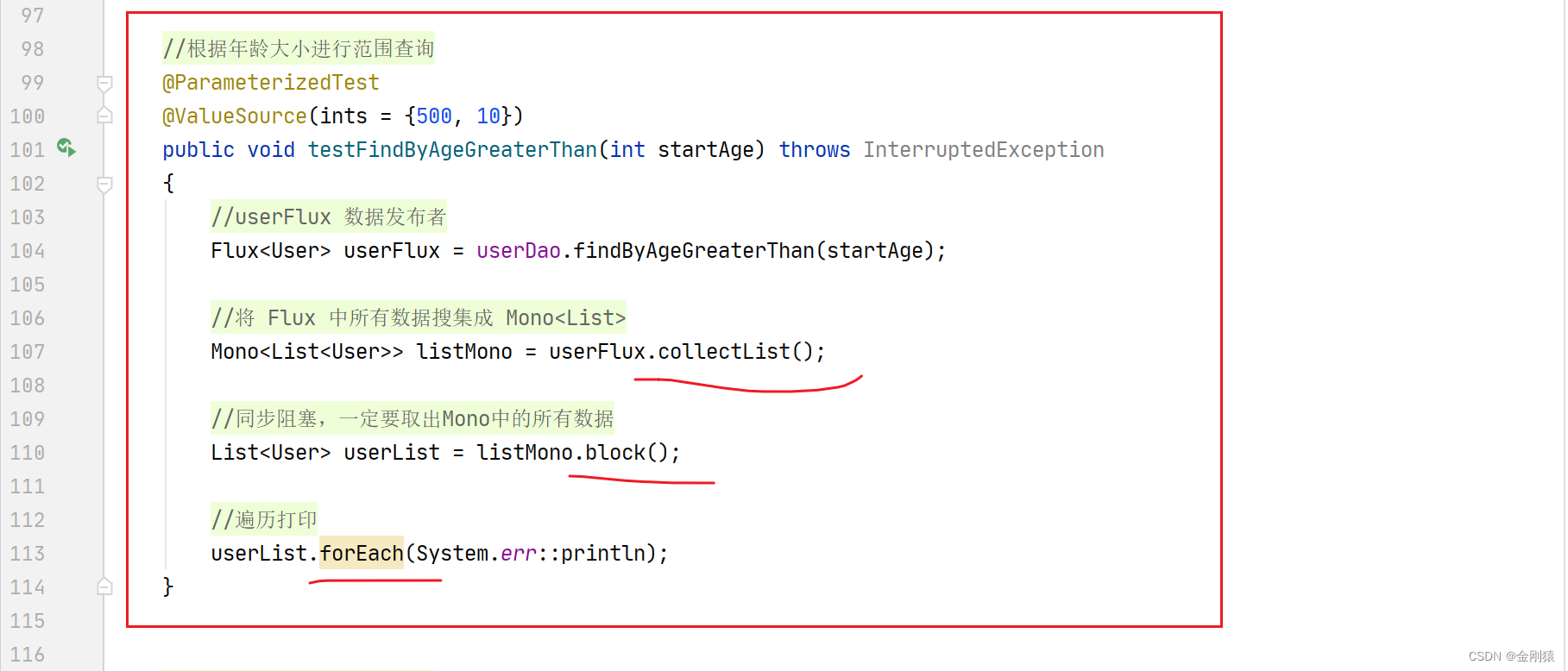
//根据年龄大小进行范围查询
@ParameterizedTest
@ValueSource(ints = {500, 10})
public void testFindByAgeGreaterThan(int startAge) throws InterruptedException
{
//userFlux 数据发布者
Flux<User> userFlux = userDao.findByAgeGreaterThan(startAge);
//将 Flux 中所有数据搜集成 Mono<List>
Mono<List<User>> listMono = userFlux.collectList();
//同步阻塞,一定要取出Mono中的所有数据
List<User> userList = listMono.block();
//遍历打印
userList.forEach(System.err::println);
}
//根据年龄区间进行范围查询
@ParameterizedTest
@CsvSource({"15,20", "500,1000"})
public void testFindByAgeBetween(int startAge, int endAge)
{
//userFlux 数据发布者
Flux<User> userFlux = userDao.findByAgeBetween(startAge, endAge);
//将 Flux 中所有数据搜集成 Mono<List>
Mono<List<User>> listMono = userFlux.collectList();
//同步阻塞,一定要取出Mono中的所有数据
List<User> userList = listMono.block();
//遍历打印
userList.forEach(System.err::println);
}
//根据密码模糊查询
@ParameterizedTest
@ValueSource(strings = {"niu%", "%3"})
public void testFindBySql(String passwordPattern)
{
//userFlux 数据发布者
Flux<User> userFlux = userDao.findByPassword(passwordPattern);
//将 Flux 中所有数据搜集成 Mono<List>
Mono<List<User>> listMono = userFlux.collectList();
//同步阻塞,一定要取出Mono中的所有数据
List<User> userList = listMono.block();
//遍历打印
userList.forEach(System.err::println);
}
//根据年龄范围修改名字----修改
@ParameterizedTest
@CsvSource({"牛魔王aa,800,1000"})
//@Transactional 和 @Rollback(false) 是只有 spring data jdbc 才需要用到
//@Transactional //事务
//@Rollback(false) //测试的数据不进行回滚
public void testUpdateNameByAge(String name, int startAge, int endAge)
{
//mono消息发布者
Mono<Integer> mono = userDao.updateNameByAge(name, startAge, endAge);
//blockOptional:同步方式获取数据,返回值为 Optional
Optional<Integer> optionalInteger = mono.blockOptional();
//ifPresent :判断是否有数据,有数据则执行打印功能
optionalInteger.ifPresent(System.err::println);
}
//通过名字进行模糊查询,
@ParameterizedTest
@ValueSource(strings = {"孙%"})
public void testCustomQuery(String namePattern)
{
//userFlux 数据发布者
Flux<User> userFlux = userDao.customQuery(namePattern);
//将 Flux 中所有数据搜集成 Mono<List>
Mono<List<User>> listMono = userFlux.collectList();
//同步阻塞,一定要取出Mono中的所有数据
List<User> userList = listMono.block();
//遍历打印
userList.forEach(System.err::println);
}
}
application.properties
# 传统的mysql数据库连接
# spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# spring.datasource.url=jdbc:mysql://localhost:3306/springboot?serverTimezone=UTC
# spring.datasource.username=root
# spring.datasource.password=123456
# R2DBC 反应式的数据库连接
# 或者不指定反应式的驱动,高版本的数据库基本可以不用我们去加载驱动,系统可以自己去识别驱动,
# spring.datasource.driver-class-name=反应式API的驱动
spring.r2dbc.url=r2dbc:mysql://localhost:3306/springboot?serverTimezone=UTC
spring.r2dbc.username=root
spring.r2dbc.password=123456
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
</parent>
<groupId>cn.ljh</groupId>
<artifactId>DataR2DBC</artifactId>
<version>1.0.0</version>
<name>DataR2DBC</name>
<properties>
<java.version>11</java.version>
</properties>
<dependencies>
<!-- 导入 spring data r2dbc 反应式 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-r2dbc</artifactId>
</dependency>
<!-- 把传统的mysql的数据库驱动 改成使用 MySql 的反应式驱动 -->
<dependency>
<groupId>dev.miku</groupId>
<artifactId>r2dbc-mysql</artifactId>
</dependency>
<!-- 传统的mysql数据库驱动 -->
<!-- dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>




![[Python]Open CV 基础知识学习](https://img-blog.csdnimg.cn/c792abf97485453fb1505b696f5c9009.png)


