文本纠错(Text Error Correction)技术旨在自动修正输入文本中的拼写、语法、标点符号等错误,以提高文本的准确性、通顺性和规范性。该技术可以通过自然语言处理技术实现,基于上下文和语言规则对文本进行分析和推断,发现其中的错误,并给出正确的替换或修改建议。
pycorrector是一个开源中文文本纠错工具,它支持对中文文本进行音似、形似和语法错误的纠正。此工具是使用Python3进行开发的,并整合了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、Transformer等多种模型来实现文本纠错功能。pycorrector官方仓库地址为:pycorrector。pycorrector安装命令如下:
pip install -U pycorrector
本文旨在介绍如何调用pycorrector提供的函数接口来进行文本纠错。事实上,pycorrector官方仓库已经提供了详尽的使用教程,可进一步深入了解pycorrector的使用方法。此外,文章PyCorrector文本纠错工具实践和代码详解也系统性地介绍了pycorrector的使用。
文章目录
- 1 pycorrector相关背景
- 2 pycorrector使用说明
- 2.1 基于规则的中文文本纠错
- 2.2 基于深度学习的中文文本纠错
- 3 参考
# jupyter notebook环境去除warning
import warnings
warnings.filterwarnings("ignore")
1 pycorrector相关背景
本节一些内容和图片来自:pycorrector源码解读。
应用背景
中文文本纠错任务的应用背景和常见错误类型如下图所示,pycorrector专注于解决"音似、形字、语法、专名错误"等类型的错误。

数据集
在文本纠错任务中,数据集的质量和数量往往比模型本身更为重要。这也是许多实际场景任务所面临的共同问题。因为模型之间的差别并不大,文本纠错模型的精度更多取决于训练数据规模。

技术思路
一般文本纠错任务有两种技术实现方式:基于规则的文本纠错和基于机器学习/深度学习的文本纠错。由于大语言模型效果很好,所以现有文本纠错方法了解即可。
基于规则的中文文本纠错技术思路如下:
- 分词:首先使用分词工具将输入的文本进行分词处理,将句子拆分成一个个词语。
- 错误检测:使用规则匹配的方式,对分词后的文本进行错误检测。常见的错误包括拼写错误、词序错误、词语冗余等。例如,可以使用字典或语料库来匹配常用词汇,如果某个词不在字典或语料库中,则认为它是一个可能的错误。
- 错误纠正:一旦发现错误,可以根据规则进行纠正。纠错的方法包括拼写纠正、词序调整、词语替换等。例如,可以利用编辑距离或拼音近似匹配算法来进行拼写纠正;可以使用语言模型预测概率来判断词序是否正确;可以使用同义词词典来进行词语替换。
基于机器学习/深度学习的文本纠错技术思路如下:
- 基于Sequence-to-Sequence模型:使用编码器-解码器结构的序列到序列模型,将输入的错误文本作为源序列,目标文本(正确文本)作为目标序列进行训练。通过最小化误差来调整模型的参数,实现对错误文本的纠错。
- 基于Transformer模型:Transformer模型是一种注意力机制的深度学习模型,广泛应用于自然语言处理任务中,如机器翻译和文本生成。在文本纠错任务中,可以使用Transformer模型将错误文本转化为正确文本,通过损失函数进行训练和优化。
- 基于语言模型的强化学习方法:使用语言模型来生成候选纠错结果,并通过强化学习算法来评估和选择最佳的纠错建议。这种方法可以通过与外部环境进行交互,不断提升纠错性能。
- 基于预训练模型,如GPT系列模型或BERT模型。其中BERT是一种预训练语言模型,具有良好的上下文理解能力。在文本纠错中,可以使用BERT模型进行编码和解码操作,通过自监督学习来训练模型,使其具备纠正错误文本的能力。
工业解决方案
尽管以GPT为代表的大语言模型在文本纠错方面展现出潜力,但其计算资源要求较高,需要训练数据和强大的计算能力。目前,工业界已有的文本纠错技术仍然具备优势和广泛应用场景。
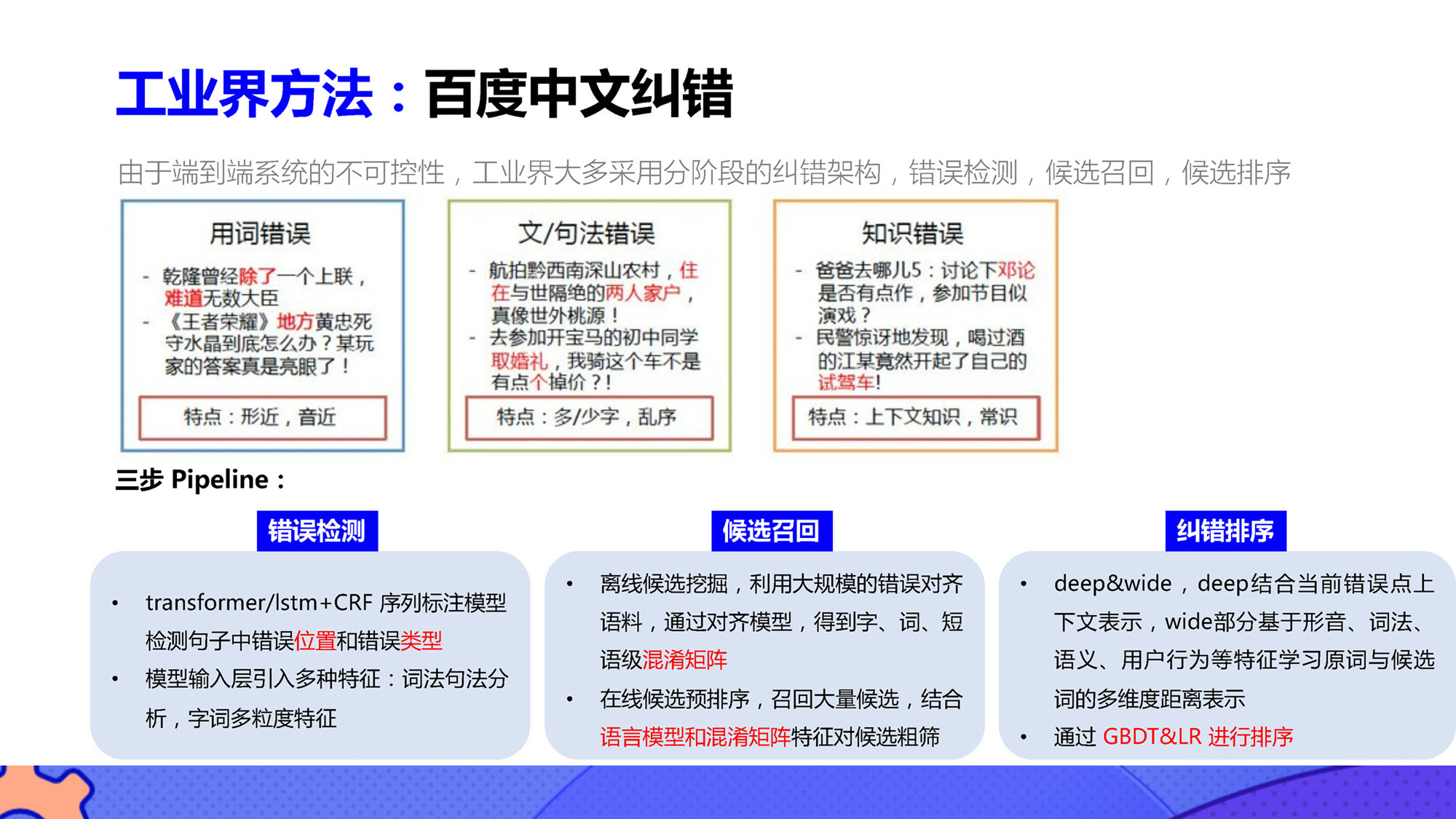
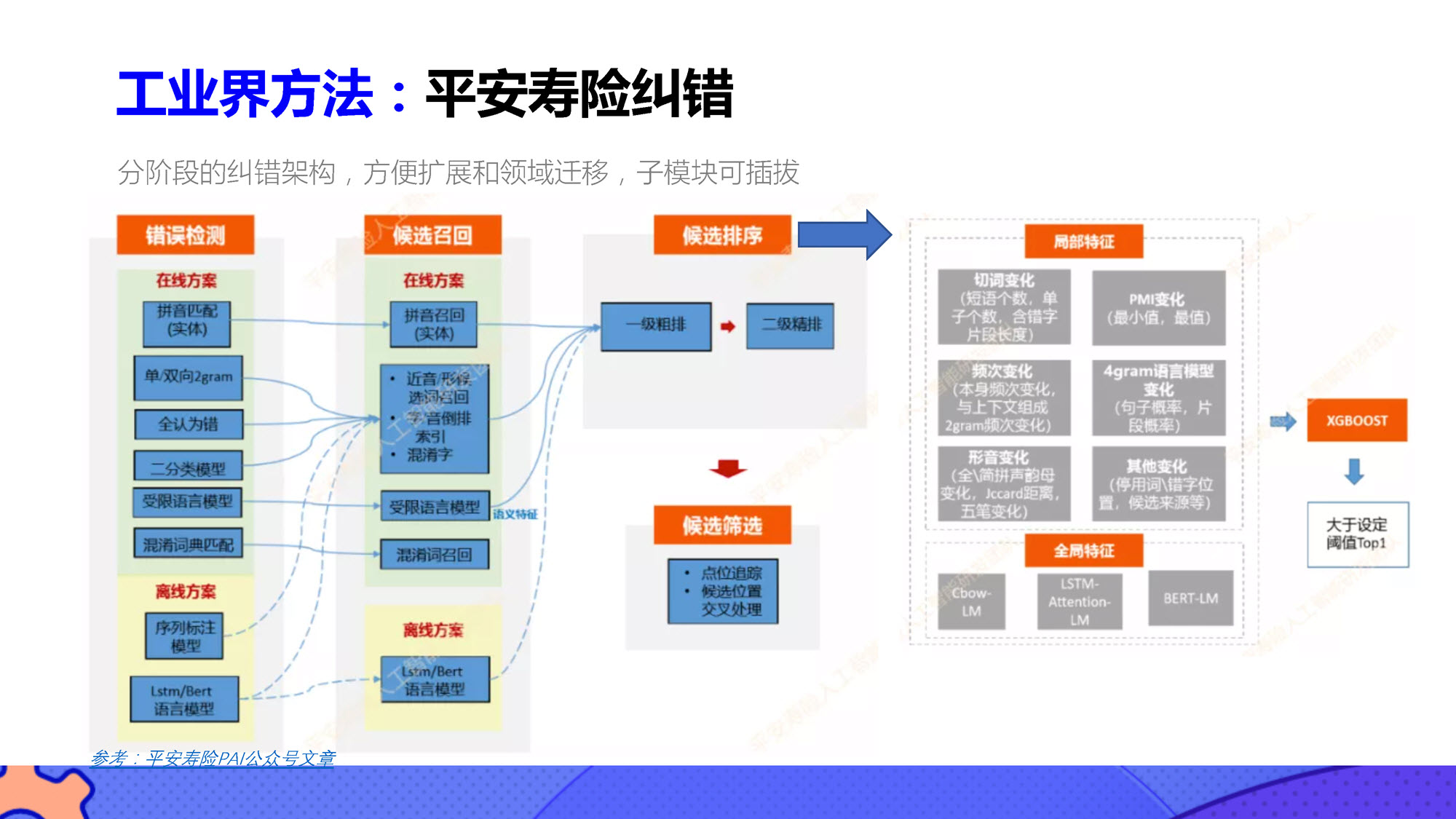

2 pycorrector使用说明
2.1 基于规则的中文文本纠错
pycorrector中基于规则的中文文本纠错接口默认使用Kenlm模型。具体来说,pycorrector基于Kenlm统计语言模型工具训练了中文NGram语言模型,结合规则方法、混淆集可以快速纠正中文拼写错误,但效果一般。
文本纠错
用于文本纠错的correct函数会从路径~/.pycorrector/datasets/zh_giga.no_cna_cmn.prune01244.klm加载kenlm语言模型文件,如果检测没有该文件, 则模型会自动联网下载。当然也可以手动下载klm模型文件(2.8G)并放置于该位置。
import pycorrector
# include_symbol: 是否包含标点符号,默认为True
# threshold: 纠错阈值,默认为57
corrected_sent, detail = pycorrector.correct("人群穿流不息,少先队员因该为老人让坐!",include_symbol=True,threshold=60)
# corrected_sent: 纠错后的句子
# detail: 纠错信息,[wrong, right, begin_pos, end_pos]
corrected_sent, detail
('人群川流不息,少先队员应该为老人让座!',
[('穿流不息', '川流不息', 2, 6), ('因该', '应该', 11, 13), ('坐', '座', 17, 18)])
错误检测
pycorrector提供detect函数来检测并返回输入文本中可能存在的语言错误和错误类型。
import pycorrector
idx_errors = pycorrector.detect('人群穿流不息,少先队员因该为老人让坐!')
print(idx_errors)
[['穿流不息', 2, 6, 'proper'], ['因该', 11, 13, 'word'], ['坐', 17, 18, 'char']]
成语、专名纠错
pycorrector提供了专门用于对成语和专名进行纠错的函数,如下所示:
from pycorrector.proper_corrector import ProperCorrector
from pycorrector import config
m = ProperCorrector(proper_name_path=config.proper_name_path)
x = [
'这块名表带带相传',
'这块名表代代相传',
'这场比赛我甘败下风',
'这场比赛我甘拜下封',
'早上在拼哆哆上买了点葡桃',
]
for i in x:
print(i, ' -> ', m.proper_correct(i))
这块名表带带相传 -> ('这块名表代代相传', [('带带相传', '代代相传', 4, 8)])
这块名表代代相传 -> ('这块名表代代相传', [])
这场比赛我甘败下风 -> ('这场比赛我甘拜下风', [('甘败下风', '甘拜下风', 5, 9)])
这场比赛我甘拜下封 -> ('这场比赛我甘拜下风', [('甘拜下封', '甘拜下风', 5, 9)])
早上在拼哆哆上买了点葡桃 -> ('早上在拼多多上买了点葡桃', [('拼哆哆', '拼多多', 3, 6)])
自定义混淆集
pycorrector通过加载自定义混淆集,支持用户纠正已知的错误,实际就是字符串替换。
from pycorrector import ConfusionCorrector, Corrector
if __name__ == '__main__':
error_sentences = [
'买iphonex,要多少钱', # 漏召回
'哪里卖苹果吧?请大叔给我让坐', # 漏召回
'共同实际控制人萧华、霍荣铨、张旗康', # 误杀
'上述承诺内容系本人真实意思表示', # 正常
'大家一哄而伞怎么回事', # 成语
]
m = Corrector()
for i in error_sentences:
print(i, ' -> ', m.detect(i), m.correct(i))
print('*' * 42)
# 自定义混淆集
custom_confusion = {'得事': '的事', '天地无垠': '天地无限', '交通先行': '交通限行', '苹果吧': '苹果八', 'iphonex': 'iphoneX', '小明同学': '小茗同学', '萧华': '萧华',
'张旗康': '张旗康', '一哄而伞': '一哄而散', 'happt': 'happen', 'shylock': 'shylock', '份额': '份额', '天俺门': '天安门'}
m = ConfusionCorrector(custom_confusion_path_or_dict=custom_confusion)
for i in error_sentences:
print(i, ' -> ', m.confusion_correct(i))
买iphonex,要多少钱 -> [['钱', 12, 13, 'char']] ('买iphonex,要多少钱', [])
哪里卖苹果吧?请大叔给我让坐 -> [] ('哪里卖苹果吧?请大叔给我让坐', [])
共同实际控制人萧华、霍荣铨、张旗康 -> [['霍荣铨', 10, 13, 'word'], ['张旗康', 14, 17, 'word']] ('共同实际控制人萧华、霍荣铨、张启康', [('张旗康', '张启康', 14, 17)])
上述承诺内容系本人真实意思表示 -> [['系', 6, 7, 'char']] ('上述承诺内容系本人真实意思表示', [])
大家一哄而伞怎么回事 -> [['一哄', 2, 4, 'word'], ['伞', 5, 6, 'char']] ('大家一哄而散怎么回事', [('伞', '散', 5, 6)])
******************************************
买iphonex,要多少钱 -> ('买iphoneX,要多少钱', [['iphonex', 'iphoneX', 1, 8]])
哪里卖苹果吧?请大叔给我让坐 -> ('哪里卖苹果八?请大叔给我让坐', [['苹果吧', '苹果八', 3, 6]])
共同实际控制人萧华、霍荣铨、张旗康 -> ('共同实际控制人萧华、霍荣铨、张旗康', [['萧华', '萧华', 7, 9], ['张旗康', '张旗康', 14, 17]])
上述承诺内容系本人真实意思表示 -> ('上述承诺内容系本人真实意思表示', [])
大家一哄而伞怎么回事 -> ('大家一哄而散怎么回事', [['一哄而伞', '一哄而散', 2, 6]])
自定义语言模型
pycorrector提供了用于加载自定义语言模型的代码,如下所示:
# 自定义模型路径
lm_path = './custom.klm'
model = Corrector(language_model_path=lm_path)
英文拼写纠错
pycorrector也提供英文拼写纠错,效果很一般。
sent = "what happending? how to speling it, can you gorrect it?"
corrected_text, details = pycorrector.en_correct(sent)
print(sent, '=>', corrected_text)
print(details)
what happending? how to speling it, can you gorrect it? => what happening? how to spelling it, can you correct it?
[('happending', 'happening', 5, 15), ('speling', 'spelling', 24, 31), ('gorrect', 'correct', 44, 51)]
pycorrect也支持自定义的词频字典设置,以防止误纠错。如下所示,shylock被纠错为shock,可以设置shylock出现频率比shock高来避免纠错。
from pycorrector.en_spell import EnSpell
# # 定义一个字符串变量
sent = "what is your name? shylock?"
# 创建一个EnSpell类的实例对象
spell = EnSpell()
corrected_text, details = spell.correct(sent)
# shylock被纠错为shock
print(sent, '=>', corrected_text, details)
print('-' * 42)
# 定义一个包含词频信息的字典
# 设置shylock出现频次比shock高
my_dict = {'your': 120, 'name': 2, 'is': 1, 'shock': 2, 'shylock': 1, 'what': 1}
# 创建一个EnSpell类的实例对象,并传入自定义词频字典
spell = EnSpell(word_freq_dict=my_dict)
corrected_text, details = spell.correct(sent)
print(sent, '=>', corrected_text, details)
what is your name? shylock? => what is your name? shock? [('shylock', 'shock', 19, 26)]
------------------------------------------
what is your name? shylock? => what is your name? shylock? []
中文简繁互换
pycorrector支持中文简体和繁体的互换,如下所示:
import pycorrector
traditional_sentence = '學而時習之,不亦說乎'
simplified_sentence = pycorrector.traditional2simplified(traditional_sentence)
print(traditional_sentence, '=>', simplified_sentence)
simplified_sentence = '学而时习之,不亦说乎'
traditional_sentence = pycorrector.simplified2traditional(simplified_sentence)
print(simplified_sentence, '=>', traditional_sentence)
學而時習之,不亦說乎 => 学而时习之,不亦说乎
学而时习之,不亦说乎 => 學而時習之,不亦說乎
2.2 基于深度学习的中文文本纠错
pycorrector提供多个基于深度学习的中文文本纠错模型,一般而言,使用深度学习进行中文文本纠错可以获得比基于规则纠错更好的效果。pycorrector在SIGHAN2015数据集数据集下对各种深度学习模型进行了评测,SIGHAN2015数据集是一个经典公开的用于中文文本纠错任务的数据集,并得出以下结论:
- 中文拼写纠错模型效果最好的是MacBert-CSC,模型名称是shibing624/macbert4csc-base-chinese,huggingface model:shibing624/macbert4csc-base-chinese
- 中文语法纠错模型效果最好的是BART-CSC,模型名称是shibing624/bart4csc-base-chinese,huggingface model:shibing624/bart4csc-base-chinese
- 最具潜力的模型是Mengzi-T5-CSC,模型名称是shibing624/mengzi-t5-base-chinese-correction,huggingface model:shibing624/mengzi-t5-base-chinese-correction,未改变模型结构,仅fine-tune中文纠错数据集,已经在
SIGHAN 2015取得接近SOTA的效果 - 基于ChatGLM-6B的纠错微调模型效果也不错,模型名称是shibing624/chatglm-6b-csc-zh-lora,huggingface model:shibing624/chatglm-6b-csc-zh-lora,大模型不仅能改错还能润色句子,但是模型太大,推理速度慢
在pycorrector中调用MacBert-CSC模型进行文本纠错的代码如下,该代码将自动加载macbert4csc-base-chinese提供的纠错模型。
from pycorrector.macbert.macbert_corrector import MacBertCorrector
from pycorrector import ConfusionCorrector
if __name__ == '__main__':
error_sentences = [
'少先队员因该为老人让坐',
'机七学习是人工智能领遇最能体现智能的一个分知',
]
m = MacBertCorrector()
# add confusion corrector for postprocess
confusion_dict = {"喝小明同学": "喝小茗同学", "老人让坐": "老人让座", "平净": "平静", "分知": "分支"}
cm = ConfusionCorrector(custom_confusion_path_or_dict=confusion_dict)
for line in error_sentences:
correct_sent, err = m.macbert_correct(line)
print("query:{} => {} err:{}".format(line, correct_sent, err))
correct_sent, err = cm.confusion_correct(correct_sent)
if err:
print("added confusion: {} err: {}".format(correct_sent, err))
此外,pycorrector也推荐使用PaddleNLP进行文本纠错。PaddleNLP提供了覆盖包括文本纠错在内的多个产业级NLP预置模型。关于PaddleNLP的安装和使用见其官方仓库:PaddleNLP。
from paddlenlp import Taskflow
corrector = Taskflow("text_correction")
# 单条输入
corrector('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。')
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。',
'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。',
'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
# 批量预测
corrector(['遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。'])
[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。',
'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。',
'errors': [{'position': 3, 'correction': {'竟': '境'}}]},
{'source': '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。',
'target': '人生就是如此,经过磨炼才能让自己更加茁壮,才能使自己更加乐观。',
'errors': [{'position': 10, 'correction': {'练': '炼'}},
{'position': 18, 'correction': {'拙': '茁'}}]}]
实际上,无论是基于规则的中文文本纠错算法还是其他基于深度学习模型的文本纠错算法,它们的效果都不如深度学习大模型(例如ChatGPT)。即使是PaddleNLP提供的纠错模型,在中文自然语言处理任务中也有相当高的精度,但面对一些简单的纠错案例时,效果也可能不佳。如下所示,“穿流不息”被错误地纠正为“传流不息”。因此,在实际应用时,应该根据具体场景定制相应的模型。如果是工业应用,在算力要求不高的情况下,应该尽可能选择开源大语言模型。
corrector('人群穿流不息,少先队员因该为老人让坐')
[{'source': '人群穿流不息,少先队员因该为老人让坐',
'target': '人群传流不息,少先队员应该为老人让坐',
'errors': [{'position': 2, 'correction': {'穿': '传'}},
{'position': 11, 'correction': {'因': '应'}}]}]
3 参考
- pycorrector
- PyCorrector文本纠错工具实践和代码详解
- pycorrector源码解读
- klm模型文件
- macbert4csc-base-chinese
- PaddleNLP