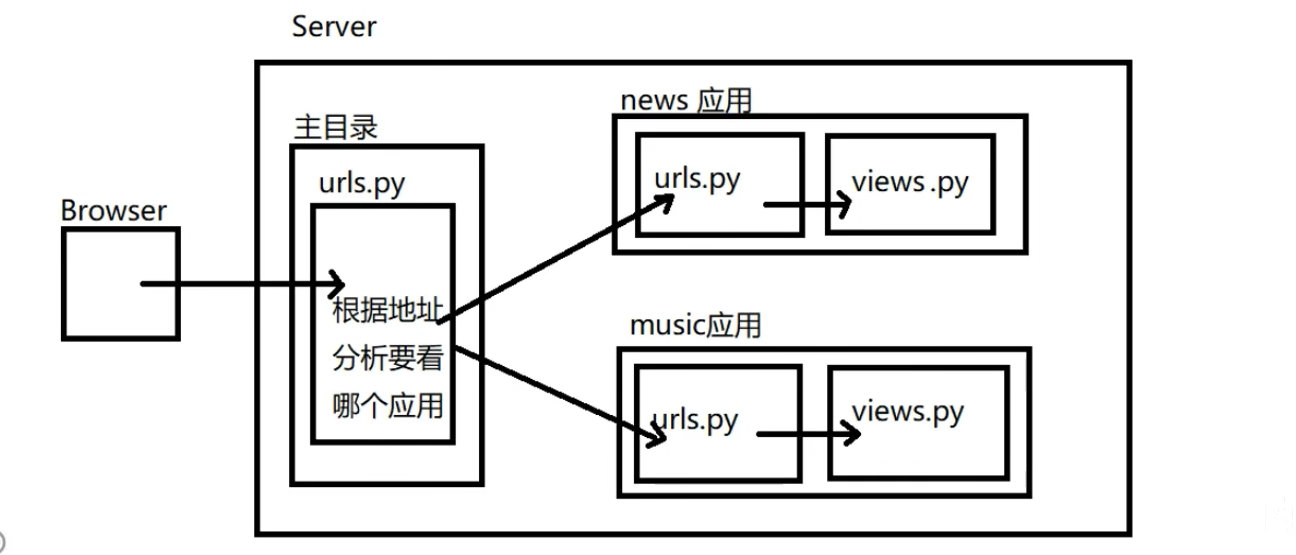
为什么会想着探索下嵌入式裸机的架构呢?是因为最近写了一个项目,项目开发接近尾声时,发现了一些问题:
1、项目中,驱动层和应用层掺杂在一起,虽然大部分是应用层调用驱动层,但是也存在驱动层调用业务层的情况,这导致了层次间的耦合;
2、应用程序全都放在了一个app.c文件夹里,代码高达1万行,实在是过于庞大,我想着将代码拆分下,发现实在是太困难,牵一发动全身;
3、全局变量满天飞,代码量大了之后,自己都晕了,虽然写了注释,但是想想,如果注释没写清楚,那么时间久了,自己回来看都不知道是啥~~~~~~;
那么,如何在后续项目中有所改进呢?
架构1.0
关于程序的架构和规范化,要做到:
层次分明,模块化,高內聚低耦合,风格规范易懂。
自顶向下设计,自底向上开发,花一两天来设计,设计好之后再开发。
层次分明
根据需求,有各种各样的功能要实现,但是因为嵌入式不仅涉及到软件,还会涉及到硬件,所以,需要分层,思维才能更清晰,更有利于后期的开发和维护。
根据我自己的开发经验,先说下我的最初裸机分层习惯。
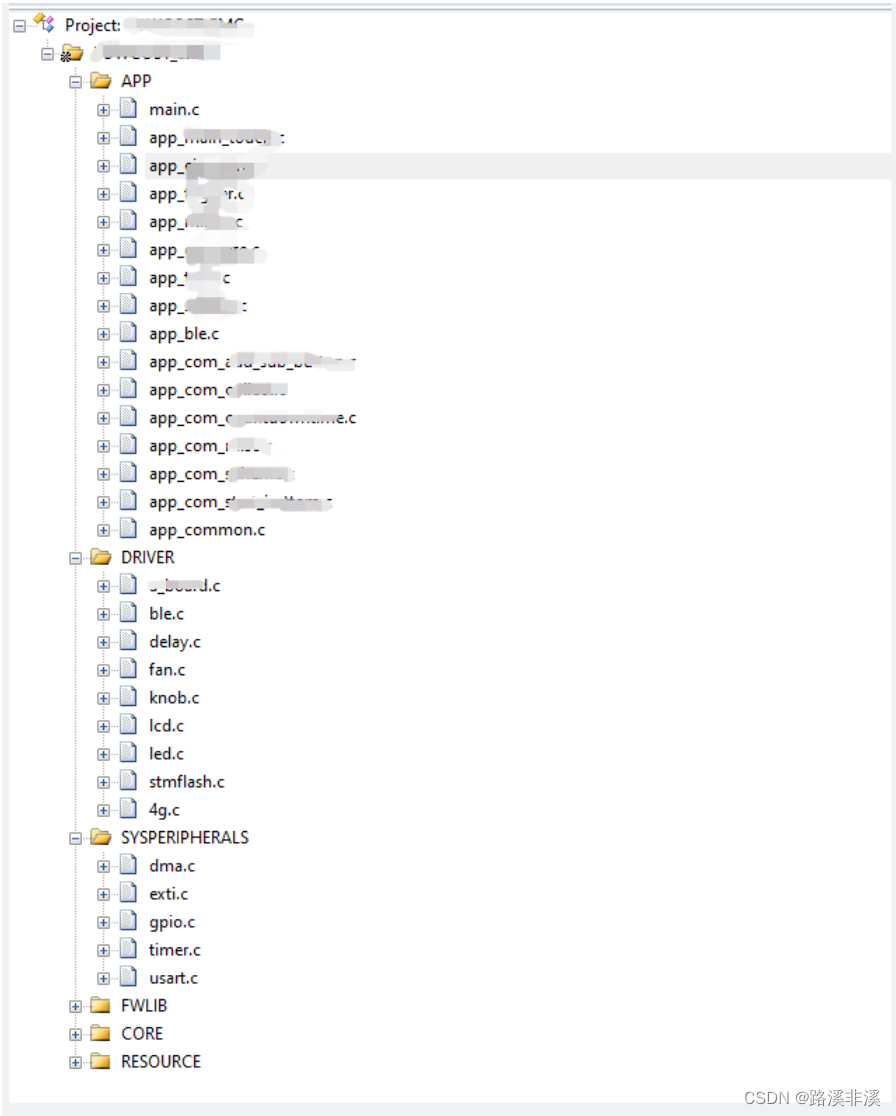
将整体的架构设计分成3层,再多层次对于裸机感觉没什么必要了。
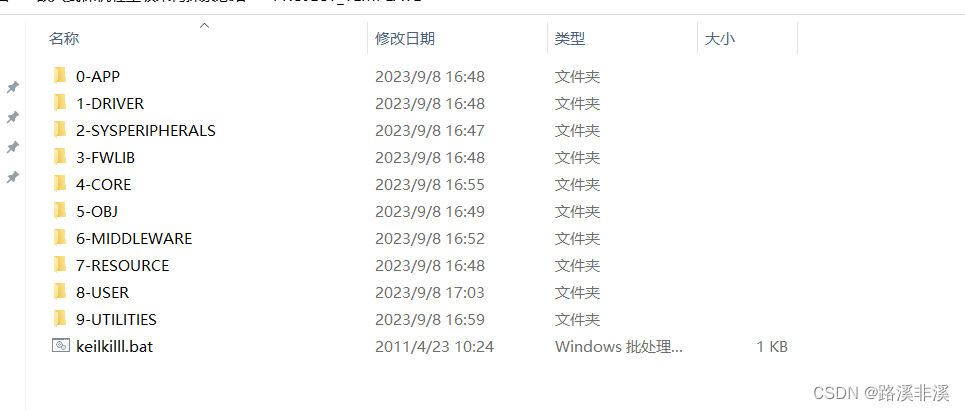
模版示例:
APP存放业务层代码;
DRIVER存放硬件驱动层代码;
SYSPERIPHERALS存放系统外设代码;
FWLIB存放固件库;
CORE存放一些板级核心代码;
OBJ存放keil的输出文件;
MIDDLEWARE存放中间件;
RESOURCE存放一些资源比如字库等;
USER存放工程;
UTILITIES存放其他内容;
除了一些固定的文件,在开发时分为系统外设、驱动层,再加上一个业务层。
系统外设层主要是对用到的各种片上外设进行初始化,之前经常跟驱动层写到一起,但时间久了就发现二者其实是不同的层次,写到一起容易混乱。
理想情况下,系统外设层向驱动层提供接口,驱动层向业务层提供接口。
系统外设层的各个硬件口,最后都用宏定义给重命名,如果要移植,就只用该硬件口就行,而不用去动驱动层,比如,如果就用GPIOA去开发,那么如果换了板子,就要改驱动层的书写,但是如果重命名,就只用改系统外设层的头文件即可。
另外,对于业务层来说,不推荐将所有的功能都放在同一个文件中,虽然比较方便,但是这会导致文件特别大,不利于后续开发和维护。最好按照功能模块进行开发,然后有一些各模块共用的功能,可以抽离出来,单独一个文件。通常,拆一个总的入口文件,再按大模块拆一拆,然后就是共用的部分。按模块其实是同级拆分,将共用功能分离出来,其实是上下层次的拆分,不过,也没啥必要再分不同目录来放了。
上面实例中,其实拆的太多了,就多了文件跟文件之间的纠缠,后续也很难理清。
前期一定就要做好设计和规划,不要试图想着先开发,后续再修改,惨痛的教训告诉你,修改比重新开发更让人烦躁,很费时间,分分钟有牵一发动全身的风险。
总之就是,越往上层,就应当越抽象。
层数越多,越复杂。
请合理平衡。
关于系统外设和驱动层的初始化,如果系统外设是和具体的驱动关联的,就可以放在驱动里,如果不能跟具体的驱动关联,就直接在系统外设层定义初始化接口即可,比如定时器。
另外,注意编码规范,如果太随意,越往后代码量越大就越难开发。就按照常规推荐的那些编码规范来写就行了,也不必特立独行。
关于变量还有头文件中的宏定义,有共用的,有专用的,专用的肯定是放在自己的c中,共用的可以放在common中,该static的就static。关于程序中的全局变量,建议如果超过3个,就用结构体封装起来,函数最好也是用函数指针结构体封装起来(借鉴硬件家园的风格)。区分仅自己使用和需要共享使用的情况,然后决定是用static限定或者加入到相应结构体中。
模块化就比较好理解,各个模块单独开发,最好可以实现独立编译。
如果是已经写好的代码,不要试图去重构,这会让你陷入无尽的烦恼之中,不必重新开发更轻松。
已经写好的,就将就用吧。
另外就是,不要试图追求完美。
架构2.0
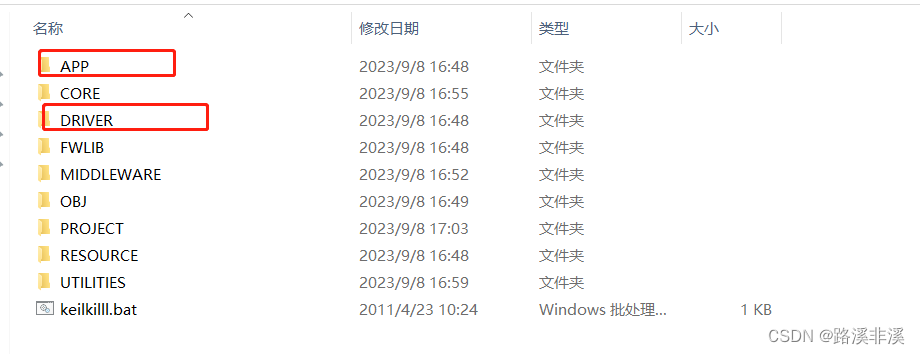
改进点:不要将硬件驱动层再分两层了。
看了很多的代码,发现也没有将驱动层分成系统外设和驱动层的。
其实,将二者合并在一起的好处也是有的:
1、减少了层次间的相互调用,而且,代码量也不会增加多少;
2、各系统外设的初始化本来就是外设的一部分,直接放在驱动文件里,也是合理的,更清晰明了,如果单独把所有外设的初始化都放在一起,也容易搞混;
3、不用考虑中断响应函数到底放在哪一层;
4、初始化时,直接按外设模块来进行即可,不用纠结到底放在哪一层来初始化;
5、照样可以用宏定义来定义。
基于以上几点考虑,还是将架构就分为两层,即硬件驱动层和业务层。
注意,将USER改名为PROJECT了,不过不重要。
架构3.0
要实现的目标:
1、硬件驱动层,各模块之间可以独立编译,互不影响;
2、硬件驱动层不会反向调用业务层的API;
3、硬件驱动层不会向外暴露自身的全局变量;
以上三点,我们来依次看一下。
第一点,很容易做到,只要各模块独立c和h即可;
第二点,开发时注意些就行,千万不要反向调用;
第三点,要多说一些。
通常,驱动层和业务层的关系,分成两种:
一种是业务层主动调用驱动层的API,比如业务层调用驱动层的打开LED函数实现点亮LED,或者主动调用数据发送函数发送数据等;
还有一种是被动响应式的,即驱动层响应之后,需要向业务层上报,此时业务层就是被动响应的,有很多的例子,比如按键按下,串口接收数据,ADC采集等等,都是驱动层响应后,需要向业务层上报数据。
我们通常的做法是,在驱动层定义一个全局变量,然后声明出去,业务层的任务中循环判断这些全局变量,从而做出相应的动作。
可参考:单片机模块化编程框架篇-编写回调函数及产品应用_哔哩哔哩_bilibili
这里说的就是业务层主动发起的调用。
那么,业务层被动响应式的情况呢?
那么,回调函数的开发思路是怎么样的呢?
说实话,回调函数其实是个不太好理解的东西。
这名字听着就不知道啥意思。
其实,在本文的场景下,我们可以这样理解:业务层调用驱动层时,是直接调用的,但是业务层被动响应的情况下,驱动层基本都是由中断来触发的,通常如果直接在驱动层的中断里调用业务层的函数,一来不符合中断快进快出的理念,二来不符合下层不应该调用上层的理念。
这种情况下,我们可以在驱动层间接调用业务层的处理函数。
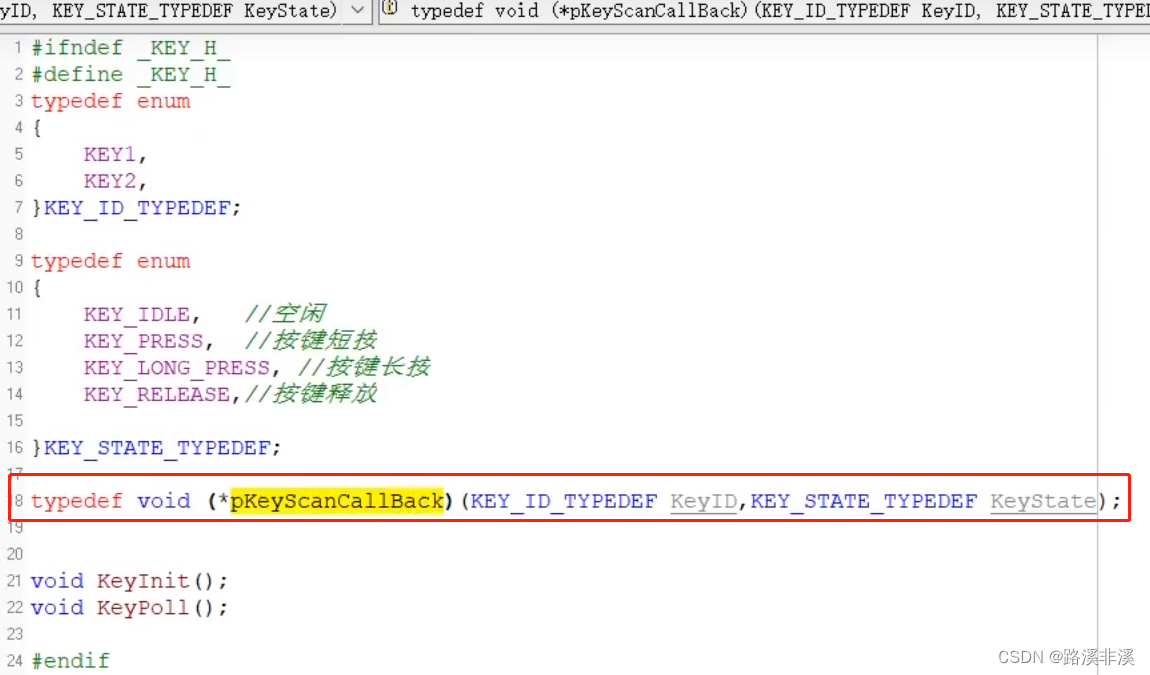
在驱动层定义一个回调函数的函数指针,函数里传入的是需要传递的全局变量
同时定义一个注册函数
还要在业务层定义一个跟函数指针同类型的处理函数
然后在业务层调用注册函数,将业务层的处理函数传入驱动层的函数指针
然后在中断里只需要调用函数指针即可实现间接调用业务层的目的
但实际上,访问的只是驱动文件中的函数指针。
因为,这个实现了下层调用上层的目的,是在上层定义,但是由下层调用,所以,被叫做回调函数,也是很合理的。
至此,就进步了一个台阶,至少,解决了驱动层和业务层之间的全局变量的传递问题。







另外,建议如果全局变量超过3个,就定义成结构体吧。
这也是一种简单的封装。
后续再优化架构估计就是在这上面琢磨了。
总之,先把上面三种架构版本熟练掌握。
裸机架构的崩塌
到了这里,要说一点感想:裸机根本就没有架构,或者说,裸机本身就是一种前后台架构。而操作系统本身也是一种架构,那就不再是裸机的架构了。
为什么有这种感想呢?
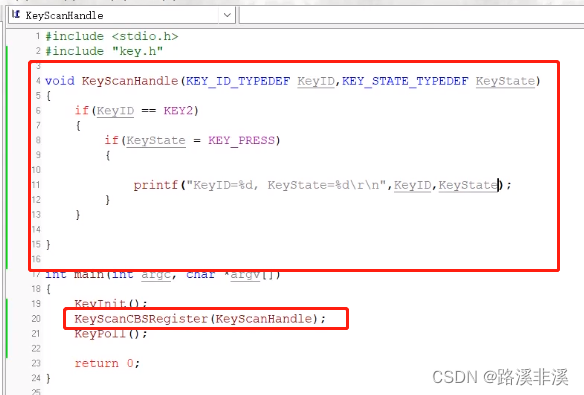
今天,我根据上述的教程,自己在裸机项目里用了下回调函数。
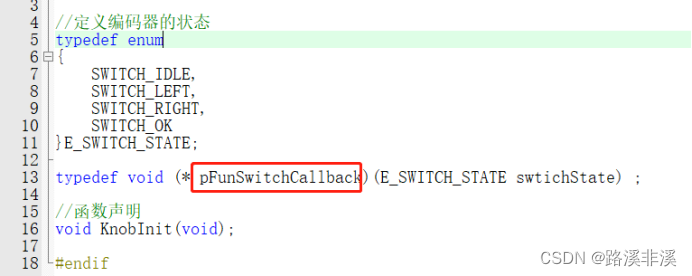
定义函数指针
注意,typedef函数指针时,上面的名称就是该函数指针的别名,别再后面再取个名了,一定要注意。
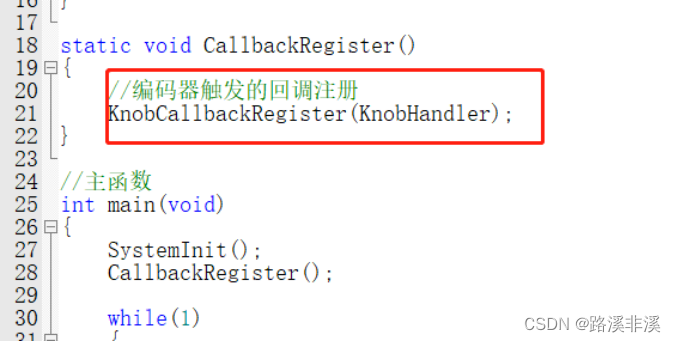
注册函数
中断触发时调用
业务层定义处理函数
主函数里注册
以上就是使用的过程。
得出几点结论:
1、可以确定的是,中断里回调函数类似于中断嵌套,会打断主循环的执行
2、接下来要确定的是,是否会阻塞中断。
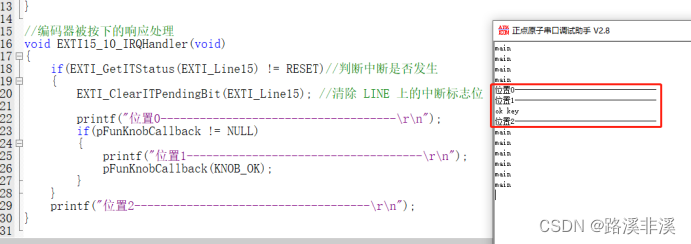
经验证:
回调函数在裸机里几乎没有作用,跟直接调用上层函数没啥区别。
我在回调处理函数中做了5秒延时,不管是直接调用,还是回调函数调用,都会阻塞中断。
也就是说,搞了半天,绕了一大圈,结果在裸机里,使用回调函数,增加复杂度不说,而且没有任何改进。
再想想,网上说了回调函数的很多好处
什么灵活、实时性强、易于封装、移植性好……
就是没人说,这个并不适用于裸机。。。。。。。。。。。。
常见于操作系统环境使用,正好我看的就是一个轻量级的操作系统的课程。。。。。。
常常是,系统有一个函数指针,用户重写这个函数,并且注册传入底层的函数,就可以实现底层调用上层的目的了,灵活性挺高。
但是,还是那句话,适用于操作系统环境。
这么一想,探索了一段时间的所谓裸机架构,其实是个几乎不存在的东西。
可以这么说,回调函数常见于操作系统的设计中,应用代码几乎用不到。
裸机中的最大特点就是,任务是依次执行的,必需先执行完上一个任务,才能再执行下一个任务。想通了这一层,就理解了裸机中回调函数也会和普通调用一样阻塞中断。
操作系统的最大特点就是并发执行。








前后台系统的回归
裸机,直接while里循环调度即可,不要搞些花里胡哨的东西。
我们能做的就是遵循前后台系统开发的原则,然后在此基础上,做好分层,做好头文件和全局变量管理,提高代码的规范性和可读性。
裸机头文件统一管理
头文件可以统一管理application.h
可以放在PROJECT里
在这个头文件里统一管理所有用到的头文件
之前以为头文件放在一起再包含,会导致很多c文件会包含很多不需要用到的头文件,进而导致内存占用更多,目标文件更大。
但经过验证,并不会影响内存占用和目标文件的大小。
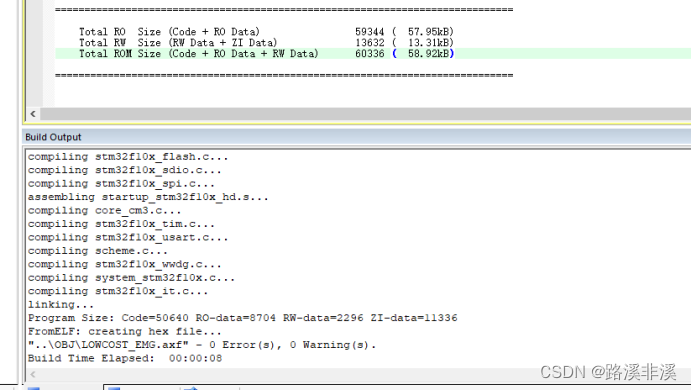
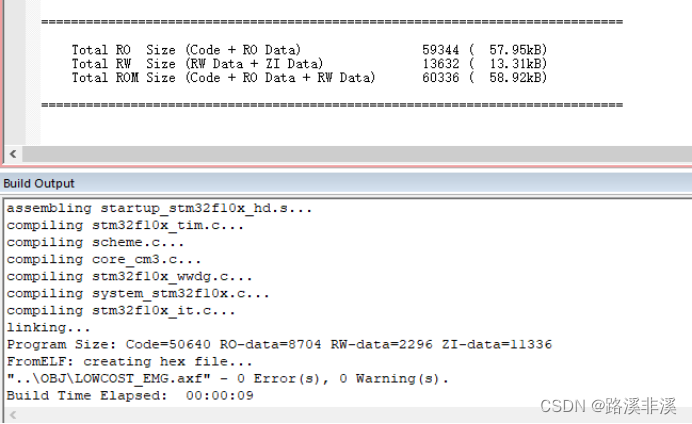
头文件没有统一管理时的空间占用以及hex文件大小
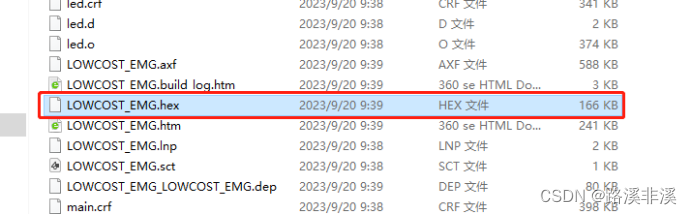
头文件统一管理之后的空间占用以及hex文件大小
通过对比可以发现,二者一模一样。
为什么呢?
因为头文件是预处理环节处理,只是进行单纯的文本代替,就是让我们能找到c文件中的宏定义或者类型定义表示什么含义而已,跟运行没关系,并不会包含进最后的烧录文件中。
另外,如果头文件中需要什么头文件,单独定义即可,一般头文件中只有声明或者类型定义,大多数情况下只需要#include <stdint.h>,如果重复包含,可能会导致循环嵌套。如果头文件中再调用application.h就会陷入循环,而单独定义,再经由application.h包含到其他文件时,无非就是重复包含的问题,而重复包含,头文件已经通过头尾的宏定义排除过了
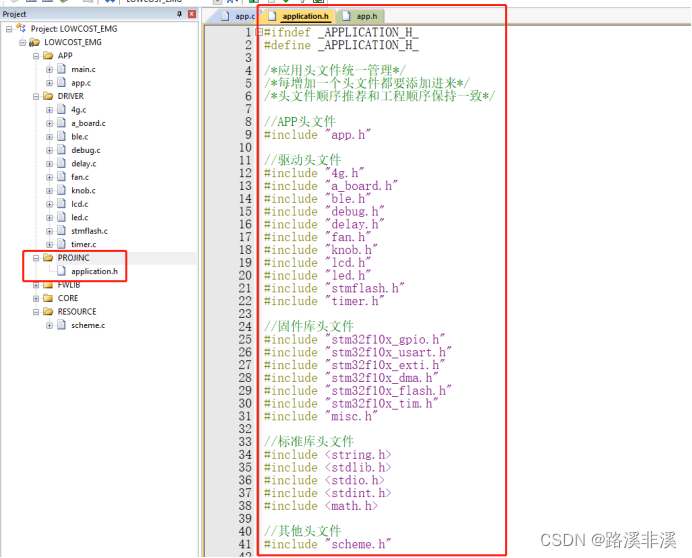
分层思想(非常重要)
这里的思想很重要
1、业务层的横拆和纵拆:各独立模块之间是横拆,如果有数据交换,就通过全局变量,模块到common之间是竖拆,主要是将共用的部分分离出来。
2、分离时,要向下分离,提供给上层调用,当向下分层后,即使有全局变量,也可以通过函数参数传递下去,而不用在底层去extern上层的内容,记住,底层永远不要去引用上层的东西。想一想c库,难道他的库还要你给他个全局变量才能执行?就算能给,难道你要改库的源码,在源码里extern?而且,很多库根本就不开放源代码,这样,库也不可能去主动调上层用户的程序。
3、高内聚,低耦合,直观体现就是,任何一个函数,最好只依靠本c文件的内容以及其他任意头文件的内容来实现,而不必依赖其他c文件中的内容,比如其他文件的全局变量。想一想c标准库,或者stm32固件库,都是一个个独立的文件,几乎可以独立编译,不需要依靠其他c文件。
4、越往上层,越抽象,越少实现过程,越少细节,越多函数调用,最好到main主函数中时,没有任何实现过程,只有一个一个的任务函数。
5、越共用的东西,越应该放到下层,这样才能方便地被上层调用。比如APP也可以有个驱动层,app_driver,再上面就是app_common,再上面就是各模块,再就是综合应用,越共用的越往下放。最好就封装成一个调用库。但是也没必要分太细,差不多就行。最优的情况是,直接调用底层函数就能完成功能,再就是允许底层暴露一些全局数据。不过,上层不应该暴露数据给底层。
各模块之间独立,要想模块独立,就得将共用的东西往下分离。
书写再规范
变量小驼峰,函数大驼峰
前缀ST E g pInt pFun
判断的变量前加个is前缀,比如,isSelected
无参的地方都加上void以显式表明
等等
代码重复量太大的,强烈建议整合,减少冗余代码
全局变量的管理
头文件统一管理之后,头文件的内容确实就不再是问题,可以重点关注全局变量的管理。
裸机中很难避免使用全局变量,我们要尽量做好全局变量的管理。
那么,有哪些技巧呢?
1、如果全局变量超过3个,就建议使用结构体封装起来;
2、通过上面讲的分层思想,减少各文件之间全局变量的相互纠缠,全局化越大的变量越往下层放,下层永远也不要去引用上层的东西,就当下层是个只能被调用并且不开放源码的库,思考这种情况下应当如何设计全局变量;
3、做好全局变量的注释;
4、全局变量是主动在头文件中extern出去,然后谁包含了谁就能用,还是谁要用谁自己去自己的c文件里extern呢?我想,如果是下层的全局变量,那么可以extern出去,供上层使用,这样,不用每个上层文件使用时都得extern,如果是同层次之间的,建议还是谁要用谁自己extern。
5、这一点很重要
我们想一想固件库,里面是不是几乎看不到显式的全局变量?
固件库的方式,下层定义相关参数结构体,在对应函数中定义结构体形参,然后直接对数据进行操作,上层调用函数时,定义结构体局部变量然后将结构体指针传入给底层函数进行操作。
但也是因为固件库基本都是对寄存器赋值,才能更好地操作,虽然上层没有寄存器,不过我们可以借鉴这种思路。
//其实仔细想想,寄存器其实就相当于最底层的全局变量,如果说我们把APP最底层的全局变量都定义在app最底层,就当这些全局变量是寄存器,我们需要的时候就去取底层寄存器的值,上层也可以方便地去修改底层寄存器的值,
//然后寄存器的值甚至可以定义设置和获取的函数,就和固件库里的有些set以及get函数一样。
//这样的话,甚至可以进行位操作。
//还是那句话,通用的变量分离到下层,专用的在自己的文件里定义。
上层向下层传递函数形参,下层向上层提供全局变量
app或者各模块
app_common
app_softregister另外,同一文件中,越共用的函数越往上放,将下层的函数放在文件上面,上层的函数放在文件下面,这样就不用进行太多的函数声明了。
关于上层和下层的这些思维,对于头文件也是一样的,越底层越往下放,你想想,固件库难道要你上层提供一个数据类型才能用?//底层越集成越好,上层假如有100个地方要用,如果要改,不用去改100个上层处,只用改一个下层即可。
这里有一篇论坛可以参考下,差不多就是我这里说的思路
如何尽量地避免使用全局变量呢? (amobbs.com 阿莫电子论坛 - 东莞阿莫电子网站)
总结来说就是以下几点:
1、底层驱动尽可能独立;
2、将APP中所有全局变量放在一个底层c中,同时,提供get和set接口函数来提供给上层访问;
3、能封装成结构体的一些变量就封装起来,然后上层通过传递结构体指针的方式来修改这些变量;
4、通用的变量分离到下层,专用的在自己的文件里定义;
5、总之,就是,尽量不要使用开放的全局变量;
6、不过,相对于直接使用全局变量,这样操作效率相对较低,但是基本没什么影响;
7、最怕在多个模块中直接操作全局变量,这样会把各个模块之间的逻辑关系搞复杂!
做好模块化、层次化。
使用这些方法好处非常多,不仅不会降低效率,还会降低代码尺寸,实现对变量的访问权限控制(只读,只写),可以一劳永逸的实现对变量的原子保护,可以在读写的时候进行有效性检查,最后调试的时候方便追踪谁对变量进行了访问,也可以填写调试值。这就是面向接口开发的好处。
最后,总结原则就是:不要让任何一个全局变量暴露出来。

随便说两句………………………………
代码的合理化规范化其实是我们人类的需求,并不是机器的需求,机器只要是最后得到的二进制数是对的,就可以了,不管代码写的多烂,哪怕把所有内容全都塞在一个文件里,对计算机来说,是没有什么差别的,但是对于我们人类的阅读开发维护等,就是极大的灾难了。这就是为什么有的代码写的很烂,但是功能也能实现。不过,我们的目标是,开发既是一门技术,也要尽量做成一门艺术。就好比踢足球,本身是个技术活,但是梅西能把足球踢成艺术,就是一种巨大的成功。