DAB-DETR(2022ICLR)
DAB:Dynamic Anchor Boxes

贡献:
-
明确了不是由于learnable queries导致的收敛缓慢
-
4D anchor
-
Anchor Update
-
Width & Height Modulated
-
Temperature Tuning
前半部分:Why a positional prior could speedup training?
为什么位置先验可以加速DETR训练?
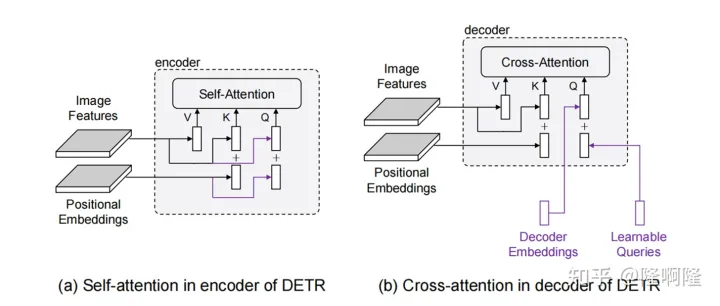
(a)图像feature+pos embedding
(b)初始的/decoder输出+object query
两个可能原因导致收敛缓慢:
- 优化挑战,object query难以学习
- learned object queries中的位置信息的编码方式与用于图像特征的正弦位置编码方式不同(原来的detr是embedding,position embedding不一样)
实验1:把学好的object query给未训练的DETR,只在前半epoch稍微高一点,因此并不是query难以学习
实验2:self attention中query挑选感兴趣的信息,关心某种图像的区域或大小
如果思考为一种位置约束,有不好的属性(之前的可是画图):
- 关注了多种模式的物体(一个slot小目标,横的,竖的)
- 查某种物体权重相似

图(a)coco数据集目标如果刚好上面和下面都有GT,存在多个物体就很难定位
图(a)底部关注太大或太小的区域,不能在提取过程中注入有用的位置信息
图(b)相比于detr关注某一物体,但忽略了物体的尺度信息(圈圈看起来都是一样大小的)
模型

具体结构看:https://img-blog.csdnimg.cn/c7bf7283aca94942b55606c667861bef.png
贡献
4D-Anchors:Aq=(xq,yq,wq,hq)(使用方式来自于conditional detr)
q是第q个锚点的意思
P
q
=
M
L
P
(
P
E
(
A
q
)
)
P_q={\mathrm{MLP}}\left(\mathrm{PE}\left(A_q\right)\right)
Pq=MLP(PE(Aq))
anchor变成4d,经过位置编码,MLP获得query的positional embed
P
E
(
A
)
.
=
P
E
(
x
q
,
y
q
,
w
q
,
h
q
)
=
C
a
t
(
P
E
(
x
q
)
,
P
E
(
y
q
)
,
P
E
(
w
q
)
,
P
E
(
h
q
)
)
{\mathrm{PE}\left(A\right)}_{.}=\mathrm{PE}\left(x_{q},y_{q},w_{q},h_{q}\right)=\mathrm{Cat}\left(\mathrm{PE}\left(x_{q}\right),\mathrm{PE}\left(y_{q}\right),\mathrm{PE}\left(w_{q}\right),\mathrm{PE}\left(h_{q}\right)\right)
PE(A).=PE(xq,yq,wq,hq)=Cat(PE(xq),PE(yq),PE(wq),PE(hq))
PE输入是四维信息,cat所有4个分量,编码为128维,cat后为512,mlp变回256
Self-Attn:
Q
q
=
C
q
+
P
q
,
K
q
=
C
q
+
P
q
,
V
q
=
C
q
\text{Self-Attn:}\quad Q_q=C_q+{P_q},\quad K_q=C_q+{P_q},\quad{V_q=C_q}
Self-Attn:Qq=Cq+Pq,Kq=Cq+Pq,Vq=Cq
self-attention没什么更改
Cross-Attn:
Q
q
=
Cat
(
C
q
,
PE
(
x
q
,
y
q
)
⋅
MLP
(
csq
)
(
C
q
)
)
,
K
x
,
y
=
Cat
(
F
x
,
y
,
PE
(
x
,
y
)
)
,
V
x
,
y
=
F
x
,
y
,
\begin{aligned}\text{Cross-Attn:}\quad&Q_q=\text{Cat}\left(C_q,\text{PE}(x_q,y_q)\cdot\text{MLP}^{(\text{csq})}\left(C_q\right)\right),\\&K_{x,y}=\text{Cat}\left(F_{x,y},\text{PE}(x,y)\right),\quad V_{x,y}=F_{x,y},\end{aligned}
Cross-Attn:Qq=Cat(Cq,PE(xq,yq)⋅MLP(csq)(Cq)),Kx,y=Cat(Fx,y,PE(x,y)),Vx,y=Fx,y,
cross-attention
Q_q:其中C_q:上一个self-attention的输出,后面是conditional detr的做法
k:Memory+posembedding
v:v不变
Anchor Update(deformable box refine):
Width & Height Modulated:
传统的位置注意映射被用作类似高斯先验,其假设具有固定大小
但先验是简单地假设所有对象都是各向同性的和固定大小的,忽略了它们的比例信息(宽度和高度)

上面是原来的标准的attention
修正positional attention map通过分别 m单独分离出相关anchor的 width 和height 从它的 x part and y part to smooth the Gaussian prior to better match with objects of different scales
wq和hq是anchor Aq的宽和高,wqref和hqref由MLP得到
Temperature Tuning(提点的):
Transformer中位置编码是使用正余弦函数进行编码的,公式如下
pos代表句子中词的位置,2i或者2i+1代表位置编码向量的一个分量,2i代表偶数,2i+1代表奇数,由此可见某个词的位置编码是一个向量不是一个值,它由词的位置,以及分量位置两个共同决定的。
def GetPosEncodingMatrix(max_len, d_emb): # 位置编码 pos_enc = np.array([ [pos / np.power(10000, 2 * (j // 2) / d_emb) for j in range(d_emb)] if pos != 0 else np.zeros(d_emb) for pos in range(max_len) ]) pos_enc[1:, 0::2] = np.sin(pos_enc[1:, 0::2]) # dim 2i pos_enc[1:, 1::2] = np.cos(pos_enc[1:, 1::2]) # dim 2i+1 return pos_enc 设置max_len为每个句子的最大长度为50,d_emb为每个词的embedding的维度为256,最终得到一个[50, 256]的位置编码矩阵,每一行代表一个位置的位置编码结果,每一列代表某个词在某个位置编码分量上的值。所有句子共享这个位置编码矩阵,也就是说所有句子相同位置的字/词的位置编码结果是一致的,
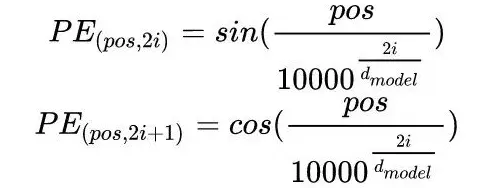
PE
(
x
)
2
i
=
sin
(
x
T
2
i
/
D
)
,
PE
(
x
)
2
i
+
1
=
cos
(
x
T
2
i
/
D
)
\operatorname{PE}(x)_{2 i}=\sin \left(\frac{x}{T^{2 i / D}}\right), \quad \operatorname{PE}(x)_{2 i+1}=\cos \left(\frac{x}{T^{2 i / D}}\right)
PE(x)2i=sin(T2i/Dx),PE(x)2i+1=cos(T2i/Dx)
温度参数:原始NLP是10000,在DETR中不适合