目录
简单了解一下字符串
String类里面是如何存放字符串的?
String的不可变性
字符串拼接的方法
1.使用+拼接字符串
2. 使用concat
3. 使用StringBuilder
4.StringBuffer
使用+字符串拼接的原理
使用concat
StringBuilder
效率比较
简单了解一下字符串
String类里面是如何存放字符串的?
private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0
原来里面是有一个value的字符数组, 一个字符串被分为一个一个字母, 存放在这个字符数组里面.
String的不可变性
为什么String类是不可变的?? 因为存放这个字符串的字符数字是使用private修饰的, 也就是说, 在这个包外面, 无法对这个value进行直接的访问(外界是看不到这个value字符数组的), 同时这个value数组被final修饰, 代表他不能被修改指向, 同时包里面也没有提供方法来修改这个字符数组里面的内容, 所以说无论怎么样这个字符数组都是不可变的. 一旦创建, 就不能改变.
这样子设计有很多好处, 比如可以缓存hashcode, 也可以使用更加安全和便利.
下面来介绍一下字符串拼接的四种常用方法
字符串拼接的方法
1.使用+拼接字符串
public class Test {
public static void main(String[] args) {
String a = "hello";
String b = "world";
String c = a + b;
System.out.println(c);
}
}
这里需要特别说明的一点事, 这里的加法 是java中提供的一个语法糖, 这个语法糖就例如基础类型对应的包装类的自动装拆箱一样.
什么是语法糖? 语法糖, 也被翻译成为糖衣语法, 是由英国计算机科学家, 彼得兰丁发明的一个术语, 这种语法对语言的功能没有影响, 但是更方便程序员使用, 语法糖让程序更加简洁, 有更高的可读性.
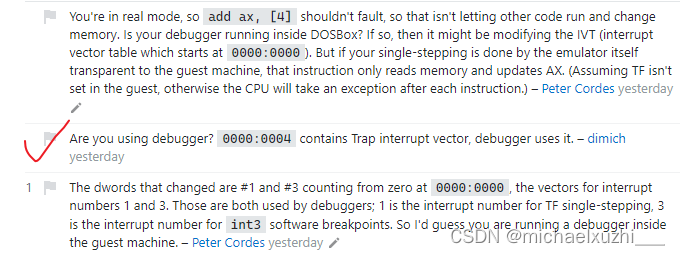
此外, +号除了可以拼接字符串和字符串, 还可以拼接其他基本数据类型, 例如Boolean类型, 如下:
public class Test {
public static void main(String[] args) {
String a = "hello ";
boolean b = false;
String c = a + b;
System.out.println(c);
}
}
2. 使用concat
除了使用+号之外, 还可以使用String类中提供的方法, concat来拼接字符串, 例如
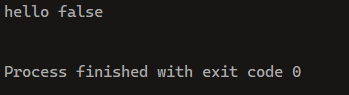
public class Test {
public static void main(String[] args) {
String a = "hello ";
String b = "world";
String c = a.concat(b);
System.out.println(c);
}
}
3. 使用StringBuilder
关于字符串, java中除了定义了一个不可变的字符串String类之外, 还提供了可以修改的字符串类, 也就是StringBuilder类, 它的对象是可以修改的.
StringBuilder里面提供了很多方法可以多字符串进行修改, 例如append方法, 直接在字符串对象后面追加字符串, 或者是使用insert直接在指定位置插入(也是一种修改). 这里我们只参考append的情况. 使用append的案例如下:
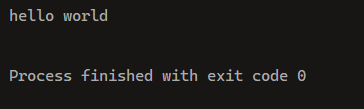
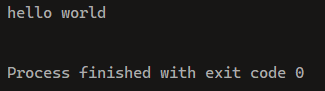
public class Test {
public static void main(String[] args) {
StringBuilder stringBuilder = new StringBuilder("hello");
String a = " world";
StringBuilder b = stringBuilder.append(a);
System.out.println(b);
}
}
4.StringBuffer
StringBuffer其语法和StringBuilder一致, 只不过StringBuffer里面提供的方法都是线程安全的.这后面讲解.
以上几种常用的字符串拼接, 到底哪种更好用, 为什么我们常说, 循环里面不建议使用+进行字符串拼接呢??
下面我们一一来解答.
使用+字符串拼接的原理
前面提到的使用+进行拼接, 只是java的语法糖, 看看它内部原理是怎么实现的.
有如下代码:
public class Test {
public static void main(String[] args) {
String a = "abc";
String b = "def";
String c = "abc" + "def";
String d = a + "def";
String e = "abc" + b;
String f = a + b;
String g = "abcdef";
}
}
我们使用jad来反编译生成的字节码文件, 看看结果.
public class Test
{
public Test()
{
}
public static void main(String args[])
{
String a = "abc";
String b = "def";
String c = "abcdef";
String d = (new StringBuilder()).append(a).append("def").toString();
String e = (new StringBuilder()).append("abc").append(b).toString();
String f = (new StringBuilder()).append(a).append(b).toString();
String g = "abcdef";
}
}还有另外一个情况如下:
public class Test {
public static void main(String[] args) {
String a = new String("abc") + "abc";
}
}其反编译结果如下:
public class Test
{
public Test()
{
}
public static void main(String args[])
{
String a = (new StringBuilder()).append(new String("abc")).append("abc").toString();
}
}我们总结一下字符串+拼接:
总结:
对于+拼接字符串的过程, 拼接的多个字符串中出现了new关键字, 或者是出现了其他字符串的引用的情况, 就会先生成一个StringBuilder对象, 然后使用这个对象的append方法追加字符串, 随后调用StringBuilder的toString方法, toString方法的实现如下:
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
} public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}我们来解释一下这个String的构造方法:
offset为从指定位置开始赋值, 往后赋值count个字符, 如果offset和count < 0就跑出异常. 并且如果 offset <= value数组的长度并且count的值为0的话就将String里面的value构造为空值, 可以理解为返回一个空字符串. 如果offset > value.length - count就会产生越界, 除了上面这些情况之外, 其他情况都满足要求, 于是就将使用Arrays.copyOfRange方法来copy字符数组, 将value数组里面从offset开始, 复制到下标为offset + count的位置到原来new String 的value里面, 然后返回, 于是就构造好了一个新的字符串.
需要注意一下的是, 这里StringBuilder里面的toString本质上还是一个new 的String:
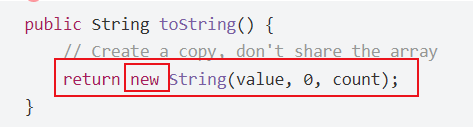
我们知道, 我们java内存空间里面, 堆区是有我们程序员控制的, 一切new出来的对象, 都存在于堆区(都会在堆区重新申请一块新内存).
所以如果有如下问题:
public class Test {
public static void main(String[] args) {
String a = "abc";
String b = "def";
String c = "abc" + "def";
String d = a + "def";
String e = "abc" + b;
String f = a + b;
String g = "abcdef";
System.out.println(c ==g); // 1
System.out.println(c == d); // 2
System.out.println(c == f); // 3
System.out.println(f == g); // 4
System.out.println(c == g); // 5
}
}
问: 1 2 3 4 5分贝输出什么??
答案如下:
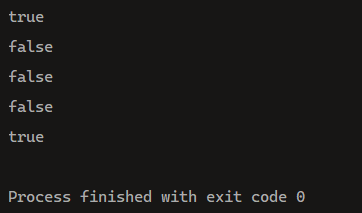
为什么?? 因为只要有变量或者是new关键字参与的字符串+拼接, 都会在底层先新建一个StringBuilder对象, 然后使用append追加, 随后使用toString方法返回一个在堆区存放的字符串. 因此有如图所示的情况.
使用concat
public class Test {
public static void main(String[] args) {
String a = "hello";
a = a.concat(" world");
System.out.println(a);
}
}
我们来看一下concat原码
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}从本质上看还是使用Arrays.copyOf的方法, 将字符串从老字符串里面的内容先拷贝到新字符串,并提前扩容, 然后将追加的字符串str里面的内容追加到buf中, 随后返回这个buf数组的String形式. 但其实末尾还是new了一个String对象.
StringBuilder
我们来看看StringBuilder的组成:
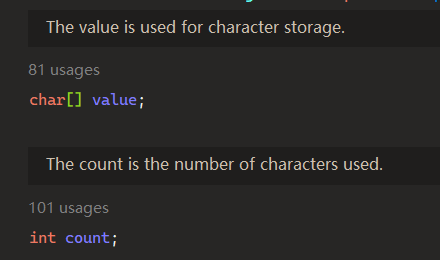
和String类似, StringBuilder也封装了一个字符数组, 然后还多了一个count属性, 用来描述这个数组中已经使用的字符个数.
其append原码如下:
public StringBuilder append(String str) {
super.append(str);
return this;
} public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}从源码上看, append会确认容量之后, 直接拷贝字符串到内部.
其中getChars的声明如下:

参数如下:

也就是说会将str中的全部字符全部存入value数组的后面, 然后返回
StringBuffer和StringBuilder差不多, 这里不单独阐述, 只是StringBuffer里面的方法都是synchronized声明的, 是一个线程安全的类.
效率比较
这么多字符串拼接, 我们还是需要来看一下, 哪一种效率会跟高. 简单对比一下, 如下:
long t1 = System.currentTimeMillis();
//这里是初始字符串定义
for (int i = 0; i < 50000; i++) {
//这里是字符串拼接代码
}
long t2 = System.currentTimeMillis();
System.out.println("cost:" + (t2 - t1));
我们使用形如以上形式的代码,分别测试下五种字符串拼接代码的运行时间。得到结果如下:
+ cost:5119
StringBuilder cost:3
StringBuffer cost:4
concat cost:3623
StringUtils.join cost:25726从里面可以看出来.
StringBuilder < StringBuffer < concat < +
- StringBuffer在StringBuilder的基础上,做了同步处理,所以在耗时上会相对多一些
- 字符串+拼接在for循环里面, 如果有变量或者是new关键词参与拼接, 那么就会每次都new出一个StringBuilder对象, 然后使用append方法, 随后又使用toString方法来new一个对应的String类, 这样繁琐的创建对象, 不仅消耗时间, 还会消耗内存资源
- 对于StringBuffer, 里面使用线程安全的synchronized来修饰方法, 自然会比StringBuilder慢一下, 至于为什么, 可以看我前面的多线程的文章.
所以,阿里巴巴Java开发手册建议:循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。而不要使用+。